

论文标题:Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields (CVPR 2022)
建议预备知识:NeRF (BV1c34y1B7Hx) Mip-NeRF (BV1QL4y1L7C7) NeRF++ (BV1dS4y1P72T) 论文链接:https://arxiv.org/abs/2111.12077
目录
1. Preliminaries初步研究: mip-NeRF
2. Scene and Ray Parameterization
3. Coarse-to-Fine Online Distillation
4. Regularization for Interval-Based Models


Abstract
虽然神经辐射场(NeRF)在物体和小的有界空间区域上表现出令人印象深刻的视图合成结果,但是它们在” 无界”场景“unbounded” scenes上很难,在无界场景中,相机可能指向任何方向,内容可能存在于任何距离。在这种设置中,现有的类似NeRF的模型经常 产生模糊或低分辨率的渲染(由于附近和远处物体的不平衡细节和比例), 训练缓慢,并且可能由于从一小组图像重建大场景的任务的 固有模糊性inherent ambiguity而 表现出伪像artifacts。我们提出了 mip-NeRF的扩展(一种解决采样和混叠的NeRF变体),它使用 非线性场景参数化 non-linear scene parameterization、 在线提取 online distillation和一种新颖的 基于失真的正则化novel distortion-based regularizer来克服无界场景带来的挑战。我们的模型被称为”mip-NeRF 360″,因为我们的目标场景是 相机绕着一个点旋转360度,与mip-NeRF相比,我们的模型将均方误差降低了57%,并且能够为高度复杂、无限的真实世界场景生成逼真的合成视图和详细的深度图depth maps。
神经辐射场(NeRF)通过在基于坐标的多层感知器(MLP)的权重内编码场景的体积密度和颜色,合成高度逼真的场景渲染。这种方法已经实现了照片真实感视图合成的重大进展[33]。然而, NeRF使用沿射线的无穷小的3D点对MLP的输入进行建模,这在渲染不同分辨率的视图时会导致 混叠。Mip-NeRF纠正了这个问题,它扩展了NeRF,改为推理沿圆锥的体积截头体 volumetric frustums[3]。虽然这提高了质量,但NeRF和mip-NeRF在处理无界场景时都很吃力, 因为相机可能面向任何方向,场景内容可能存在于任何距离。在这项工作中,我们提出了一个对mip-NeRF的扩展,我们称之为”mip-NeRF 360 “,它能够生成这些无界场景的逼真渲染,如图1所示。

图一。(a)虽然mip-NeRF能够产生物体的精确轮廓,但是对于无边界的场景,它经常产生 模糊的背景和低细节的前景。(b)我们的模型产生了这些无界场景的 详细的现实渲染,正如来自两个模型的渲染(顶部)和深度图(底部)所示。请参见补充视频了解更多结果。
将类似NeRF的模型应用于大型无界场景提出了三个关键问题:
- 参数化。无界360度场景可以占据欧几里德空间的 任意大的区域,但是mip-NeRF要求3D场景坐标位于 有界域中。
- 效率。大而详细的场景要求 更多网络容量,但是在训练期间沿着每条射线密集地查询大的MLP是 昂贵的。
- Ambiguity。无界场景的内容可能位于任何距离,并且将仅被少量光线观察到,这加剧了从2D图像重建3D内容的 固有模糊性。
参数化。
由于透视投影, 放置在远离相机的物体将占据图像平面的一小部分,但是如果放置在附近,将占据图像的大部分并且细节可见。因此,理想的3D场景参数化应该将更多的容量分配给附近的内容,而将较少的容量分配给远处的内容。在NeRF之外,传统的视图合成方法通过在 投影全景空间projective panoramic space[2,4,9,16,23,27,36,46,54]中参数化场景或者通过在已经使用多视图立体恢复的一些代理几何结构[17,26,41]中嵌入场景内容来解决这个问题。
NeRF成功的一个方面是它将特定的场景类型与其适当的3D参数化相结合。最初的NeRF论文[33]关注的是具有遮蔽背景的物体的360度特征,以及所有图像大致面向同一方向的正面场景。 对于被遮蔽的物体,NeRF直接在3D欧几里得空间中参数化场景,但是 对于正面场景,NeRF使用在投影空间中定义的坐标(标准化的设备坐标,或”NDC”[5])。通过将无限深的摄像机截锥camera frustum 扭曲成一个有界立方体,其中沿z轴的距离对应于视差disparity(距离的倒数),NDC以一种与透视投影几何一致的方式有效地重新分配了MLP的容量ca- pacity。
然而,在所有方向上没有边界的场景,而不仅仅是在一个方向上,需要不同的参数化。NeRF++ [51]和DONeRF [34]探索了这一想法,前者使用一个额外的网络来模拟远处的物体,后者提出了一个空间扭曲程序来将远处的点向原点收缩。这两种方法的行为都有点类似于NDC,但是是在每个方向上,而不仅仅是沿着z轴。在这项工作中,我们将这一思想扩展到mip-NeRF,并提出了一种 对 体volumes(而不是点)应用任何平滑参数化的方法,还提出了我们自己 对无界场景的参数化。
Efficiency
处理无界场景的一个基本挑战是这种场景通常很大且很详细。虽然类似NeRF的模型可以使用数量少得惊人的权重精确地再现对象或场景区域,但是 当面对日益复杂的场景内容时,NeRF MLP的能力会饱和。此外,较大的场景需要沿每条射线进行更多的采样,以精确定位表面。例如,当将NeRF从物体扩展到建筑物时,Martin- Brualla等人[30]将MLP隐藏单元的数量增加了一倍,并将MLP评估的数量增加了8倍。这种模型容量的增加是昂贵的——一个NeRF已经需要几个小时来训练,并且将这个时间乘以额外的40倍对于大多数用途来说是非常慢的
NeRF和mip-NeRF使用的从粗到细的重新采样策略加剧了这种训练成本:使用”粗”和”细”射线间隔多次评估MLP,并且在两次通过passes中都使用图像重建损失进行监控。这种方法很浪费,因为场景的”粗糙”渲染对最终图像没有贡献。我们将训练两个MLP:一个 proposal MLP“提议MLP”和一个” NeRF MLP “,而不是训练一个在多个尺度上监督的NeRF MLP。 proposal MLP预测体积密度(但不是颜色),这些密度用于对提供给NeRF MLP的新间隔进行重新采样,后者随后渲染图像。重要的是, 由 proposal MLP 产生的权重不是使用输入图像来监督的,而是使用由NeRF MLP产生的 直方图权重 来监督的。这使得我们可以使用评估次数相对较少的大型NeRF MLP,以及评估次数较多的小型proposal MLP。因此,我们的整个模型的总容量比mip-NeRF的大得多(15倍),从而大大提高了渲染质量,但我们的训练时间仅略有增加(2倍)
我们可以认为这种方法是一种”在线蒸馏online dis- tillation”:虽然”蒸馏”通常是指训练一个小网络,以匹配一个已经训练好的大网络的输出[19],在这里,我们 通过同时训练两个网络,将NeRF MLP预测的输出结构提取到”在线” proposal MLP 中。NeRV [47]为一项完全不同的任务执行了类似的在线提取:训练MLP来近似渲染积分,以便对可见性和间接照明进行建模。我们的在线蒸馏方法在精神上类似于DONeRF中使用的”采样oracle网络”,尽管该方法使用地面真实深度进行监督[34]。TermiN- eRF [39]中使用了一个相关的想法,尽管这种方法只是加速了推理,实际上减缓了训练(训练一个NeRF来收敛,然后再训练一个额外的模型)。NeRF详细研究了一个learned “proposer” network[1],但只实现了25%的加速,而我们的方法将训练加速了300%。
一些作品试图将经过训练的NeRF提炼或”烘焙”distill or “bake”成一种可以快速渲染的格式[18,40,50],但这些技术并不能加速训练。通过诸如八叉树[43]或包围体分层结构[42]的分层数据结构来加速光线跟踪的思想在绘制文献中得到了很好的探索,尽管这些方法假定场景的几何形状是先验知识,因此不能自然地推广到场景的几何形状未知且必须被恢复的逆绘制环境。事实上,尽管在优化类NeRF模型的同时构建了八叉树加速结构,但神经稀疏体素场方法并没有显著减少训练时间[28]。
Ambiguity 。
虽然传统上使用场景的许多输入图像来优化NeRF,但是重新覆盖从新的相机角度产生真实合成视图的NeRF的问题仍然基本上是不充分的——无限的NeRF家族可以解释输入图像,但是只有一小部分产生可接受的新视图结果。例如,一个NeRF可以通过简单地将每个图像重建为其各自摄像机前面的纹理平面来重建所有的输入图像。最初的NeRF论文通过在整流器[33]之前将高斯噪声注入NeRF MLP的密度头来规则化模糊场景,这促使密度趋向于零或无穷大。虽然这通过阻止半透明的密度减少了一些”floaters”,但我们将证明这对于我们更具挑战性的任务来说是不够的。已经提出了针对NeRF的其他正则化方法,例如密度上的鲁棒损失[18]或表面上的平滑度惩罚[35,53],但是这些解决方案解决的问题与我们的不同(分别为缓慢渲染和非平滑表面)。此外,这些正则化子是为NeRF使用的点样本设计的,而我们的方法是为沿着每个mip-NeRF射线定义的连续权重设计的。
在审查mip-NeRF之后,这三个问题将分别在第2、3和4节中讨论。我们将使用由具有挑战性的室内和室外场景组成的新数据集来展示我们对先前工作的改进。我们强烈建议读者观看我们的补充视频,因为我们的结果在制作动画时会得到最好的欣赏。
1. Preliminaries初步研究: mip-NeRF


2. Scene and Ray Parameterization

这个设计和NDC有着相同的动机:远点应该按比例分配给disparity(相反的距离)而不是距离。在我们的模型中,不是根据等式1在欧几里德空间中使用mip-NeRF的IPE特征,我们在这个收缩空间中使用类似的特征(见附录):γ(contract(μ,Σ))。有关这种参数化的可视化,请参见图2。
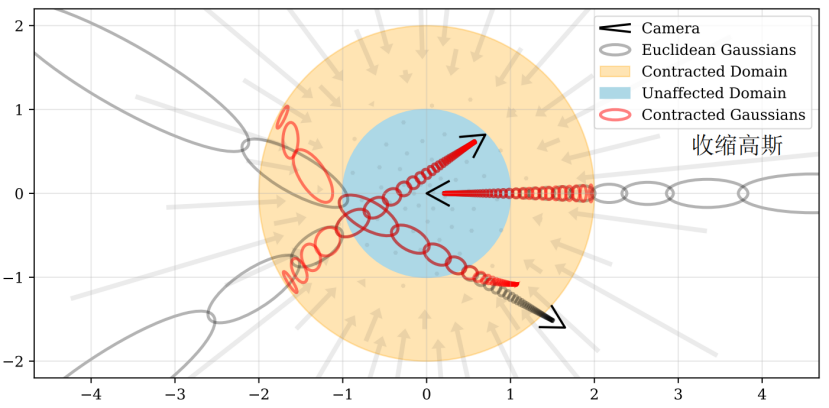
图2。一个对我们的 场景参数化的二维可视化。我们定义了一个contract(·) operator(公式10,如箭头所示),它将坐标映射到半径为2的球(橙色)上,其中半径为1(蓝色)内的点不受影响。我们将这种收缩应用于 欧几里得三维空间(灰色椭圆)中的 mip-NeRF高斯分布,类似于卡尔曼滤波器Kalman filter来产生我们的 收缩高斯分布(红色椭圆),其中心保证位于半径为2的球内。contract(·)的设计结合我们根据视差disparity 线性空间光线间隔space ray intervals linearly的选择,意味着位于 场景原点的摄像机投射的光线在橙色区域将有等距间隔,如这里所示。
除了应该如何参数化3D坐标的问题之外,还有应该如何选择 射线距离t的问题。在NeRF中,这通常是通过根据等式5从近平面和远平面均匀采样来实现的。然而,如果 使用NDC参数化,这个均匀间隔的样本系列实际上是在相反的深度上均匀间隔的(视差)in inverse depth (disparity)。这种设计决策非常适合相机仅面向一个方向的无界场景,但不适用于所有方向都无界的场景。因此,我们将明确地对我们的距离t进行视差线性采样sample our distances t linearly in disparity (参见[32]中关于该间距的详细动机)。
为了根据视差来参数化射线,我们定义 欧几里德射线距离t和” 归一化”射线距离s之间的 可逆映射:

其中g()是某个可逆标量函数。这给了我们映射到[tn,tf ]的”归一化”射线距离s ∈ [0,1]。在整篇论文中,我们将在t空间或s空间中引用沿射线的距离,这取决于哪个更方便或更直观。通过设置g(x) = 1/x并构造均匀分布在s空间的射线样本,我们产生了t距离在视差中线性分布的射线样本(此外,设置g(x) = log(x)会产生DONeRF的对数间距[34])。在我们的模型中,我们用s距离进行采样,而不是用t距离在等式5和等式6中进行采样。这意味着,不仅我们的初始样本在视差上是线性间隔的,而且来自权重w的各个间隔的后续重采样也将类似地分布。从图2中心的摄像机可以看出,光线样本的线性视差间距linear-in-disparity spacing 相互平衡地收缩 counter-balances contract(·)。实际上,我们已经共同设计了我们的 场景坐标空间和我们的 反深度间距,这给了我们一个无界场景的参数化,非常类似于原始NeRF论文的高效设置:在有界空间内均匀间隔的光线间隔。
3 . Coarse-to-Fine Online Distillation

图3。比较了我们的模型的架构与mipNeRF的架构。Mip-NeRF使用一个多尺度的MLP,重复查询(这里只显示两次重复)的权重,重新采样到下一阶段的间隔,并监督在所有尺度下产生的效果图renderings。我们使用一个”proposal MLP”,它发出重新采样的权重(但不是颜色),在 最后阶段,我们使用一个”NeRF MLP”来产生权重和颜色,生成渲染图像,我们监督。proposal MLP被训练以产生与NeRF MLP的w输出一致的 proposal weights ˆw。通过使用一个小的proposal MLP和一个大的NeRF MLP,我们获得了一个高容量的组合模型,它仍然易于训练。
如前所述,mip-NeRF采用了一种从粗到细的重采样策略(图3 ),其中使用”粗略”射线间隔评估一次MLP,并再次使用”精细”射线间隔
,并使用两个级别的图像重建损失进行监控。相反,我们训练两个MLP,一个” NeRF MLP” θ NeRF(其行为类似于NeRF和mip-NeRF使用的MLP)和一个” proposal MLP” θ prop。proposal MLP 预测体积密度,其根据等式4被转换成 proposal weight vector wˆ,但是不预测颜色。这些proposal weight wˆ被用于 采样s-间隔,然后被提供给NeRF MLP,后者预测其自己的 权重向量w(以及颜色估计,用于渲染图像)。关键的是,proposal MLP没有被训练来再现输入图像,而是被训练来限制由NeRF MLP产生的权重w。两个MLP都是随机初始化并联合训练的,因此这种监督可以被认为是将NeRF MLP 的知识”在线提取”到proposal MLP 中的一种方式。我们使用一个大的NeRF MLP和一个小的proposal MLP,用许多样本对proposal MLP进行反复评估和重采样(为了清楚起见,一些图和讨论只说明了一次重采样),但只用一组较小的样本对NeRF MLP进行一次评估。这给了我们一个模型,它表现得好像具有比mip-NeRF 高得多的容量,但是训练起来只是稍微昂贵一些。正如我们将要展示的,使用一个小的MLP来模拟proposal distribu- tion并不会降低精度,这表明提取NeRF MLP比视图合成更容易。
这种在线提取需要一个损失函数,该函数鼓励由 proposal MLP (ˆt, wˆ )和the NeRF MLP (t, w)发出的直方图保持一致。乍一看,这个问题似乎微不足道,因为最小化两个直方图之间的不相似性是一个公认的任务,但是回想一下,那些直方图ˆt和t的”面元”bins不需要相似——实际上, 如果 proposal MLP 成功地剔除了场景内容存在的距离集合,则 ˆt 和t将非常不相似。尽管文献中包含了多种方法来测量两个具有相同条柱的直方图之间的差异[12,29,38],但我们的情况相对来说探索不足。这个问题是具有挑战性的,因为我们不能对一个直方图仓histogram bin内的内容分布做任何假设:具有非零权重的区间可以指示整个区间上的权重的均匀分布、位于该区间中任何位置的δ函数、或者无数myriad其他分布。因此,我们在下面的假设下构造我们的损失:如果有任何可能,两个直方图都可以用任何单一的质量分布single distribution of mass 来解释,那么损失必须为零。只有当两个直方图都不可能反映相同的”真实”连续质量分布时,才会产生非零损失。有关这一概念的可视化,请参见附录。

这种损失类似于统计学和计算机视觉中常用的 卡方直方图距离的半平方版本[38]。这种损失是不对称的,因为我们只想惩罚proposal weights 低估了NeRF MLP所暗示的分布——高估是意料之中的,因为proposal weights可能比NeRF权重更粗糙,因此会形成一个上限。除以wi保证了当界限为零时,该损失相对于界限的梯度是恒定值,这导致了良好的优化。因为t和ˆt是排序的,所以可以通过使用 总面积表[11]有效地计算公式13。注意,这种损失是距离t的单调变换的变体(假设已经在t-空间中计算了w和wˆ),因此无论是应用于欧几里德射线t-距离还是归一化射线s-距离,其表现都是相同的。
我们在NeRF直方图(t,w)和所有proposal直方图
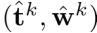 之间强加这个损失。与在mip-NeRF中一样,NeRF MLP使用输入图像的重建损失Lrecon进行监控。当 计算Lprop时,我们在NeRF MLP 的输出t和w上放置一个 停止梯度,使得NeRF MLP “领先”,而proposal MLP “跟随”——否则,NeRF可能被鼓励产生一个更差的场景重建,以便使proposal MLP的工作不那么困难。这种主动监督的效果可以在图4中看到,其中,NeRF MLP逐渐将其权重w定位在场景中的表面周围,而proposal MLP”赶上”并预测包围NeRF权重的粗略建议直方图coarse proposal histograms。
之间强加这个损失。与在mip-NeRF中一样,NeRF MLP使用输入图像的重建损失Lrecon进行监控。当 计算Lprop时,我们在NeRF MLP 的输出t和w上放置一个 停止梯度,使得NeRF MLP “领先”,而proposal MLP “跟随”——否则,NeRF可能被鼓励产生一个更差的场景重建,以便使proposal MLP的工作不那么困难。这种主动监督的效果可以在图4中看到,其中,NeRF MLP逐渐将其权重w定位在场景中的表面周围,而proposal MLP”赶上”并预测包围NeRF权重的粗略建议直方图coarse proposal histograms。

图4。在训练过程中, NeRF MLP(黑色)发出的直方图(t,w)和proposal MLP(黄色和橙色)发出的两组直方图(ˆt,ˆw)的来自数据集的自行车场景的单个射线的可视化。下面我们用固定的x轴和y轴来可视化整个光线,但在上面我们裁剪了两个轴,以更好地可视化场景内容附近的细节。 直方图的权重被绘制成 积分为1的分布。(a)当训练开始时,所有的权值都随射线距离t均匀分布。(b,c)随着训练的进行,NeRF的权值开始集中在一个表面周围,而proposal weights在这些NeRF的权值周围形成一种包络线。
4. Regularization for Interval-Based Models
由于不适定性,训练有素的NeRFs经常表现出两种典型的伪影,我们称之为” 浮动floaters“和” 背景塌陷back- ground collapse“,如图5(a)所示。通过” 浮动“,我们指的是体积密集空间的小的不连续区域,其用于解释输入视图子集的某些方面,但是当从另一个角度观看时,看起来像模糊的云。我们所说的” 背景塌陷“指的是这样一种现象,即远处的表面被不正确地建模为靠近摄像机的密集内容的半透明云。在这里,我们提出一个正则化器,如图5所示,它比NeRF使用的 将噪声注入体积密度的方法更有效地防止漂浮物和背景碰撞[33]。

图5。我们的正则化器抑制了”floaters”(漂浮在空间中的半透明材料碎片,这些材料在深度图中很容易识别),并防止了背景中的表面 向相机”塌陷”的现象(显示在(a)的左下角)。Mildenhall etal等人[33]的 噪声注入方法仅部分消除了这些伪影,并降低了重建质量(注意在遥远的树木深度缺乏细节)。查看补充视频以了解更多的可视化。
我们的正则化器具有直接的定义,根据由参数化每条射线的(归一化的)射线距离s和权重w的集合定义的 阶梯函数

我们使用归一化的射线距离s,因为使用t会显著增加远距离间隔的权重,并导致附近的间隔被有效地忽略。这个损失是沿着这个1D阶跃函数的所有点对之间的距离的积分,由NeRF MLP分配给每个点的权重w来缩放。我们称之为” 失真distortion“,因为它保留了由k-means最小化的失真的连续版本(尽管它也可以被认为是最大化了一种自相关)。通过设置w = 0,可以将这种损失降至最低(请记住,w总和不超过1,而不是正好1)。如果这是不可能的(即,如果射线是非空的),则通过将权重合并到尽可能小的区域中来最小化它。图6通过在toy直方图上显示这种损失的梯度来说明这种行为。

图6。我们的正则化器的梯度 ∇Ldist的可视化,作为s和w的函数,on a toy step function。我们的损失鼓励每条射线尽可能紧凑的,通过1)最小化每个间隔的宽度,2)拉近间隔距离,3)将权重整合成一个区间或少量附近的间隔,和4)驱动所有权重向零,当可能的时候(如整个射线空置)。
虽然公式14定义简单,但计算起来却不简单。但是因为ws()在每个区间内具有恒定值,所以我们可以将等式14重写为:
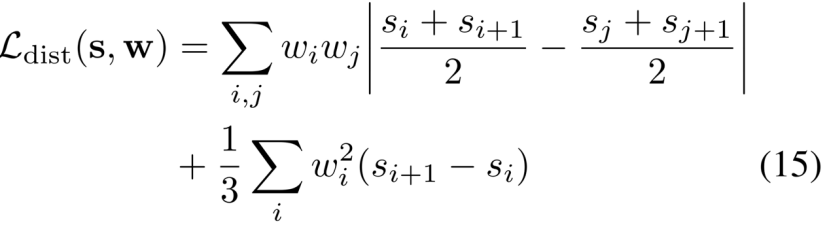
在这种形式下,我们的distortion失真 loss很容易计算。这种重新表述也为这种损失如何表现提供了一些直觉:第一项最小化所有区间中点对之间的加权距离,第二项最小化每个单独区间的加权大小。
5. Optimization

平均每批中所有射线(射线不包括在我们的标记中)。λ超参数平衡了我们的数据项

7.结论
我们已经提出了mip-NeRF 360,它是一个mip-NeRF扩展,设计用于具有不受约束的摄像机方位的真实世界场景。使用一种新颖的类似卡尔曼Kalman-like的场景参数化、一种有效的基于提议的由粗到细的提取框架proposal-based coarse-to-fine distillation framework以及一种为mip- NeRF射线间隔设计的正则化器,我们能够合成逼真的新颖视图和复杂的深度图,用于具有挑战性的无界真实世界场景,与mip-NeRF相比,均方误差降低了57%。
Original: https://blog.csdn.net/qq_43620967/article/details/124801893
Author: ysh9888
Title: Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/651043/
转载文章受原作者版权保护。转载请注明原作者出处!