

1.VIT 整体架构


对图像数据构建patch序列
对于一个图像,将图像分为9个窗口,要将这些窗口拉成一个向量,比如一个10103维的图像,我们首先要将这个图像拉成一个300维的向量。
位置编码:
位置编码有两种方式,第一种编码是一维编码,将这些窗口按照顺序,依次编码成1,2,3,4,5,6,7,8,9.第二种方式是二维编码,返回每个图像窗口的坐标。
最后,连接一层全连接,将图像编码和位置编码映射到计算更容易识别的编码。
那么,架构图中的0编码有什么作用呢?
我们一般在图像分类中加入0编码,图像分割与目标检测一般不需要加入,0patch主要用于特征整合,整合各个窗口的特征向量,因此,0 patch可以加在任何位置。
2.公式详解
输入patch[(PP)C]经过全连接E得到((PP)D),即做一个特征映射,N+1表示额外找一个patch表示分类特征,即上面所说的 0 patch,然后再将特征整合相加。
MSA就是一个残差连接。

3.多头注意力的感受野
如图所示,纵轴表示注意力的距离,也相当于卷积的感受野,当只有一个transformer时,感受野比较小,也会有感受野大的情况出现,随着transformer数量的增多,感受野普遍都比较大,这说明了Transformer提取的是全局特征。

4. 位置编码
结论:编码有用,但是怎么编码影响不大,干脆用简单的得了,2D(分别计算行和列的编码,然后求和)的效果还不如1D的,每一层都加共享的位置编码也没啥太大用

当然,这是分类任务,位置编码可能影响不大
5.实验效果 (/14表示patch的边长是多少)
6.TNT:Transformer in Transformer
VIT中只针对pathch进行建模,忽略了其中更小的细节
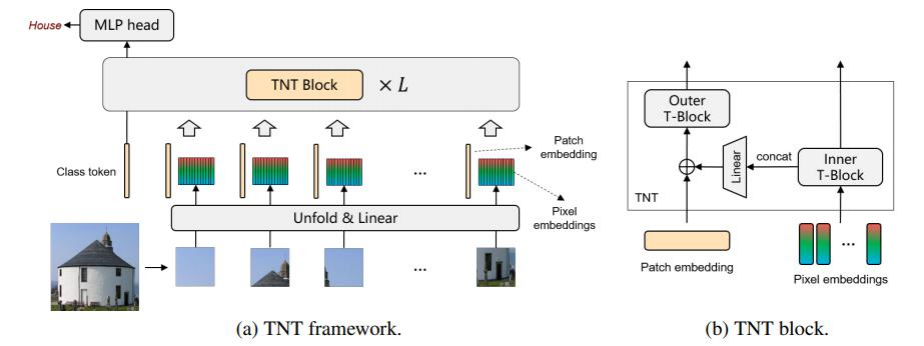
外部transformer将原始图像分为一个个窗口,经过图像编码和位置编码生成一个特征向量。
内部transformer将外部transformer的窗口,在进一步重组为多个超像素,重组为新的向量,比如说:外部transformer将图像拆分为16163的窗口,内部tranformer再将其拆分为44的超像素,此时小窗口大小为44*48,这样每一个patch就整合了多个channels的信息。新向量再通过全连接改变输出特征大小,此时内部组合后的向量与patch编码大小相同 ,将内部向量与外部向量再相加。


TNT的PatchEmbedding的可视化
对于蓝色的点表示TNT提取的特征,从可视化图像中可以看出,蓝色的点特征更离散,方差更大,更有利于分离,特征更鲜明,分布更多样性

实验结果
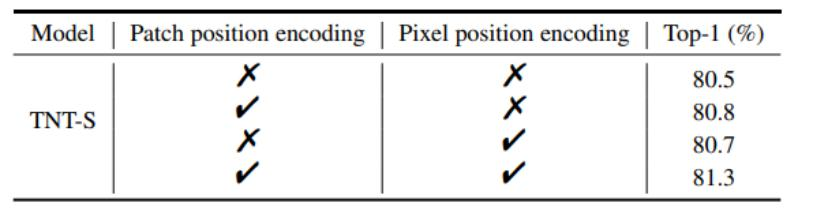
内外兼修,都加编码效果最好
Original: https://blog.csdn.net/qq_52053775/article/details/126242791
Author: 樱花的浪漫
Title: VIT transformer详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/651780/
转载文章受原作者版权保护。转载请注明原作者出处!