

算法笔记更新~
引入
SVM(支持向量机),相信有一些机器学习基础的朋友对这个算法应该早已耳熟。SVM是现有的机器学习基础算法里较为能扛的一个。 此篇文章偏向实战,对svm背后繁杂而又精致的数学知识不做展开叙述,笔者学习时参考的是东大一位智慧与才情并存的教授在知乎发表的文章:零基础学习SVM,教授讲解的十分详细,引人入胜,层层递进的同时令人不禁感慨数学的美妙!如果你对svm最后的目标函数一无所知,同时又有兴趣探个究竟,强烈安利你移步上述链接。
SVM经过一番推导之后,得到的目标函数为:



对这个优化目标函数,解读为:需要找到一组α,
; SMO基本内容
在线性约束条件下优化具有多个变量的二次函数目标函数并不容易,1996年发布的序列最小最优化算法(SMO),用于训练SVM。SMO算法的目标是找出一系列α,从而得到b值,进而计算权重向量w,w与b确定后,分隔超平面也就确定了。
SMO 工作原理:每次循环中选择两个α进行优化处理,一旦找到满足 条件的两个α,就增大其中一个同时减小另外一个。 此处的条件为:(1)两个α必须要在间隔边界之外,(2)还未进行过区间处理或者不在边界上。
简化版SMO算法与 完整版SMO算法的主要区别在于α选择方式不同,完整版SMO算法是对简化版SMO算法的优化,旨在加快其运行速度。
简化版SMO: 第一个α:依次遍历数据集。 第二个α:随机选择
完整版SMO: 第一个α,选择方式在两种方式之间交替进行。(1)、在所有数据集上进行单遍扫描。(2)、在所有非边界α中实现单遍扫描。非边界α指的是那些不等于边界0或者C的α值。 第二个α:在优化过程中,会通过最大化步长的方式来获得第二个α值。此处的步长指的是两个α对应的实例的分类误差。
程序实现
简化版SMO
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
进行优化时需要调用的辅助函数
def selectJrand(i,m):
j=i
while (j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print("L==H"); continue
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print("eta>=0"); continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
print ("iter: %d i:%d, pairs changed %d"% (iter,i,alphaPairsChanged))
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print("iteration number: %d" % iter)
return b,alphas
函数功能测试
dataArr,labelArr=loadDataSet('testSet.txt')
b,alphas=smoSimple(dataArr,labelArr,0.6,0.01,40)
print(b)
print(alphas[alphas>0])
for i in range(100):
if alphas[i]>0.0:print(dataArr[i],labelArr[i])
最终输出:
[[-3.88824118]]
[[0.12674555 0.24476987 0.37151542]]
[4.658191, 3.507396] -1.0
[3.457096, -0.082216] -1.0
[6.080573, 0.418886] 1.0
完整版SMO算法:加速优化
辅助函数:
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler):
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2)))
def calcE(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*(oS.X*oS.X[k,:].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei):
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList:
if k == i: continue
Ek = calcE(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else:
j = selectJrand(i, oS.m)
Ej = calcE(oS, j)
return j, Ej
def updateE(oS, k):
Ek = calcE(oS, k)
oS.eCache[k] = [1,Ek]
优化过程
def innerL(i, oS):
Ei = calcE(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei)
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print ("L==H"); return 0
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: print("eta>=0"); return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateE(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
updateE(oS, i)
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
主函数,调用此函数即可运行完整版SMO算法
def smoPwithout_K(dataMatIn, classLabels, C, toler, maxIter):
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
else:
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print ("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet: entireSet = False
elif (alphaPairsChanged == 0): entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas
函数功能测试:
dataArr,labelArr=loadDataSet('testSet.txt')
b,alphas=smoPwithout_K(dataArr,labelArr,0.6,0.001,40)
print(b)
print(alphas[alphas>0])
for i in range(100):
if alphas[i]>0.0:print(dataArr[i],labelArr[i])
输出:
[[-2.88322544]]
[[0.1069263 0.04393521 0.0165247 0.0651882 0.05993338 0.0277492
0.03089371 0.16949654]]
[3.634009, 1.730537] -1.0
[4.658191, 3.507396] -1.0
[3.223038, -0.552392] -1.0
[3.457096, -0.082216] -1.0
[6.960661, -0.245353] 1.0
[2.893743, -1.643468] -1.0
[5.286862, -2.358286] 1.0
[6.080573, 0.418886] 1.0
计算w值:
def calcWs(alphas,dataArr,classLabels):
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
可视化
此处仅针对线性可分的数据集。(带核版的SMO不做阐述)
if __name__ == '__main__':
dataMat, labelMat = svm.loadDataSet('testSet.txt')
b,alphas=svm.smoSimple(dataMat,labelMat,0.6,0.01,40)
b,alphas =svm.smoPwithout_K(dataMat,labelMat,0.6,0.001,40)
w =svm.calcWs(alphas,dataMat, labelMat)
visual(dataMat, labelMat,w, b)
简化版SMO输出:
[[0.04892969 0.19730257 0.10204282 0.14944409 0.19883099]]
[4.658191, 3.507396] -1.0
[3.457096, -0.082216] -1.0
[2.893743, -1.643468] -1.0
[5.286862, -2.358286] 1.0
[6.080573, 0.418886] 1.0
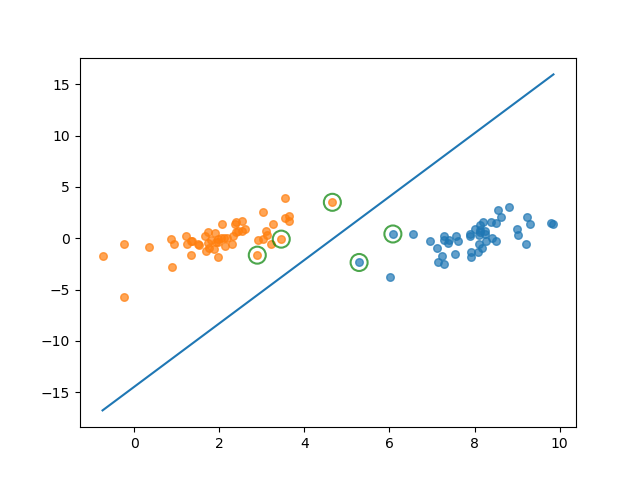
完整版SMO输出:
[[0.04916579 0.05794998 0.16680268 0.02385687 0.02385687 0.10711577
0.16680268]]
[3.634009, 1.730537] -1.0
[3.125951, 0.293251] -1.0
[3.223038, -0.552392] -1.0
[3.457096, -0.082216] -1.0
[6.960661, -0.245353] 1.0
[5.286862, -2.358286] 1.0
[6.080573, 0.418886] 1.0

以上就是SMO算法简单版及完整版的具体实现。
Original: https://blog.csdn.net/weixin_44014976/article/details/124078969
Author: 且听风吟~
Title: 采用SMO优化算法训练SVM(实战篇)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/618652/
转载文章受原作者版权保护。转载请注明原作者出处!