

分类任务部分半监督
一.Mixmatch( NeurIPS2019)
MixMatch: A Holistic Approach to Semi-Supervised
论文地址:https://arxiv.org/abs/1905.02249
Code:https://github.com/YU1ut/MixMatch-pytorch
1.对有标数据进行增强
2.给无标数据一个人工标签。通过对一个无标数据增强K次并输入模型得到预测结果,对K次结果进行平均并锐化(Sharpen),得到人工标签。值得注意的是,这里的标签并不是one-hot的,而是一个概率分布。
3.将增强后有标数据和K个打上人工标签的无标数据都当做是有标数据,正常进行Mixup操作。
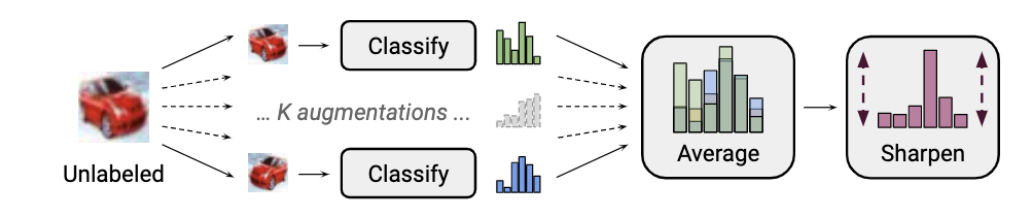

综上,MixMatch是综合 一致性正则 和 熵最小正则(smoothness/cluster assumption)的应用。
一致性正则体现在将一个无标数据增强K次后打上同样的label。
熵最小正则体现在给无标数据一个人工标签的过程。
二.Remixmatch(ICLR2020)
ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
论文地址:https://arxiv.org/abs/1911.09785
Code:https://github.com/google-research/remixmatch
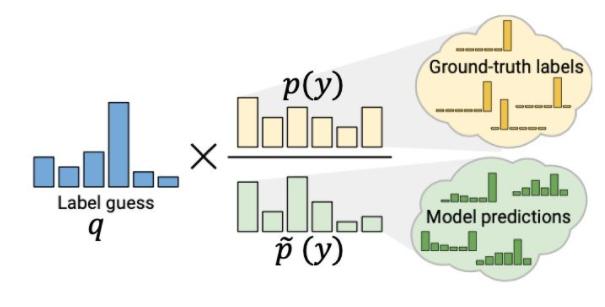
1:对MixMatch中人工标签生成过程进行改进。首先认为打标的过程中增强K次的无标数据的模型预测结果之间有分布不一致的问题,因此提出了Distribution Alignment来进行处理。
由于MixMatch的标签猜测可能存在噪声和不一致的情况,作者提出利用有标签数据的标签分布,对无标签猜测进行对齐。q是对当前无标签数据的标签猜测,
(y)是一个运行平均版本(running average)的无标签猜测, p(y) 是有标签数据的标签分布。对齐之后的标签猜测如下
并像往常一样进行sharpening和其他处理。在实践中,计算模型在过去128个批次中对未标记的例子的预测的滑动平均作为
(y)
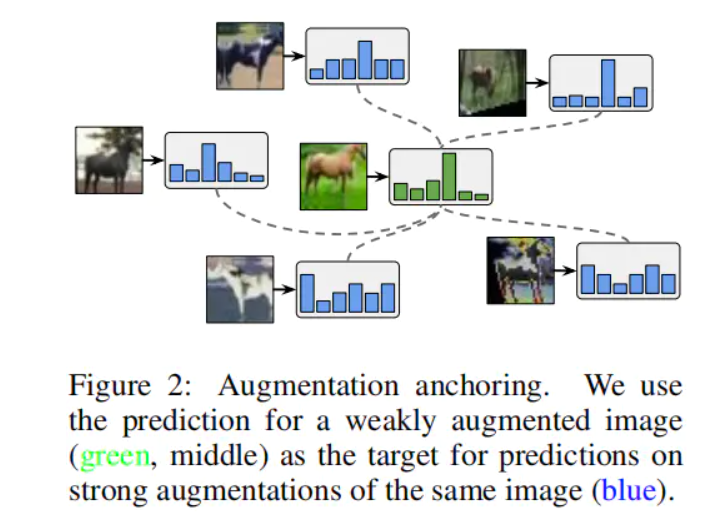
2:作者的假设是对样本进行简单增强(比如翻转和裁切)之后的预测结果,要比多次复杂变换更加可靠和稳定。因此,对于同一张图片,首先进行弱增强,得到预测结果,然后对同一张图片进行复杂的强增强。弱增强和强增强共同使用一个标签猜测 进行Mixup和模型训练。
我们假设带有自动增强的MixMatch不稳定的原因是MixMatch对K个增强的预测进行了平均。较强的增强会导致不同的预测,所以它们的平均值可能不是一个有意义的目标。相反,给定一个未标记的输入,我们首先通过对它进行弱增强来生成一个 anchoring。然后,我们使用CTAugment对同一未标记的输入生成K个强增强版本。我们使用猜测的标签(在应用distribution和sharpening之后)作为所有K个强增强版本图像的目标。
这里新加了两个loss:
Pre-mixup unlabeled loss: 将u的猜测标签和模型输出预测做一个单独的交叉熵损失
Rotation loss:最近的结果表明,将自监督学习的思想应用于半监督学习可以产生出色的性能,将这个想法通过旋转每个图像来实现,Rotate(u,r)是将图片旋转 r~0,90,180,270,然后让模型将旋转量作为四分类任务;
这里没有使用mean square loss使用了交叉熵损失,实验证明这里使用交叉熵效果更好
三:Fixmatch(NeurIPS2020)
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
论文地址:https://arxiv.org/abs/2001.07685
Code:https://github.com/kekmodel/FixMatch-pytorch
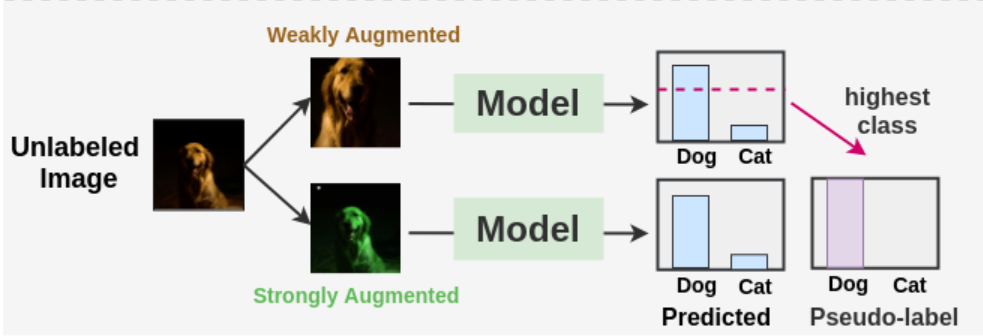
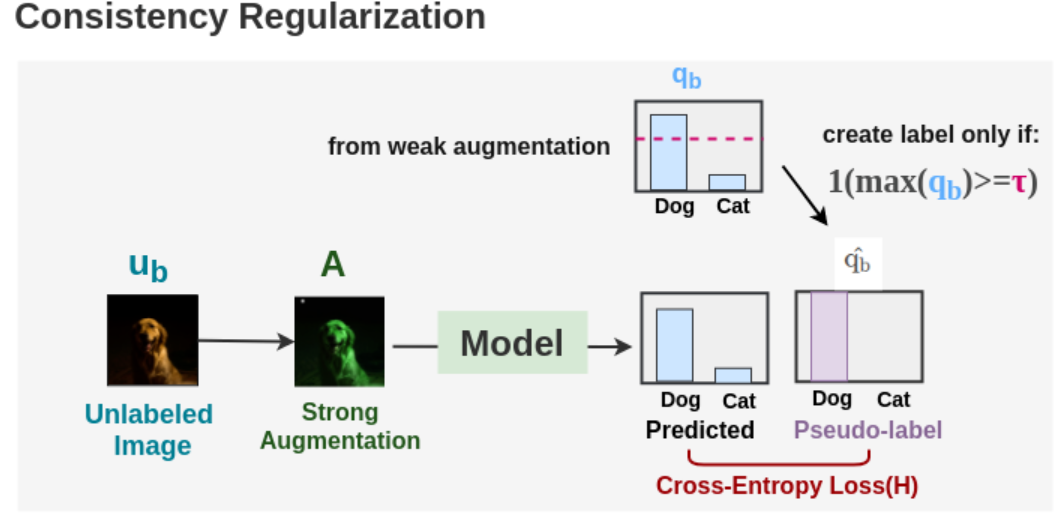
使用交叉熵损失在标注的图像上训练了监督模型,对于每个未标注的图像,使用弱增强和强增强获得两个图像。弱增强图像被传递到模型中,得到了关于类的预测。将最有信心的类别的概率与阈值进行比较。如果它高于阈值,那么我们将该类作为 ground truth 的标签,即伪标签。然后,将经过强增强的图像传递到我们的模型中,获取类别的预测。使用交叉熵损失将此概率分布与 ground truth 伪标签进行比较。两种损失组合起来进行模型的更新
四:Flexmatch(NeruIPS2021)
FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling
论文地址: https://arxiv.org/abs/2110.08263
Code:https://link.zhihu.com/?target=https%3A//github.com/TorchSSL/TorchSSL
随着模型训练而产生的伪标签往往伴随着大量错误标注,很多算法因此设定了一个 高而固定的阈值 ,来选取那些置信度高的伪标签去计算无监督损失。高阈值可以有效地降低确认偏差(confirmation bias),过滤有噪数据
像FixMatch这种固定阈值的伪标签算法存在主要的问题:
- 在训练的过程中仅仅考虑那些高置信度的样本忽视了大量的其他低置信度样本,尤其是在训练的初期,只有少数的样本能够超过设定的阈值。
- 这种算法没有考虑不同类别样本之间的学习难度,而是将所有的类别同等程度考虑。
为此提出课程伪标签(Curriculum Pseudo Labeling, CPL), 随着训练的过程动态的调整每个类别的阈值( flexible threshold),同时没有引入 额外的参数与计算量。
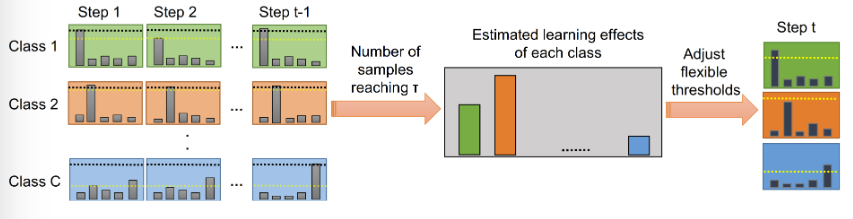
每个类别的估计学习效果是由落入这个类别并高于固定阈值的未标记数据样本的数量决定的。
(1)
表示未标注数据的预测第 c类在t时刻的学习效果,其实就是在所有样本中对高于固定阈值且属于类别c的样本的数目。
(2)注意这里归一化分母不是所有类的统计的求和,而是取所有类预估学习效果中的最大值。这样做的特点是,学的最好的类的学习效果为1,进而在应用第二个公式后,其阈值变为
,也是动态阈值的上限。
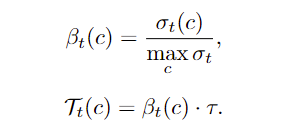
loss为:

Threshold warm-up:
在训练的早期阶段,模型可能会根据参数的初始化,盲目地将大多数未标记的样本预测为某一类别(即更可能有确认偏差)。因此,在这个阶段,估计的学习状态可能并不可靠,引入阈值预热:
“学习效果最大值”改为”学习效果最大值 和 尚未被选择过的样本数 二者的最大值”,分母的后一项为未使用的未标记数据的数量,前期,尚未被选择的样本数量占优,因此后项在起作用,随着大部分样本被选择过至少一次,前项起作用
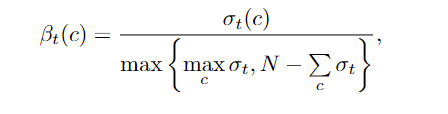
五.SimPLE(CVPR2021)
SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
论文地址:http://SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
Code:https://github.com/zijian-hu/SimPLE
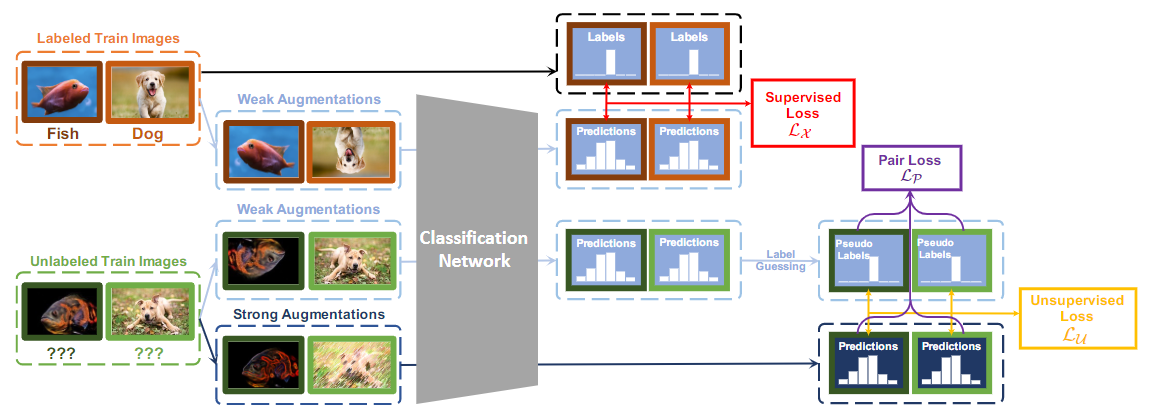
提出的SimPLE算法的概述。SimPLE用三个训练目标来优化分类网络。1)监督损失LX,用于增强的标签数据;2)无监督损失LU,将强增强的无标签数据与弱增强的数据产生的伪标签对齐;3)配对损失LP,根据强增强的数据的相似性和可信度,最小化其预测之间的统计距离
我们的算法使用增强锚定(remixmatch,fixmatch),其中伪标签来自于弱增强的样本作为 “锚”,而我们将强增强的样本与 “锚 “对齐。我们的弱增强,遵循MixMatch[2]、ReMixMatch[1]和FixMatch[26]的做法,包含一个随机裁剪,然后是一个随机地平线翻转。我们使用RandAugment[6]或一个固定的增强策略,其中包含困难的变换,如ran-dom affine和color jitter作为强增强。对于每一个批次,RandAugment从一个预定义的池中随机选择固定数量的增强;每个变换的强度由一个幅度参数决定。在我们的实验中,我们发现该方法可以很快适应高强度的增强。因此,我们简单地将幅度固定为可能的最高值
我们的伪标签是基于mixmatch中使用的标签猜测技术。我们首先将模型对同一未标记样本的几个弱增强版本的预测的平均值作为其伪标签。
由于预测是由同一输入的K个轻微扰动而不是K个严重扰动[2]或单一扰动[1,26]的平均值,猜测的伪标签应该更稳定。然后,我们使用[2]中定义的锐化操作来提高标签分布的温度。由于伪标签分布的峰值被 “锐化”,网络会将这个样本推到离决策边界更远的地方。此外,按照MixMatch[2]的做法,我们在每个时间步骤中使用模型的指数移动平均值来猜测标签
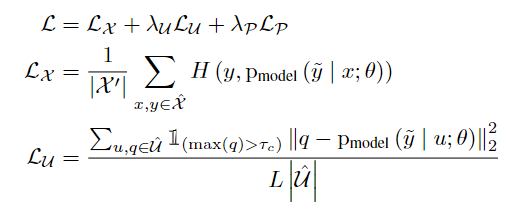
LX计算弱增强的la-beled样本的交叉熵;LU表示强增强的样本与它们的伪标签之间的L2距离,由置信度阈值来填充。请注意,LU只强制要求同一样本的不同扰动之间的一致性,而不是不同样本之间的一致性。
pairloss:
由于我们的目标是利用未标记样本之间的关系,因此我们在此引入了一个新的损失项,即配对损失,它允许信息在不同的未标记样本之间隐性传播。在配对损失中,我们使用一个高置信度的无标签点的伪标签p,作为 “chor”。所有伪标签与p足够相似的无标签样本都需要在严重扰动下将其预测与 “锚 “对齐。在这个过程中,相似性阈值以一种适应性的方式 “扩展 “了我们的置信度阈值,因为一个伪标签置信度低于阈值的样本仍然可以被损失所选择,并被推到一个更高的置信度水平。从形式上看,我们对配对损失的定义如下
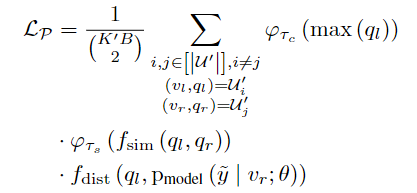
这里,τc和τs分别表示置信度阈值和模拟相似度阈值。φt(x) = ✶(x>t)x是一个由阈值t控制的硬阈值函数。 fsim (p, q) 通过Bhattacharyya系数[3]测量两个概率向量p, q之间的相似性。 该系数在[0, 1]之间有界,代表两个离散分布的重叠部分的大小。
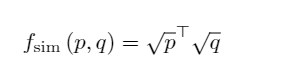
dist (p, q) 衡量两个概率向量p, q之间的距离。由于fsim (p, q) ∈ [0, 1], 我们选择距离函数为fdist (p, q) = 1 – fsim (p, q)
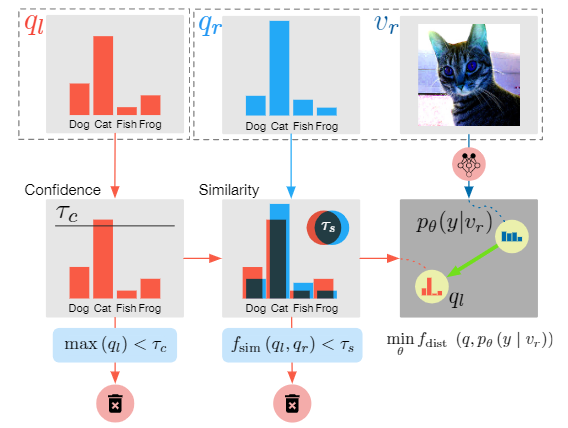
给定一个伪标签ql(红色),它是一个代表猜测的类别分布的概率向量,如果ql中的最高条目超过了置信度阈值τc,ql将成为一个 “锚”。然后,对于任何伪标签和图像元组qr(浅蓝色)和vr(深蓝色),如果ql和qr之间的重叠比例(即相似性)大于置信度阈值τs,这个元组(qr,vr)将通过将模型对vr的强增强版本的预测推到 “锚 “ql(绿色箭头)来为配对损失作出贡献。在这个过程中,如果任何一个阈值不能被满足,ql、qr、vr将被重新检测。
我们遵循MixMatch选择监督损失LX和非监督损失LU项。我们在配对损失中使用Bhattacharyya系数,因为它可以测量两个分布之间的过度搭接,并且可以更直观地选择相似性阈值τs。尽管我们认为Bhattacharyya系数比L2距离(或2-L2)更适合衡量两个分布之间的相似性,但我们在无监督损失项中保留了L2距离,以提供与MixMatch更好的比较。此外,由于交叉熵测量的是熵,而且是不对称的,所以它不是分布之间的一个好的距离测量。在我们的实验中,我们观察到带有L2配对损失的SimPLE的测试精度比原来的低0.53%。
通过把本节介绍的所有组件放在一起,我们现在介绍SimPLE算法。在训练过程中,对于一小批样本,SimPLE首先用弱增强和强增强对有标签和无标签的样本进行增强。无标签样本的伪标签是通过平均化得到的,然后对弱增强的无标签样本进行模型预测的锐化。最后,我们根据增强的样本和伪标签来优化损失项。在测试过程中,SimPLE使用模型权重的指数移动平均值来进行预测,就像MixMatch在[2]中所采用的方式。图2给出了SimPLE的概述,完整的算法在算法1中。
六.Featmatch(ECCV2020)
FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning
论文地址:https://arxiv.org/abs/2007.08505
Code:https://github.com/GT-RIPL/FeatMatch
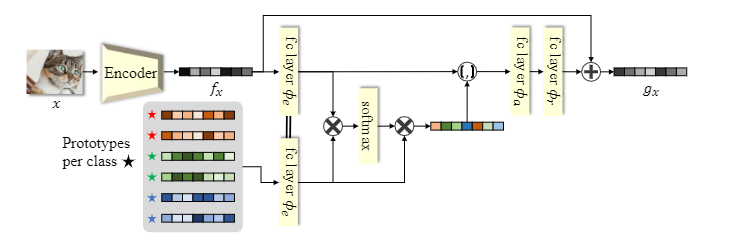
FeatMatch 中提出: 通过从其他图像的特征中提取的代表性原型的 soft-attention 来学习细化和增强输入图像特征
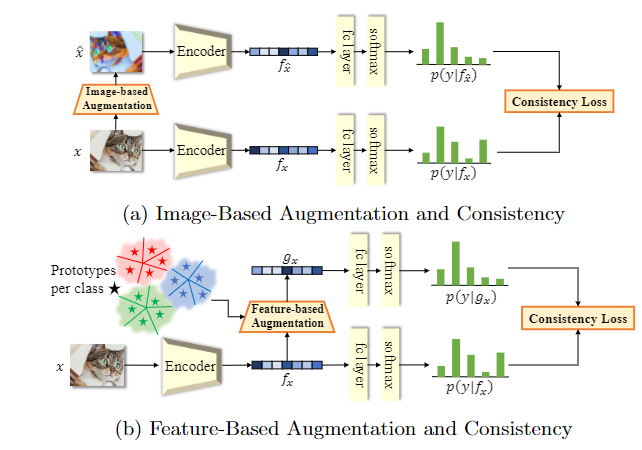
在特征空间中使用 K-Means 聚类来提取
个聚类作为每个类的原型集合. 但是, 这存在两个技术挑战:
1.在 SSL 设置中, 大多数图像为未标记状态.
2.即使所有标签都可用, 在运行K-Means 之前从整个数据集中提取所有图像的特征仍然计算量很大.
为了解决这些问题, 在训练循环的每次迭代中存储网络已经生成的特征
和伪标签 .K-Means 在每个 epoch 都进行原型提取, 最后, 特征细化和增强模块在训练循环中使用新提取的原型更新现有的原型. 基本过程如下图所示
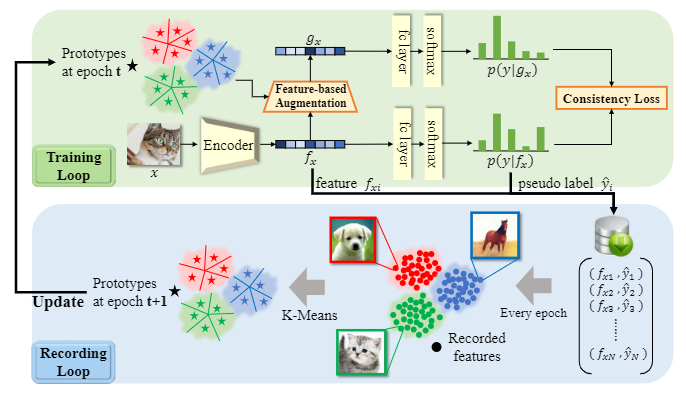
选择出的新的原型集合后, 通过 soft-attention 对原型集进行特征细化和增强

loss函数

七.UPS(ICLR2021)
In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning
论文地址:https://arxiv.org/abs/2101.06329
Code:https://link.zhihu.com/?target=https%3A//github.com/nayeemrizve/ups.
1) Positive & Negative Pseudo Label
如果大量的无标注样本被贴上错的标签并用作训练,将导致训练集中存在大量的噪声样本,从而严重影响模型的性能.以前我们都是基于阈值,来确定是否属于c类

现在我们我们定义一个变量即gc(Nagetive Learning)
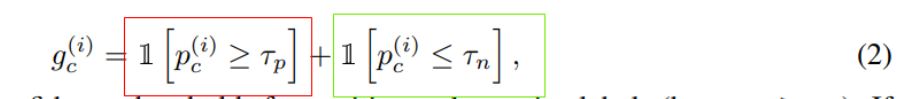
红色部分代表正样本,绿色部分代表负样本,仔细看,当预测是否属于c类的时候,如果概率高过Tp ,那么红色是1,绿色是0,gc结果是1,如果低于Tn,那么红色是0,绿色是1,gc结果还是1,基于情况即大于Tn小于Tp ,gc是0,逻辑含义就是:
gc代表的就是用不用其训练网络,当概率高过Tp即正样本置信度高,我们可以用,当低于Tn负样本置信度高,我们也可以拿来训练网络,但当处于中间时,就是不确定了,我们就不用其训练网络了,所以loss是
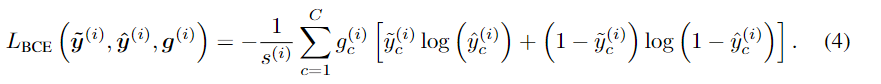
2) 基于不确定性的伪标签选择法
模型校准就是要让模型结果预测概率和真实的经验概率保持一致。说人话也就是,在一个二分类任务中取出大量(M个)模型预测概率为0.6的样本,其中有0.6M个样本真实的标签是1。总结一下,就是模型在预测的时候说某一个样本的概率为0.6,这个样本就真的有0.6的概率是标签为1。
还是在一个二分类任务中取出大量(M个)模型预测概率为0.6的样本,而这些样本的真实标签全部都是1。虽然从accuracy的角度来考察,模型预测样本概率为0.6最后输出时会被赋予的标签就是1,即accuracy是100%。但是从置信度的角度来考察,这个模型明显不够自信,本来这些全部都是标签为1的样本,我们肯定希望这个模型自信一点,输出预测概率的时候也是1
网络校正可以衡量伪标签是否可靠,而模型对单个样本的不确定性和网络校正有着一种映射关系,如下图
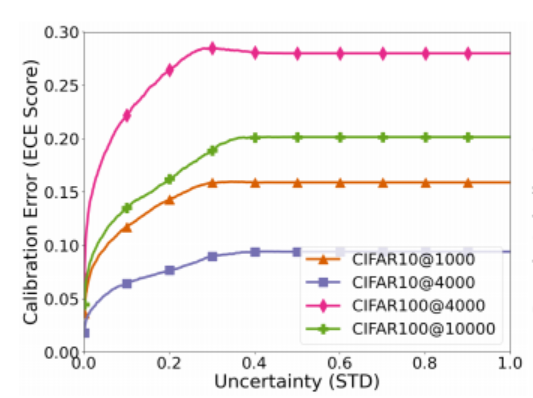
这里的纵坐标就是网络校正的量化指标即 the Expected Calibration Error (ECE) score, 看到模型对单个样本的不确定性(STD)越低,网络校正的误差就越小,所以不确定性也可以作为一种置信度,于是我们可以进一步改进loss
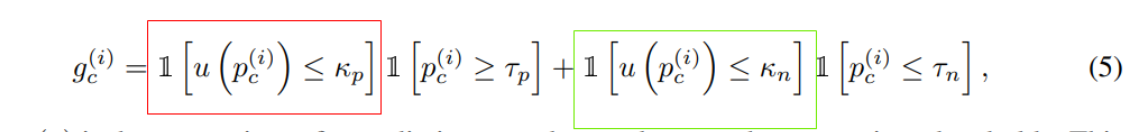
这里的u就是计算不确定性,kp和kn是正负样本不确定性的门限,直观理解就是当低于一定门限时(说明伪标签可靠),我们才用即红框和绿框才为1
总体来说分为3步:
(1) 只用有标注的数据训练一个模型;
(2) 用训练得到的模型结合UPS方法筛选出样本打伪标签;
(3) 拿打上伪标签的数据和有标注数据一起训练模型(重新随机初始化),然后跳至(2)继续执行,直至循环到最大迭代次数。之所以要重新随机初始化,是为了避免打上错误伪标签的样本带来的误差在迭代训练中不断传播
总结:
Mixmatch:作k次增强平均
Remixmatch:k次增强预测分布不一致,通过有标让无标对齐。K次强增强与一次弱增强计算loss
Fixmatch :弱增强最有信心的作为伪标签与强增强的计算loss
Flexmatch:固定阈值取伪标签存在问题,故提出动态阈值
Simple:考虑到未标记样本之间的关系
Featmatch:考虑到图像特征方面,图像与特征聚类进行特征细化和增强,再与原图计算loss
Ups:考虑到有些样本被贴上错误的标签来训练,故加入了负样本一项,来排除掉网络不确定的一些标签;另一个是关于模型校准降低误差
其中前几个都是基于数据增强,后面有些考虑到伪标签的准确性
Original: https://blog.csdn.net/qq_40950565/article/details/123181489
Author: 啥也不会就会混
Title: 半监督学习近几年相关论文解读(分类)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662334/
转载文章受原作者版权保护。转载请注明原作者出处!