

一、前言


SSD(Single Shot MultiBox Detector)是一种单阶段实时目标检测模型,在问世之初,取得了非常好的性能和实时检测能力,一度是最受欢迎的目标检测架构,引用量高达2W3(数据来自谷歌学术)。虽然现在yolo模型的应用更加广泛,但SSD的思想和方法依然十分具有价值,另外通过SSD的项目代码来学习目标检测的一些通用知识也十分可取。
本文选取github上收藏最多的SSD项目代码(pytorch版本)进行解析,该项目代码简洁清晰,灵活性强,很多实现方法都值得学习。这篇文章相当于作者在学习SSD过程中的笔记,也顺便谈一谈自己的理解以帮助读者了解SSD模型。
注意:本文重在讲解SSD的功能实现,如果读者没有SSD的基础理论知识,可以先阅读论文或者浏览SSD基础介绍的博客,也可以去看一看李沐老师的《动手学习深度学习》中SSD的简洁实现。
项目链接:GitHub – lufficc/SSD: High quality, fast, modular reference implementation of SSD in PyTorchl
论文链接:
https://link.springer.com/content/pdf/10.1007/978-3-319-46448-0_2.pdf
由于源码内容很多,因此分为几个部分来讲解,并且只讲解关键的实现,本篇讲解项目的网络模型构造。
二、网络模型
1.BACKBONE
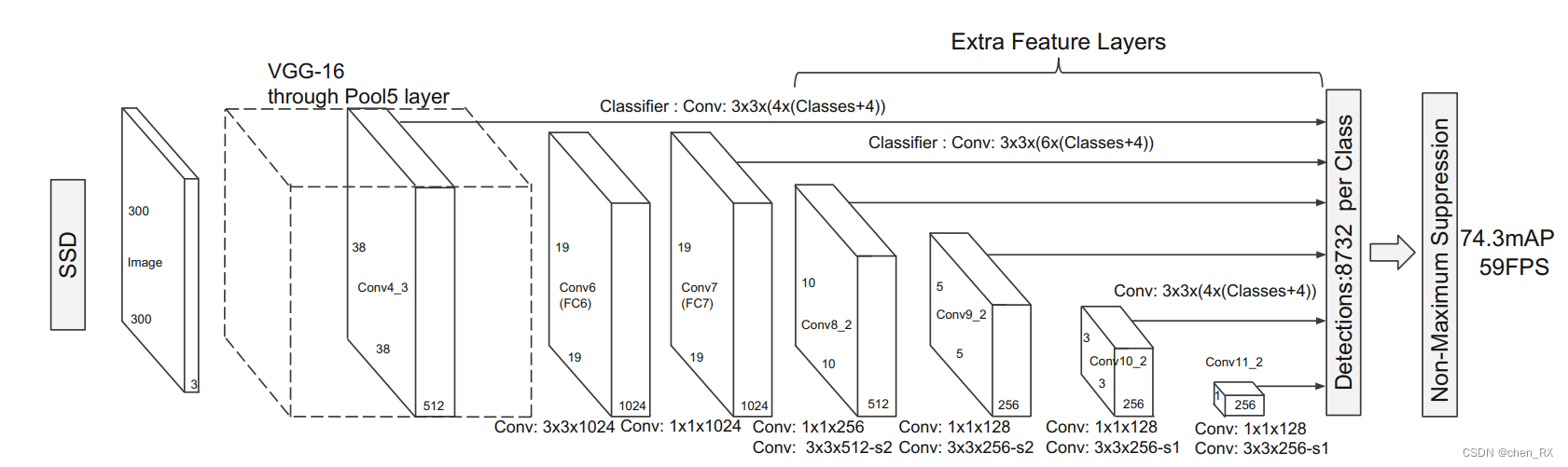
原论文采用了截断的VGG16作为backbone提取特征,事实上可以采取各种网络来提取特征,只不过论文发表的时候VGG是当时最好的选择。
下面是检测器的最外层构造:
class SSDDetector(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.backbone = build_backbone(cfg)
self.box_head = build_box_head(cfg)
def forward(self, images, targets=None):
features = self.backbone(images)
detections, detector_losses = self.box_head(features, targets)
if self.training:
return detector_losses
return detections
可以看到,像大多数工程化的项目而言,本项目也采用了高度模块化的设计方法,以便我们可以较轻松地替换其中地各个部分以验证想法。网络分为backbone 和 box_head两部分,backbone为vgg网络。
def build_backbone(cfg):
return registry.BACKBONES[cfg.MODEL.BACKBONE.NAME](cfg, cfg.MODEL.BACKBONE.PRETRAINED)
这里采用了注册机(关于注册机,不懂的读者可以读一读装饰器和深度学习框架中的注册机制_CV小蜗牛的博客-CSDN博客 )也可以暂时跳过
总之,网络构造的所有模块都会在执行的时候添加到注册表
from ssd.utils.registry import Registry
BACKBONES = Registry()
BOX_HEADS = Registry()
BOX_PREDICTORS = Registry()
模型的构造依赖注册机的管理,这里初始化了三个注册机,我们所需要的所有网络模块都会在执行的时候被添加到注册表中,由注册机维护这个表,该项目中的注册表是字典形式,输入对应的模块名即可返回模块
def _register_generic(module_dict, module_name, module):
# 将模块名和模块添加到注册表中
assert module_name not in module_dict
module_dict[module_name] = module
class Registry(dict):
"""
A helper class for managing registering modules, it extends a dictionary
and provides a register functions.
Eg. creating a registry:
some_registry = Registry({"default": default_module})
There're two ways of registering new modules:
1): normal way is just calling register function:
def foo():
...
some_registry.register("foo_module", foo)
2): used as decorator when declaring the module:
@some_registry.register("foo_module")
@some_registry.register("foo_module_nickname")
def foo():
...
Access of module is just like using a dictionary, eg:
f = some_registry["foo_module"]
"""
def __init__(self, *args, **kwargs):
super(Registry, self).__init__(*args, **kwargs)
def register(self, module_name, module=None):
# used as function call
if module is not None:
_register_generic(self, module_name, module)
return
# used as decorator
def register_fn(fn):
_register_generic(self, module_name, fn) # 由于Registry继承自dict,因此self即为 注册表字典
return fn
return register_fn
下面是backbone的base_net和extra feature layers的构建函数(构建细节可以后续研究,只需知道其构建了网络的base_net和extra feature layers,网络会输出其中的6个特征图)
import torch.nn as nn
import torch.nn.functional as F
from ssd.layers import L2Norm
from ssd.modeling import registry
from ssd.utils.model_zoo import load_state_dict_from_url
model_urls = {
'vgg': 'https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth',
}
borrowed from https://github.com/amdegroot/ssd.pytorch/blob/master/ssd.py
def add_vgg(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
def add_extras(cfg, i, size=300):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False # flag控制卷积核交替变化(1x1和3x3)
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1], kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
if size == 512: # 对于512的输入,额外增加两个卷积层
layers.append(nn.Conv2d(in_channels, 128, kernel_size=1, stride=1))
layers.append(nn.Conv2d(128, 256, kernel_size=4, stride=1, padding=1))
return layers
vgg_base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
}
extras_base = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [256, 'S', 512, 128, 'S', 256, 128, 'S', 256, 128, 'S', 256],
}
extra_base 中,带有'S'表明需要高宽减半,实际上每一层conv包含了两个卷积层,第一个卷积层1x1,第# 二个卷积层3x3,如果中间带有'S',表明需要高宽减半
VGG网络的构造比较简单,不作过多讲解,这里的vgg函数采用了注册机的装饰函数,装饰函数的作用就是使模型添加到注册表中以供我们使用,其后所有的模块构造时,只要有
@registry.BOX_HEADS.register('模块名')
类似的装饰器在模块上面,那么该模块和对应的模块名便会存储在注册表中以供我们调用
BackBone的作用在于提取多尺度特征层,一共需要提取6个特征图
这六个特征图有两个位于base_net, 4个位于extra feature layers
-
base_net conv4之后,pool4之前,特征图大小:38*38×256 (原图经过了3次减半)
-
base_net末尾,即cnov7之后, 特征图大小:19*19×1024
-
extra feature layers conv8_2之后,特征图大小: 10x10x512
-
extra feature layers conv9_2之后,特征图大小:5x5x256
-
extra feature layers conv10_2之后,特征图大小:3x3x256
-
extra feature layers conv11_2之后,特征图大小:1x1x256
那么这六个特征层总共会产生:
38384 + 19196 + 10106 + 556 + 334 + 114 = 8732 个锚框
结合代码来看
class VGG(nn.Module):
def __init__(self, cfg):
super().__init__()
size = cfg.INPUT.IMAGE_SIZE
vgg_config = vgg_base[str(size)]
extras_config = extras_base[str(size)]
self.vgg = nn.ModuleList(add_vgg(vgg_config))
self.extras = nn.ModuleList(add_extras(extras_config, i=1024, size=size))
self.l2_norm = L2Norm(512, scale=20)
self.reset_parameters()
def reset_parameters(self):
for m in self.extras.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
nn.init.zeros_(m.bias)
def init_from_pretrain(self, state_dict):
self.vgg.load_state_dict(state_dict)
def forward(self, x):
features = [] # 存储前向传播过程中我们需要的特征图
for i in range(23):
x = self.vgg[i](x)
s = self.l2_norm(x) # Conv4_3 L2 normalization
features.append(s)
# apply vgg up to fc7
for i in range(23, len(self.vgg)):
x = self.vgg[i](x)
features.append(x)
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
features.append(x)
return tuple(features)
创建了base_net和extra feature layers之后,我们重点关注其前向传播过程,这里创建了一个列表用以存储backone中6个特征层的特征图,后续会将其传入box_head层进行预测。
在base_net部分,分别在vgg[22]之后和vgg末尾保存了一次特征,查看self.vgg

可以看到,vgg[22]正好位于conv4_3之后,pool4之前,所以其特征图的大小只在原图基础上经历了三次池化减半,大小为38×38,如果经过了vgg[23]即pool4则特征图变为19×19。
features列表将所需要的6个特征图保存,这6个特征图就是整个BackBone的目标,预测任务就交给Box_Head层。
2.Box_Head
下面是box_head.py
@registry.BOX_HEADS.register('SSDBoxHead')
class SSDBoxHead(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.predictor = make_box_predictor(cfg)
self.loss_evaluator = MultiBoxLoss(neg_pos_ratio=cfg.MODEL.NEG_POS_RATIO)
self.post_processor = PostProcessor(cfg)
self.priors = None
def forward(self, features, targets=None):
cls_logits, bbox_pred = self.predictor(features)
if self.training:
return self._forward_train(cls_logits, bbox_pred, targets)
else:
return self._forward_test(cls_logits, bbox_pred)
def _forward_train(self, cls_logits, bbox_pred, targets):
gt_boxes, gt_labels = targets['boxes'], targets['labels']
reg_loss, cls_loss = self.loss_evaluator(cls_logits, bbox_pred, gt_labels, gt_boxes)
loss_dict = dict(
reg_loss=reg_loss,
cls_loss=cls_loss,
)
detections = (cls_logits, bbox_pred)
return detections, loss_dict
def _forward_test(self, cls_logits, bbox_pred):
if self.priors is None:
self.priors = PriorBox(self.cfg)().to(bbox_pred.device)
scores = F.softmax(cls_logits, dim=2)
boxes = box_utils.convert_locations_to_boxes(
bbox_pred, self.priors, self.cfg.MODEL.CENTER_VARIANCE, self.cfg.MODEL.SIZE_VARIANCE
)
boxes = box_utils.center_form_to_corner_form(boxes)
detections = (scores, boxes)
detections = self.post_processor(detections)
return detections, {}
可以看到,这个模块也被添加到了注册表中,这个模块负责多尺度特征层的类别和偏移量预测,需要计算损失,如果是测试阶段还要进行后处理。
因此,可以看到__init__()中获得了predictor, loss_evaluator, post_processor,它们又有各自的构造函数。下面来看第一个,也就是predictor的构造
def make_box_predictor(cfg):
return registry.BOX_PREDICTORS[cfg.MODEL.BOX_HEAD.PREDICTOR](cfg)
这里从注册表中调用了predictor,我们往前找,就可以找到带有对应装饰器的模块
@registry.BOX_PREDICTORS.register('SSDBoxPredictor')
class SSDBoxPredictor(BoxPredictor):
def cls_block(self, level, out_channels, boxes_per_location):
return nn.Conv2d(out_channels, boxes_per_location * self.cfg.MODEL.NUM_CLASSES, kernel_size=3, stride=1, padding=1)
def reg_block(self, level, out_channels, boxes_per_location):
return nn.Conv2d(out_channels, boxes_per_location * 4, kernel_size=3, stride=1, padding=1)
cfg中默认使用的就是这个模块,而这个模块又继承自:
class BoxPredictor(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.cls_headers = nn.ModuleList()
self.reg_headers = nn.ModuleList()
for level, (boxes_per_location, out_channels) in enumerate(zip(cfg.MODEL.PRIORS.BOXES_PER_LOCATION, cfg.MODEL.BACKBONE.OUT_CHANNELS)):
self.cls_headers.append(self.cls_block(level, out_channels, boxes_per_location))
self.reg_headers.append(self.reg_block(level, out_channels, boxes_per_location))
self.reset_parameters()
def cls_block(self, level, out_channels, boxes_per_location):
raise NotImplementedError
def reg_block(self, level, out_channels, boxes_per_location):
raise NotImplementedError
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, features):
cls_logits = []
bbox_pred = []
for feature, cls_header, reg_header in zip(features, self.cls_headers, self.reg_headers):
cls_logits.append(cls_header(feature).permute(0, 2, 3, 1).contiguous())
bbox_pred.append(reg_header(feature).permute(0, 2, 3, 1).contiguous())
batch_size = features[0].shape[0]
cls_logits = torch.cat([c.view(c.shape[0], -1) for c in cls_logits], dim=1).view(batch_size, -1, self.cfg.MODEL.NUM_CLASSES)
bbox_pred = torch.cat([l.view(l.shape[0], -1) for l in bbox_pred], dim=1).view(batch_size, -1, 4)
return cls_logits, bbox_pred
子类重写了父类的cls_block, reg_block方法,这两个方法是用来在各个尺度的特征图上获得类别预测和偏移量预测的。类别预测需要输出的通道数为该层每个像素产生的锚框数 * 类别数,偏移量预测输出的通道数为 该层每个像素产生的锚框数 * 4, 4代表xywh偏移量。对于特征图上的每个像素,其在原图上都拥有一个感受野区域,在该像素上产生的预测,就代表了在原图该区域上进行预测。
查看默认配置可以看到:
_C.MODEL.BACKBONE.OUT_CHANNELS = (512, 1024, 512, 256, 256, 256)
_C.MODEL.PRIORS.BOXES_PER_LOCATION = [4, 6, 6, 6, 4, 4] # number of boxes per feature map location
共有6个不同的特征层,predictor也会有6个,分别对每个特征层进行预测
观察前向传播过程,box_head层接收的参数为BackBone层前向传播得到的features列表,里面包含了6个特征层,box_head层初始化了6个类别预测器和6个边界框偏移量预测器,分别对这六个特征图预测类别和偏移量,最后将所有预测进行连接。
关于各层预测值的连接,采用的策略是:每一层的预测(例如类别预测 bach_size, num_anchors*classes, h, w)是四维张量,除了第一维的batch_size相同,其余维度皆不相同
融合时将通道维(第二维)移到最后再展平,变为(batch_size, -1),然后在dim=1上连接。
输出时再将张量变换为batch_size, -1, 4(bbox预测)和 batch_size, -1, num_classes(类别预测)的形式
下面我们自己创建一个张量输入网络,看一下网络的backbone和box_head的输出结果是否符合我们的推论
from ssd.modeling.backbone import VGG
from ssd.config import cfg
model_base = VGG(cfg)
model_head = make_box_predictor(cfg)
input = torch.randn(1, 3, 300, 300)
features = model_base(input)
cls_pred, bbox_pred = model_head(features)


正如前面我们所讲,features是backbone的输出,包含了6个特征层
将6个特征层送入box_head,输出cls_pred和bbox_pred,它们的形状分别为:
cls_pred: batch_size, total_anchors, num_classes
bbox_Pred: batch_size, total_anchors, 4
网络的输出讲解完成,回到Box_head模块的前向传播,我们得到了网络的预测之后,会连同targets一起送入本模块的前向传播
def forward(self, features, targets=None):
cls_logits, bbox_pred = self.predictor(features)
if self.training:
return self._forward_train(cls_logits, bbox_pred, targets)
else:
return self._forward_test(cls_logits, bbox_pred)
box_head模块包含了输出的损失函数计算,于是整个网络的输出有三个内容:
1.类别预测
2.边界框预测
3.损失
不同于我们一般的训练过程,损失的计算也被包含在了网络之中
def _forward_train(self, cls_logits, bbox_pred, targets):
gt_boxes, gt_labels = targets['boxes'], targets['labels']
reg_loss, cls_loss = self.loss_evaluator(cls_logits, bbox_pred, gt_labels, gt_boxes)
loss_dict = dict(
reg_loss=reg_loss,
cls_loss=cls_loss,
)
detections = (cls_logits, bbox_pred)
return detections, loss_dict
三、总结
SSD网络分为两个基本块,BackBone和Box_Head,Backbone采用截断的vgg16网络和额外的特征层作为基本网络结构,其目的是输出6个不同尺度的特征层。
Box_Head网络模块接收BackBone产生的6个特征层,使用6个类别预测器和6个Bbox偏移预测器生成网络的预测并且连接。除此之外,还接收targets,并计算预测值的损失,网络的输出在训练时为预测损失,在测试和推理时为类别和边界框偏移预测。
自此,网络的输出讲解基本完成,我们已经知道了SSD网络的基本架构,知道了backbone和box_head分别承担什么任务,一张图像进入网络会得到哪些输出。
有了这些内容,基本上离训练已经不远了。后续还会讲解损失函数的实现以及训练过程的实现。对于模型的测试和推理过程,有时间的话也会出。
Original: https://blog.csdn.net/chen_RX/article/details/126611382
Author: chen_RX
Title: SSD项目代码解析(pytroch)(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/681418/
转载文章受原作者版权保护。转载请注明原作者出处!