

回归任务详解
- 1. 回归任务的定义
- 2. 回归任务的举例
- 3. 模型建立的步骤
* - 3.1 模型假设,选择模型框架(以线性模型为例)
– - 3.2 模型评估,如何判断众多模型的好坏(损失函数的确定)
– - 3.3 模型优化,如何筛选最优的模型(梯度下降)
– - 4.如何验证训练好的模型的好坏
- 5. 更强大复杂的模型:1元N次线性模型
- 6. 过拟合
- 7.步骤优化
* - 7.1 将多个线性模型合并成一个线性模型
- 7.2 加入更多的参数,收集更多的数据
- 7.3 进行正则化
-
回归任务的定义
找到一个函数function,通过输入的特征值X,输出一个连续的数值Scalar
- 回归任务的举例
回归任务名称输入数据输出数据股市预测过去十年股票的变动、新闻预测、并购等预测股市明天的平均值自动驾驶无人车上的各个sensor数据(路况等)方向盘的角度商品推荐商品的特性购买商品的几率宝可梦精灵攻击力预测进化前CP值,物种等进化后的CP值
- 模型建立的步骤
3.1 模型假设,选择模型框架(以线性模型为例)
3.1.1 线性模型的定义
通过对特征值的线性组合来构建模型
3.1.2 一元线性模型(单特征)
- 构建目标函数:y = w x + b y = wx + b y =w x +b
- 参数构成:w , b w, b w ,b
3.1.3 多元线性模型(多特征)
- 构建目标函数:y = w T x + b y = w^Tx + b y =w T x +b(将累加和公式转化为矩阵运算)
- 参数构成:w T , b w^T, b w T ,b(此时的w w w为一个向量,维度等于特征个数)
3.2 模型评估,如何判断众多模型的好坏(损失函数的确定)
3.2.1 收集和查看训练数据
获取到训练所需的数据集,并可以尝试着将这些数据进行一些简单的可视化(为了更方便的看出数据之间的关系以及趋势)
3.2.2 如何判断众多模型的好坏(Loss Function)
在这里,我们使用y i ^ \hat{y_i}y i ^来表示真实值,使用f ( x i ) f(x_i)f (x i )表示预测值
通过距离来衡量模型的好坏
构建损失函数(Loss Function),通过计算( y i ^ − f ( x i ) ) 2 (\hat{y_i} – f(x_i))^2 (y i ^−f (x i ))2的和的大小来衡量模型的好坏。
- 值越小,证明预测值与真实值之间的差距越小,模型越好
- 值越大,证明预测值与真实值之间的差距越大,模型越差


; 3.2.3 公式推导
假设为一元线性模型
此时目标函数为y = w x + b y = wx + b y =w x +b
Loss Function = ∑ y → 0 x → n ( y i ^ − f ( x i ) ) 2 \displaystyle \sum^{x \to n}{y \to 0}(\hat{y_i} – f(x_i))^2 y →0 ∑x →n (y i ^−f (x i ))2
= ∑ y → 0 x → n ( y i ^ − ( w x + b ) ) 2 \displaystyle \sum^{x \to n}{y \to 0}(\hat{y_i} – (wx + b))^2 y →0 ∑x →n (y i ^−(w x +b ))2
3.3 模型优化,如何筛选最优的模型(梯度下降)
3.3.1 如何筛选最优的模型 w , b w,b w ,b (梯度下降法的一般步骤)
- 首先,要设定一个学习率η \eta η(用来决定参数更新的”步长”)
- 一般步骤:
- 随机选取一个起始点w 0 w^0 w 0
- 计算当前的梯度方向,根据梯度的方向来判定移动的方向
- 大于0,向右移动(增加w w w)
- 小于0,向左移动(减小w w w)
- 根据学习率η \eta η进行移动
- 重复2和3,直至找到最低点
3.3.2 梯度下降法面对的一些问题
- 无法收敛到全局最优解,只能收敛到局部最优解
- 当梯度等于0的情况
- 当梯度约等于0的情况
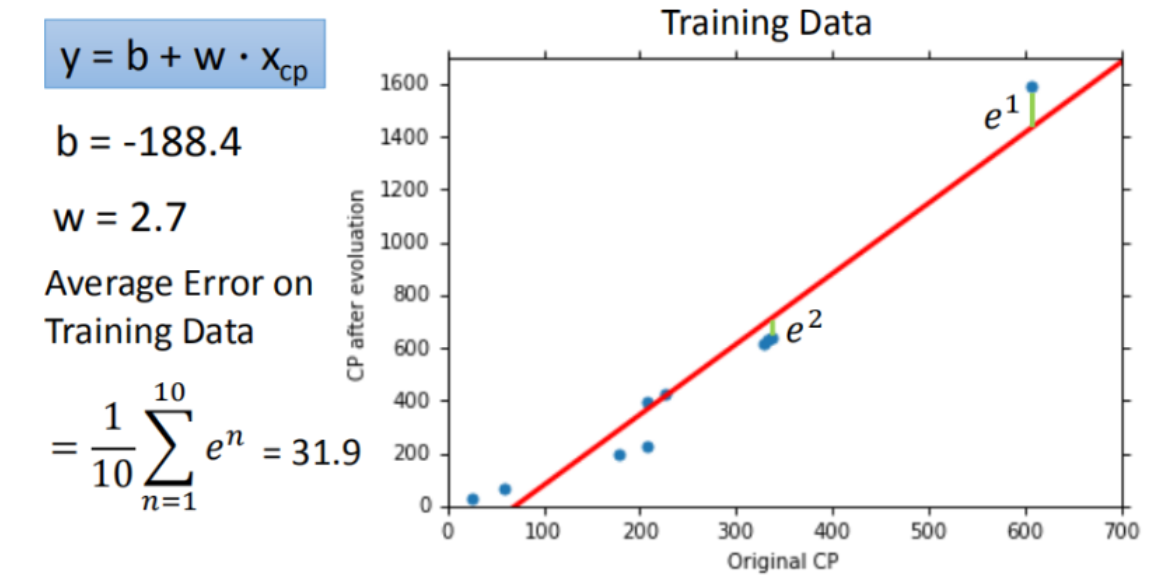
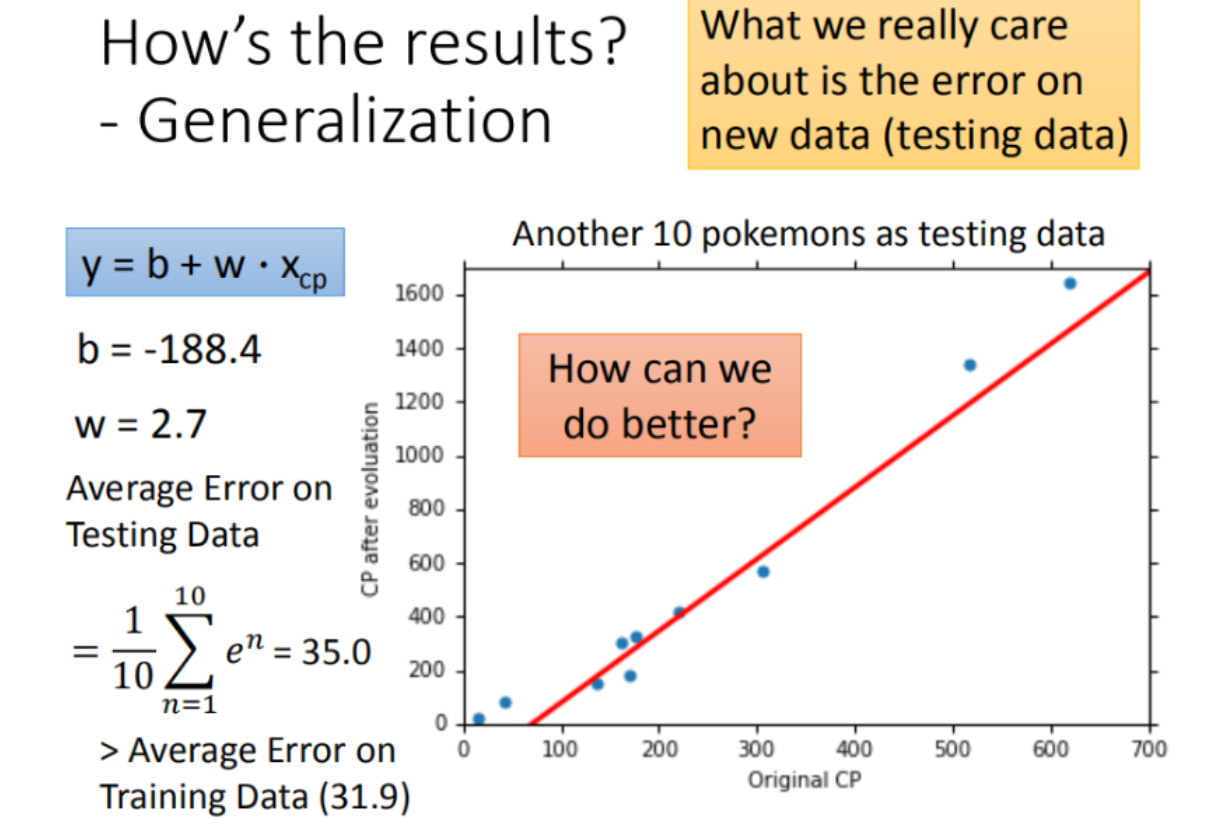
4.如何验证训练好的模型的好坏
使用训练集和测试集的平均误差
; 5. 更强大复杂的模型:1元N次线性模型
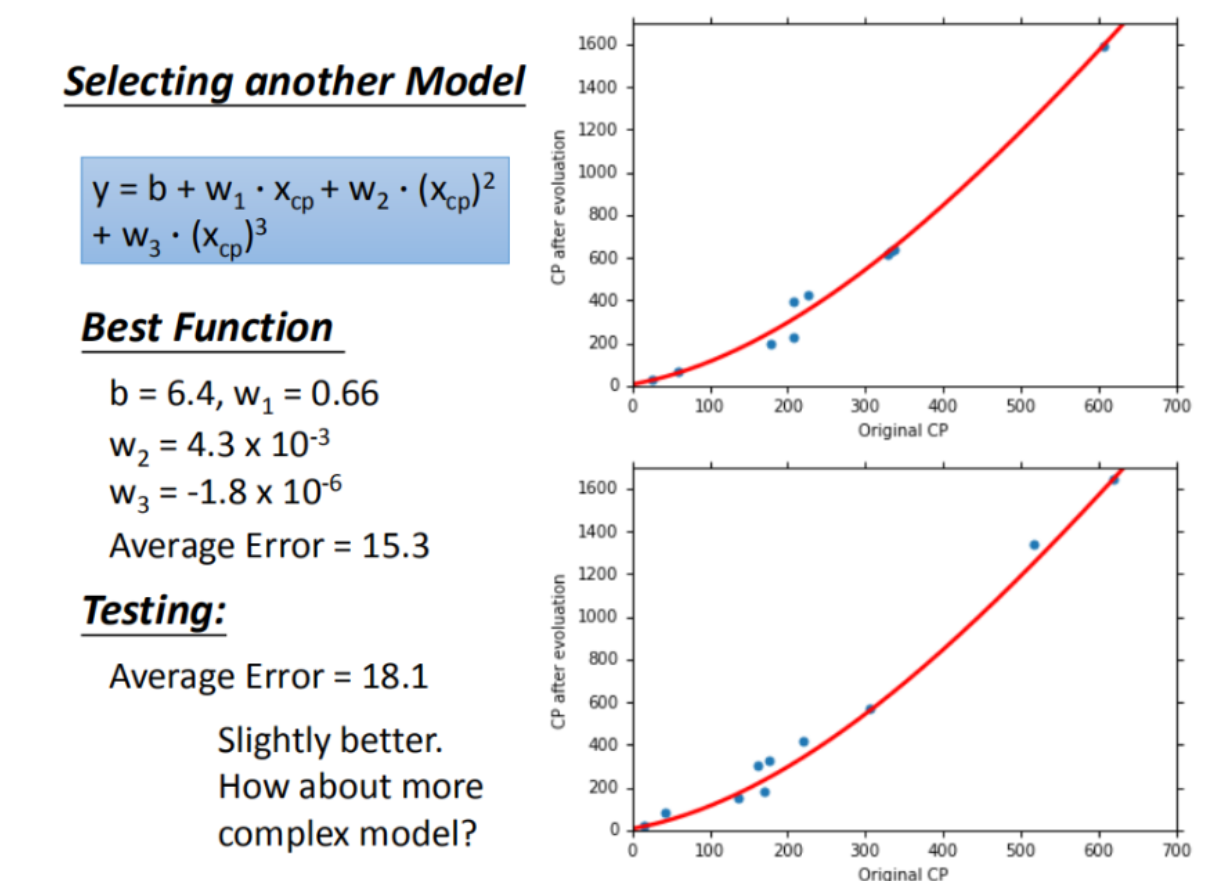
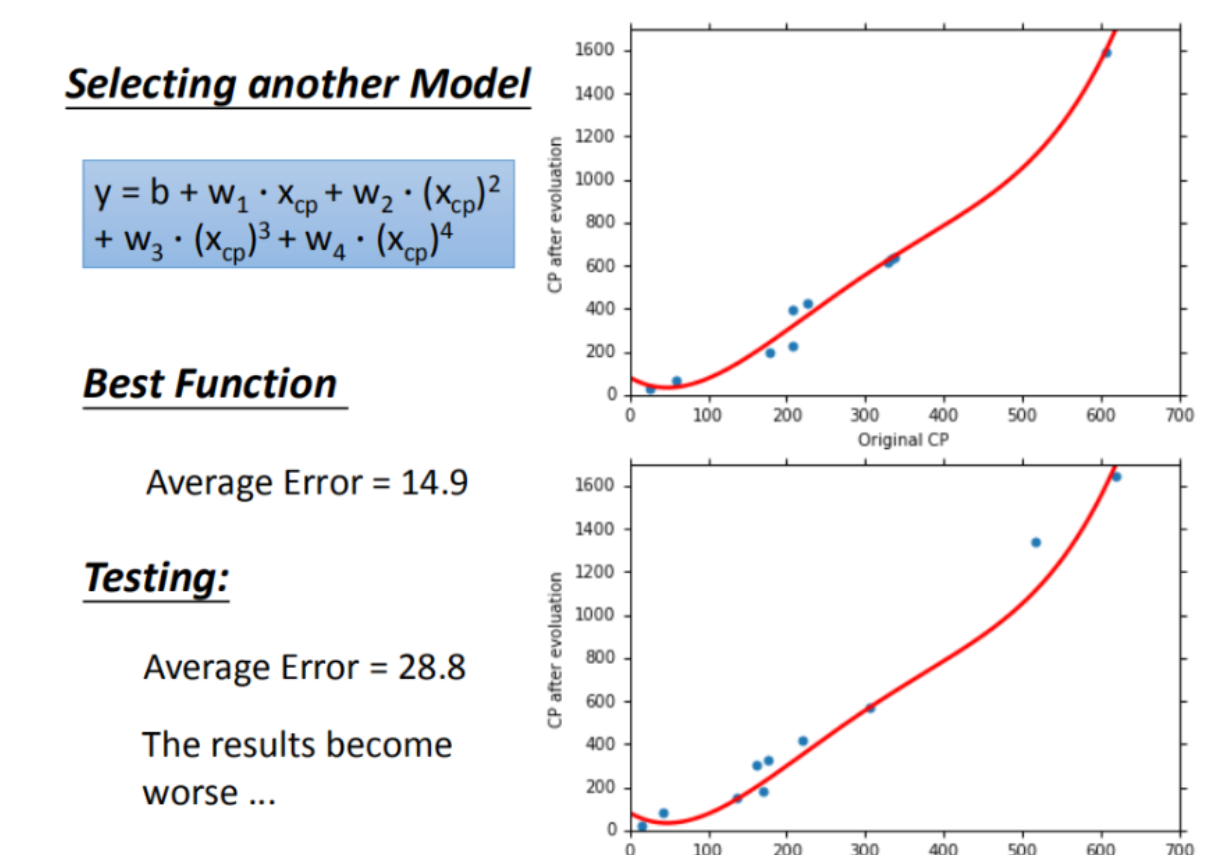
使用更高维的的线性模型通常能够更好的拟合曲线,但也会导致计算量的增加,若维度过高,便可能导致过拟合现象的产生
-
过拟合
-
产生原因:模型在学习过程中,模型把数据独有的一些特征当成实例的一般特征学习,导致模型的泛化性能下降
- 根本原因:模型的学习能力太强
- 举例说明:
随着线性模型次数的增加,模型拟合训练数据的效果越来越好,可是测试集测试的效果却大幅下降
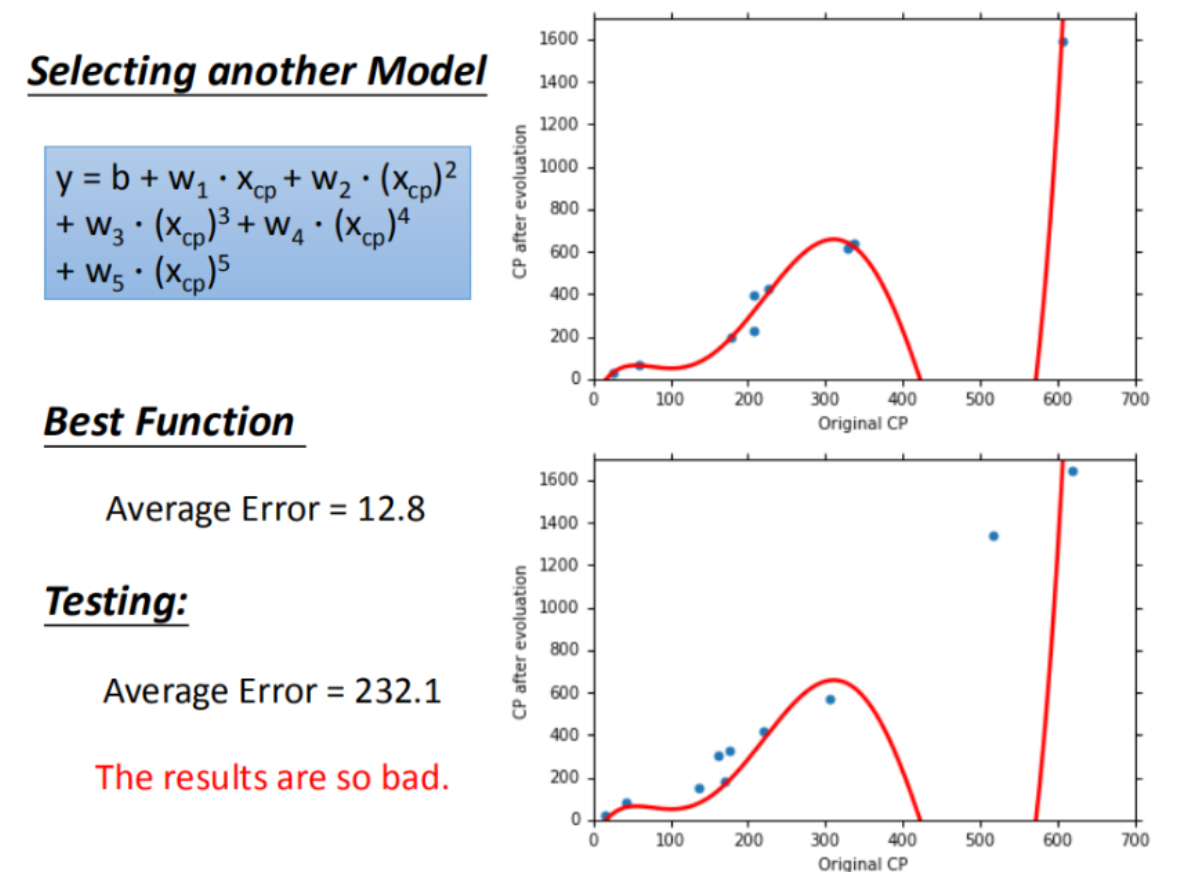
; 7.步骤优化
7.1 将多个线性模型合并成一个线性模型
7.2 加入更多的参数,收集更多的数据
7.3 进行正则化
- 目的:避免权重w w w可能会使某些特征权重过高,仍旧导致过拟合
- 注:
- w 越小,表示f u n c t i o n function f u n c t i o n较平滑的,f u n c t i o n function f u n c t i o n输出值与输入值相差不大
- 在很多应用场景中,并不是w w w越小模型越平滑越好,但是经验值告诉我们w w w越小大部分情况下都是好的。
- b b b 的值接近于0 ,对曲线平滑是没有影响
总结
本篇文章只是对回归任务的一个概述,重点描述了线性模型这个基础模型,涉及到梯度下降、正则化等公式推导部分留到以后完成
希望对你们有所帮助。
有问题的话希望指正。
谢谢!
Original: https://blog.csdn.net/Yzy_fulture/article/details/118727785
Author: Y_fulture
Title: 回归任务详解(李宏毅深度学习 task2)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/629939/
转载文章受原作者版权保护。转载请注明原作者出处!