

题目目录
- 1. 打开 Rstudio 告诉我它的工作目录。
- 2. 新建6个向量,基于不同的数据类型。(重点是字符串,数值,逻辑值)
- 3. 告诉我在你打开的rstudio里面 getwd() 代码运行后返回的是什么?
- 4. 新建一些数据结构,比如矩阵,数组,数据框,列表等重点是数据框,矩阵)
- 5. 在你新建的数据框进行切片操作,比如首先取第1,3行, 然后取第4,6列
- 6. 使用data函数来加载R内置数据集,找到rivers的描述。
- 7. 下载 [https://www.ncbi.nlm.nih.gov/sra?term=SRP133642](https://www.ncbi.nlm.nih.gov/sra?term=SRP133642) 里面的 RunInfo Table 文件读入到R里面,了解这个数据框,多少列,每一列都是什么属性的元素。
- 8. 下载 [https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE111229](https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE111229) 里面的样本信息sample.csv读入到R里面,了解这个数据框,多少列,每一列都是什么属性的元素。
- 9. 把前面两个步骤的两个表(RunInfo Table 文件,样本信息sample.csv)关联起来,使用merge函数。
- 10. 对前面读取的RunInfo Table文件在R里面探索其MBases列。把前面读取的样本信息表格的样本名字根据下划线分割看第3列元素的统计情况。第三列代表该样本所在的plate。根据plate把关联到的RunInfo Table信息的MBases列分组检验是否有统计学显著的差异。分组绘制箱线图(boxplot),频数图(hist),以及密度图(density) 。
- 11. 使用ggplot2把上面的图进行重新绘制。
- 12. 使用ggpubr把上面的图进行重新绘制。
前面学习了Linux的基础操作和一些文件格式的shell练习,接下来开始学习R语言。R语言是生信学习的重要基石。我的学习路线是过一遍教学课程,然后用题目来加深自己的理解。
推荐几个优秀课程:
R语言入门与数据分析:https://www.bilibili.com/video/BV19x411X7C6
R语言与生物信息绘图:https://www.bilibili.com/video/BV1XJ411m73p
生信人应该这样学R语言:https://www.bilibili.com/video/BV1cs411j75B
建议搭配《R语言实战(第2版)》按顺序进行学习。最后一个可看可不看。
本文的题目来自Jimmy老师的R语言练习题:http://www.bio-info-trainee.com/3793.html
博主将题目进行了整理,并且对Jimmy老师的部分答案进行了适量修改。需要代码和文件的可以私信我。学就完事了…
- 打开 Rstudio 告诉我它的工作目录。
getwd()
- 新建6个向量,基于不同的数据类型。(重点是字符串,数值,逻辑值)
有两种最基本的数据类型:原子向量(atomic vector)和泛型向量(generic vector)。原子向量是包含单个数据类型的数组。 原子向量是包含单个数据类型(逻辑类型、实数、复数、字符串或原始类型)的数组。泛型向量也称为列表,是原子向量的集合。
a1 c(T, F, T, F)
class(a1)
a2 c(15, 18, 25, 14, 19)
class(a2)
a3 c(1+2i, 0+1i, 39+3i, 12+2i)
class(a3)
a4 c("Bob", "Ted", "Carol", "Alice")
class(a4)
a5 matrix(1:20,4,5)
class(a5)
a6 list(1:20)
class(a6)
- 告诉我在你打开的rstudio里面 getwd() 代码运行后返回的是什么?
getwd()
- 新建一些数据结构,比如矩阵,数组,数据框,列表等重点是数据框,矩阵)
rnames c("R1", "R2", "R3", "R4", "R5")
cnames c("C1", "C2", "C3", "C4")
mymatrix matrix(1:20, 5, 4, byrow=T, dimnames=list(rnames, cnames))
mymatrix
dim1 c("A1", "A2")
dim2 c("B1", "B2", "B3")
dim3 c("C1", "C2", "C3", "C4")
myarray array(1:24, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))
myarray
dnames c("ergou", "lisi", "zhangsan")
dages c(12, 23, 45)
dgender c("man", "Woman", "man")
dheight c(160, 170, 180)
dweight c(50, 55, 75)
dwage c(5000, 4000, 3000)
mydataframe data.frame(dages,dnames,dgender,dheight,dweight,dwage)
mydataframe
g "My First List"
h c(25, 26, 18, 39)
j matrix(1:10, nrow=5)
k c("one", "two", "three")
mylist list(title=g, ages=h, j, k)
mylist


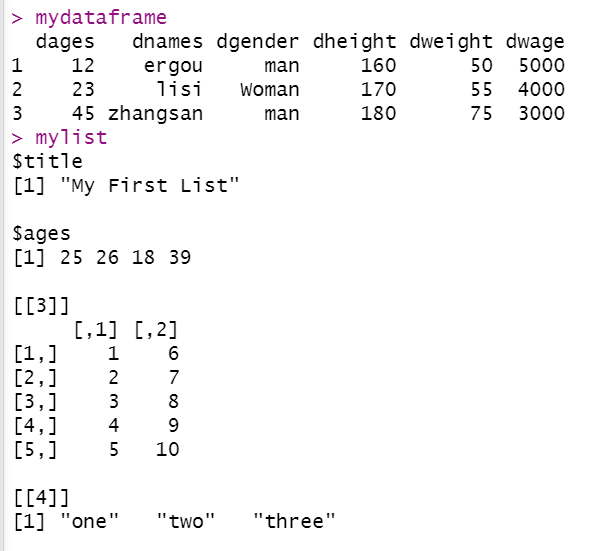
- 在你新建的数据框进行切片操作,比如首先取第1,3行, 然后取第4,6列
data mydataframe[c(1,3), c(4,6)]
data
dheight dwage
1 160 5000
3 180 3000
- 使用data函数来加载R内置数据集,找到rivers的描述。
查看更多的R语言内置的数据集:https://mp.weixin.qq.com/s/dZPbCXccTzuj0K kOL7R31g
data()
rivers
[1] 735 320 325 392 524 450 1459 135 465
[10] 600 330 336 280 315 870 906 202 329
[19] 290 1000 600 505 1450 840 1243 890 350
[28] 407 286 280 525 720 390 250 327 230
[37] 265 850 210 630 260 230 360 730 600
[46] 306 390 420 291 710 340 217 281 352
[55] 259 250 470 680 570 350 300 560 900
[64] 625 332 2348 1171 3710 2315 2533 780 280
[73] 410 460 260 255 431 350 760 618 338
[82] 981 1306 500 696 605 250 411 1054 735
[91] 233 435 490 310 460 383 375 1270 545
[100] 445 1885 380 300 380 377 425 276 210
[109] 800 420 350 360 538 1100 1205 314 237
[118] 610 360 540 1038 424 310 300 444 301
[127] 268 620 215 652 900 525 246 360 529
[136] 500 720 270 430 671 1770
(参考B站生信小技巧获取runinfo table) 这是一个单细胞转录组项目的数据,共768个细胞,如果你找不到RunInfo Table 文件,可以点击下载,然后读入你的R里面也可以。
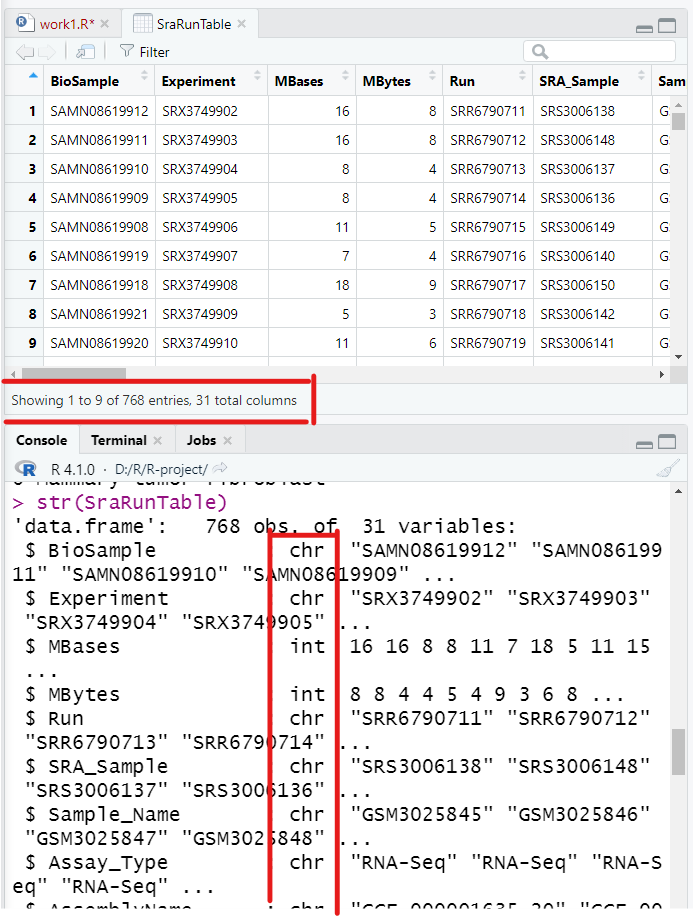
SraRunTable read.table("practice/SraRunTable.txt", header = T, sep = "\t")
View(SraRunTable)
str(SraRunTable)
768行,31列,每一列的属性如图。
(参考 https://mp.weixin.qq.com/s/fbHMNXOdwiQX5BAlci8brA 获取样本信息sample.csv)如果你实在是找不到样本信息文件sample.csv,也可以点击下载。
sample read.csv("practice/sample.csv", header = T)
sample1 read.table("practice/sample.csv", header = T, sep = ",")
View(sample)
str(sample)
768行,12列。各列属性如图。

- 把前面两个步骤的两个表(RunInfo Table 文件,样本信息sample.csv)关联起来,使用merge函数。
view(SraRunTable)
view(sample)
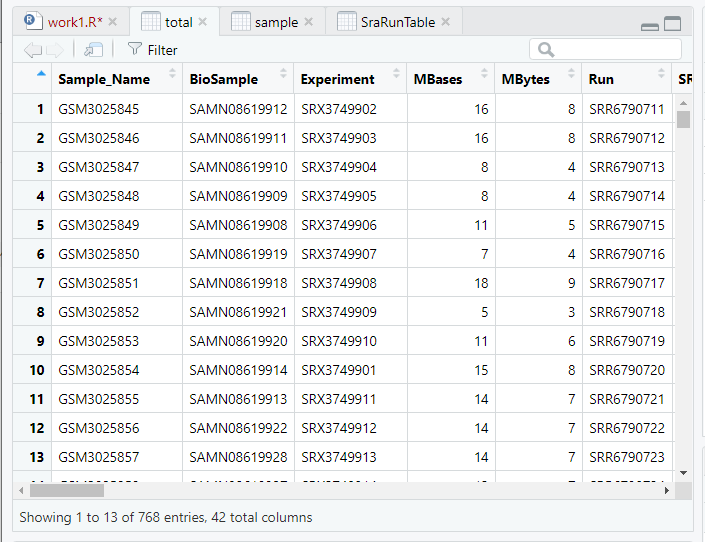
total merge(SraRunTable, sample, by.x = "Sample_Name", by.y = "Accession")
View(total)
合并之后的数据,有768行,42列。
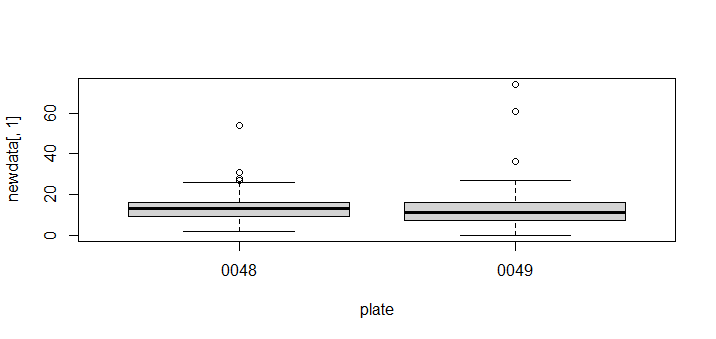
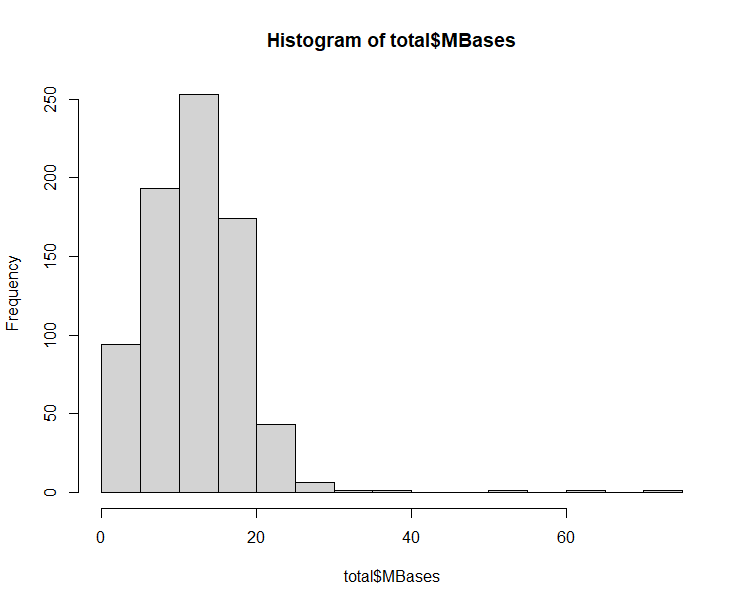
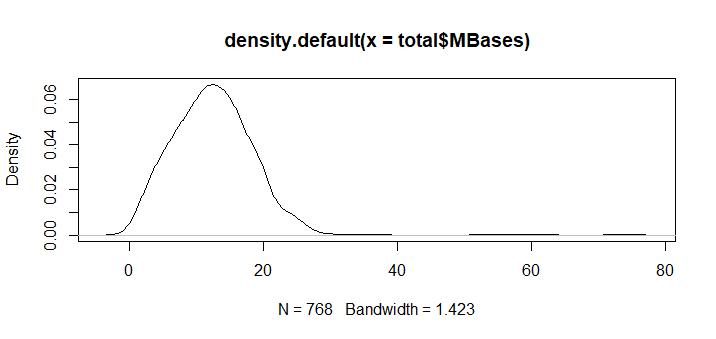
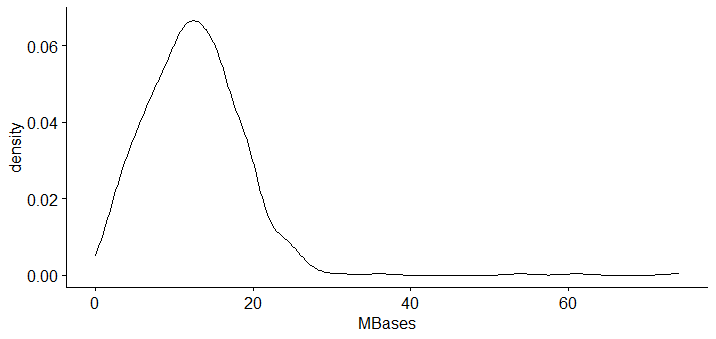
- 对前面读取的RunInfo Table文件在R里面探索其MBases列。把前面读取的样本信息表格的样本名字根据下划线分割看第3列元素的统计情况。第三列代表该样本所在的plate。根据plate把关联到的RunInfo Table信息的MBases列分组检验是否有统计学显著的差异。分组绘制箱线图(boxplot),频数图(hist),以及密度图(density) 。
newdata total[,c("MBases","Title")]
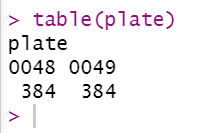
plate unlist(lapply(newdata[,2],function(x){
x
strsplit(x,'_')[[1]][3]}))
table(plate)
t.test(newdata[,1]~plate)

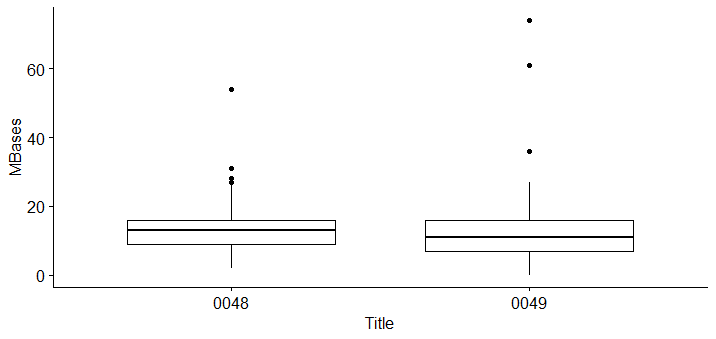
boxplot(newdata[,1]~plate)
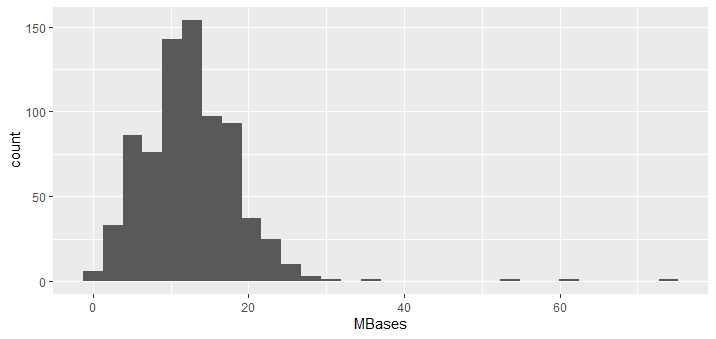
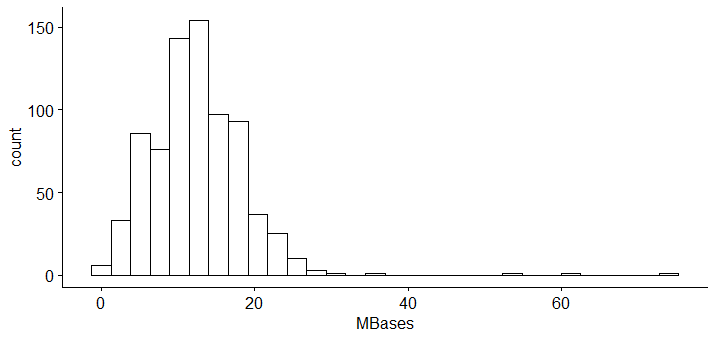
hist(total$MBases)
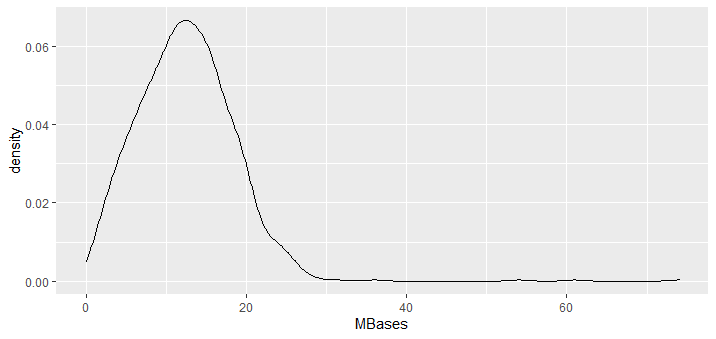
plot(density(total$MBases))
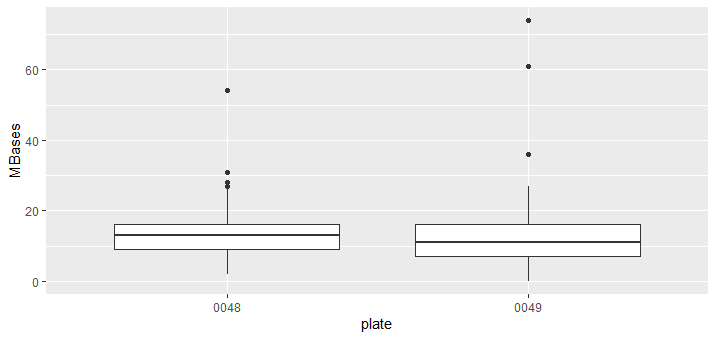
- 使用ggplot2把上面的图进行重新绘制。
library(ggplot2)
newdata$Title plate
ggplot(newdata,aes(x=plate,y=MBases))+geom_boxplot()
ggplot(newdata,aes(x=MBases))+geom_histogram()
ggplot(newdata,aes(x=MBases))+geom_density()
- 使用ggpubr把上面的图进行重新绘制。
library(ggpubr)
ggboxplot(newdata, x = "Title", y = "MBases")
gghistogram(newdata, x = "MBases")
ggdensity(newdata, x = "MBases")
Original: https://blog.csdn.net/narutodzx/article/details/119282538
Author: Dzfly..
Title: 生信学习——R语言练习题-初级(附详细答案解读)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600888/
转载文章受原作者版权保护。转载请注明原作者出处!