

PP-OCR文字检测与识别
一、配置Paddle环境
创建虚拟环境
conda create --name pp python=3.7

创建完成后激活环境
conda activate pp
登录飞桨的官网下载最新的paddle,官网地址:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
选择合适的CUDA版本,然后会在下面生成对应的命令。
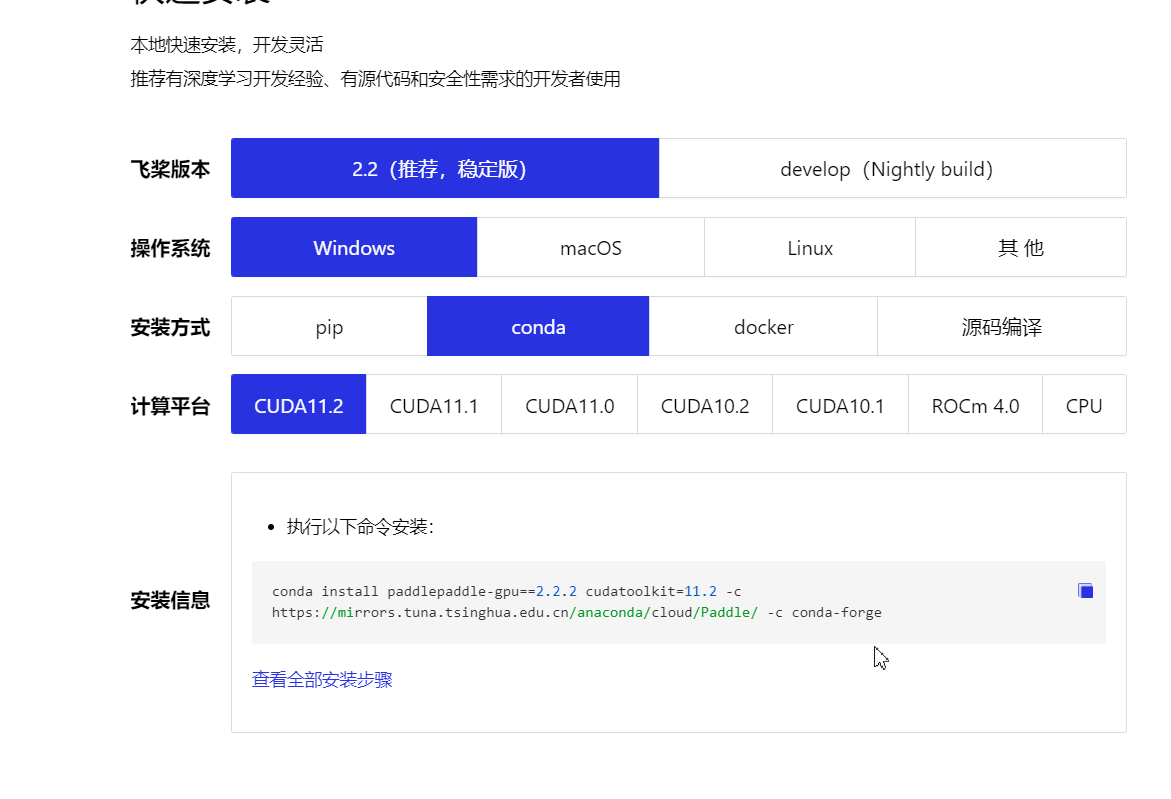
然后,复制命令即可
conda install paddlepaddle-gpu==2.2.2 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
二、配置PaddleOCR
下载地址:(https://gitee.com/paddlepaddle/PaddleOCR
将其下载到本地,然后解压配置环境。
1、安装python包
1、yaml
pip install pyyaml
2、imgaug
pip install imgaug
3、pyclipper
pip install pyclipper
4、lmdb
pip install lmdb
5、Levenshtein
pip install Levenshtein
6、tqdm
pip install tqdm
2、测试环境
模型列表
模型简介模型名称推荐场景检测模型方向分类器识别模型中英文超轻量PP-OCRv2模型(13.0M)ch_PP-OCRv2_xx移动端&服务器端
推理模型 训练模型 推理模型 预训练模型 推理模型 训练模型
中英文超轻量PP-OCR mobile模型(9.4M)ch_ppocr_mobile_v2.0_xx移动端&服务器端
推理模型 预训练模型 推理模型 预训练模型 推理模型 预训练模型
中英文通用PP-OCR server模型(143.4M)ch_ppocr_server_v2.0_xx服务器端
推理模型 预训练模型 推理模型 预训练模型 推理模型 预训练模型
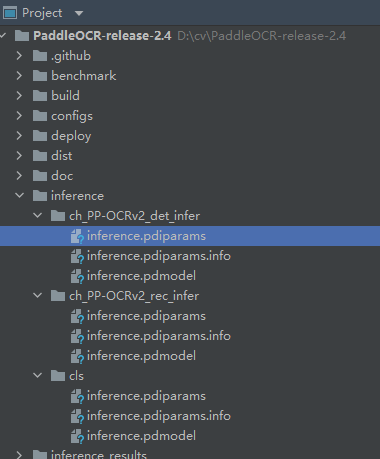
选择上面的一组模型放入到inference文件夹中,注意:是一组,包括:监测模型、方向分类器、识别模型。如下:
PaddleOCR-release-2.4
└─inference
├─ch_PP-OCRv2_det_infer #检测模型
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
├─ch_PP-OCRv2_rec_infer #识别模型
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
└─cls #方向分类器
├─inference.pdiparams
├─inference.pdiparams.info
└─inference.pdmodel
将待检测的图片放在./doc/imgs/文件夹下面,然后执行命令:
python tools/infer/predict_system.py --image_dir="./doc/imgs/0.jpg" --det_model_dir="./inference/ch_PP-OCRv2_det_infer/" --cls_model_dir="./inference/cls/" --rec_model_dir="./inference/ch_PP-OCRv2_rec_infer/" --use_angle_cls=true
然后在inference_results文件夹中查看结果,例如:
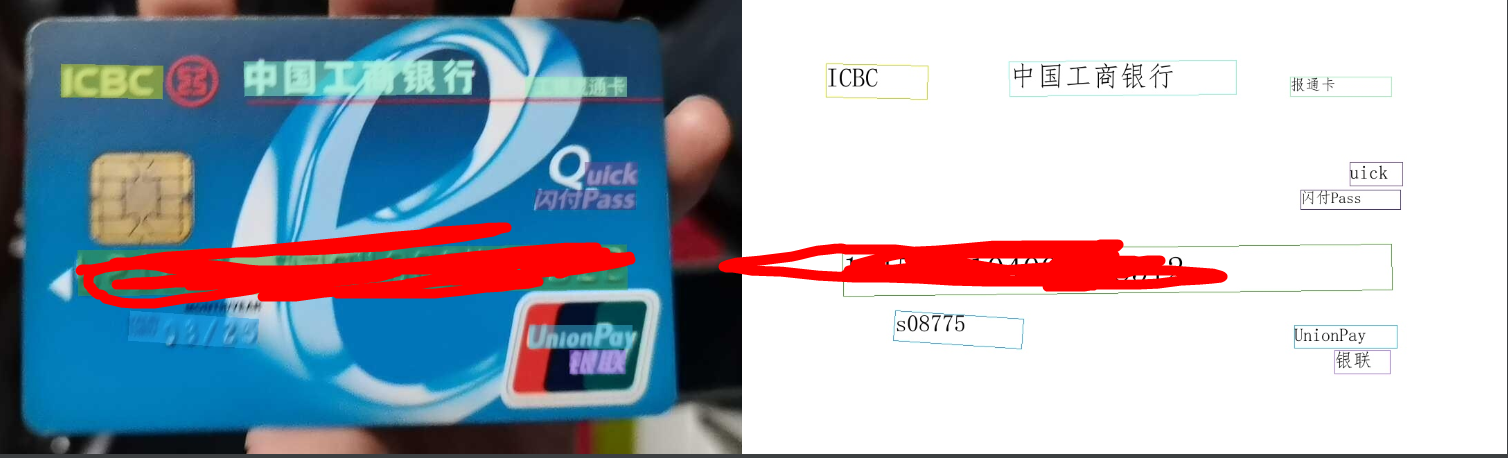
如果能看到结果就说明环境是ok的。
更多的命令,如下:
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/ch_PP-OCRv2_det_infer/" --cls_model_dir="./inference/cls/" --rec_model_dir="./inference/ch_PP-OCRv2_rec_infer/" --use_angle_cls=true
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/ch_PP-OCRv2_det_infer/" --rec_model_dir="./inference/ch_PP-OCRv2_rec_infer/" --use_angle_cls=false
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/ch_PP-OCRv2_det_infer/" --rec_model_dir="./inference/ch_PP-OCRv2_rec_infer/" --use_angle_cls=false --use_mp=True --total_process_num=6
三、标注工具PPOCRLabel
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
由于PaddleOCR已经包含PPOCRLabel,可以直接运行,命令如下:
cd ./PPOCRLabel # 切换到PPOCRLabel目录
python PPOCRLabel.py --lang ch

点击自动标注后就能看到自动标注的结果,用户根据自己的需求微调和修改,非常简单。
更多的方式和注意事项,详见下面
1. 安装与运行
1.1 安装PaddlePaddle
pip3 install --upgrade pip
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照安装文档中的说明进行操作。
1.2 安装与运行PPOCRLabel
PPOCRLabel可通过whl包与Python脚本两种方式启动,whl包形式启动更加方便,python脚本启动便于二次开发
1.2.1 通过whl包安装与运行
Windows
pip install PPOCRLabel
PPOCRLabel --lang ch
注意:通过whl包安装PPOCRLabel会自动下载
paddleocrwhl包,其中shapely依赖可能会出现[winRrror 126] 找不到指定模块的问题。的错误,建议从这里下载并安装
Ubuntu Linux
pip3 install PPOCRLabel
pip3 install trash-cli
PPOCRLabel --lang ch
MacOS
pip3 install PPOCRLabel
pip3 install opencv-contrib-python-headless==4.2.0.32
PPOCRLabel --lang ch
如果上述安装出现问题,可以参考3.6节 错误提示
1.2.2 本地构建whl包并安装
cd PaddleOCR/PPOCRLabel
python3 setup.py bdist_wheel
pip3 install dist/PPOCRLabel-1.0.2-py2.py3-none-any.whl -i https://mirror.baidu.com/pypi/simple
1.2.3 通过Python脚本运行PPOCRLabel
如果您对PPOCRLabel文件有所更改,通过Python脚本运行会更加方面的看到更改的结果
cd ./PPOCRLabel
python PPOCRLabel.py --lang ch
2. 使用
2.1 操作步骤
- 安装与运行:使用上述命令安装与运行程序。
-
打开文件夹:在菜单栏点击 “文件” – “打开目录” 选择待标记图片的文件夹[1].
-
自动标注:点击 “自动标注”,使用PPOCR超轻量模型对图片文件名前图片状态[2]为 “X” 的图片进行自动标注。
- 手动标注:点击 “矩形标注”(推荐直接在英文模式下点击键盘中的 “W”),用户可对当前图片中模型未检出的部分进行手动绘制标记框。点击键盘Q,则使用四点标注模式(或点击”编辑” – “四点标注”),用户依次点击4个点后,双击左键表示标注完成。
- 标记框绘制完成后,用户点击 “确认”,检测框会先被预分配一个 “待识别” 标签。
- 重新识别:将图片中的所有检测画绘制/调整完成后,点击 “重新识别”,PPOCR模型会对当前图片中的 所有检测框重新识别[3]。
- 内容更改:双击识别结果,对不准确的识别结果进行手动更改。
- 确认标记:点击 “确认”,图片状态切换为 “√”,跳转至下一张。
- 删除:点击 “删除图像”,图片将会被删除至回收站。
- 导出结果:用户可以通过菜单中”文件-导出标记结果”手动导出,同时也可以点击”文件 – 自动导出标记结果”开启自动导出。手动确认过的标记将会被存放在所打开图片文件夹下的 _Label.txt_中。在菜单栏点击 “文件” – “导出识别结果”后,会将此类图片的识别训练数据保存在 _crop_img_文件夹下,识别标签保存在 _rec_gt.txt_中[4]。
2.2 注意
[1] PPOCRLabel以文件夹为基本标记单位,打开待标记的图片文件夹后,不会在窗口栏中显示图片,而是在点击 “选择文件夹” 之后直接将文件夹下的图片导入到程序中。
[2] 图片状态表示本张图片用户是否手动保存过,未手动保存过即为 “X”,手动保存过为 “√”。点击 “自动标注”按钮后,PPOCRLabel不会对状态为 “√” 的图片重新标注。
[3] 点击”重新识别”后,模型会对图片中的识别结果进行覆盖。因此如果在此之前手动更改过识别结果,有可能在重新识别后产生变动。
[4] PPOCRLabel产生的文件放置于标记图片文件夹下,包括一下几种,请勿手动更改其中内容,否则会引起程序出现异常。
文件名说明Label.txt检测标签,可直接用于PPOCR检测模型训练。用户每确认5张检测结果后,程序会进行自动写入。当用户关闭应用程序或切换文件路径后同样会进行写入。fileState.txt图片状态标记文件,保存当前文件夹下已经被用户手动确认过的图片名称。Cache.cach缓存文件,保存模型自动识别的结果。rec_gt.txt识别标签。可直接用于PPOCR识别模型训练。需用户手动点击菜单栏”文件” – “导出识别结果”后产生。crop_img识别数据。按照检测框切割后的图片。与rec_gt.txt同时产生。
3. 说明
3.1 快捷键
快捷键说明Ctrl + shift + R对当前图片的所有标记重新识别W新建矩形框Q新建四点框Ctrl + E编辑所选框标签Ctrl + R重新识别所选标记Ctrl + C复制并粘贴选中的标记框Ctrl + 鼠标左键多选标记框Backspace删除所选框Ctrl + V确认本张图片标记Ctrl + Shift + d删除本张图片D下一张图片A上一张图片Ctrl++缩小Ctrl–放大↑→↓←移动标记框
3.2 内置模型
- 默认模型:PPOCRLabel默认使用PaddleOCR中的中英文超轻量OCR模型,支持中英文与数字识别,多种语言检测。
-
模型语言切换:用户可通过菜单栏中 “PaddleOCR” – “选择模型” 切换内置模型语言,目前支持的语言包括法文、德文、韩文、日文。具体模型下载链接可参考PaddleOCR模型列表.
-
自定义模型:如果用户想将内置模型更换为自己的推理模型,可根据自定义模型代码使用,通过修改PPOCRLabel.py中针对PaddleOCR类的实例化,通过修改PPOCRLabel.py中针对PaddleOCR类的实例化) 实现,例如指定检测模型:
self.ocr = PaddleOCR(det=True, cls=True, use_gpu=gpu, lang=lang),在det_model_dir中传入 自己的模型即可。
3.3 导出标记结果
PPOCRLabel支持三种导出方式:
- 自动导出:点击”文件 – 自动导出标记结果”后,用户每确认过一张图片,程序自动将标记结果写入Label.txt中。若未开启此选项,则检测到用户手动确认过5张图片后进行自动导出。
默认情况下自动导出功能为关闭状态
- 手动导出:点击”文件 – 导出标记结果”手动导出标记。
- 关闭应用程序导出
3.4 导出部分识别结果
针对部分难以识别的数据,通过在识别结果的复选框中 取消勾选相应的标记,其识别结果不会被导出。被取消勾选的识别结果在标记文件 label.txt 中的 difficult 变量保存为 True 。
注意:识别结果中的复选框状态仍需用户手动点击确认后才能保留
3.5 数据集划分
在终端中输入以下命令执行数据集划分脚本:
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data
参数说明:
trainValTestRatio是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2datasetRootPath是PPOCRLabel标注的完整数据集存放路径。默认路径是PaddleOCR/train_data分割数据集前应有如下结构:
|-train_data
|-crop_img
|- word_001_crop_0.png
|- word_002_crop_0.jpg
|- word_003_crop_0.jpg
| ...
| Label.txt
| rec_gt.txt
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
3.6 错误提示
- 如果同时使用whl包安装了paddleocr,其优先级大于通过paddleocr.py调用PaddleOCR类,whl包未更新时会导致程序异常。
- PPOCRLabel 不支持对中文文件名的图片进行自动标注。
- 针对Linux用户:如果您在打开软件过程中出现objc[XXXXX]开头的错误,证明您的opencv版本太高,建议安装4.2版本:
pip install opencv-python==4.2.0.32
- 如果出现
Missing string id开头的错误,需要重新编译资源:
pyrcc5 -o libs/resources.py resources.qrc
- 如果出现
module 'cv2' has no attribute 'INTER_NEAREST'错误,需要首先删除所有opencv相关包,然后重新安装4.2.0.32版本的headless opencv
pip install opencv-contrib-python-headless==4.2.0.32
四、训练检测器
1、制作数据集
完成数据的标注就可以看是训练检测器了。找到Lable.txt,将其中一部分放到train_label.txt ,将一部分放到test_label.txt,将图片放到ppocr( 这个文件夹的名字和标注时的图片文件夹的名字一致),如下:
/PaddleOCR/train_data/icdar2015/text_localization/
└─ ppocr/ 图片存放的位置
└─ train_label.txt icdar数据集的训练标注
└─ test_label.txt icdar数据集的测试标注
自定义切分数据集代码。我在这里没有使用官方给的切分方式,是自定义的切分方式。
import os
import shutil
from sklearn.model_selection import train_test_split
label_txt='./ppocr/Label.txt'
with open(label_txt, 'r') as f:
txt_List=f.readlines()
trainval_files, val_files = train_test_split(txt_List, test_size=0.1, random_state=42)
print(trainval_files)
f = open("train_label.txt", "w")
f.writelines(trainval_files)
f.close()
f = open("test_label.txt", "w")
f.writelines(val_files)
f.close()
for txt in txt_List:
image_name=txt.split('\t')[0]
new_path="./tmp/"+image_name.split('/')[1]
shutil.move(image_name, new_path)
print(image_name)
如果路径不存在,请手动创建。
2、下载预训练模型
然后下载预训练模型,将其放到pretrain_models文件夹中,命令如下:
根据backbone的不同选择下载对应的预训练模型
下载MobileNetV3的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
或,下载ResNet18_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet18_vd_pretrained.pdparams
或,下载ResNet50_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet50_vd_ssld_pretrained.pdparams
3、修改配置文件
然后修改该config文件,路径: configs/det/det_mv3_db.yml,打开文件对里面的参数进行修改该。
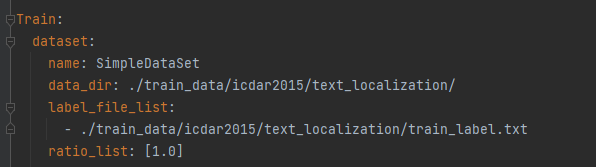
按照自己定义的路径,修改训练集的路径。
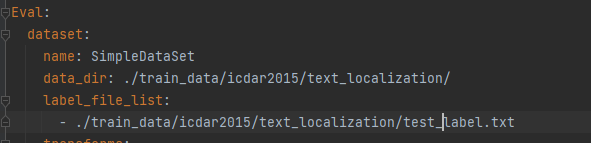
按照自己定义的路径,修改验证集的路径。
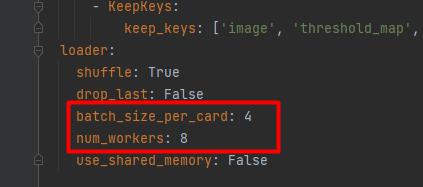
对BatchSize的修改。
; 4、开启训练
完成上面的工作就可以启动训练了,在pycharm的Terminal中输入命令:
注意:在PaddleOCR的根目录执行命令。
单机单卡训练 mv3_db 模型
python tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
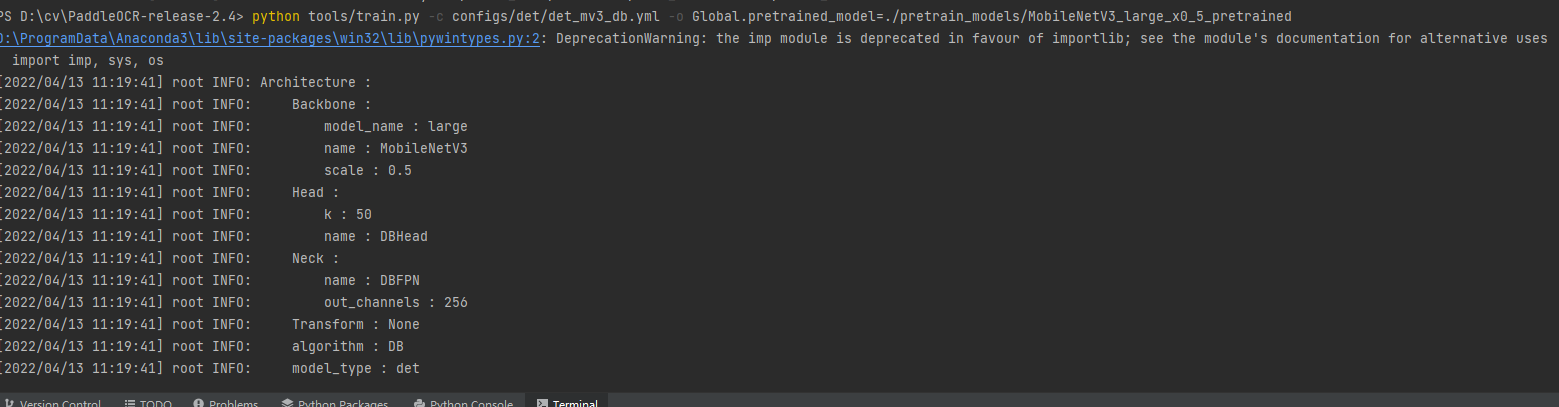
更多的训练方式如下:
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
五、训练识别器
图片裁剪与数据集生成
在训练识别器之间,我们还有一步要做,就是将标注的数据裁剪出来。裁剪代码如下:
import json
import os
import numpy as np
import cv2
def get_rotate_crop_image(img, points):
'''
img_height, img_width = img.shape[0:2]
left = int(np.min(points[:, 0]))
right = int(np.max(points[:, 0]))
top = int(np.min(points[:, 1]))
bottom = int(np.max(points[:, 1]))
img_crop = img[top:bottom, left:right, :].copy()
points[:, 0] = points[:, 0] - left
points[:, 1] = points[:, 1] - top
'''
assert len(points) == 4, "shape of points must be 4*2"
# 求范数,得到宽度
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]),
np.linalg.norm(points[2] - points[3])))
# # 求范数,得到高度
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]),
np.linalg.norm(points[1] - points[2])))
pts_std = np.float32([[0, 0], [img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height]])
#计算得到转换矩阵
M = cv2.getPerspectiveTransform(points, pts_std)
#实现透视变换
dst_img = cv2.warpPerspective(
img,
M, (img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def write_txt_img(src_path,label_txt):
with open(src_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
print(line)
content = line.split('\t')
print(content[0])
imag_name = content[0].split('/')[1]
image_path = './train_data/icdar2015/text_localization/' + content[0]
img = cv2.imread(image_path)
list_dict = json.loads(content[1])
nsize = len(list_dict)
print(nsize)
num = 0
for i in range(nsize):
print(list_dict[i])
lin = list_dict[i]
info = lin['transcription']
info=info.replace(" ","")
points = lin['points']
points = [list(x) for x in points]
points = np.float32([list(map(float, item)) for item in points])
imag_name=str(num)+"_"+imag_name
save_path = './train_data/rec/train/' + imag_name
dst_img = get_rotate_crop_image(img, points)
cv2.imwrite(save_path, dst_img)
label_txt.write('train/'+imag_name+'\t'+info+'\n')
num=num+1
if not os.path.exists('train_data/rec/train/'):
os.makedirs('train_data/rec/train/')
src_path = r"./train_data/icdar2015/text_localization/train_icdar2015_label.txt"
label_txt=r"./train_data/rec/rec_gt_train.txt"
src_test_path = r"./train_data/icdar2015/text_localization/test_icdar2015_label.txt"
label_test_txt=r"./train_data/rec/rec_gt_test.txt"
with open(label_txt, 'w') as w_label:
write_txt_img(src_path,w_label)
with open(label_test_txt, 'w') as w_label:
write_txt_img(src_test_path, w_label)
获取标注区域的图像主要用到了getPerspectiveTransform计算转换的矩阵和warpPerspective函数透视转换的组合。
获取到图像和标注的内容,生成文字识别通用数据集(SimpleDataSet)。
数据集的格式:
注意: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
" 图像文件名 图像标注信息 "
train/word_001.jpg 简单可依赖
train/word_002.jpg 用科技让复杂的世界更简单
生成数据集的路径如下:
修改配置文件,在configs/rec/中,用rec_icdar15_train.yml 举例:
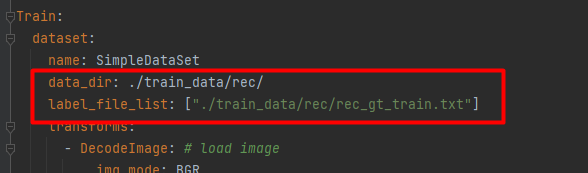
设置训练集的路径。
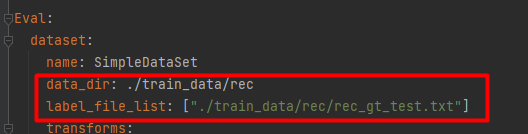
设置验证集的路径。

调整训练集和验证集的图片尺寸
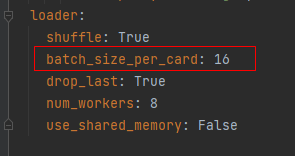
设置训练和验证的batchsize。
完成上面的参数的设置,然后开始训练,命令如下:
python tools/train.py -c configs/rec/rec_icdar15_train.yml

Original: https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/124145612
Author: AI浩
Title: PaddleOCR文字检测、标注与识别详细记录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/649213/
转载文章受原作者版权保护。转载请注明原作者出处!