

一:常见的主备一致有哪些结构
1.m-s结构
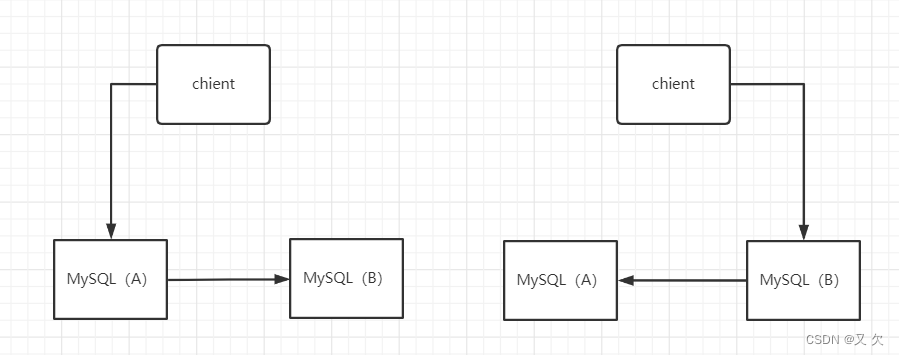

如上就是M-S结构
客户端的读写都直接访问节点 A,而节点 B 是 A 的备库,只是将 A 的更新都同步过来,到本地执行。这样可以保持节点 B 和 A 的数据是相同的。
当需求切换时,这时候客户端读写访问的都是节点 B,而节点 A 是 B 的备库。(切换过程中需要修改主备关系。)
2. 双m结构
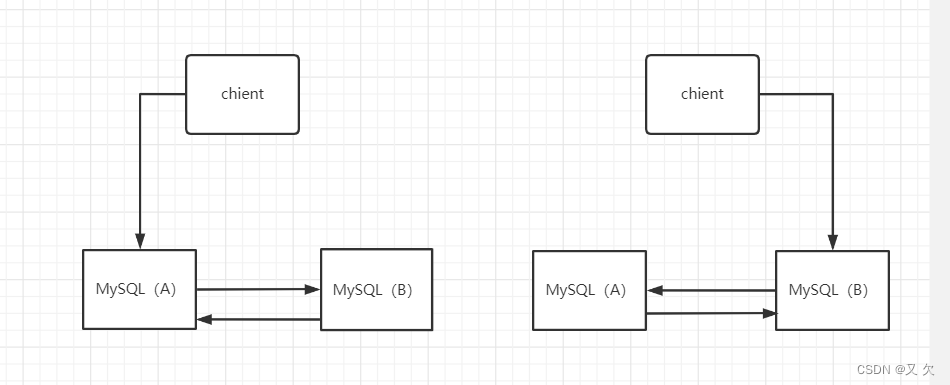
如上就是双M结构
双 M 结构和 M-S 结构,其实区别只是多了一条线,即:节点 A 和 B 之间总是互为主备关系。这样在切换的时候就不用再修改主备关系。
在前面文章中,我们讲述了MySQL是怎么保证主从一致的问题。但是MySQL 要提供高可用能力,只有最终一致性是不够的。当我们主备存在延迟时,主备切换时MySQL会怎么处理?有哪些策略
; 二:主备延迟
1. 什么是主备延迟?
主备延迟指的是主库执行完成的时间和备库执行完成的时间的差距
主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;
之后传给备库 B,我们把备库 B 接收完这个 binlog 的时刻记为 T2;
备库 B 执行完成这个事务,我们把这个时刻记为 T3。
所以主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1。
2.是什么导致了主备延迟?
情况一:备库服务器性能比主库差
这个就很好理解了,假如备库服务器性能是主库的一半,那么在执行语句(relay log)速度时,备库肯定不如主库。
情况二:备库压力很大
当我们使用读写分离时,由于主库直接影响业务,大家使用起来会比较克制,反而忽视了备库的压力控制。结果就是,备库上的查询耗费了大量的 CPU 资源,影响了同步速度,造成主备延迟。
情况三:大事务
大事务这种情况很好理解。因为主库上必须等事务执行完成才会写入 binlog,再传给备库。所以,如果一个主库上的语句执行 5 分钟,那这个事务很可能就会导致从库延迟 5 分钟。
比如我们使用delete删除大量数据时
使用delete删除大量数据,无论有无索引(无索引导致扫全表,锁所有数据,情况更严重),存储引擎都要一条一条的查询并加锁,将数据返回给执行引擎,执行引擎标记数据删除。所有的数据都处理完成后,提交事务释放锁。 这样的事务时间长,称之为大事务。 大事务导致事务不能迅速提交,主备延迟大。
三:主备存在延迟,MySQL是如何进行切换的?
1.可靠性优先策略
当seconds_behind_master小于某个值时,将主库readonly,当备库seconds_behind_master = 0时,将备库可读写,业务切换到备库。
seconds_behind_master:主备延迟的时间差值
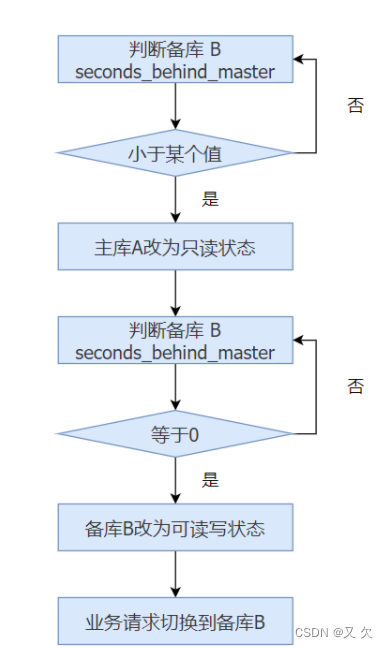
在可靠性优先策略下的双M结构的切换流程
1.判断备库 B 现在的 seconds_behind_master,如果小于某个值(比如 5 秒)继续下一步,否则持续重试这一步;
2.把主库 A改成只读状态,即把 readonly(读写) 设置为 true;
3.判断备库 B 的 seconds_behind_master 的值,直到这个值变成0 为止;
4.把备库 B 改成可读写状态,也就是把 readonly (读写设置为 false;
5.把业务请求切到备库 B。
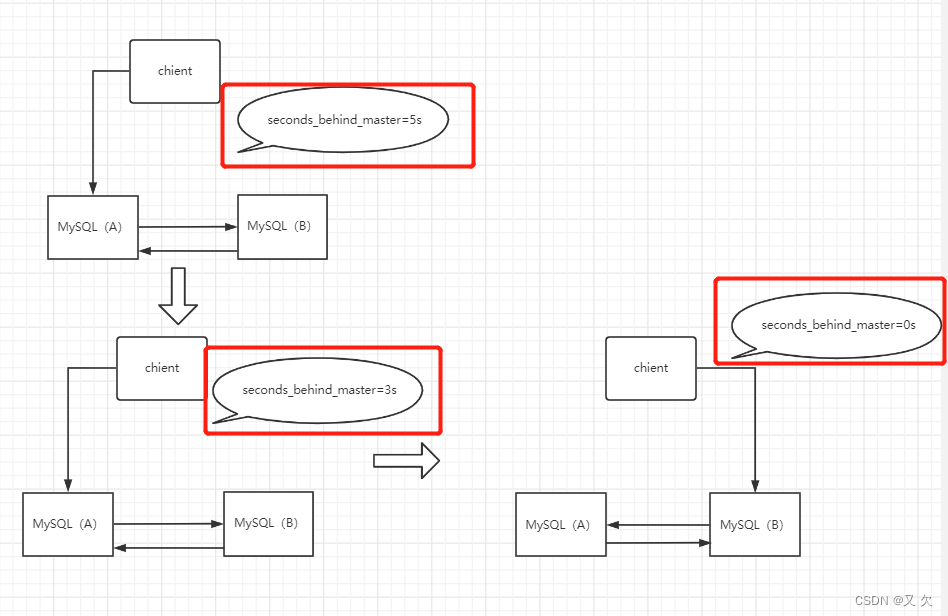
可以看到,这个切换流程中有不可用时间。
因为在步骤 2 之后,主库 A 和备库 B 都处于 只读状态,也就是说这时系统处于不可写状态,直到步骤 5 完成后才能恢复。
在不可用状态中,比较耗费时间的是步骤 3,可能需要耗费好几秒的时间。
这也是为什么需要在步骤 1 先做判断,确保 seconds_behind_master 的值足够小。
2. 可用性优先策略
在使用可靠性优先策略时,MySQL会存在一定时间的不可用状态。如果我强行把步骤 4、5 调整到最开始执行,也就是说不等主备数据同步,直接把连接切到备库 B,并且让备库 B 可以读写,那么系统几乎就没有不可用时间了。
1.把备库 B 改成可读写状态,也就是把 readonly (读写设置为 false);
2.主库 A改成只读状态,即把 readonly(读写) 设置为 true;
3.把业务请求切到备库 B。
4.主库B执行备库A的realy log中转日志
虽然切换让系统几乎就没有不可用时间,但是这个切换流程的代价,就是可能出现数据不一致的情况。
实验一:使用binlog_format=statement格式(statement:每一条会修改数据的 SQL 都会记录在 binlog 中。)
我现在有一张test表,主键是且自增id,还有一个字段是c。
insert into t(c) values(4);
insert into t(c) values(5);
假设,现在主库上其他的数据表有大量的更新,导致主备延迟达到 5 秒。在插入一条 c=4 的语句后,发起了主备切换。
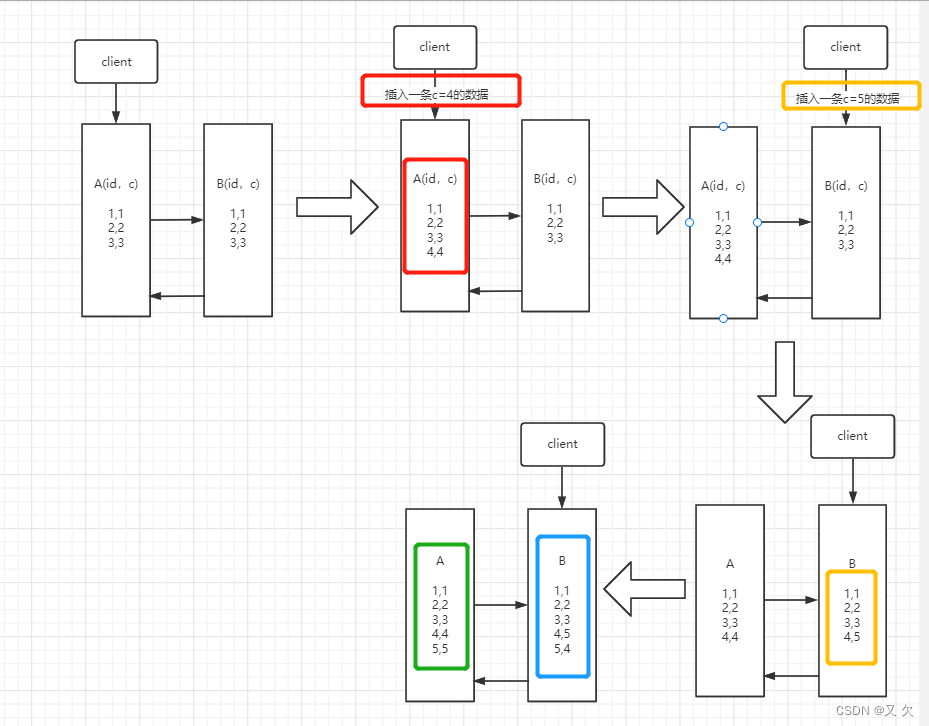
步骤 2 中,主库 A 执行完 insert 语句,插入了一行数据(4,4),之后开始进行主备切换。
步骤 3 中,由于主备之间有 5 秒的延迟,所以备库 B 还没来得及应用”插入 c=4″这个中转日志,就开始接收客户端”插入c=5″的命令。
步骤 4 中,备库 B 插入了一行数据(4,5),并且把这个 binlog 发给主库 A。
步骤 5 中,备库 B 执行”插入 c=4″这个中转日志,插入了一行数据(5,4)。而直接在备库 B 执行的”插入 c=5″这个语句,传到主库 A,就插入了一行新数据(5,5)。
最后的结果就是,主库 A 和备库 B 上出现了两行不一致的数据。可以看到,这个数据不一致,是由可用性优先流程导致的。
实验二:使用binlog_format=row格式(row:不记录 SQL 语句上下文信息,仅保存哪条记录被修改。)
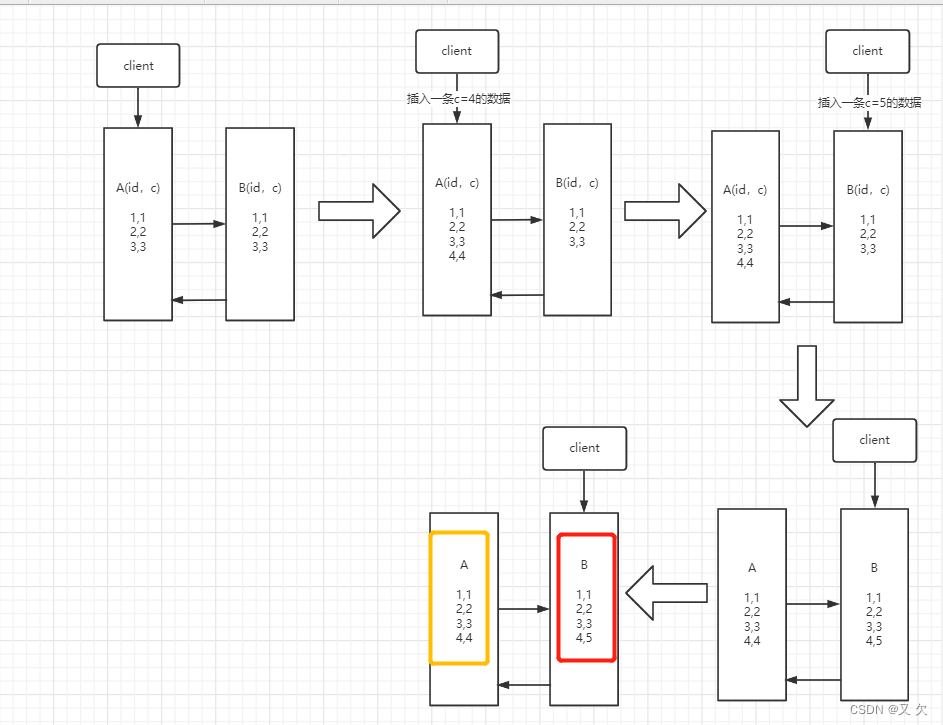
步骤 2 中,主库 A 执行完 insert 语句,插入了一行数据(4,4),之后开始进行主备切换。
步骤 3 中,由于主备之间有 5 秒的延迟,所以备库 B 还没来得及应用”插入 c=4″这个中转日志,就开始接收客户端”插入c=5″的命令。
步骤 4 中,备库 B 插入了一行数据(4,5),并且把这个 binlog 发给主库 A。
步骤 5 中,备库 B 执行”插入 c=4″这个中转日志时
由于是row格式,记录的是哪条记录被修改 inset into test (id,c) values (4,4),由于备库B已存在id4记录,主键冲突
同理主库A也会出现主键冲突等问题,都不会被执行。
四:总结
1.平时开发建议使用row格式
使用 row 格式的 binlog 时,数据不一致的问题更容易被发现。而使用 mixed 或者 statement 格式的 binlog 时,数据不一致不容易发现。如果过了很久才发现数据不一致的问题,很可能这时的数据不一致已经不可查,或者连带造成了更多的数据逻辑不一致。所以平时开发建议多使用row格式。
2.建议使用可靠性优先策略
主备切换的可用性优先策略会导致数据不一致。 因此,大多数情况下,都建议使用可靠性优先策略。毕竟对数据服务来说的话,数据的可靠性一般要优于可用性的。
3.尽量减少主备延迟
在满足数据可靠性的前提下,MySQL 高可用系统的可用性,是依赖于主备延迟的。延迟的时间越小,在主库故障的时候,服务恢复需要的时间就越短,可用性就越高。
Original: https://blog.csdn.net/qq_48157004/article/details/127824090
Author: 又 欠
Title: MySQL是如何保证高可用的
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/660725/
转载文章受原作者版权保护。转载请注明原作者出处!