

1 前言
一般情况下,文本分类算法运行在各种不同软件系统的中心位置,用于规模化地处理数据。例如,电子邮件系统使用文本分类算法确定电子邮件是否是垃圾邮件,社区论坛使用分类算法确定用户发表的评论是否合法。


如上图所示,该图表示使用传统关键字检测的分类算法,其预先定于两个INBOX与SAPM FOLDER主题分类,使用CLASSIFIER分类器,将SPAM邮件过滤到SPAM FOLDER主题中,将非SPAM的正常邮件投递到INBOX主题中。
此外,其他基于情感分析的文本分类算法,该算法一般分为两个或者更多的类别:喜欢、不喜欢或者其他情感类别,该分类算法主要用在诸如Twitter社交网络场景中,分析来自用户文本内容中所属的情感类别,从而推断出用户的喜好并向用户推送其爱好的购物商品。
本文主要描述最优文本分类算法,使用TensorFlow机器学习技术框架实现,其中包括以下几个重要方面的内容:
- 使用机器学习以高层次、端到端的工作流程解决文本分类的问题
- 如何为文本分类问题选择正确的模型
- 如何使用TensorFlow实现选择的模型
文本分类算法的高层次视图可分为如下步骤,后续章节将详细描述每个步骤:

- 收集数据
- 探索数据
- 选择模型
-
准备数据
-
机器学习 构建模型 训练模型 评估模型
-
参数调优
- 部署模型
其中, 选择模型的步骤是非必要步骤,但是选择一个合适的模型对于整体算法流程起到关键的作用,可以简化后续的算法分析工作。
2 收集数据
在解决任何监督型机器学习问题的过程中,收集数据是最重要的步骤,文本分类器的精确程度取决于从收集数据中构建的数据集的优劣程度。TensorFlow为研究人员提供很多开源的数据集合用于机器学习的研究,如果研究人员需要解决某一类特定的问题,则需要自行收集对应的数据集合。其中,一些知名的社交网络也提供开放APIs,为研究人员提供渠道下载用于机器学习的数据集合,例如Twitter。
如下列举一些收集数据时,需要注意的重要事项:
- 如果使用开放APIs收集数据,则需要注意APIs的使用限制
- 收集数据的学习样本越多,则分类器的精确程度越好
- 确保每个分类的数据集合的大小都相等
- 确保收集数据的学习样本全面覆盖所有分类
本文主要使用电影网站IMDb提供的用户对电影的评价作为机器学习的学习样本,该数据集合样本分为两类,表示为积极评价或者消极评价,标识用户对电影的评价为喜欢或者不喜欢。
3 探索数据
构建模型或者训练模型只是TensorFlow其中一个步骤,在这个步骤之前理解数据的特性有助于构建更好的模型,即有助于提高分类器预测的准确程度,也就是说,数据的质量比数据的数量更加重要。
3.1 加载数据集
- 从以下连接地址下载样本数据集合
http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
- 样本数据描述如下所示:
概述
数据集合包括用户对电影的观影感受的评价,属于情感行为分析,包括两个分类标签:消极(neg)或者积极(pos)。
数据集
- 监督型机器学习的核心数据集合包括50k的电影评价,分为25k的训练数据集以及25k的测试数据集,数据集的分类标签是均衡分布,即25k的消极(neg)与25k的积极(pos)
- 非监督型机器学习的数据集合包括50k的电影评价,未对标签分类
- 监督型机器学习的核心数据集合中每部电影的总评价数不大于30(影响相关率),此外,训练数据集与测试数据集不相交,消极评价的分数不大于4分,积极评价的分数不小于7分,总数是10分,评分制度是类似于权重
- 非监督型机器学习的数据集没有什么限制
文件
两个目录,train/表示训练数据集, test/表示测试数据集,每个目录下包括两个子目录,neg/表示消极评价数据标签集,pos/表示积极评价数据标签集,其中文件格式是test/pos/200_8.txt,数字200表示文件的ID,数字8表示评价的分数
- 加载样本数据的代码如下所示:
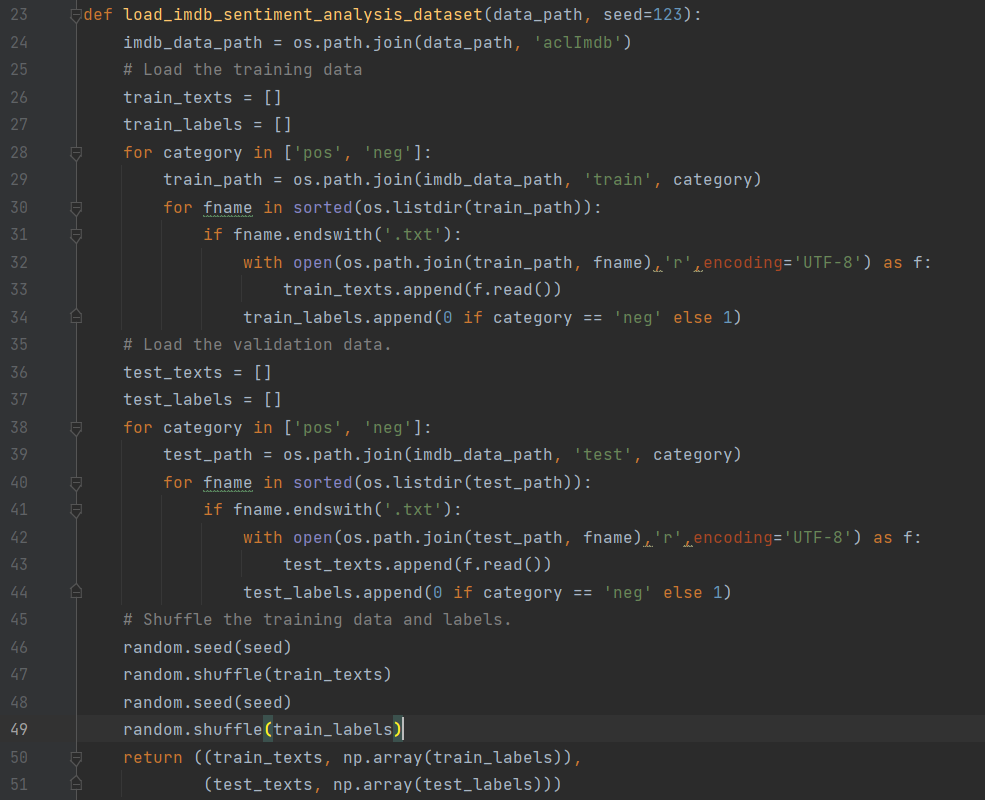
由以上的代码可知,返回训练数据集及其对应的分类标签、测试数据集及其对应的分类标签。
3.2 检查数据
数据加载完毕,需要随机抽取一些数据,并且手工检查这些数据是否与评价的标签分类保持一致,例如对应以下观众的观影评价如下所示:
“Ten minutes worth of story stretched out into the better part of two hours. When nothing of any significance had happened at the halfway point I should have left.”
…电影拍得不怎样…
很明显地,该观众的评价是消极的,对照样本数据集合中的标签分类,需要保持一致。
3.3 数据信息统计
完成上一步骤的数据随机检查,当前步骤需要汇总统计数据集的信息,这些统计信息有助于利用特征解决文本分类问题,数据统计信息包括如下所示的统计项:
数据集合中的样本总数
25000
数据集合中的样本的标签分类数
2
数据集合中的每个标签分类的样本总数
12500
数据集合中每个样本的单词数量(中间值)
174
每个单词在数据集合中的频率分布
数据集合中每个样本的单词数量的分布
统计信息的代码如下所示:

每个样本的单词总数长度分布图如下所示,x坐标表示每个样本的单词总数,y坐标表示相同单词总数的样本数:

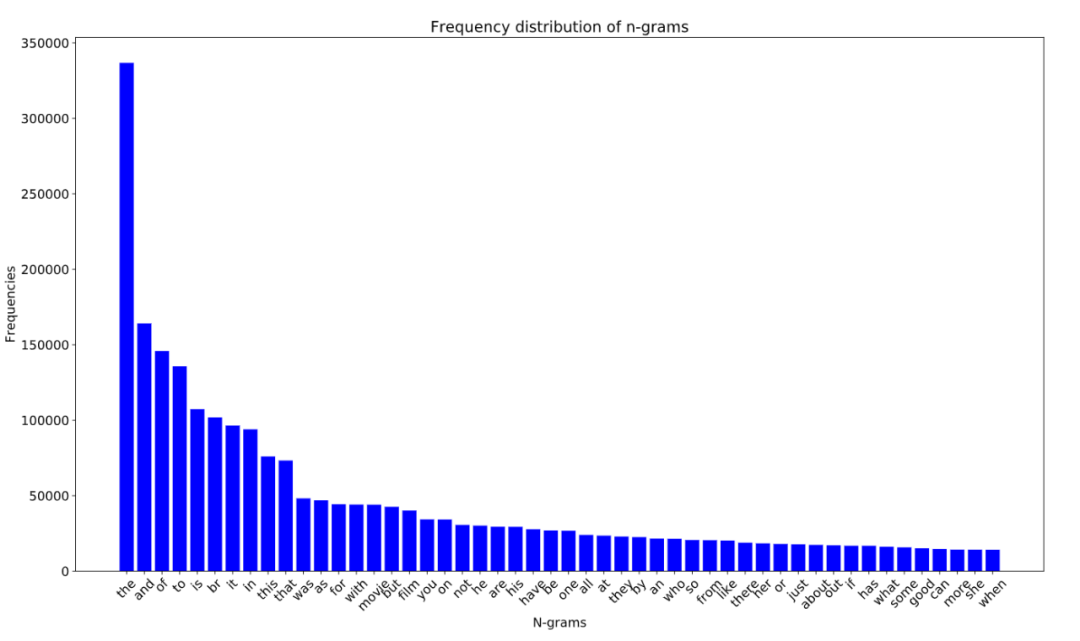
单词出现频率的分布图如下所示,x坐标表示单词,y坐标表示该单词出现的次数:
4 选择模型
前面的步骤已经实现数据收集,以及对收集的数据样本执行统计分析、探查了数据样本的特征,当前步骤主要是根据前面步骤得出的特征,选择一个合适的、高效的模型用于机器学习,那么,有待解决的问题如下所示:
问题1:
样本是非数字类型,如何为算法提供数字类型的输入?
(例如,特征向量)
问题2:
使用什么模型?
(例如,神经网络)
问题3:
为选择的模型设置什么参数?
(例如,评估函数)
对于以上的问题,可以参考一些研究机构的成熟方案,但是数据规模越大则复杂度越高,因此,需要根据实际情况选择合适的技术方案。本步骤提供的选择模型的方法,其目标是简化选择模型的过程,使模型在训练过程中最小化计算时间,同时,也最大化模型预测的准确度。
本文提供的数据处理与构建模型的算法步骤如下图所示:

对于以上的流程图,分步骤描述如下所示:
步骤1.计算上一步骤的比率R1,R1=样本总数/每个样本的单词数(中间值),本例,R1=25000/174约等于143.678,R1是上图的S/W
步骤2.假如R1小于1500,则使用n-gram算法对文本分词,并且选择MLP模型,其中n-gram表示n个单词的顺序串,在机器学习中,其逻辑是与单词的顺序相关的,也就是,单词相同,但顺序不同,则属于不同串,例如, madly truly 与 truly madly 是不同的 2-gram _,_如下显示n-gram的定义:
- bigram or 2-gram,表示的2个单词的顺序串,例如to go, go to, eat lunch, eat dinner
- trigram or 3-gram,表示的3个单词的顺序串 ,_例如 _ate too much, three smart things, the bell tolls
- 4-gram,表示的4个单词的顺序串,walk in the park, dust in the wind, the person ate lentils
在自然语言的学习中,假如用户输入three smart,则机器推测出用户下一个输入的单词很可能是 things,因为以上3-gram的列表中存在对应的单词顺序串。
MLP模型的英文全称是multi-layer perceptron,使用多层汇聚的技术模拟人类的视觉神经网络,如下图所示:

如上图所示,一个软件或者硬件系统使用该模型接受一个或者多个的输入,用函数计算输入值的权重和,从而输出单一的值,在机器学习领域中,该函数是非线性的,例如ReLU、sigmoid、tanh函数,其中sigmoid是比较常用的收敛函数,函数形式如下所示:
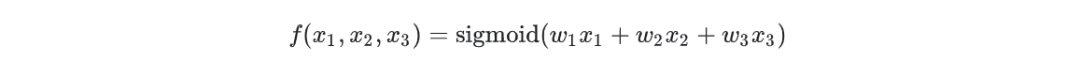
Perceptron节点接受来自权重和的输入,作为神经网络计算输入,多个perceptron组成了深度网络,在深度神经网络中,使用反向传导算法(数学定义)实现参数的优化,从而使得预测更加准确。
因此,使用n-gram以及简单的MLP模型执行以下步骤:
- 对样本分词,输出n-gram,转换n-gram为向量集
- 向量集计算分数,按照分数的排名,选择集合中的前20k条记录
- 构建MLP模型
步骤3.假如R1大于1500,对样本分词成普通的单词序列,并且使用sepCNN模型,该模型是纵深式、可分离的卷积神经网络模型,其特点是计算效率高,使用该模型的步骤如下所示:
- 对样本分词,按照单词出现的频率排序,选择前20k的单词
- 转换样本为单词序列的向量集
- 构建sepCNN模型
步骤4. 使用样本数据集合不断测量模型,对模型的参数进行调优。
综合以上4个步骤的分析,那么,得出两个关键的问题:
问题1:
应该使用哪个学习算法、应该选择哪个模型?
问题2:
应该如何准备数据,让模型高效地学习文本与分类标签之间的对应关系?
理论上,问题2的答案依赖于问题1的答案,不同模型,则需要准备输入不同格式的数据,模型可以分为两大类别:序列模型或者n-gram模型,而序列模型又可以分为卷积神经网络(CNNs)、循环神经网络(RNNs)以及其他优化变异的神经网络,n-gram模型包括逻辑回归、简单的MLPs、全连接神经网络、梯度上升树、支持向量机。
研究显示,S/W的比率值与模型的好坏程度有关。由前面的分析可知,当S/W的比率值小于1500,MLPs模型的n-gram分词输入的效果更好,MLPs模型的优点是简单易懂,而且消耗的计算时间也很少,当S/W大于等于1500,使用序列模型的效果更好。由以上的计算可知,S/W~144,因此,选择MLPs模型。
(未完待续)
Original: https://blog.csdn.net/uesowys/article/details/127013284
Author: uesowys
Title: TensorFlow之文本分类算法-1
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662685/
转载文章受原作者版权保护。转载请注明原作者出处!