

文章目录
前言
这篇文章是关于 Softmax 回归算法的总结和代码实现,Softmax 回归算法可以借助广义线性模型推导,也可以和逻辑回归作对比,将其看成逻辑回归算法在多分类问题上的一个推广。
- Softmax 回归模型
如果有一个多分类问题需要我们处理,我们假设输出变量 y y y 可能的取值为 { 1 , 2 , ⋯ , k } \left{ 1,2,\cdots ,k \right}{1 ,2 ,⋯,k } ,特征向量还是 x = ( x 0 , x 1 , ⋯ , x n ) = ( 1 , x 1 , ⋯ , x n ) x=\left( x_0,x_1,\cdots ,x_n \right) =\left( 1,x_1,\cdots ,x_n \right)x =(x 0 ,x 1 ,⋯,x n )=(1 ,x 1 ,⋯,x n ) ,这时我们应该如何预测 y y y 的取值呢?
如果我们使用广义线性模型来设计一种分类模型,那么我们就可以按照广义线性模型的流程来推导多分类问题的模型,这也就是 softmax 回归模型。不过这个模型推导稍微繁琐,也就不推导了,先看看 Logistic 回归的情况,Logistic 回归使用这样的函数当做预测值为 1 1 1 的概率:
P ( y = 1 ∣ x ; θ ) = h θ ( x ) = 1 1 + exp ( − θ T x ) P\left( y=1|x;\theta \right) =h_{\theta}\left( x \right) =\frac{1}{1+\exp \left( -\theta ^Tx \right)}P (y =1 ∣x ;θ)=h θ(x )=1 +exp (−θT x )1
这里的参数只使用了一个向量 θ \theta θ ,如果我们使用两个参数 θ 0 \theta_0 θ0 和 θ 1 \theta_1 θ1 ,使用下面的式子作为概率:
P ( y = 1 ∣ x ; θ 1 , θ 2 ) = exp ( θ 1 T x ) exp ( θ 0 T x ) + exp ( θ 1 T x ) = 1 1 + exp [ ( θ 0 T − θ 1 T ) T x ] P\left( y=1|x;\theta 1,\theta _2 \right) =\frac{\exp \left( \theta {1}^{T}x \right)}{\exp \left( \theta {0}^{T}x \right) +\exp \left( \theta {1}^{T}x \right)} \ =\frac{1}{1+\exp \left[ \left( \theta {0}^{T}-\theta {1}^{T} \right) ^Tx \right]}P (y =1 ∣x ;θ1 ,θ2 )=exp (θ0 T x )+exp (θ1 T x )exp (θ1 T x )=1 +exp [(θ0 T −θ1 T )T x ]1
如果 θ = θ 1 − θ 0 \theta =\theta 1-\theta _0 θ=θ1 −θ0 ,那么两种概率就一样了,这样做给了一种启发,对于多元分类问题,我们可以用下面的公式代表概率:
P ( y = i ∣ x ; θ ) = exp ( θ i T x ) ∑ j = 1 k exp ( θ j T x ) ( i = 1 , 2 , ⋯ , k ) P\left( y=i|x;\theta \right) =\frac{\exp \left( \theta {i}^{T}x \right)}{\sum_{j=1}^k{\exp \left( \theta {j}^{T}x \right)}}\,\, \left( i=1,2,\cdots ,k \right)P (y =i ∣x ;θ)=∑j =1 k exp (θj T x )exp (θi T x )(i =1 ,2 ,⋯,k )
其中 θ = ( θ 1 , θ 2 , ⋯ , θ k ) \theta =\left( \theta _1,\theta _2,\cdots ,\theta _k \right)θ=(θ1 ,θ2 ,⋯,θk ) ,θ i = ( θ i 0 , θ i 1 , θ i 2 , ⋯ , θ i n ) \theta _i=\left( \theta {i0},\theta {i1},\theta {i2},\cdots ,\theta {in} \right)θi =(θi 0 ,θi 1 ,θi 2 ,⋯,θi n ) ,可以这样来理解:对每一个类别 i i i ,都有一个参数 θ i \theta_i θi , θ i \theta_i θi 是特征向量 x x x 各个分量的权重,线性组合 θ i T x \theta^T_i x θi T x 越大,就说明特征向量 x x x 越有可能属于类别 i i i ,指数会放大每个线性组合 θ i T x \theta^T_i x θi T x 的差距,因此用指数作用,会使 x x x 更确定地被分到某一类别中(这句话的意思是:如果原本特征向量属于类别 i i i 的可能性最大,那么使用指数作用后,特征向量属于类别 i i i 的可能会变得更加大,以一种更大的概率分类),而分母是为了归一化,使各项加和为 1 1 1 。由上述公式很容易得到这样的公式:
P ( y ( i ) ∣ x ( i ) ; θ ) = exp ( θ y ( i ) T x ( i ) ) ∑ j = 1 k exp ( θ j T x ( i ) ) P\left( y^{\left( i \right)}|x^{\left( i \right)};\theta \right) =\frac{\exp \left( \theta {y^{\left( i \right)}}^{T}x^{\left( i \right)} \right)}{\sum_{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)}}P (y (i )∣x (i );θ)=∑j =1 k exp (θj T x (i ))exp (θy (i )T x (i ))
接下来运用极大似然估计来求解参数。对数似然函数为:
l ( θ ) = ∑ i = 1 m ln exp ( θ y ( i ) T x ( i ) ) ∑ j = 1 k exp ( θ j T x ( i ) ) = ∑ i = 1 m [ θ y ( i ) T x ( i ) − ln ∑ j = 1 k exp ( θ j T x ( i ) ) ] l\left( \theta \right) =\sum{i=1}^m{\ln \frac{\exp \left( \theta {y^{\left( i \right)}}^{T}x^{\left( i \right)} \right)}{\sum{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)}}}=\sum{i=1}^m{\left[ \theta {y^{\left( i \right)}}^{T}x^{\left( i \right)}-\ln \sum{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)} \right]}l (θ)=i =1 ∑m ln ∑j =1 k exp (θj T x (i ))exp (θy (i )T x (i ))=i =1 ∑m [θy (i )T x (i )−ln j =1 ∑k exp (θj T x (i ))]
那么 θ = a r g max θ l ( θ ) \theta =\mathop {arg\max} \limits{\theta}\,\,l\left( \theta \right)θ=θa r g max l (θ) ,最大化这样的函数的过程就是参数训练的过程。
Softmax 回归的 损失函数可以定义为对数似然函数的负数,这和 Logistic 回归类似,损失函数为:
J ( θ ) = − ∑ i = 1 m ln exp ( θ y ( i ) T x ( i ) ) ∑ j = 1 k exp ( θ j T x ( i ) ) = ∑ i = 1 m [ ln ∑ j = 1 k exp ( θ j T x ( i ) ) − θ y ( i ) T x ( i ) ] J\left( \theta \right) =-\sum_{i=1}^m{\ln \frac{\exp \left( \theta {y^{\left( i \right)}}^{T}x^{\left( i \right)} \right)}{\sum{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)}}}=\sum{i=1}^m{\left[ \ln \sum_{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)}-\theta {y^{\left( i \right)}}^{T}x^{\left( i \right)} \right]}J (θ)=−i =1 ∑m ln ∑j =1 k exp (θj T x (i ))exp (θy (i )T x (i ))=i =1 ∑m [ln j =1 ∑k exp (θj T x (i ))−θy (i )T x (i )]
Logistic 回归中有 h θ ( x ) h_{\theta}\left( x \right)h θ(x ) ,在 Softmax 回归中也有,它可以这样定义:
h θ ( x ) = [ P ( y = 1 ∣ x ; θ ) , P ( y = 2 ∣ x ; θ ) , ⋯ , P ( y = k ∣ x ; θ ) ] T = [ exp ( θ 1 T x ) ∑ j = 1 k exp ( θ j T x ) , exp ( θ 2 T x ) ∑ j = 1 k exp ( θ j T x ) , ⋯ , exp ( θ k T x ) ∑ j = 1 k exp ( θ j T x ) ] T h_{\theta}\left( x \right) =\left[ P\left( y=1|x;\theta \right) ,P\left( y=2|x;\theta \right) ,\cdots ,P\left( y=k|x;\theta \right) \right] ^T \ =\left[ \frac{\exp \left( \theta {1}^{T}x \right)}{\sum{j=1}^k{\exp \left( \theta {j}^{T}x \right)}},\frac{\exp \left( \theta {2}^{T}x \right)}{\sum_{j=1}^k{\exp \left( \theta {j}^{T}x \right)}},\cdots ,\frac{\exp \left( \theta {k}^{T}x \right)}{\sum_{j=1}^k{\exp \left( \theta _{j}^{T}x \right)}} \right] ^T h θ(x )=[P (y =1 ∣x ;θ),P (y =2 ∣x ;θ),⋯,P (y =k ∣x ;θ)]T =[∑j =1 k exp (θj T x )exp (θ1 T x ),∑j =1 k exp (θj T x )exp (θ2 T x ),⋯,∑j =1 k exp (θj T x )exp (θk T x )]T
- 优化方法
要最小化损失函数梯度下降法是机器学习中很常用的方法,可以使用梯度下降法最小化损失函数,当然也可以使用别的优化方法来优化损失函数,例如牛顿迭代法。很多优化方法都是要求解函数的导数的,所以现在对损失函数求导,先看这几项导数:
∂ θ y ( i ) T x ( i ) ∂ θ l = x ( i ) I { y ( i ) = l } \frac{\partial \theta {y^{\left( i \right)}}^{T}x^{\left( i \right)}}{\partial \theta _l}=x^{\left( i \right)}I\left{ y^{\left( i \right)}=l \right}∂θl ∂θy (i )T x (i )=x (i )I {y (i )=l }
这里的 I I I 是指示函数,I { t r u e } = 1 I\left{ true \right} =1 I {t r u e }=1 ,I { f a l s e } = 0 I\left{ false \right} =0 I {f a l s e }=0 。
∂ ln ∑ j = 1 k exp ( θ j T x ( i ) ) ∂ θ l = exp ( θ l T x ( i ) ) x ( i ) ∑ j = 1 k exp ( θ j T x ( i ) ) = P ( y ( i ) = l ∣ x ( i ) ; θ ) x ( i ) \frac{\partial \ln \sum{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)}}{\partial \theta _l}=\frac{\exp \left( \theta {l}^{T}x^{\left( i \right)} \right) x^{\left( i \right)}}{\sum_{j=1}^k{\exp \left( \theta {j}^{T}x^{\left( i \right)} \right)}}=P\left( y^{\left( i \right)}=l|x^{\left( i \right)};\theta \right) x^{\left( i \right)}∂θl ∂ln ∑j =1 k exp (θj T x (i ))=∑j =1 k exp (θj T x (i ))exp (θl T x (i ))x (i )=P (y (i )=l ∣x (i );θ)x (i )
因此损失函数的导数为:
∂ J ( θ ) ∂ θ l = ∑ i = 1 m [ P ( y ( i ) = l ∣ x ( i ) ; θ ) x ( i ) − I { y ( i ) = l } x ( i ) ] = ∑ i = 1 m [ P ( y ( i ) = l ∣ x ( i ) ; θ ) − I { y ( i ) = l } ] x ( i ) \frac{\partial J\left( \theta \right)}{\partial \theta _l}=\sum{i=1}^m{\left[ P\left( y^{\left( i \right)}=l|x^{\left( i \right)};\theta \right) x^{\left( i \right)}-I\left{ y^{\left( i \right)}=l \right} x^{\left( i \right)} \right]} \ =\sum_{i=1}^m{\left[ P\left( y^{\left( i \right)}=l|x^{\left( i \right)};\theta \right) -I\left{ y^{\left( i \right)}=l \right} \right] x^{\left( i \right)}}∂θl ∂J (θ)=i =1 ∑m [P (y (i )=l ∣x (i );θ)x (i )−I {y (i )=l }x (i )]=i =1 ∑m [P (y (i )=l ∣x (i );θ)−I {y (i )=l }]x (i )
这样,梯度下降法的核心步骤就是:
θ l ⟵ θ l − α ∑ i = 1 m [ P ( y ( i ) = l ∣ x ( i ) ; θ ) − I { y ( i ) = l } ] x ( i ) \theta l\longleftarrow \theta _l-\alpha \sum{i=1}^m{\left[ P\left( y^{\left( i \right)}=l|x^{\left( i \right)};\theta \right) -I\left{ y^{\left( i \right)}=l \right} \right] x^{\left( i \right)}}θl ⟵θl −αi =1 ∑m [P (y (i )=l ∣x (i );θ)−I {y (i )=l }]x (i )
- 代码实现
Softmax 回归类:
import numpy as np
class Softmax(object):
theta = 0
def __h(self,x):
h = np.empty(self.theta.shape[0])
for i in range(h.shape[0]):
h[i] = np.exp(np.dot(self.theta[i], x))
h = h / h.sum()
return h
def __GD(self,X, y):
X = np.insert(X, 0, 1, axis = 1)
alpha = 0.1
iter_num = 0
while True:
tmp = self.theta.copy()
H = np.empty(X.shape)
for i in range(X.shape[0]):
H[i] = self.__h(X[i])
for k in range(tmp.shape[0]):
for i in range(X.shape[0]):
tmp[k] = tmp[k] - alpha * (H[i,k] - (y[i]==k)) * X[i]
if np.allclose(self.theta, tmp, rtol = 1e-3):
break
self.theta = tmp.copy()
iter_num += 1
print("迭代次数:",iter_num)
def fit(self, X, y):
self.theta = np.zeros([np.max(y) + 1, X.shape[1] + 1])
self.__GD(X, y)
def predict(self, X):
X = np.insert(X, 0, 1, axis = 1)
y_pred = np.empty(X.shape[0])
for i in range(y_pred.shape[0]):
y_pred[i] = np.argmax(self.__h(X[i]))
return y_pred
使用该算法来看一个实例:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import confusion_matrix
X, y = make_blobs(90, 2,random_state=0,
centers=[[1,6],[6,1],[8,8]])
plt.scatter(X[:,0],X[:,1],c=y)
clf = Softmax()
clf.fit(X, y)
x1,x2=np.mgrid[-2:12:0.1,-2:12:0.1]
X_test=np.stack([x1.flat,x2.flat],axis=1)
y_pred = clf.predict(X_test)
y_pred = y_pred.reshape(x1.shape)
plt.pcolormesh(x1,x2,y_pred,alpha=0.2)
plt.show()
上述数据可视化后是这样的:
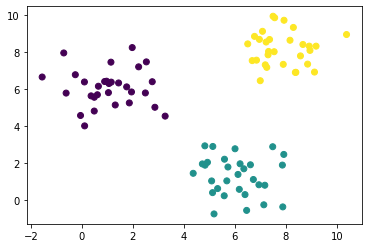

在代码中,输出变量 y y y 的取值为 { 0 , 1 , 2 } \left{ 0,1,2 \right}{0 ,1 ,2 } ,与上面的算法稍微有所不同,很多编程语言的序列下标都是从 0 0 0 开始计数的,输出变量 y y y 从 0 0 0 开始也是比较方便的。运行代码训练后,迭代次数为 24 24 2 4 ,可视化:
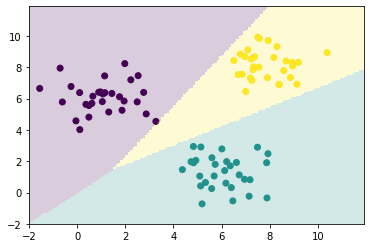
可以看到算法将所有训练数据正确分类,不过也可以看到一点,在黄色类别附近再多给几个点,算法有可能将其错误分类。
总结
Softmax 回归是一种多分类的算法,它可以说是 Logistic 回归的推广,本篇文章中就将其和 Logistic 回归作对比。它也可以使用广义线性模型进行推导。
Original: https://blog.csdn.net/qq_54434938/article/details/124237621
Author: AI研究者
Title: (五)Softmax 回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662609/
转载文章受原作者版权保护。转载请注明原作者出处!