

之前有篇博客介绍了自己对PointConv的理解,那篇文章虽然在某种程度上实现了高效卷积,并且利用了一种注意力的方法(密度加权),但是其分割的效果并不是特别的理想,miou并不是特别的高,所以这篇文章讲述一下自己对CVPR2019年发表的一篇文章KPConv的理解。
一、这篇文章的贡献我觉得是提出了一种新的点卷积设计,就是Kernel卷积的方法,它使用任意点数量的核点使KPConv比固定卷积更加具有灵活性,并且论文中提出了两种KPConv,grid型的KPConv用于简单的任务,可变形的KPConv可用于执行更复杂的任务。并且它的实验结果有大大提升。
二、对于输入的话有两个,一个是点P,另一个是特征F,并且它的local选择的是半径搜索的方法,因为如果采用KNN的搜索方法的话,会导致感受野忽大忽小,导致一定的不确定性。像图像卷积一样,我们希望核点卷积对不同区域的点的权重也是不同的,所以我们利用一种距离的方法,利用这个距离对Kernel中点的权重进行激活,KPConv中使用的是线性相关的方法,这种方法比较简单,以在学习内核变形时简化梯度反向传播。
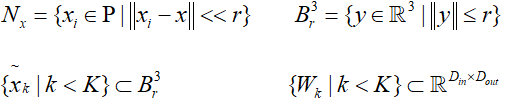

上述分别是邻域、核点的定义域、核点以及每个Kernel点的权重。最终的卷积方法可以写成下图的方式,并且上文也提到了一种利用距离激活的方法实现加权。
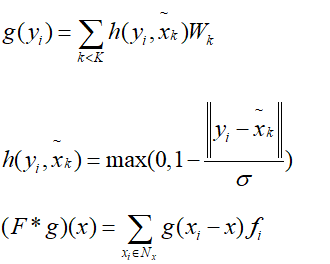
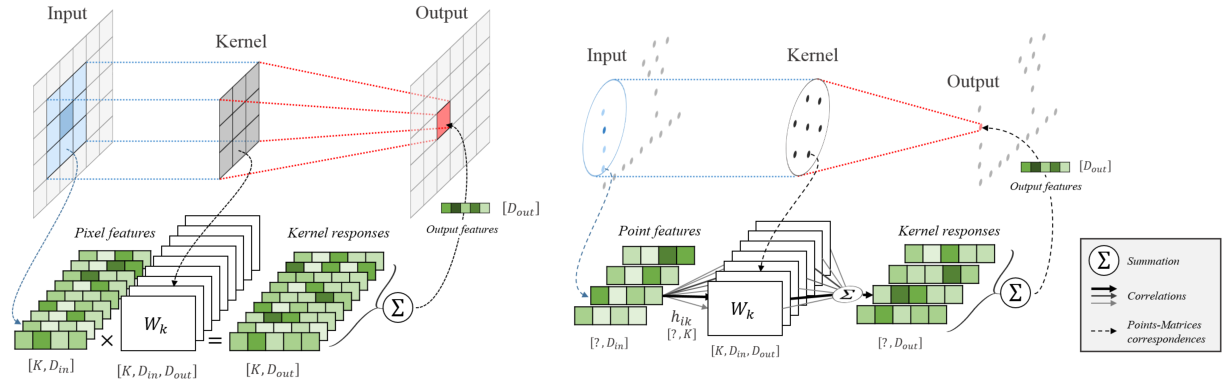
它卷积的计算方法与图像不太一样,图像是将卷积核(也就是Kernnel)分别与输入矩阵进行乘法然后加权,KPConv是将Kernel种所有点与输入点进行卷积,以致于处理完所以local内的点的特征,然后进行加权,得到一个点x的特征输出。
三、文章开头也提到了这篇文章的一个贡献是提出了一个可变形的KPConv,作者刚开始想着对于每一层都使用不同的Kernel Points,但是这种方法会降低网络的表述能力,刚性的KPConv中的内点是不动的,特别是给定一个特别大的K来足够覆盖核的球域时,核函数g对于x是可微的,意味着它们是可学习的,所以原作者为了更加适应点云学习,给每个卷积位置生成一组Local shifts,用于执行更复杂的任务。
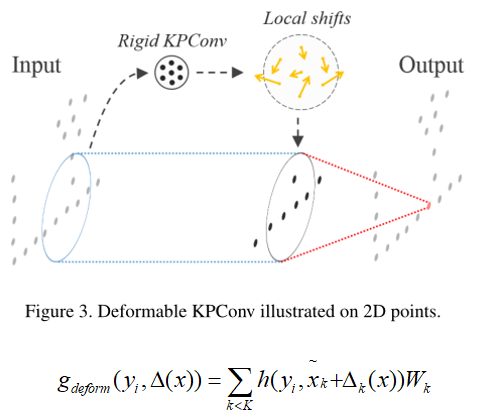
为了防止邻域内的点出现聚集,不均匀,或者说我们更希望点会靠近中心点,而且在实践中,内核点最终会被拉离输入点,核点就会被网络丢失,所以文章添加了两个正则化损失,用于惩罚该问题。第一个损失函数是让Kernel Points中的点形状更像点云的形状,就是领域点到核点之间的距离和尽量小,第二个损失函数是Kernel Points的两点之间的距离更远一点,更均匀一点。
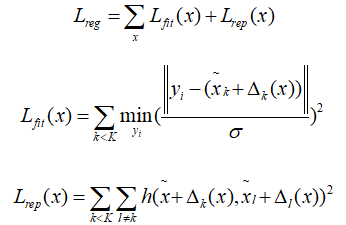
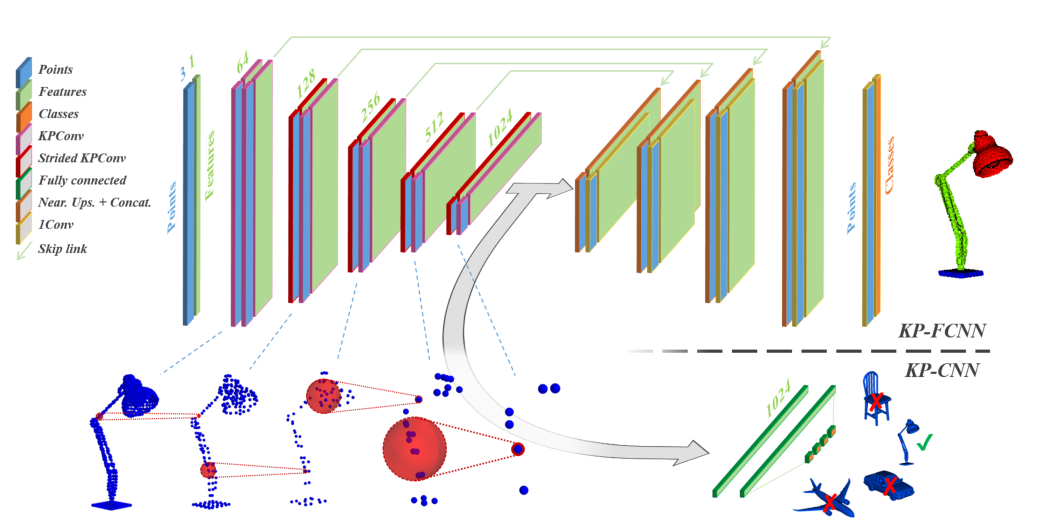
四、对于KPConv的网络架构的话,主要有种,一种KP-FCNN用于分割,KP-CNN用于分类,前面都是一个5层的网络结构,以点和特征作为输入,进行卷积、池化并且提升维度,分类其实就是选择半径球域,然后进行KPConv聚合成更少的点,最终加入FC和softmax进行分类打分。分割的话是一个还原的过程,先利用上采样,将聚合的点进行降维,然后与之前的点进行一个skip link后进行一个one by one的卷积,逐渐的还原,以致于还原到原始点云的情况。
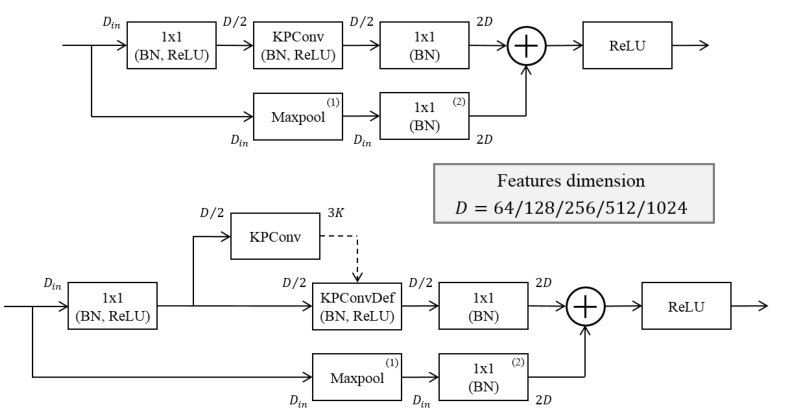
对每一个block而言,以Din为输入,先进行一个1×1卷积,进行一个上采样,降维到D/2,然后在进行KPConv,与maxpooling之后的进行相加,全块用ReLU函数激活,在deformableKPConv中,添加将输入Din映射到3K值的刚性KPConv的输出,其他的与rigid一样。
五、对于实验的话,以为做的实验比较多,而且论文后面有一些内核点的学习以及Kernel的具体结构,可以去参考论文,在这里不详细说明,以上是我对这篇文章的一个初步了解,如有不对或者错误,请多多指正!!!
附上原文的网址:https://arxiv.org/abs/1904.08889
Original: https://blog.csdn.net/weixin_48845174/article/details/123183336
Author: YXLiu_XMYang_PCSS
Title: 【计算机视觉】简述对KPConv的理解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/651302/
转载文章受原作者版权保护。转载请注明原作者出处!