

层次聚类和DBSCAN
1.层次聚类
下面这样的结构应该比较常见,这就是一种层次聚类的树结构,层次聚类是通过计算不同类别点的相似度创建一颗有层次的树结构,在这颗树中,树的底层是原始数据点,顶层是一个聚类的根节点。

创建这样一棵树的方法有自底向上和自顶向下两种方式。
下面介绍一下如何利用自底向上的方式的构造这样一棵树:
为了便于说明,假设我们有5条数据,对这5条数据构造一棵这样的树,如下是5条数据:

第一步,计算两两样本之间相似度,然后找到最相似两条数据(假设1、2两个最相似),然后将其merge起来,成为1条数据:
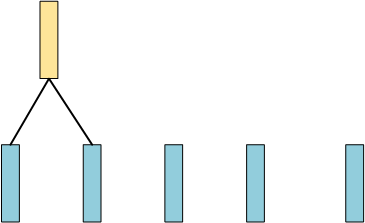
现在数据还剩4条,然后同样计算两两之间的相似度,找出最相似的两条数据(假设前两条最相似),然后再merge起来:
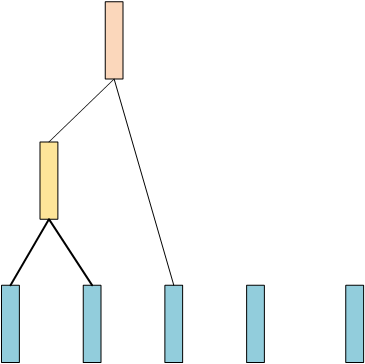
现在还剩余3条数据,然后继续重复上面的步骤,假设后面两条数据最相似,那么:
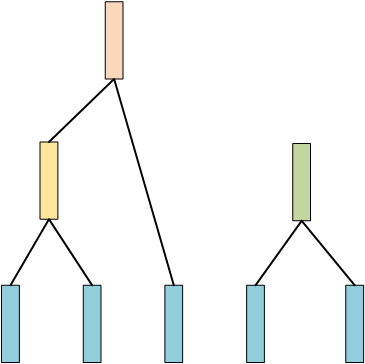
然后还剩余两条数据,再把这两条数据merge起来,最终完成一个树的构建:
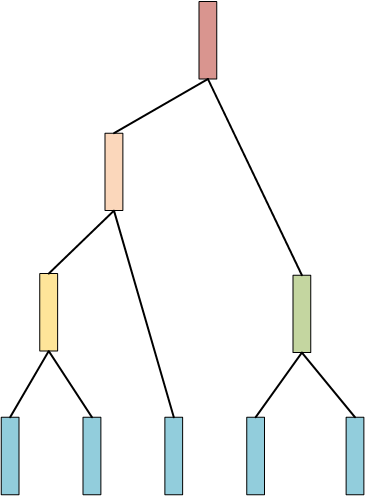
上述就是自底向上聚类树的构建过程,自顶向下的过程与之相似,只不过初始数据是一个类别,不断分裂出距离最远的那个点,知道所有的点都成为叶子结点。
那么我们如何根据这棵树进行聚类呢?
我们从树的中间部分切一刀,像下面这样:
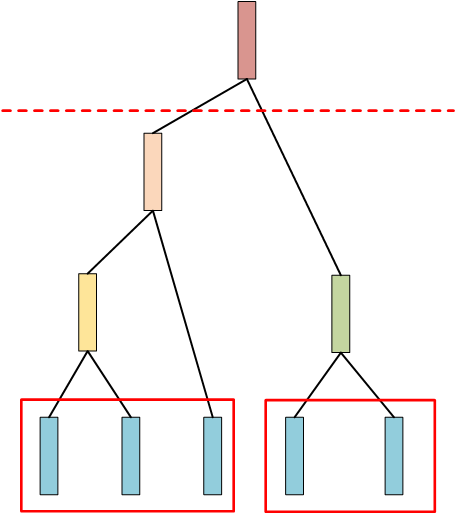
然后叶子节点被分成两个类别,也可以像下面这样切:
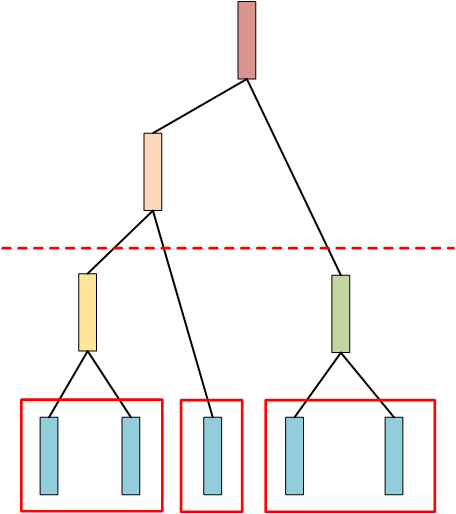
那么样本集就被分成3个类别。 这个切割的线是由一个阈值”threshold”来决定切在什么位置,而这个阈值是需要预先给定的 。
但在实做过程中,往往不需要先构建一棵树,再去进行切分,注意看上面切分,切完后,所剩余的节点数量就是类别个数。
那么在 建树的过程中,当达到所指定的类别后,则就可以停止树的建立了 。
下面看一下HAC(自底向上)的实现过程:
import math
import numpy as np
def euler_distance(point1, point2):
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a-b, 2)
return math.sqrt(distance)
定义聚类树的节点
class ClusterNode:
def __init__(self, vec, left=None, right=None, distance=-1, id=None, count=1):
"""
vec: 保存两个数据merge后新的中心
left: 左节点
right: 右节点
distance: 两个节点的距离
id: 保存哪个节点是计算过的
count: 这个节点的叶子节点个数
"""
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
self.count = count
层次聚类的类
不同于文中所说的先构建树,再进行切分,而是直接根据所需类别数目,聚到满足条件的节点数量即停止
和k-means一样,也需要指定类别数量
class Hierarchical:
def __init__(self, k=1):
assert k > 0
self.k = k
self.labels = None
def fit(self, x):
# 初始化节点各位等于数据的个数
nodes = [ClusterNode(vec=v, id=i) for i, v in enumerate(x)]
distance = {}
point_num, feature_num = np.shape(x)
self.labels = [-1] * point_num
currentclustid = -1
while len(nodes) > self.k:
min_dist = np.inf
# 当前节点的个数
nodes_len = len(nodes)
# 最相似的两个类别
closest_part = None
# 当前节点中两两距离计算,找出最近的两个节点
for i in range(nodes_len-1):
for j in range(i+1, nodes_len):
# 避免重复计算
d_key = (nodes[i].id, nodes[j].id)
if d_key not in distance:
distance[d_key] = euler_distance(nodes[i].vec, nodes[j].vec)
d = distance[d_key]
if d < min_dist:
min_dist = d
closest_part = (i, j)
part1, part2 = closest_part
node1, node2 = nodes[part1], nodes[part2]
# 将两个节点进行合并,即两个节点所包含的所有数据的平均值
new_vec = [(node1.vec[i] * node1.count + node2.vec[i] * node2.count) / (node1.count + node2.count)
for i in range(feature_num)]
new_node = ClusterNode(vec=new_vec, left=node1, right=node2, distance=min_dist, id=currentclustid,
count=node1.count + node2.count)
currentclustid -= 1
# 删掉这最近的两个节点
del nodes[part2], nodes[part1]
# 把新的节点添加进去
nodes.append(new_node)
# 树建立完成,这里要注意,在示例中是最终凝聚为1个节点,而这里到达所要指定的类别数目即停止,一个node属于一个类别
self.nodes = nodes
# 给每个node以及node包含的数据打上标签
self.calc_label()
def calc_label(self):
# 调取聚类结果
for i, node in enumerate(self.nodes):
self.leaf_traversal(node, i)
def leaf_traversal(self, node: ClusterNode, label):
# 递归遍历叶子结点
if node.left is None and node.right is None:
self.labels[node.id] = label
if node.left:
self.leaf_traversal(node.left, label)
if node.right:
self.leaf_traversal(node.right, label)
通过读取sklearn自带的鸢尾花的数据库,测试一下:
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
my = Hierarchical(4)
my.fit(iris.data)
data = iris.data
data_0 = data[np.nonzero(np.array(my.labels) == 0)]
data_1 = data[np.nonzero(np.array(my.labels) == 1)]
data_2 = data[np.nonzero(np.array(my.labels) == 2)]
data_3 = data[np.nonzero(np.array(my.labels) == 3)]
plt.scatter(data_0[:, 0], data_0[:, 1])
plt.scatter(data_1[:, 0], data_1[:, 1])
plt.scatter(data_2[:, 0], data_2[:, 1])
plt.scatter(data_3[:, 0], data_3[:, 1])
print(np.array(my.labels))
from sklearn.cluster import KMeans
km = KMeans(4)
km.fit(iris.data)
print(km.labels_)
data_0_ = data[np.nonzero(np.array(km.labels_) == 0)]
data_1_ = data[np.nonzero(np.array(km.labels_) == 1)]
data_2_ = data[np.nonzero(np.array(km.labels_) == 2)]
data_3_ = data[np.nonzero(np.array(km.labels_) == 3)]
plt.figure()
plt.scatter(data_0_[:, 0], data_0_[:, 1])
plt.scatter(data_1_[:, 0], data_1_[:, 1])
plt.scatter(data_2_[:, 0], data_2_[:, 1])
plt.scatter(data_3_[:, 0], data_3_[:, 1])
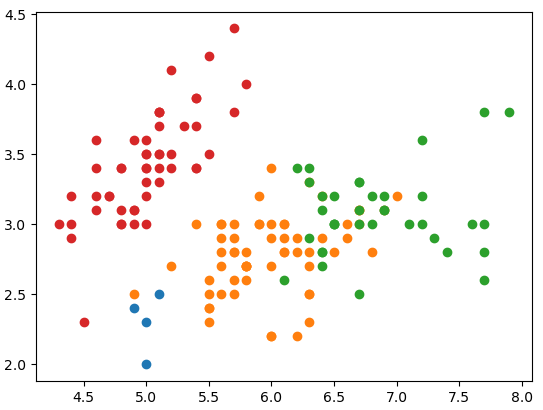
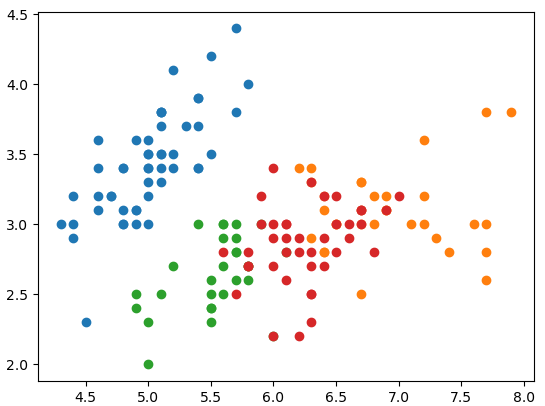
可以看到,两种结果差不多,但是也有些不同。
其实sklearn中也有层次聚类算法,上面是为了更好理解层次聚类的算法过程,下面利用sklearn库实现层次聚类算法:
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import MinMaxScaler
model = AgglomerativeClustering(n_clusters=4, affinity='euclidean', memory=None, connectivity=None,
compute_full_tree='auto', linkage='ward', pooling_func='deprecated')
"""
参数:
n_cluster: 聚类数目
affinity: 计算距离的方法,'euclidean'为欧氏距离, 'manhattan'曼哈顿距离, 'cosine'余弦距离, 'precompute'预先计算的affinity matrix;
memory: None, 给定一个地址,层次聚类的树缓存在相应的地址中;
linkage: 层次聚类判断相似度的方法,有三种:
'ward': 即single-linkage
'average': 即average-linkage
'complete': 即complete-linkage
"""
"""
属性:
labels_: 每个数据的分类标签
n_leaves_:分层树的叶节点数量
n_components:连接图中连通分量的估计值
children:一个数组,给出了每个非节点数量
"""
data_array = np.array(load_iris().data[:50, :])
min_max_scalar = MinMaxScaler()
data_scalar = min_max_scalar.fit_transform(data_array)
model.fit(min_max_scalar)
from scipy.cluster.hierarchy import linkage, dendrogram
plt.figure(figsize=(20, 6))
Z = linkage(data_scalar, method='ward', metric='euclidean')
p = dendrogram(Z, 0)
plt.show()
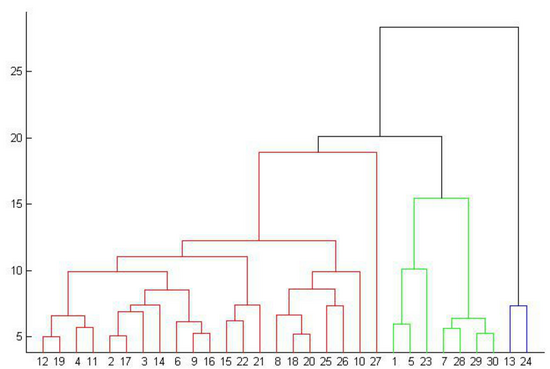
有关参数已在上面进行注释,关于类别间的距离计算,有三种:single-linkage、complete-linkage和average-linkage,一个是以最近距离作为类别间的距离,一个是以最远距离作为类间距离,还有是以各个样本距离总的平均值为类间距离。
代码后半部分是生成一个开篇说的那种图的可视化方式,限于显示需要,只取前50个数据,生成的树的结果如图所示(这里并没有分类,而是一种可视化的形式):
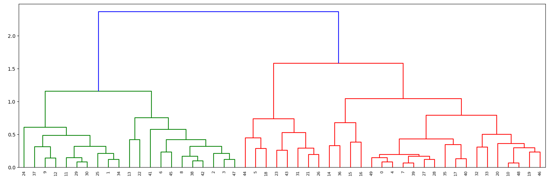
层次聚类的优缺点:
优点:
1、距离的定义比较容易,而且比较自由;
2、有时可以不用指定所需类别个数,就像前面说的,我们可以通过阈值来进行类的划分;
3、可以生成非球形的簇,发现层次间的关系。
缺点:
1、在建树过程中要计算每个样本间的距离,计算复杂度较高;
2、算法对于异常值比较敏感,影响聚类效果;
3、容易形成链状的簇。
2.DBSCAN
前面说了层次聚类算法,其实原理比较简单,但对于噪声(异常值)比较敏感,且基于距离的算法只能发现”类圆形”的簇。
另一种聚类算法 DBSCAN算法是一种基于密度的聚类算法,它能够克服前面说到的基于距离聚类的缺点,且对噪声不敏感,它可以发现任意形状的簇 。
DBSCAN的主旨思想是 只要一个区域中的点的密度大于一定的阈值,就把它加到与之相近的类别当中去 。
那么究竟是如何做呢,我们首先需要了解与DBSCAN有关的几个概念:
先看下面一张图,结合图来理解下面几个概念:
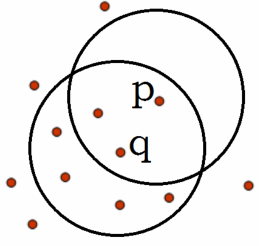
(1) ε-邻域: 一个对象在半径为ε内的区域,简单来说就是在给定一个数据为圆心画一个半径为ε的圈;
(2) 核心对象: 对于给定的一个数值m,在某个对象的邻域内,至少包含m个点,则称之为核心,简单来说就是某个对象的圈内的数据大于m个,则这个对象就是核心;
(3) 直接密度可达: 结合上图,给定一个对象q,如果这个对象的邻域内有大于m个点,而另一个对象p又在这个邻域内,则称之为p是q的直接密度可达;
(4) 间接密度可达: 如下一张图,p1是q的直接密度可达,而p是p1的直接密度可达,那么p则是q的密度可达;
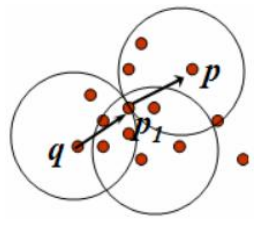
(5) 密度相连 :假设一个对象O,是对象p的密度可达,而q是O的密度可达,那么p和q则是密度相连的。
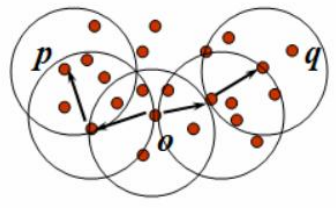
(6) 簇 :基于密度聚类的簇就是最大的密度相连的所有对象的集合;
(7) 噪声 :不属于任何簇中的对象称之为噪声;
其实上面的概念看似复杂,这里也进行了简化,原先的定义更加比较难理解,但 结合当前疫情感染情况 ,我们可以试着对上面概念进行一个类比和解释:
假设某个区域突然发现1例感染者,那么防疫人员就要对这个人轨迹进行溯源,就假设这个人的活动区域就是一个圆,那么这个圆就称为这个确诊者的 邻域 ;
然后来过该区域内的所有人员进行核酸筛查,假设发现有3个以上的确诊者,就算中高风险地区了,通过筛查发现第一个人的邻域内有5个确诊者,那么第1个病例这里称之为A,就是 核心 ;
由于这5个人都到过这个区域,那么这5个人的任意一个人都是A的 直接密度可达 。
这里注意, 直接密度可达是一个不对称的 ,可以说这5个其中一个是A的直接密度可达,但不能说第1个病例是这5个的直接密度可达,因为这5个人的活动范围只是与A有交集,但在其各自的活动范围内,并不一定都有超过3个确诊病例;
在又筛查出来5个以后,防疫人员又要进一步扩大核酸范围,那么需要分别对这另外5个人的活动范围进行排查;
经排查发现其中一个确诊者,这里称之为B,B的活动范围内有3个阳性,那么这里B就也是一个 核心 ,其中一个称之为C,不在A的邻域内,那么 C是B的直接密度可达 , C是A的间接密度可达 ;
这里注意,间接密度可达同样也是不对称的,同样的道理,可以说C是A的间接密度可达,不能说A是C的间接密度可达;
接下来,防疫人员又要对C的邻域进行排查,发现C的活动范围内也有3个确诊者,那么C也是一个 核心, 而这3个确诊者当中,有一个没有来过B的活动范围 ,称之为D;
那么,D是C的直接密度可达,D是B的间接密度可达,D是A的密度相连。密度相连是一个对称的概念,因为二者都与C有关;
然后,上面的这些人的活动区域连接起来,则就构成了整个中高风险地区,也就是一个 簇;
假设在另一个区域又突然发现一名确诊者,经排查后,如果这个确诊者也作为核心向周围扩散发现很多确诊者,那么这就形成了一个 新的簇 ;
如果其所在区除了他自己,没有别的确诊病例了,因此,这个就是属于 噪声点。
通过上面的举例,应该可以很好理解有关密度聚类的几个概念了,而且能够为后面算法的理解更容易。
那么根据上面簇的概念和所举的例子,有关DBSCAN的算法过程就比较简单理解了:

下面再举一个实际的例子,来看一下DNSCAN的算法处理过程,例子来源于水印。
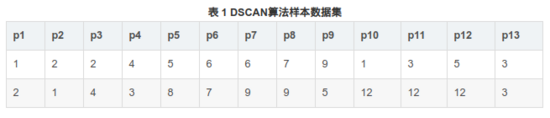
假设有一组数据,设定MinPts=3,ε=3,数据如图所示:

第一步:
首先扫描点p1(1,2),以p1为中心:
(1)p1的邻域内有点{p1,p2,p3,p13},因此p1是核心点;
(2)以p1为核心点,建立簇C1;找出所有与p1的密度可达的点;
(3)p2的邻域内为{p1,p2,p3,p4,p13},因此p4属于p1的密度可达,p4属于簇C1;
(4)p3的邻域内为{p1,p2,p3,p4,p13},这些点都已属于簇C1,继续;
(5)p4的邻域内为{ p3,p4,p13 },这些点也都属于簇C1,继续;
(6)p13的邻域内为{p2,p3,p4,p13},也都处理过了
至此,以p1为核心的密度可达的数据点搜索完毕,得到簇C1,包含{ p1,p2,p3,p13,p4 }
第二步:
继续扫描点,到p5,以p5为中心:
(1)计算p5邻域内的点{ p5,p6,p7,p8 },因此p5也是核心点;
(2)以p5为核心点 ,建立簇C2,找出所有与p5的密度可达的点;
(3)同第一步中一样,依次扫描p6、p7、p8;
得到以p5为核心点的簇C2,包含的点为{ p5,p6,p7,p8 }。
第三步:
继续扫描点,到点p9,以p9为中心:
(1)p9的邻域内的点为{p9},所以p9b不是核心点,进行下一步
第四步:
继续扫描点,到点p10,以p10为中心:
(1)p10的领域内的点为{ p10,p11 },所以p10不是核心点,进行下一步。
第五步:
继续扫描到点p11,以p11为中心:
(1)计算p11邻域内的点为{ p11,p10,p12 },所以p11是核心点;
(2)以p11为核心点建立簇C3,找出所有的密度可达点;
(3)p10已被处理处理过,继续扫描;
(4)扫描p12,p12邻域内{ p12,p11 };
至此,p11的密度可达点都搜索完毕,形成簇C3,包含的点为{ p11,p10,p12 }
第六步:
继续扫描点,p12,p13都已被处理过,至此所有点都被处理过,算法结束。
下面对DBSCAN进行算法的实现,首先是算法的步骤实现,然后再用sklearn进行实现:
import numpy as np
import random
import matplotlib.pyplot as plt
import copy
from sklearn import datasets
搜索邻域内的点
def find_neighbor(j, x, eps):
"""
:param j: 核心点的索引
:param x: 数据集
:param eps:邻域半径
:return:
"""
temp = np.sum((x - x[j]) ** 2, axis=1) ** 0.5
N = np.argwhere(temp <= eps).flatten().tolist() return n def dbscan(x, eps, minpts): k="-1" # 保存每个数据的邻域 neighbor_list="[]" 核心对象的集合 omega_list="[]" 初始化,所有的点记为未处理 gama="set([x" for x in range(len(x))]) cluster="[-1" _ range(len(x))] i range(len(x)): neighbor_list.append(find_neighbor(i, x, eps)) if len(neighbor_list[-1])>= MinPts:
omega_list.append(i)
omega_list = set(omega_list)
while len(omega_list) > 0:
gama_old = copy.deepcopy(gama)
# 随机选取一个核心点
j = random.choice(list(omega_list))
# 以该核心点建立簇Ck
k = k + 1
Q = list()
# 选取的核心点放入Q中处理,Q中只有一个对象
Q.append(j)
# 选取核心点后,将核心点从核心点列表中删除
gama.remove(j)
# 处理核心点,找出核心点所有密度可达点
while len(Q) > 0:
q = Q[0]
# 将核心点移出,并开始处理该核心点
Q.remove(q)
# 第一次判定为True,后面如果这个核心点密度可达的点还有核心点的话
if len(neighbor_list[q]) >= MinPts:
# 核心点邻域内的未被处理的点
delta = set(neighbor_list[q]) & gama
delta_list = list(delta)
# 开始处理未被处理的点
for i in range(len(delta)):
# 放入待处理列表中
Q.append(delta_list[i])
# 将已处理的点移出标记列表
gama = gama - delta
# 本轮中被移除的点就是属于Ck的点
Ck = gama_old - gama
Cklist = list(Ck)
# 依次按照索引放入cluster结果中
for i in range(len(Ck)):
cluster[Cklist[i]] = k
omega_list = omega_list - Ck
return cluster
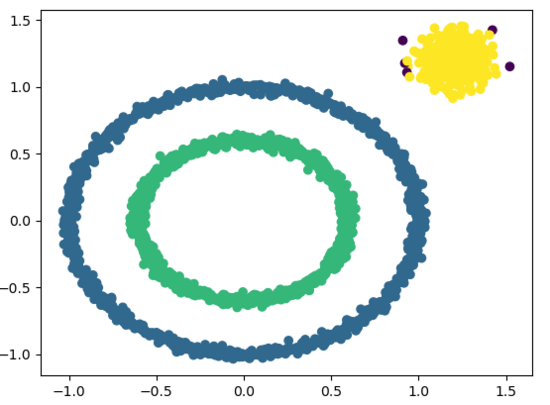
X1, y1 = datasets.make_circles(n_samples=2000, factor=.6, noise=.02)
X2, y2 = datasets.make_blobs(n_samples=400, n_features=2, centers=[[1.2, 1.2]], cluster_std=[[.1]], random_state=9)
X = np.concatenate((X1, X2))
eps = 0.08
min_Pts = 10
C = DBSCAN(X, eps, min_Pts)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=C)
plt.show()</=>
运行结果如图所示:
然后就是利用sklearn中的DBSCAN类进行实现:
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.08, min_samples=10, metric='euclidean', algorithm='auto')
"""
eps: 邻域半径
min_samples:对应MinPts
metrics: 邻域内距离计算方法,之前在层次聚类中已经说过,可选有:
欧式距离:“euclidean”
曼哈顿距离:“manhattan”
切比雪夫距离:“chebyshev”
闵可夫斯基距离:“minkowski”
带权重的闵可夫斯基距离:“wminkowski”
标准化欧式距离: “seuclidean”
马氏距离:“mahalanobis”
algorithm:最近邻搜索算法参数,算法一共有三种,
第一种是蛮力实现‘brute’,
第二种是KD树实现‘kd_tree’,
第三种是球树实现‘ball_tree’,
‘auto’则会在上面三种算法中做权衡
leaf_size:最近邻搜索算法参数,为使用KD树或者球树时, 停止建子树的叶子节点数量的阈值
p: 最近邻距离度量参数。只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。
"""
model.fit(X)
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=model.labels_)
plt.show()
上面一些参数是需要调的,如eps和MinPts,基于 密度聚类对这两个参数敏感。
关于DBSCAN的优缺点:
优点
1、不必指定聚类的类别数量;
2、可以形成任意形状的簇,而K-means只适用于凸数据集;
3、对于异常值不敏感;
缺点:
1、计算量较大,对于样本数量和维度巨大的样本,计算速度慢,收敛时间长,这时可以采用KD树进行改进;
2、对于eps和MinPts敏感,调参复杂,需要联合调参;
3、 样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN 算法一般不适合;
4、样本同采用一组参数聚类,有时不同的簇的密度不一样,有人提出OPTICS聚类算法(有空会把这一算法补上);
5、由于对噪声不敏感,在一些领域,如异常检测不适用。
Original: https://blog.csdn.net/Python_xiaowu/article/details/121983688
Author: Python_xiaowu
Title: 【Python机器学习实战】聚类算法——层次聚类(HAC)和DBSCAN
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549602/
转载文章受原作者版权保护。转载请注明原作者出处!