

基于孪生网络的变化检测结构分析
目录
二、BIT(Bitemporal Image Transformer
前言
变化检测相较于其他cv任务来说,应该属于一个较为小众的领域了,但因为要需要复现BIT这篇论文,并且最近也在做变化检测相关的任务,所以就来讲解一下这篇论文和其设计思路。因为要复现的原因,所以这篇文章会对网络结构做一个详细的解读。
一、孪生网络 Siamese Network
在介绍BIT之前,简单介绍一下孪生网络的概念。孪生网络其实主要有两种形式, 一种为共享权重的一种为不共享权重的。这里只介绍共享权重的。


其实孪生网络可以认为就是一个网络拆开两份用,这里说拆开两份用,不是指建两个一模一样的网络,而是用一个网络,一份权重,同时用两张图片去训练这个网络。

以变化检测举例,当同一个网络送入两张相似的图片(AB)进行训练,并且loss的建立是依据两张图片的差别(label),那么反向传播训练后。孪生网络预测两张图片的输出特征图,可以认为越相似的输入图片, 其特征图中,相似处对应的向量矩阵越相似。我们就可以利用这个孪生网络生成的特征图,在CV领域去做类似于人脸身份识别,变化检测等上游任务,在NLP领域去判断这两个句子是否意思相近等。
更多的细节,也可以去搜相关方便的知识。
二、BIT( Bitemporal Image Transformer
BIT网络其实想将Transformer的思想引入变化检测这个领域。在分类的VIT中,网络实质上是用一个分类的token去学习整合transformer的特征的,然后依靠token进行分类预测的。BIT中就直观的认为,可以用一个semantic tokens去学习整合两张图片真正变化的部分,并且高维像素点代表的特征,也可以用一个semantic tokens去表示,那么网络即可以得到高效性和高性能。
整个BIT分为三部分,Backbone,Bitemporal Image Transformer和Prediction Head。其中Backbone为上面介绍的孪生网络,用来提取两张图片的相似特征图。Bitemporal Image Transformer则为Transormer提取特征模块,Prediction Head则为利用Transormer decoder出来的特征,生成原尺寸的分割图像。

Backbone:改进Resnet18的孪生网络
BIT中的Backbone孪生网络,其实是对经典的Resnet18网络做了微小的修改。经典的Resnet18网络的特点是 一共有五个stages,每个stages都会对特征图下采样2倍,即将特征图大小减半,维度乘二。
而BIT中则将Resnet18做出的改进主要有两点,一是将Resnet18中最后两个stages的下采样改为1,一方面防止特征图过小,导致空间信息的丢失,另外一方面增强了感受野。二是在Resnet18后面接上了一个双线性插值和一个逐点卷积来增加特征图尺寸和改变特征图的维度(论文里说的是逐点卷积,但代码中只是一个不改变shape的3×3卷积)
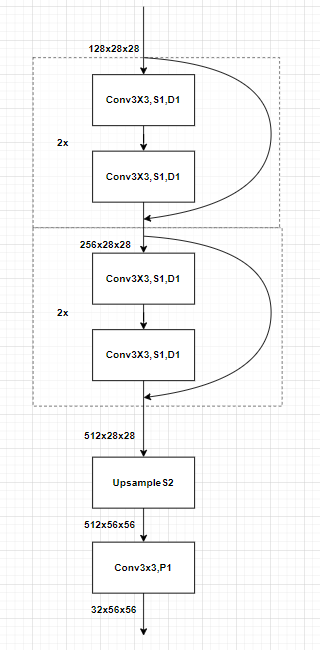
这里仅画出resnet18后半部分,因为前半部分是一样的,如果输入是3x224x224的图像,最后输出则为32x56x56的特征图。
这里BIT其实还提出了两个剪枝的版本, 既是分别去除resnet18的最后一层和最后两层,然后直接接上最后的上采样和输出卷积。
Bitemporal Image Transformer
整个Transformer的部分,大体可以分为三部分: Semantic Tokenizer,Encoder和Decoder。其中 Semantic Tokenizer是将由Backbone得到特征图转换为token的表达形式的过程,前面也说了,作者直观的认为,对于两幅图像的变化部分,可以使用一个token来进行表达,就像图像分类中,可以用token表达两张类别的差异一样。并且一个两幅图像的语义信息应该是可以共享的,所以作者设计出了孪生型的tokens(其实也就是把两幅特征图, 送到同一个Tokenizer的网络去)
而 Encoder和Decoder则为transformer处理特征的结构了。
Semantic Tokenizer

在NLP的tokenizer里,会将输入的句子分成若干个元素,并用token去表达每个元素。作者借鉴这种思想,将得到的特征图也分为若干个子图,并每一个都去映射成token,而为了去汇聚空间层面上的信息,作者则用了spatial_attention来提取空间信息,这样使得得到的token紧凑,语义信息丰富。
有关spatial_attention的具体知识可以看看这篇文Spatial Attention空间注意力及Resnet_cbam实现
这里有一个可调的参数,即具体要用多长的token来表达这些信息,我们下面的所有说明都以token长度为4来说明。所以整体semantic tokenizer可以用下面的结构图代替。(下图中的4均为token的长度)

根据这个semantic tokenizer的过程,我们就将backbone得到的特征图, 转换为了具有高维语义信息的token,就可以送入transformer进行处理了。
这里的tokenizer转换的网络同样也是孪生网络。
Transformer:Encoder
在从孪生型的tokenizer网络得到两个token后,我们将两个token concact起来送到transformer的encoder进行特征提取。 但其实作者还设计了代表位置信息的pos_token,其实这个position的token,在VIT中就有设计,因为transform把图片转成patch后,就丢失了patch和patch直接的空间联系了,所以需要加一个position token来表达这个先验知识(只不过在原版VIT中,作者做了实验,加和不加没有什么区别是了),但在BIT中,作者也做了实验,加了确实有效果,所以到底加不加这个position token,感觉还是和具体任务有关。

整体的encoder的结构其实和普通的VIT相比,并没有太大的区别。对于其中的多头注意力的解释可以看看这篇文章:多头注意力-Multi-Head Attention及其实现
其中多头注意力的形式如下。

这里说两个细节,具体实现起来,QKV可以拼成一个矩阵进行Linear线性层合成一步运算。,然后里面的norm是Layernorm。
其中MLP层结构如下,下面的32为token的长度。

这样一来,整个decoder的结构就比较清晰了。 (就像上面说的,和普通的VIT transform的decoder没有区别)
Transformer:Decoder
在BIT中,Decoder采用的孪生网络的形式,因为最终是要通过Decoder生成两张新特征图并且这两张新特征图应该具备区分两者异同点的特点。
当然,要先把encoder出来的token,重新分为两部分才能送入到decoder。并且像正常的decoder,也是需要把原始的特征图送入encoder的。

清楚VIT都知道,其实decoder就是把KV的输入,换成encoder的输出,并且输入decoder模块的为原始的特征图,这个过程可以理解成语言翻译的过程,特征图作为需要翻译的句子,token则为翻译的提供信息。
所以这里也不细分析了。
注:Decoder出来的图和进去的特征图尺寸和维度是一样的。
Prediction Head
prediction head部分就可以理解为目标检测领域里的输出头了。根据Decoder翻译出来的特征图信息(这里特征图信息已经包含了两张图直接的差别信息,即对于相似的部分,输出的部分应该相似)
所以这里输出头,其实就是将两张图对应位置相减,然后以FCN的思想上采样和经过一系列小卷积调整通道,变化图就生成了!

实验结果

; 总结
整体结构就捋了一遍,BIT的结构还是比较小巧且高效的。BIT的主要思想就是利用transformer的token这个概念,去提取语义信息,并利用孪生decoder的结构,去生成两个高维语义token之间真正的区别。
Original: https://blog.csdn.net/lzzzzzzm/article/details/124155057
Author: lzzzzzzm
Title: VisionTransformer(三)BIT—— 基于孪生网络的变化检测结构分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/650842/
转载文章受原作者版权保护。转载请注明原作者出处!