

鸢尾花数据在机器学习中经常会运用到,并且其中的数据可以进行三分类的操作,机器学习算法对其的应用例子特别多。最近在学习神经网络方面的知识,所以运用了神经网络方面的知识对其数据进行分析以及对神经网络构建训练对鸢尾花种类进行一个预测分析。
文章目录
问题描述
利用数据分析知识对鸢尾花数据进行可视化分析以及通过运用神经网络算法构建模型,根据鸢尾花的花萼和花瓣大小,区分鸢尾花的品种。实现一个基础的三分类问题。


; 一、数据集的获取以及观察
数据集的获取我们可以通过在Sklearn机器学习包中获取,Sklearn集成了各种各样的数据集,包括糖尿病数据集、鸢尾花数据集等,使得我们可以对其直接利用以及进行数据分析,本文使用鸢尾花卉Iris数据集,这个数据集共150行数据,其中了包括四个特征变量:
- 花瓣长度
- 花瓣宽度
- 萼片长度
- 萼片宽度
同时这个数据集也包含了其对应的输出类型变量,不同花的类型分别对应不同标签,即:
- 山鸢尾(Iris-setosa)→ 0
- 变色鸢尾(Iris-versicolor)→ 1
- 维吉尼亚鸢尾(Iris-virginica )→ 2
我们可以打开位于Sklearn包中的数据csv文件进行观察(一般情况下此数据集在\sklearn\datasets\data\iris.csv或者通过Everything文件搜索插件直接对数据集合直接搜索获取),数据如下(pandas读取对部分展示进行展示):

二、数据分析
通过对数据的简单浏览,不难发现花萼或者花瓣的形状特征对花的品质有着很大的影响,但是初略的观测难以观察出对于结果的影响,通过对数据进行统计画图分析就能更直观分析以及对数据进行简单的预测。本文分别对花萼数据以及对花瓣数据进行plt绘图分析。
1.代码展示:
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
数据集导入
iris = load_iris()
print(iris.data, iris.data.shape)
print(iris.target, iris.target.shape)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.subplot(1,2,1)
plt.scatter(iris.data[:, 0], iris.data[:, 1],
c=iris.target, marker='x')
plt.xlabel('花萼长度')
plt.ylabel('花萼宽度')
plt.title('花萼分布')
plt.subplot(1,2,2)
plt.scatter(iris.data[:, 2], iris.data[:, 3],
c=iris.target, marker='x')
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
plt.title('花瓣分布')
调节图与图之间的距离
plt.subplots_adjust(wspace=0.5)
plt.savefig('鸢尾花分析.png')
plt.show()
2.统计图结果展示
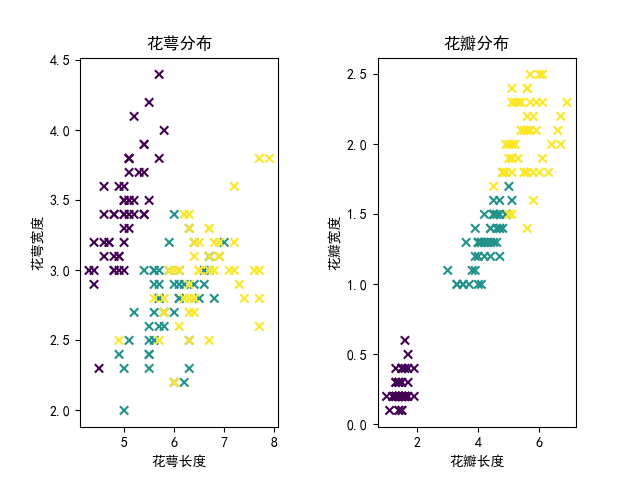
通过上图的对比以及比较我们不难看出花瓣的形状对鸢尾花的种类影响更大、更直观,分类效果更加集中在某个区域,但也并不是说明花萼对花的种类无明显变化。
; 三、神经网络构建以及模型的分析
1、神经搭建
通过以上对鸢尾花数据的分析以及观测,可以初步通过花萼形状以及花瓣的形状对鸢尾花品种进行人为的预测。但我们需要的是通过电脑对数据进行准确的预测,本文通过tensorflow框架搭建神经网络,并训练以达到这个目的。接下来就是以达到这样的目的进行项目神经网络搭建。
对于数据集获取以及对数据集合进行分割形成测试集数据以及验证集数据,运用train_test_split函数对数据进行8:2的比例分割。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import tensorflow as tf
iris = load_iris()
shuffle = True 随机打乱后再进行分割数据
X_train, X_test,
y_train, y_test = train_test_split(iris.data,
iris.target, test_size=0.2, shuffle=True)
独热编码 0用[1,0,0]表示, 1用[0,1,0]表示,这样的只含有0,1的数组
y_train = tf.one_hot(y_train, 3)
y_test = tf.one_hot(y_test, 3)
模型搭建部分:这是一个比较简单的模型,用于对鸢尾花这样的小数据进行分类已经足够。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model = Sequential()
model.add(Dense(1024, input_dim=4, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(3, activation='softmax'))
model.summary()
其中用到的激活函数为softmax,这个函数专门用于多分类神经网络。输出的其中模型如下:

模型编译以及模型训练,
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, validation_data=(X_test, y_test),
epochs=30, batch_size=32, verbose=1)
对模型初步预测,对训练过程的部分数据进行保存,以及对模型保存成.h5格式,以便于后续的调用。
import pickle
score, acc = model.evaluate(X_test, y_test, batch_size=32)
print('Test score:', score)
print('Test accuracy:', acc)
with open('history.txt', 'wb', ) as file_txt:
pickle.dump(history.history, file_txt)
model.save('model.h5')
2、模型可视化分析
接下来我们对模型进行分析运用一些数据分析知识对模型的一些评估指标进行获取以及分析来查看模型的训练成果,这是一个特别重要的环节能使得我们能够了解训练的模型是否合适,以及后期对模型的进一步调参以达到要求的模型。
首先我们熟知的是模型训练过程的准确率以及损失率的变化,我们通过tensorflow的API进行获取以及绘制。
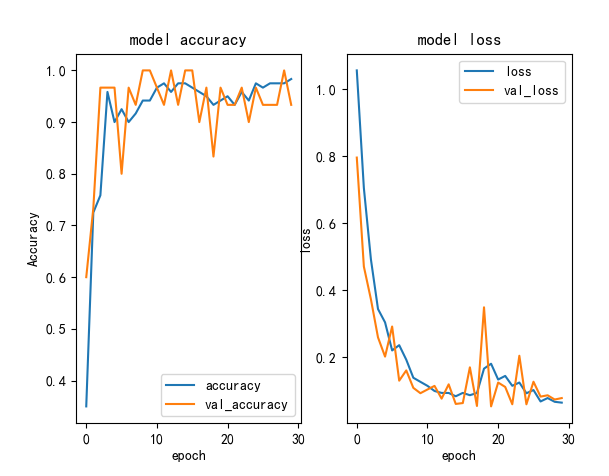
从图中我们可以发现通过迭代次数的增加准确率以及可以达到98%以上,损失也控制在5%左右以下,这说明模型的训练效果很好,达到了很高的水平。但是我们也可以发现预测的准确率以及损失波动特别大,这也说明了模型发生了过拟合现象,这是神经网络经常出现的问题,可能是我们输入模型的数据过少或者我们把更多的数据用于对模型的测试,通过这些我们可以以这个图表后续对模型进行调参。
接下来绘制出该训练模型的混淆矩阵,以直观的图表观察模型一些指标。
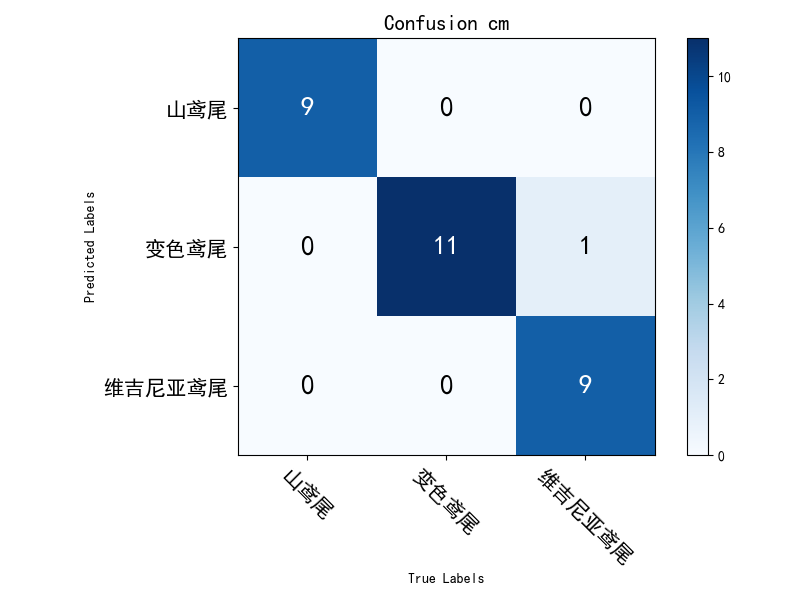
我们可以发现混淆矩阵对角线两侧几乎都为零,这是模型比较完美的表现,但是正常情况下是达不到这样的效果的,这也进一步说明我们训练的数据量以及测试的数据量太过于少,当数据量大了对角线两侧就会出现更多的预测失误的数值。通过以上混淆矩阵我们可以对模型的Precision、Recall、Specificity、F_measure进行计算,进一步评估模型指标。本文通过PrettyTable方法进行指标的统一展示,如下图:

通过这些指标我们可以可以进一步对模型进行调参以达到最优的模型,使得模型可以运用以及搭建在其他软件或者硬件上使用,发挥出其功能。
; 四、简单的模型运用
我们可以简单的运用保存的模型对一些数据进行预测,预测的效果还是相对较差,但是还是可以进一些简单的预测操作。
from tensorflow.keras.models import load_model
import numpy as np
model = load_model('model.h5')
y_pred = model.predict([[4,4,2,2],[1,4,5,10],[3,5,2,5]])
print(y_pred)
for i in y_pred:
a = np.argmax(i)
if a == 0 : print('该花为山鸢尾')
elif a == 1 : print('该花为变色鸢尾')
elif a == 2 : print('该花为维吉尼亚鸢尾')
print(y_pred[:, 0]+y_pred[:, 1]+y_pred[:, 2])
'''
输出结果
[[9.5189631e-01 4.8051883e-02 5.1872288e-05]
[2.0090450e-11 1.1240993e-06 9.9999893e-01]
[1.5872159e-03 1.0056519e-01 8.9784759e-01]]
该花为山鸢尾
该花为维吉尼亚鸢尾
该花为维吉尼亚鸢尾
[1.0000001 1. 1. ]
'''
总结
本文通过对鸢尾花数据进行一个分析以及构建简单神经网络模型进行训练,并对模型进行一些指标评估。文章所做的项目是比较简单基础的项目,其中自己觉得比较重要的是对神经网络模型各个指标的获取以及后续调参的工作。本项目更多的是让自己熟悉如何进行数据的分析以及模型构建、评估,以达到熟悉整个流程为了以后能够在接触到更难的深度学习项目时有更好的切入点,更好的思维。也希望对大家有一些帮助!其中有一些代码或者其他的可能是我借鉴其他大佬博主的,如有雷同十分抱歉!如果对您产生影响希望能告知我一下。谢谢!~ 。~
Original: https://blog.csdn.net/weixin_54730336/article/details/120346929
Author: 仍旧丶
Title: 构建神经网络对鸢尾花进行多分类分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662739/
转载文章受原作者版权保护。转载请注明原作者出处!