

Multi-Label Classification
首先分清一下multiclass和multilabel:
- 多类分类(Multiclass classification): 表示分类任务中有多个类别, 且假设每个样本都被设置了一个且仅有一个标签。比如从100个分类中击中一个。
- 多标签分类(Multilabel classification): 给每个样本一系列的目标标签,即表示的是样本各属性而不是相互排斥的。比如图片中有很多的概念如天空海洋人等等,需要预测出一个概念集合。
Challenge
多标签任务的难度主要集中在以下问题:
- 标签数量较大且基本会呈现长尾形态。
- 短视频内容标签的标准很难统一,标签系统可变,且往往类标之间相互依赖并不独立。
- absence标签占比较高,即标注的标签并不能完美覆盖所有概念面。
- 标签往往较短语义少,理解困难。
Solution
现有的方法应对multi的预测主要有2大路线:
- 改造数据适应算法:将多个类别合并成单个类别。
- 改造算法适应数据:控制激活函数阈值得到结果。
而一般研究最多的应对relation会有3种策略:
- 一阶策略:忽略和其它标签的相关性,比如把多标签分解成多个独立的二分类问题。
- 二阶策略:考虑标签之间的成对关联,比如为相关标签和不相关标签排序。
- 高阶策略:考虑多个标签之间的关联,比如对每个标签考虑所有其它标签的影响。
接下来博主主要会整理一些比较重要的论文。


[arxiv2016] Multi-label Image Classification with Regional Latent Semantic Dependencies
早期的backbone基本都是先对图像进行理解,然后通过一个label预测器得到结果。这篇文章就是属于比较经典的架构了,模型如上图,为了预测小物体,作者提出了一个区域潜在语义依赖模型(RLSD),基本就是先利用目标检测RPN得到多个依赖标签的局部区域,然后把这写区域region送到LSTM去发掘区域层次上潜在的语义依赖,最后用maxpooling得到预测结果。

[CVPR2019] Multi-Label Image Recognition with Graph Convolutional Networks
前面提到的挑战中的一点就是标签之间的关系如何挖掘,上一篇文章是尝试用LSTM来捕捉,但当GCN火爆起来的时候,Graph的结构就是十分适合建模标签之间的关系了。这篇文章就是利用GCN在多个标签之间传播信息,从而学习每个图像标签的相互依赖关系。
模型架构如上图,上半部分和通用的架构类似都是用图像特征(ResNet-101)到标签预测的pipeline,重点就是下半部分的标签关系学习,分为两点1怎么构图、2怎么优化标签节点表示:
- 构图。使用数据驱动的方法建立相关矩阵,即在数据集中挖掘标签的共现模式来定义标签之间的相关性,且共现的概率矩阵之间是有向的(人出现了但他不一定在打棒球,但是棒球出现了而人出现的概率就会比较高,所以两者的共现性并不平等)。但是这样会出现两个问题:1共现也是长尾分布,而且一些罕见的共现可能是噪声,2训练和测试中共现分布并不一致,会影响泛化能力。所以作者使用阈值τ来过滤有噪声的边,并且控制邻居的影响以免出现过度平滑,直接看代码就很清晰了:
def gen_A(num_classes, t, adj_file):
import pickle
result = pickle.load(open(adj_file, 'rb'))
_adj = result['adj']
_nums = result['nums']
_nums = _nums[:, np.newaxis]
_adj = _adj / _nums
_adj[_adj < t] = 0
_adj[_adj >= t] = 1
_adj = _adj * 0.25 / (_adj.sum(0, keepdims=True) + 1e-6)
_adj = _adj + np.identity(num_classes, np.int)
return _adj
- 优化。然后使用多层GCN进行特征优化,再参与到模型的上半部分就行了。
code:https://github.com/Megvii-Nanjing/ML-GCN
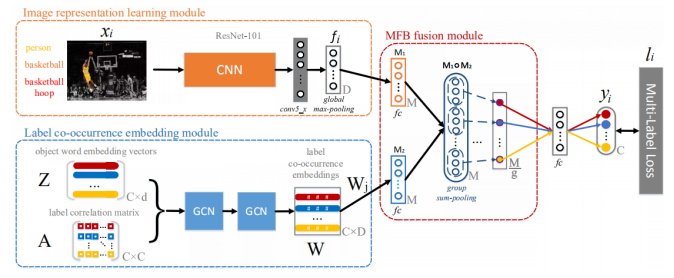
[CIKM2020] Fast Graph Convolution Network Based Multi-label Image Recognition via Cross-modal Fusion
这篇文章仍然是图像特征+label共现图,然后GCN可以得到特征,然后做融合,最后做标签预测。但是这篇文章考虑更多的是跨模态融合方面,因为比较label是文本模式,图像是视觉模式,他们天生就会有这种表达上的差异,即上图的MFB fusion module用来有效地融合图像表示和标签共现嵌入。
该模块分为两方面:1Hadmard product,2 group sum-pooling
- Hadmard product。增加了不同模态向量之间的相互作用。
- Group sum-pooling。减少过拟合和参数爆炸,加快了收敛速度。
其实也算是多模态融合里面一个放到今天相对比较常规的做法了,更多融合方法可以参考博主整理过的文章,传送门:多模态融合 。

[ICCV2019] Learning Semantic-Specific Graph Representation for Multi-Label Image Recognition
这篇文章的motivation是,由于缺乏对局部目标的监督和语义指导,现有的方法无法准确知道语义区域和它们的相互作用,也没有明确地对标签共现进行建模,所以提出了一个语义图表示学习(SSGRL)框架。
该框架由两个关键模块组成:1)语义解耦模块,包含类别语义来指导特定语义表示的学习.2)语义交互模块,将这些表示与基于统计标签共现的图相关联,并通过图传播机制探索它们之间的交互。
- 语义解耦。首先将其输入到一个全卷积的网络中,. 然后用语义引导的注意力机制对于每个类别给区域加注意力权重,以学习特定于语义的表示,即表示关注于该label类别的视觉语义区域。
- 语义交互。构图方式差不多,统计标签共现先验知识,然后图神经网络采用门控循环更新机制去图传播消息,学习上下文的节点级特征。博主自己的理解是它把原来LSTM一支的输出做到图传播中去了,每次的输出都会重新算加权重算传播,可以让语义的学习更加充分。
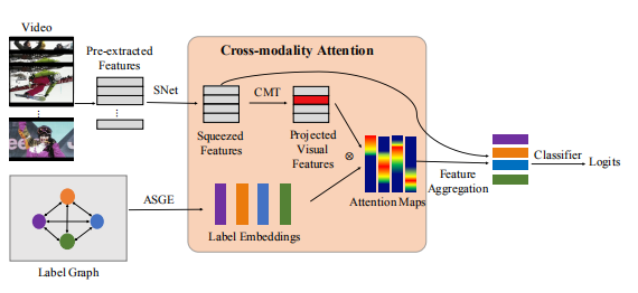
[AAAI2020] Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification
这篇文章主要是考虑到语义标签与图像内容之间的关联,以往的工作并没有对齐图像空间和标签语义之间的依赖关系。所以提出跨模态注意力(Cross-modality Attention, CMA)去充分考虑这一点。
模型架构如上图,比较突出的部分个人觉得是两个,对标签特征学习的ASGE模块和跨模态注意力对齐这里。
- 邻近相似度图表示(ASGE)。以前的工作都是基于联合的共现概率来构图的,这种方式容易受到类别失衡的影响。所以作者提出干脆直接学习label的嵌入就好,所以直接把Graph embedding的技术拿进来,博主也整理过了很多相关技术就不再赘述了。大概就是先one-hot,然后由图结构学习语义嵌入空间来得到label的表示。
- 跨模态注意力。Cross就是视觉特征对label特征计算attention,这样可以直接根据图片的特征去获得标签所应该关注的区域。
最后再classification就行了,所以其实这里的融合和对齐部分是还可以多做点事情的。
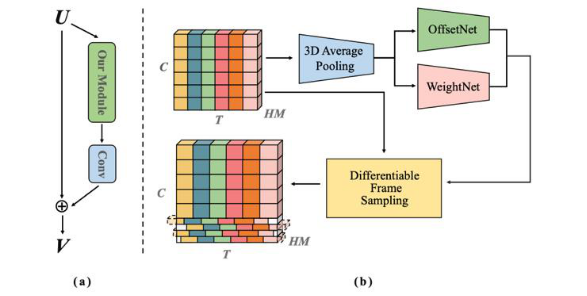
[AAAI2020] Top-1 Solution of Multi-Moments in Time Challenge 2019
ICCV19 MMIT 多标签视频理解竞赛冠军方案。这一部分就主要是在视频理解上做很多的处理,最核心的部分就是时序交错网络,即不学习时间特征,而是通过交错过去到未来以及未来到过去的空间特征来融合时-空信息。
具体的做法是固定3/4 的 channel 特征,再将余下 1/4 的特征沿着 channel 维度分为 4 组,每组会应用不同的偏移量,其中2组正向,2组反向以保证信息在时序维度上的流动是对称的,有利于后续特征的融合。
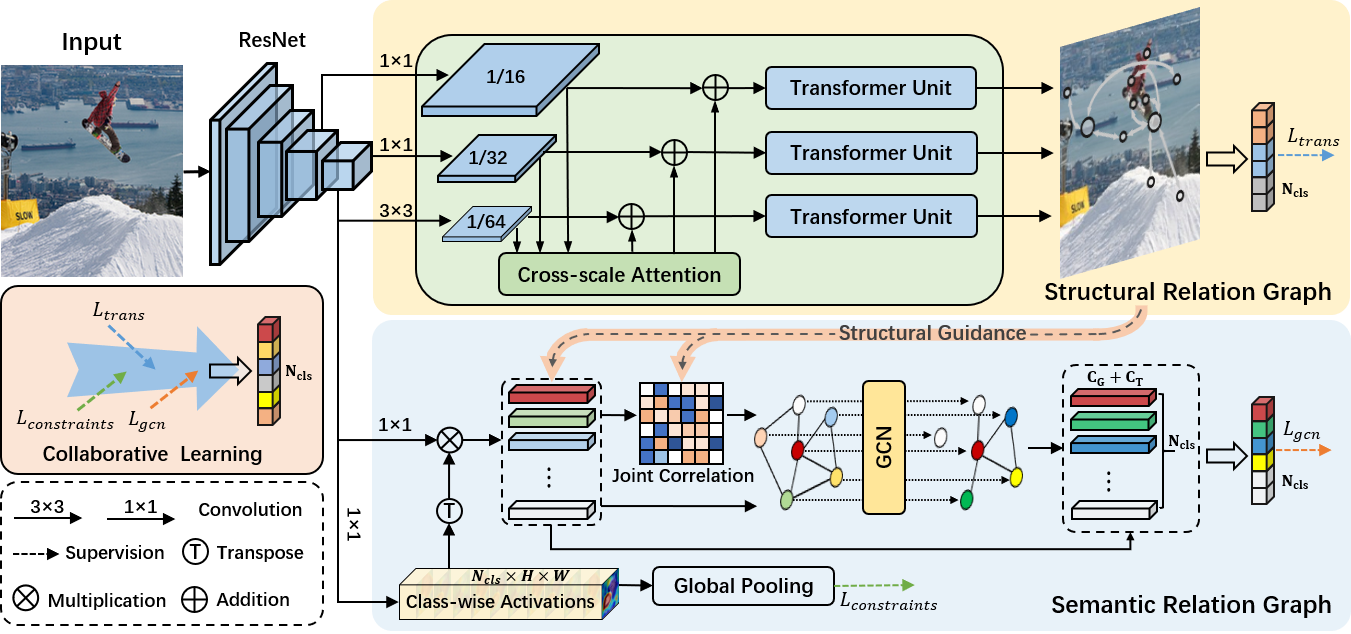
Transformer-based dual relation graph for multi-label image recognition
补上ICCV21的文章,主要是处理图像中各种对象尺度、不一致的外观和混淆的类间关系。
即现有的大多数工作主要通过学习标签共现依赖关系从而增强特征的语义表达,而忽略了图像中多个物体间的空间依赖关系。对此,本文提出一种基于Transformer的双路互补关系学习框架来联合学习空间依赖与共现依赖,通过探索相关性的两个方面,即结构关系图和语义关系图来构建互补关系。模型图如上。
- 针对空间依赖,提出跨尺度Transformer建模长距离空间上下文关联。即使用Transformer建模不同scale空间的上下文。
- 针对共现依赖,提出类别感知约束和空间关联引导,基于图神经网络联合建模动态语义关联。即利用共性关系建模基于类别gcn和空间关系的增强。
最后联合这两种互补关系进行协同学习得到鲁棒的多标签预测结果。
Original: https://blog.csdn.net/qq_39388410/article/details/114753747
Author: 上杉翔二
Title: Multi-Label Image Classification(多标签图像分类)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662496/
转载文章受原作者版权保护。转载请注明原作者出处!