

在人工智能领域,机器学习的模型及效果如何需要用各种指标来评价。本文将简单介绍几种机器学习中无监督学习的常用评价指标。无监督学习主要分为两类:分类问题与回归问题。
- 分类问题又分为二分类与多分类,输出类别值为离散型,其评价指标包含:精确率(precision),召回率(recall),准确率(accuracy),F1分数,ROC曲线和AUC曲线;
- 回归问题的输出变量为连续型,其评价指标主要包含均方误差(MSE)、平均绝对误差(MAE)、决定系数(R 2 R^2 R 2)。
文章目录
- 一、分类问题
* - 1.1、混淆矩阵
- 1.2、精确率(查准率)、召回率(查全率)、准确率、F1分数
- 1.3、ROC曲线、AUC面积
- 二、回归问题
* - 2.1、决定系数(R 2 R^2 R 2 )
- 2.2、均方误差(MSE)
- 2.3、平方根误差(RMSE)
- 2.4、平均绝对误差(MAE)
- 三、python实现评价指标的计算
* - 3.1、分类
- 3.2、回归
一、分类问题
1.1、混淆矩阵
- 首先看个例子:现有红蓝球各五个,经过模型训练后,红球中的2个被识别为蓝球,蓝球中的1个被识别为红球。这个过程我们可以用一个矩阵来表示:
真实情况分类结果红球(1)蓝球(0)红球(1)32蓝球(0)14
- 这个就叫做混淆矩阵,是一个评估分类问题常用的工具,对于 k 分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。现在我们看一下通用的二分类混淆矩阵:
真实情况分类结果正例负例正例真正例假反例负例假正例真反例
`
简称简写含义真正例TP (True Positives)实际为正例,预测也为正例真反例TN (True Negatives)实际为负例,预测也为负例假正例FP(False Positives)实际为负例,预测也为正例假反例FN(False Negatives)实际为正例,预测也为负例
1.2、精确率(查准率)、召回率(查全率)、准确率、F1分数
- 精确率:正例预测为正例的样本数在预测结果中的占比
P r e c i s i o n = T P T P + F P = 真 正 例 真 正 例 + 假 正 例 = N ( 正 → 正 ) N ( 正 → 正 ) + N ( 负 → 正 ) Precision = \frac{TP}{TP+FP} = \frac{真正例}{真正例+假正例}=\frac{N(正→正)}{N(正→正)+N(负→正)}P r e c i s i o n =T P +F P T P =真正例+假正例真正例=N (正→正)+N (负→正)N (正→正) - 召回率:正例预测为正例的样本数在原数据样本中的占比
R e c a l l = T P T P + F N = 真 正 例 真 正 例 + 假 负 例 = N ( 正 → 正 ) N ( 正 → 正 ) + N ( 正 → 负 ) Recall = \frac{TP}{TP+FN} = \frac{真正例}{真正例+假负例}=\frac{N(正→正)}{N(正→正)+N(正→负)}R e c a l l =T P +F N T P =真正例+假负例真正例=N (正→正)+N (正→负)N (正→正) - F1分数:是精确率和召回率的调和均值(2 F 1 = 1 P + 1 R \frac {2} {F_1}=\frac{1}{P} +\frac{1}{R}F 1 2 =P 1 +R 1 );当P和R都高时,F1也会高。
F 1 = 2 T P 2 T P + + F P + F N F_1 = \frac{2TP}{2TP++FP+FN}F 1 =2 T P ++F P +F N 2 T P - 准确率:预测正确(正→正,负→负)的样本数占所有样本的比例
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP+TN}{TP+TN+FP+FN}A c c u r a c y =T P +T N +F P +F N T P +T N
准确率是分类问题中最简单直观的指标,但是在实际中应用不多。原因是:当样本标签分布不均衡时,比如:正样本占比99%,只要模型把所有样本都预测为正样本,则准确率达到99%,但是实际上模型根本没有预测能力。 - 以红蓝球为例:分别计算这四个评价指标:
真实情况分类结果红球(1)蓝球(0)红球(1)32蓝球(0)14
P = N ( 红 → 红 ) N ( 红 → 红 ) + N ( 蓝 → 红 ) = 3 4 P=\frac{N(红→红)}{N(红→红)+N(蓝→红)}=\frac{3}{4}P =N (红→红)+N (蓝→红)N (红→红)=4 3 ,R = N ( 红 → 红 ) N ( 红 → 红 ) + N ( 红 → 蓝 ) = 3 5 R=\frac{N(红→红)}{N(红→红)+N(红→蓝)}=\frac{3}{5}R =N (红→红)+N (红→蓝)N (红→红)=5 3
F 1 = 2 ∗ N ( 红 → 红 ) 2 ∗ N ( 红 → 红 ) + N ( 蓝 → 红 ) + N ( 红 → 蓝 ) = 2 ∗ 3 2 ∗ 3 + 1 + 2 = 2 3 F1=\frac{2N(红→红)}{2N(红→红)+N(蓝→红)+N(红→蓝)}=\frac{23}{23+1+2}=\frac{2}{3}F 1 =2 ∗N (红→红)+N (蓝→红)+N (红→蓝)2 ∗N (红→红)=2 ∗3 +1 +2 2 ∗3 =3 2
A c c u r a c y = N ( 红 → 红 ) + N ( 蓝 → 蓝 ) N = 3 + 4 10 = 7 10 Accuracy=\frac{N(红→红)+N(蓝→蓝)}{N}=\frac{3+4}{10}=\frac {7} {10}A c c u r a c y =N N (红→红)+N (蓝→蓝)=1 0 3 +4 =1 0 7
1.3、ROC曲线、AUC面积
- 参考:一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC 这篇文章比较详细并附有动态图演示,大家可以看看。
介绍ROC曲线和AUC面积前,再了解下四个基本指标:
- 灵敏度(Sensitivity) = TP/(TP+FN) 将正例预测为正例的样本数占原数据正例样本数的比例,与召回率相等
- 特异度(Specificity) = TN/(FP+TN) 将负例预测为负例的样本数占原数据负例样本数的比例
- 真正率(TPR) = 灵敏度 = TP/(TP+FN) 将正例预测为正例的样本数占原数据正例样本数的比例
- 假正率(FPR) = 1- 特异度 = FP/(FP+TN) 将负例预测为正例的样本数占原数据负例样本数的比例
我们发现TPR和FPR分别在实际的正样本和负样本中来计算概率的。 正因为如此,所以无论样本是否平衡,都不会被影响。例如总样本中,99%是正样本,1%是负样本。如果用准确率是有水分的,但是用TPR和FPR不一样。这里,TPR只关注99%正样本中有多少是被预测正确了的,而与那1%毫无关系,同理,FPR只关注1%负样本中有多少是被预测错误了的,也与那99%毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。
- ROC曲线,又称接受者操作特征曲线,用于评价模型的预测能力,ROC曲线是基于混淆矩阵得出的。ROC曲线的两个重要指标就是真正率和假正率,其中横坐标为假正率(FPR),纵坐标为真正率(TPR),下面就是一个标准的ROC曲线图。(阈值就是一个分界点,例如某样本的特征大于某个阈值,则该样本就属于正例,否则属于负例。阈值不同,分类结果也不同,因此可以改变阈值来观察ROC曲线的变化,从而获取最优阈值进行分类。)
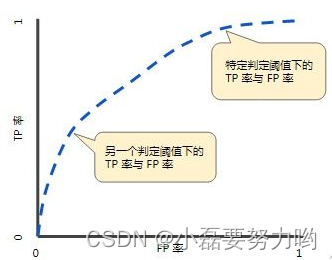

- 如何判断ROC曲线的好坏?
- 改变阈值只是不断地改变预测结果中的正负样本数,即TPR和FPR,但是曲线本身是不会变的。那么如何判断一个模型的ROC曲线是好的呢?从TPR和FPR的定义出发:TPR指的是将正例预测为正例的样本数占原数据正例样本数的比例,FPR是将负例预测为正例的样本数占原数据负例样本数的比例。我们当然希望预测的越准确越好即TPR越高越好,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。
- AUC面积曲线下面积
- 如果我们连接对角线,红线为对角线,对角线以下的阴影面积即为0.5.。对角线的实际含义是:正负样本预测正确或错误的概率应该都是50%,表示预测结果随机,此时效果应该是最差的了,所以一般AUC的值是介于0.5到1之间的。ROC曲线越陡越好,当TPR=1,FPR=0时,是我们的理想效果,但基本不能实现。(图片来自百度)

; 二、回归问题
2.1、决定系数( R 2 R^2 R 2 )
- 决定系数(coefficient of determination),也叫可决系数或拟合优度,是指在线性回归中,回归平方和与总离差平方和之比值,其数值等于相关系数的平方。它是对估计的回归方程拟合优度的度量。该统计量越接近于1,模型的拟合优度越高
R 2 = S S R S S E = ∑ i = 1 n ( y i ^ − y ‾ ) 2 ∑ i = 1 n ( y i ^ − y i ) 2 R^2=\frac{SSR}{SSE}=\frac{\sum^n_{i=1}(\hat{y_i}-\overline{y})^2}{\sum^n_{i=1}(\hat{y_i}-{y_i})^2}R 2 =S S E S S R =∑i =1 n (y i ^−y i )2 ∑i =1 n (y i ^−y )2 ,其中y i , y ‾ , y i ^ y_i,\overline{y},\hat{y_i}y i ,y ,y i ^分别为实际值,平均值,估计值。SSR,SSE分别为回归差总平方和,残差/误差总平方和。
2.2、均方误差(MSE)
- MSE是真实值与预测值的差值的平方然后求和平均。
M S E = S S E n = ∑ i = 1 n ( y i ^ − y i ) 2 n MSE=\frac{SSE}{n}=\frac{\sum^n_{i=1}(\hat{y_i}-{y_i})^2}{n}M S E =n S S E =n ∑i =1 n (y i ^−y i )2
2.3、平方根误差(RMSE)
- RMSE是对MSE的开方。
R M S E = S S E n = ∑ i = 1 n ( y i ^ − y i ) 2 n RMSE=\sqrt\frac{SSE}{n}=\sqrt\frac{\sum^n_{i=1}(\hat{y_i}-{y_i})^2}{n}R M S E =n S S E =n ∑i =1 n (y i ^−y i )2
2.4、平均绝对误差(MAE)
- MAE是预测值与实际值的差的绝对值之和求平均。
M A E = ∑ i = 1 n ∣ y i ^ − y i ∣ n MAE=\frac{\sum^n_{i=1}|\hat{y_i}-{y_i}|}{n}M A E =n ∑i =1 n ∣y i ^−y i ∣
三、python实现评价指标的计算
3.1、分类
- 混淆矩阵
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix,recall_score,accuracy_score,precision_score,f1_score,RocCurveDisplay,auc
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
x_fearures = np.array([[-1, 2], [2, 1], [3, -2], [1, 3], [-2, 1], [3, 2],[4,-7],[-5,9],[6,9],[-12,6]])
y_label = np.array([0, 0, 0, 1, 1, 1,0,1,1,1])
logr = LogisticRegression(random_state=0,solver='lbfgs')
logr.fit(x_fearures,y_label)
y_pre = logr.predict(x_fearures)
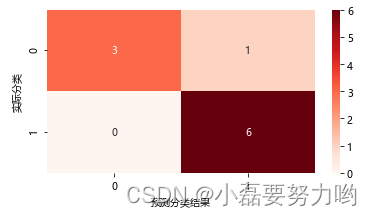
confusion_matrix = confusion_matrix(y_label,y_pre)
plt.figure(figsize=(6, 3))
sns.heatmap(confusion_matrix, annot=True, cmap='Reds')
plt.xlabel('预测分类结果')
plt.ylabel('实际分类')
plt.show()
- 评价指标
print('准确率:%0.2f' % accuracy_score(y_label,y_pre))
print('精确率:%0.2f' % precision_score(y_label,y_pre))
print('召回率:%0.2f' % recall_score(y_label,y_pre))
print('F1得分:%0.2f' % f1_score(y_label,y_pre))
准确率:0.90
精确率:0.86
召回率:1.00
F1得分:0.92
- ROC和AUC
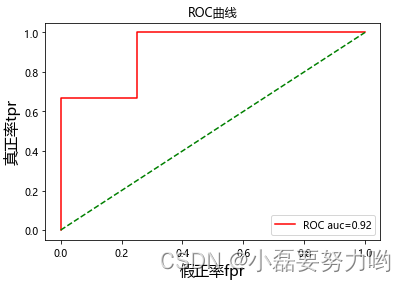
prob = logr.predict_proba(x_fearures)
prob = prob[:, 1]
fpr, tpr, thresholds = roc_curve(y_label, prob)
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, color='red', label='ROC auc=%0.2f' % roc_auc)
plt.plot([0, 1], [0, 1], color='green', linestyle='--')
plt.xlabel('假正率fpr',size=15)
plt.ylabel('真正率tpr',size=15)
plt.title('ROC曲线')
plt.legend()
plt.show()
3.2、回归
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
x = load_boston().data
y = load_boston().target
print(x.shape,y.shape)
lr = LinearRegression()
lr.fit(x,y)
print(f'回归系数为:{lr.coef_}')
print(f'截距为:{lr.intercept_}')
回归系数为:[-1.08011358e-01 4.64204584e-02 2.05586264e-02 2.68673382e+00
-1.77666112e+01 3.80986521e+00 6.92224640e-04 -1.47556685e+00
3.06049479e-01 -1.23345939e-02 -9.52747232e-01 9.31168327e-03
-5.24758378e-01]
截距为:36.459488385089855
y_pre = lr.predict(x)
print('决定系数为:%0.2f'% r2_score(y,y_pre))
print('平均绝对误差为:%0.2f' % mean_absolute_error(y,y_pre))
print('均方误差为:%0.2f' % mean_squared_error(y,y_pre))
print('均方根误差为:%0.2f' % np.sqrt(mean_squared_error(y,y_pre)))
决定系数为:0.74
平均绝对误差为:3.27
均方误差为:21.89
均方根误差为:4.68
- 分类算法看这里:
K近邻
朴素贝叶斯
逻辑回归 - 回归问题看这里:
线性回归、岭回归与Lasso回归 - 参考:
《统计学习方法 李航著》
Original: https://blog.csdn.net/m0_69435474/article/details/124586316
Author: 小磊要努力哟
Title: 机器学习之分类与回归的常见评价指标
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662307/
转载文章受原作者版权保护。转载请注明原作者出处!