

个人复习总结(jupyter)
1 导入必要的库和创建数据
import pandas as pd
路径='D:/数据分析有关数据集/十套练习/exercise_data/chipotle.tsv'
数据=pd.read_csv(路径,sep='\t')
#'\t'是到下一个制表单位,就是向后数第9位,即Tab,也叫横向制表符
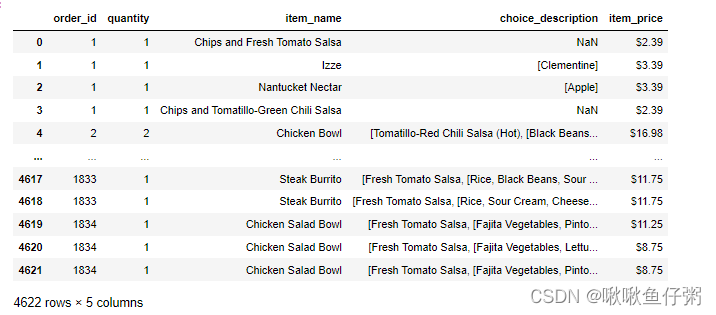
数据

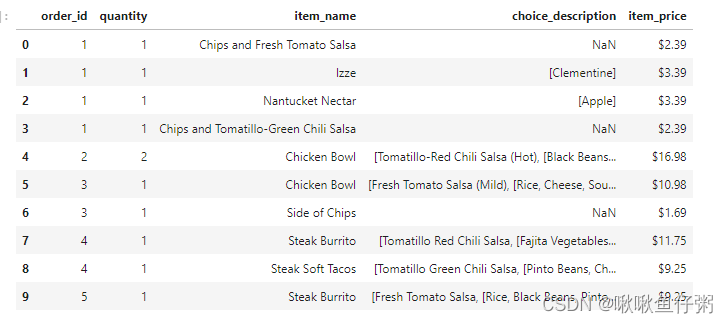
2 查看前10行内容
数据.head(10)
3数据集中有多少行和列(columns)
数据.shape #查看数据的形状,返回(行数、列数)
数据.shape[0] #数据集中有多少个行
数据.shape[1] #数据集中有多少个列(columns)

4打印出全部的列名称
数据.columns #打印出全部的列名称

5数据集的索引是怎样的
数据.index
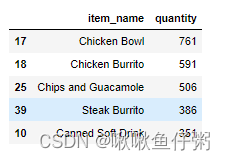
6被下单数最多商品(item)是什么?
数据3=数据.groupby('item_name',as_index=False).agg({'quantity':'sum'})
#as_index=True时,“as_index”就类似表示将组标签(类似“主键”)作为索引;
#as_index=False时,索引为0,1,2,3…
#agg是对于列聚合
数据3.sort_values(by='quantity',ascending=False,inplace=True)
#对quantity进行倒序排序,对数据3原表操作
数据3.head()
7在item_name这一列中,一共有多少种商品被下单?
数据['item_name'].nunique() #nunique为去重

8一共下单了多少商品
数据['quantity'].sum()

9将item_price转换为浮点数
#去掉item_price里的货币符号,并变成浮点数
#字符串取切片从第二位到最后一位,也就是索引1到-1,目的是去掉$符号。然后再转化为浮点型,不然object没办法进行统计运算。
#apply可以运行括号里的函数
dollarizer = lambda x: float(x[1:-1])
数据['item_price']=数据['item_price'].apply(dollarizer)
数据
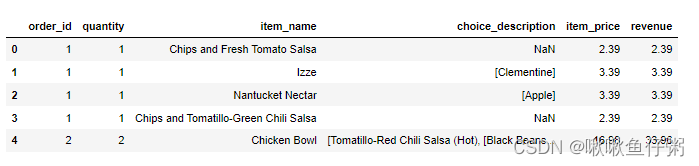
10在该数据集对应的时期内,收入(revenue)是多少
#在该数据集对应的时期内,收入(revenue)是多少?
数据['revenue']=round(数据['quantity']*数据['item_price'],2)
数据.head()
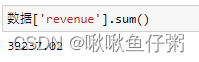
数据['revenue'].sum()
Original: https://blog.csdn.net/m0_71361876/article/details/126198547
Author: 啾啾鱼仔粥
Title: Python数据分析1实战(1)——探索Chipotle快餐数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/640284/
转载文章受原作者版权保护。转载请注明原作者出处!