

决策树
先构造树形结构,再进行一系列决策,决策树是分类算法,也能做回归。
比如有五个人(样本数据),打算分类谁愿意打篮球,根据年龄和性别进行决策分类。
第一次先通过其中特征进行部分选择,再在子类中根据另一个特征再分类。最后一个叶子节点就是最终分类结果。
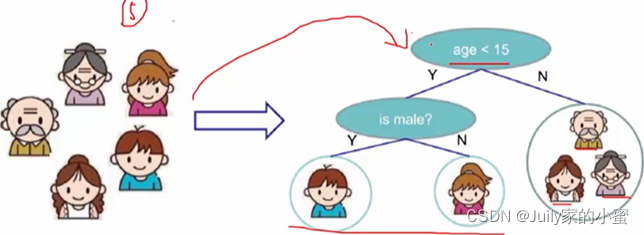

决策树算法以树状结构表示数据分类的结果。每个决策点实现一个具有离散点输出的测试函数,记为分支。

- 训练阶段
从给定的训练数据集DB,构造出一棵决策树。
Class = DecisionTree(DB) - 分类阶段
从根开始,按照决策树的分类属性逐层往下划分,直到叶节点,获得概念(决策、分类)结果。
y = DecisionTree(x)
; 衡量模型的标准
熵
越大分类效果不好(等概的时候信息熵最大,为了尽可能分类,那么需要一方的概率尽可能大,另一方尽可能小,这样信息熵和也会更小)

Gini系数

越大分类效果不好
; 构造决策树的基本思想
构造树的基本思想就是随着树深度的增加,节点的熵迅速降低,熵降低速度越快越好,这样有望得到 最矮的决策树。
假设有如下样本,如何决定哪个节点开始划分,这个时候就需要看熵了。

什么都没做的时候统计熵值,从play这个label来看

基于属性划分之后,计算熵值之和
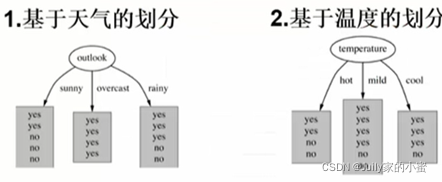



根节点选取使得信息增益最大的。现在把1当成根节点,那么接下来的选择就是选择2,3,4使得信息增益最大。

ID3(信息增益)
决策树存在的问题:如果有ID属性,最终分类结果每个ID编号都只有一个,所以分类后的熵达到最小,这样信息增益就达到最大了,但是选择ID属性作为划分显然是无效的。
所以提出了一个新的值。
C4.5:信息增益率
让算法的信息增益除以自身的熵值(以ID举例,它的自身熵值很大,所以除法之后得到的信息增益率就会变小)
如何衡量最终的决策树分类效果如何
评价函数:(希望它越小越好,作用类似于损失函数)

Nt属于叶子节点样本总数,用H(t)表示当前叶子节点熵值。
如果是连续型的属性。首先将连续型属性离散化,把每个连续型属性的值分成不同的区间,依据是比较各个分裂点Gian值(信息增益)的大小。比如如下的年龄用区间划分

下面数字序列,如果进行”二分”,那么有9个可能的分界点
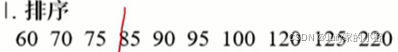
在构建决策树时,可以简单地忽略缺失数据,在计算增益时,仅考虑具有属性值的记录。

X[2]表示特征,特征分类按照小于等于2.45和大于2.45来划分。

决策树高度太高,说明有很多分支,最终所有叶子节点熵为0,每一个样本都分对,在训练集上分类效果100%。切得太碎,被异常点影响,造成 过拟合的问题。
所以要剪枝!!!防止过拟合
; 剪枝
预剪枝
在构建决策树的过程时,提前停止,边构建边剪枝
例如指定决策树深度为3,或者构建过程中,手动停止;或者样本数小于五十就提前停止。

; 后剪枝
决策树建好后,然后才开始裁剪。
构造新的损失函数,加入叶子节点个数作为约束项。

Tleaf表示叶子节点的个数,C(T)是前面讲述的评价函数。
α大,叶子节点就约束要更少一点,α小,叶子节点数量可以相对大一点。比较不分叶子节点之前和之后的损失值。就是比较剪枝和不剪枝的损失。
随机森林
构建多棵决策树,用这一片决策树去共同进行最终决策。
双重随机性:1.样本选择随机,决策树的构建从原始训练集随机选择(可能就只随机选择样本中的60%的数据,有放回采样);2.特征选择随机,也可能有异常特征,特征选择不是有放回的。决策树均选择部分特征。

Bootstraping:有放回采样
Bagging:有放回采样n个样本一共建立分类器
; 通过花萼和花瓣的长度和宽度对鸢尾花分类
from sklearn import datasets
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.75, random_state=1)
iris_data = pd.read_csv("iris.xls",error_bad_lines=False)
decision_tree_classifier = DecisionTreeClassifier()
decision_tree_classifier.fit(X_train,y_train)
m = decision_tree_classifier.score(X_test,y_test)
Original: https://blog.csdn.net/weixin_42882887/article/details/124452324
Author: Juily家的小蜜果
Title: 决策树分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662362/
转载文章受原作者版权保护。转载请注明原作者出处!