

关注公众号,发现CV技术之美
本篇分享论文 『Federated Learning over Wireless Networks: Optimization Model Design and Analysis』,无线网络中的联邦学习:优化模型设计与分析。
详细信息如下:


- 论文链接:https://ieeexplore.ieee.org/document/8737464
- 代码链接:https://github.com/IIT-Lab/OnDevAI
01
背景与引言
联邦学习基于数据隐私前提,并且拥有现代强大的处理器和低延迟的移动边缘网络支持,然而无线信道的不确定性和具有异构功率约束的移动设备尚未在联邦学习中得到充分探索。这些问题尤其影响到如下方面:
- 计算和通信延迟由学习准确度水平决定;
- 联邦学习时间和移动设备能耗之间的关系。
通过将无线网络上的联邦学习公式化为一个优化问题FedL来解决,作者利用问题结构将FedL分解并转换为三个凸子问题,并通过描述所有子问题的封闭形式解决方案来获得全局最优解,从而获取最优FedL学习时间、准确度水平和移动设备能量成本。
一方面,联邦学习与其他机器学习方案类似,联邦学习最关键的性能指标之一是收敛到预定义准确度水平所需的学习时间。然而,与传统的机器学习方法不同,联邦学习时间不仅包括移动设备(UE)的计算时间还包括通信时间(取决于移动设备的信道增益和更新数据大小)。
因此,第一个问题是: UE是否应该在计算上花费更多时间以实现高学习精度和更少通信更新,反之亦然?另一方面,由于参赛者资源有限,如何分配UE的计算和传输功率等资源以最大限度地降低能耗是主要关注的问题。因此,第二个问题是: 如何在最小化联邦学习时间和UE能源消耗这两个相互冲突的目标之间取得平衡。
为了解决这些问题,对于基于无线网络的联合学习问题设计和分析,具体可概括为:
- 提出了基于无线网络的联邦学习问题FedL,该问题包括两个方面的权衡 (1)使用Pareto效率模型的学习时间与UE能耗;(2) 通过寻找最优的学习精度参数来确定计算与通信学习时间。
- 利用变量分解方法将FedL分解为三个凸子问题,所有子问题的组合解可以提供FedL的全局最优解;
- 进一步提供了广泛的数值结果来检验:UE异构性的影响、UE能量成本与系统学习时间之间的关系以及计算与通信时间的比例对最佳精度水平的影响。
02
FedL解决方案
我们考虑由一个基站(BS)和N个UE的集合组成的无线多用户系统,其中每个参与方UE存储本地数据集Dn,然后我们可以通过以下方式来定义总数据大小D=D1+…+Dn。在监督学习设置的示例中,Dn被定义作为一组输入输出对(xi,yi),其中xi是具有d个特征的输入样本向量,yi则是对应标签。
数据可以通过使用UE来生成(例如通过与移动应用程序的交互),基于UE数据机器学习应用程序可以用于无线网络。在典型的学习问题中,对于输入样本数据(xi,yi)其任务是基于损失函数fi(w)并表征输出yi的模型参数w。关于n个UE数据集上损失函数被定义为:

然后,学习模型是最小化全局损失函数问题:

基于无线网络的联邦学习:在UE参与方,更新分为两个阶段(计算和通信):首先,每个UE在其本地计算问题:

接着,所有UE共享无线环境并向BS发送W(t)n和梯度∇J(t)n。在BS处则汇总了以下所有来自UE信息,并反馈给所有参与UE:

进一步而言,FedL通过多次全局迭代以达到全局精度水平ε,并基于UE和BS交互完成每次全局迭代。参与方UE在每个计算阶段将使用本地训练数据Dn最小化本地损失函数Fn(Wn),通过多次本地迭代达到精度阈值θ,然后使用无线媒体共享方案(例如分时TDMA)将更新发送到BS。随后,BS分别聚合接收的局部模型参数和梯度,在下一次全局迭代中更新并然后广播给所有参与方UE以最小化全局损失函数。
FedL同时受全局精度ε和局部精度θ的影响,当ε和θ较小(更准确)时,FedL需要运行更多的全局迭代次数。此外,每次全局迭代都包含计算时间和上行通信时间,其中计算时间取决于局部迭代的次数,经过证明可知其收敛时间上界为O(log(1/θ)),如果用Tcmp表示一次局部迭代的时间,那么对于某个条件数v其在一个全局迭代中的计算时间是vlog(1/θ) Tcmp,接着我们定义Tcom表示一次全局迭代的通信时间,因此FedL一次全局迭代的总时间定义为:

在本文中,我们考虑一个固定的全局精度ε所需要的时间开销,因此在这里将O(log(1/θ))归一化为1以便于表示K(θ)=1/(1-θ),此外我们还将v归一化为1从而可以将v吸收到Tcmp中作为一次局部计算迭代的上界。综上来看,可以得出FedL学习时间上界为K(θ)Tglob(θ)。
计算模型:由于所有样本{xi,yi}且i∈Dn具有相同的数据位数大小,因此第n个UE运行一次本地迭代所需的CPU周期数为cnDn(cn表示执行一个数据样本的CPU周期数),并使用fn表示CPU周期频率。那么对于第n个UE而言,计算一次局部迭代的CPU能耗可以表示如下:
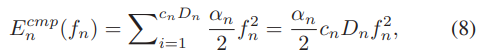
其中αn/2是UE计算芯片组的有效电容系数,此外UE每次局部迭代的计算时间为cnDn/fn。
通信模型:在FedL中针对UE的通信阶段,本文考虑了一种用于UE的分时多址协议,需要注意的是,这种分时模型是不受限制的,因为其他方案也可以应用于FedL。关于第n个UE的可实现传输速率定义如下:

其中B是带宽,N0是背景噪声,Pn是发射功率,Hn是信道增益,进一步假设Hn在FedL学习时间内是常数,那么第n个UE所分配的通信时间的比例则记为Tn,UE的参数Wn与梯度∇Jn大小记为Sn,并假设它们的大小在整个FedL学习过程中是恒定的,则每个UE的传输速率为:

这被证明是最节能的传输策略,为了在持续时间Tn内发送Sn,则UE能量消耗表达式如下:

FedL方案:FedL全局最优解可以拆分为若干子问题的组合解,这个定理的证明很简单,其思想是利用KKT条件来寻找FedL的驻点。然后,可以将KKT条件方程分解成若干组,每一组都与子问题的KKT条件完全匹配,可以分别求解其子问题的唯一闭合解。
因此,这个唯一的驻点也是FedL的全局最优解。通常,每个UE往往有两个独立的处理器:一个用于移动应用的CPU,另一个用于无线电控制功能的基带CPU。通过它们可以揭示通信成本比计算成本高多少,从而确定最佳局部精度水平。
关于FedL伪代码如下所示(即如何将UE分为三组子问题:N1由一组总是运行其最大频率的瓶颈UE构成、N2由以最小频率也能在计算截止日期之前完成任务的强UE组构成、N3则是在其可行集的内部具有最佳频率的UE组)。

03
实验结果
实验设置:通信和计算模型都遵循固定设置,UE数量增加到50并且所有UE具有相同的fmaxn=2.0GHz,cn=20cycles/bit。此外还定义了两个新参数Lcmp和Lcom,分别用以解决FedL中关于计算和通信阶段的UE异构性,如下所示:

可以看出,Lcmp和Lcom值越高表明UE的异质性水平越高。例如,由于不平衡的数据分布或UE配置使得具有最小频率的UE仍然与具有最大频率的UE得到相同的计算时间,Lcmp=1可以被认为是高度异质性水平。异质性的程度由两种不同的参数设置控制,基于Dmin/Dmax∈{1.0,0.2,0.001}来生成数据集Dn,对于不同的Lcmp值,所有UE的平均数据保持在相同的值(7.5MB)。
另一方面,为了改变Lcom值,基于UE和BS之间的距离d使得dmin/dmax∈{1.0,0.2,0.001},同样对于不同的Lcom值,所有UE的平均距离保持在26m。此外在所有场景中,当变化Lcom时,我们固定Lcmp=0.3,当变化Lcmp时,我们固定Lcom=0.48。
UE异构性影响:如下图4所示,增加Lcmp和Lcom会强制使最优fn和Tn 具有更多样化的值,从而分别增加计算和通信时间。进一步地,我们观察到高水平的UE异构性对FedL系统具有负面影响,如图6(a)和6(b)所示,会使得总成本(FedL的目标)分别随着Lcmp和Lcom的值的增加而增加。


FedL最优权衡:如上图6所示,这条曲线显示了最小化时间成本K(θ)Tglob和能源成本K(θ)Eglob这两个相互冲突的目标之间的权衡,我们可以在增加一种成本的情况下减少另一种目标的成本。此外,该图还表明,当系统具有低水平的UE异构性时,FedL的Pareto曲线更有效(例如,较小的Lcmp或Lcom值)。
超参数η的影响:通过在如下图7中改变k来量化η对最优θ∗的影响。显然可以观察到当k非常小或非常大时,会驱动最优θ∗中相应的η值分别按图8(a)或图8(b)所示的比例变化,这也侧面驱动对应的θ∗值进行优化。
然而,例如在具有50个参与方UE的情况下,当k非常大时,η和θ∗会减小到较小的值,这种差异的主要原因是由于无线共享性质:通信时间随着UE数量的增加而缩放,这使得当k增加后导致时间部分较小。从图7和图8总结可以发现:当Lcmp(Lcom) 值越高,计算时间的部分越高(越低),这同样使得η和θ∗的值越高(越低)。


04
FedL总结
本文研究了一种分散的机器学习方案,即无线网络上的联邦学习,其中训练模型被分发到参与的移动设备上,对其本地数据执行训练计算。以往工作尚不清楚计算和通信延迟如何影响系统学习时间,尤其是当联邦学习在无线网络上使用时。
因此,本文首先提供了一个通过无线网络实现联邦学习的模型来解决这个问题,每个移动设备不仅计算本地学习任务,而且还计划以分时方式传输更新参数。具体而言,将无线网络FL优化问题分解为三个具有凸结构的子问题,分别描述了移动设备的计算和通信延迟如何影响UE能耗、系统学习时间和学习精度参数之间的各种权衡,并量化了移动设备的计算和通信延迟。
总得来说,本文可以为无线网络上的联邦学习系统设计提供参考,并且还对未来可改进方向(计算成本以及通信损耗之间的权衡)进行了相关思考。

END
加入「计算机视觉 」 交流群👇备注:CV

Original: https://blog.csdn.net/moxibingdao/article/details/126615830
Author: 我爱计算机视觉
Title: 无线网络中的联邦学习:优化模型设计与分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/650495/
转载文章受原作者版权保护。转载请注明原作者出处!