

今天给大家爬取一个王者荣耀的详情,让大家更好更快了解,说白了,就是想练练手
点个赞留个关注吧!!
今天爬取的内容相对简单,我也不知道难不难,可能对于新手来说会一点难,难就难着吧,不下功夫当然过不了,熬三个夜晚就会了
今天爬取的主要内容分别是: 英雄名称、详情链接、英雄属性(生存、伤害、技能、难度) 、英雄皮肤(非图片) 、铭文搭配推荐、召唤师技能推荐(针对不同英雄给予不同的推荐) 、出装搭配推荐(两种方案) 、最佳的搭档、压制英雄、被压制英雄
爬取的不包含图片/文件,只有可视文字字幕,,用了一个晚上做出来的,闲的睡不着觉才想到做这个爬虫的,希望能帮助到大家,不妨先点个关注,给个赞也可以
因为这个网站的一些问题,爬取不到前几位的英雄,我试了很多次都无济于事,也懒得搞了就暂时先不管这个了,如果有哪一位博主知道怎么回事,请在评论区或私信说一下,谢谢


废话不多说,由于代码较多,原本我也想分三个文件写入,但是我太懒了,直接写到一个py文件内了,直接上代码:
-*- coding: utf-8 -*-
import requests
import re
from bs4 import BeautifulSoup
URL = requests.get('https://pvp.qq.com/web201605/herolist.shtml')
html = URL.content
soup = BeautifulSoup(html,'html.parser',from_encoding="utf-8") #解析器
div_people_list = soup.find('ul', attrs={'class': 'herolist clearfix'})
for a in div_people_list.find_all('li'):
#爬取人物详情链接
text_1 = a.find('a')
URL_2 = ('https://pvp.qq.com/web201605/'+text_1['href']) #链接
#脾气任务名称
URL_3 = requests.get(f'{URL_2}')
html_2 = URL_3.content #再次解析
soup_2 = BeautifulSoup(html_2,'html.parser',from_encoding="utf-8") #解析器
text_2 = soup_2.find('h2', attrs={'class': 'cover-name'}).get_text() #名称
#print(text_2+'\t\t'+URL_2)
#爬取任务伤害比例
text_3 = soup_2.find('ul', attrs={'class': 'cover-list'}) # 伤害
T = 0
for text_4 in text_3.find_all('i', attrs={'class': 'ibar'}):
r = text_4['style']
T += 1
#获取属性伤害
if T == 1:
print(f'------------------------------>>{text_2}<
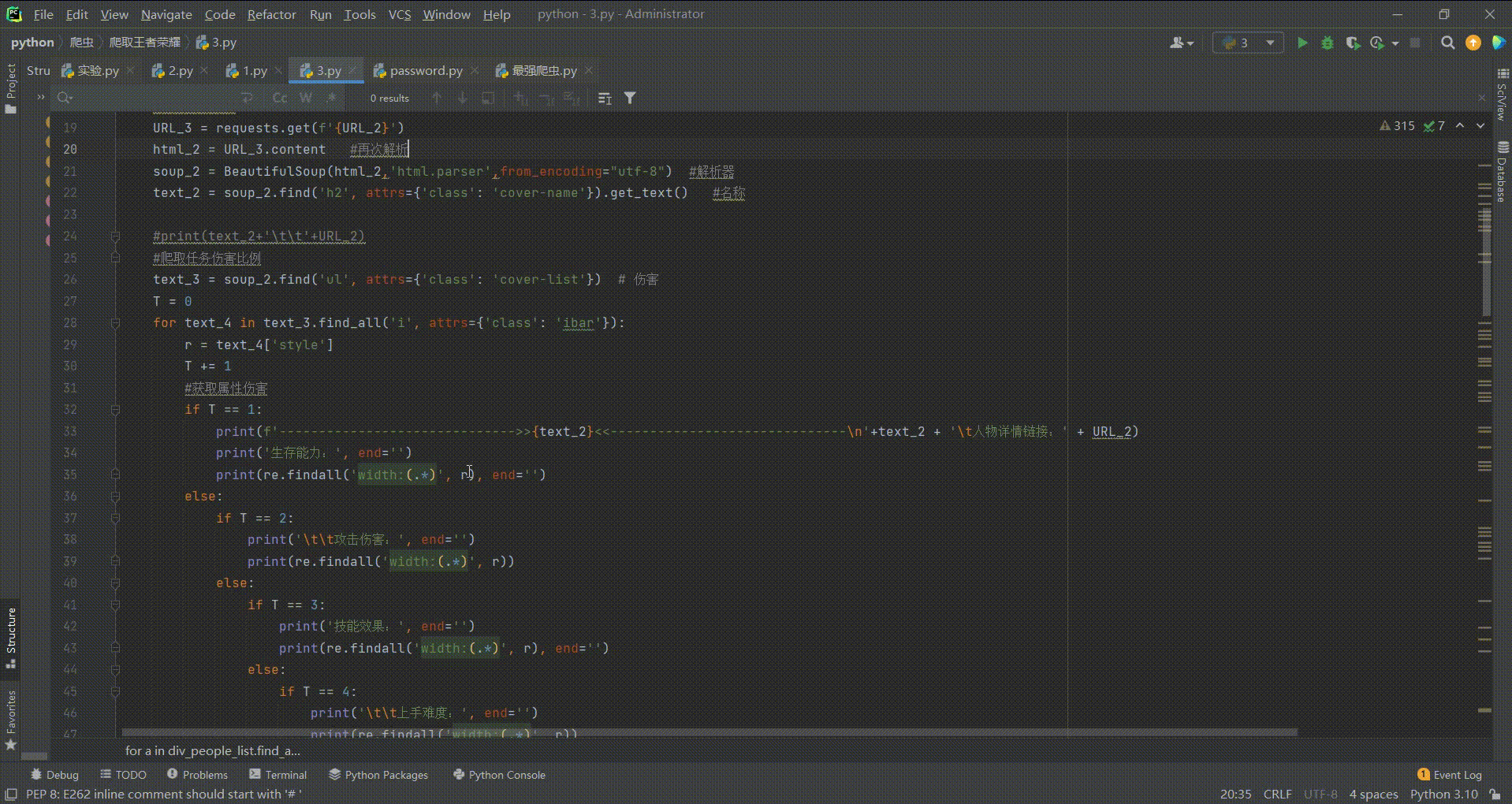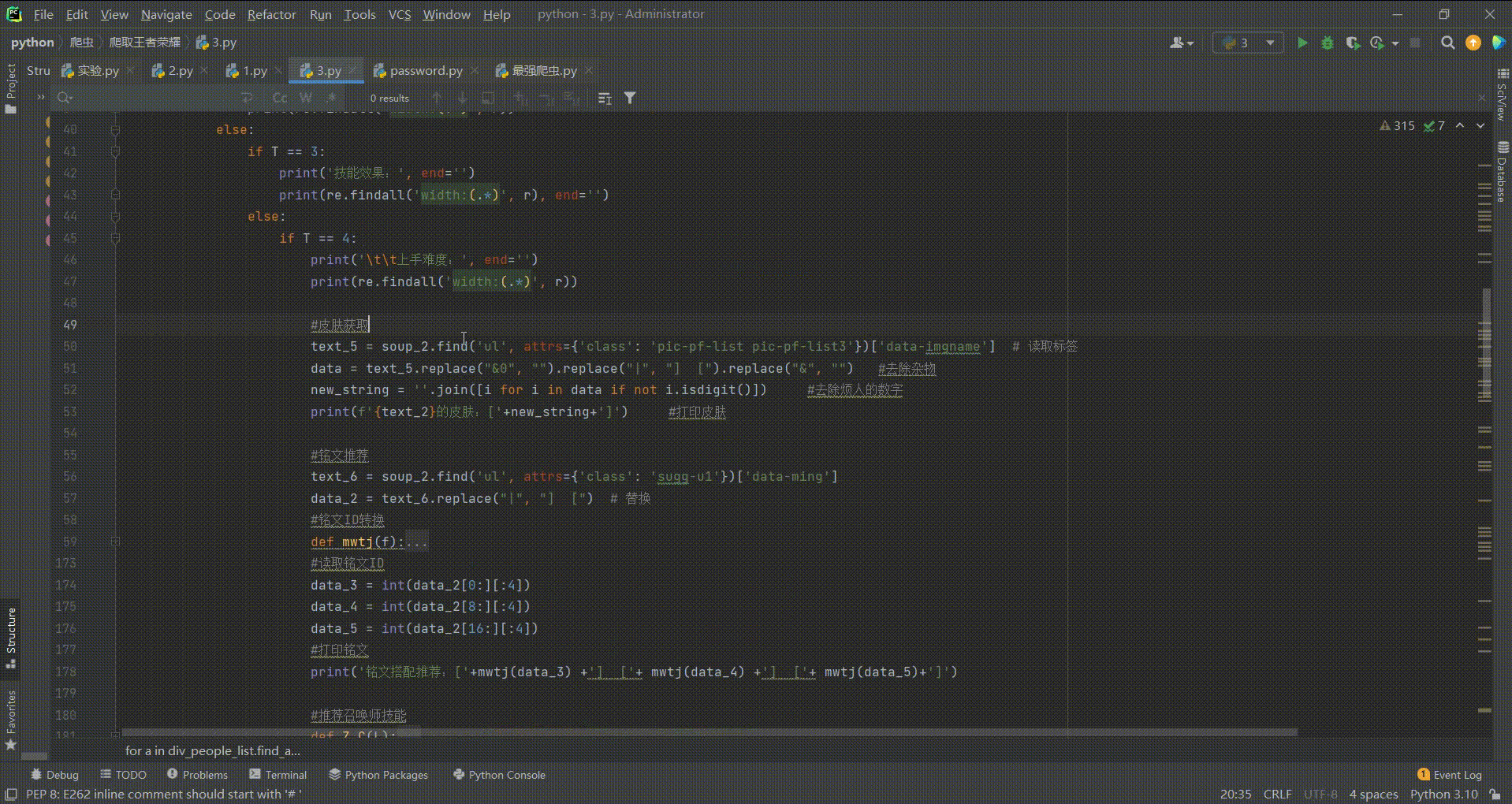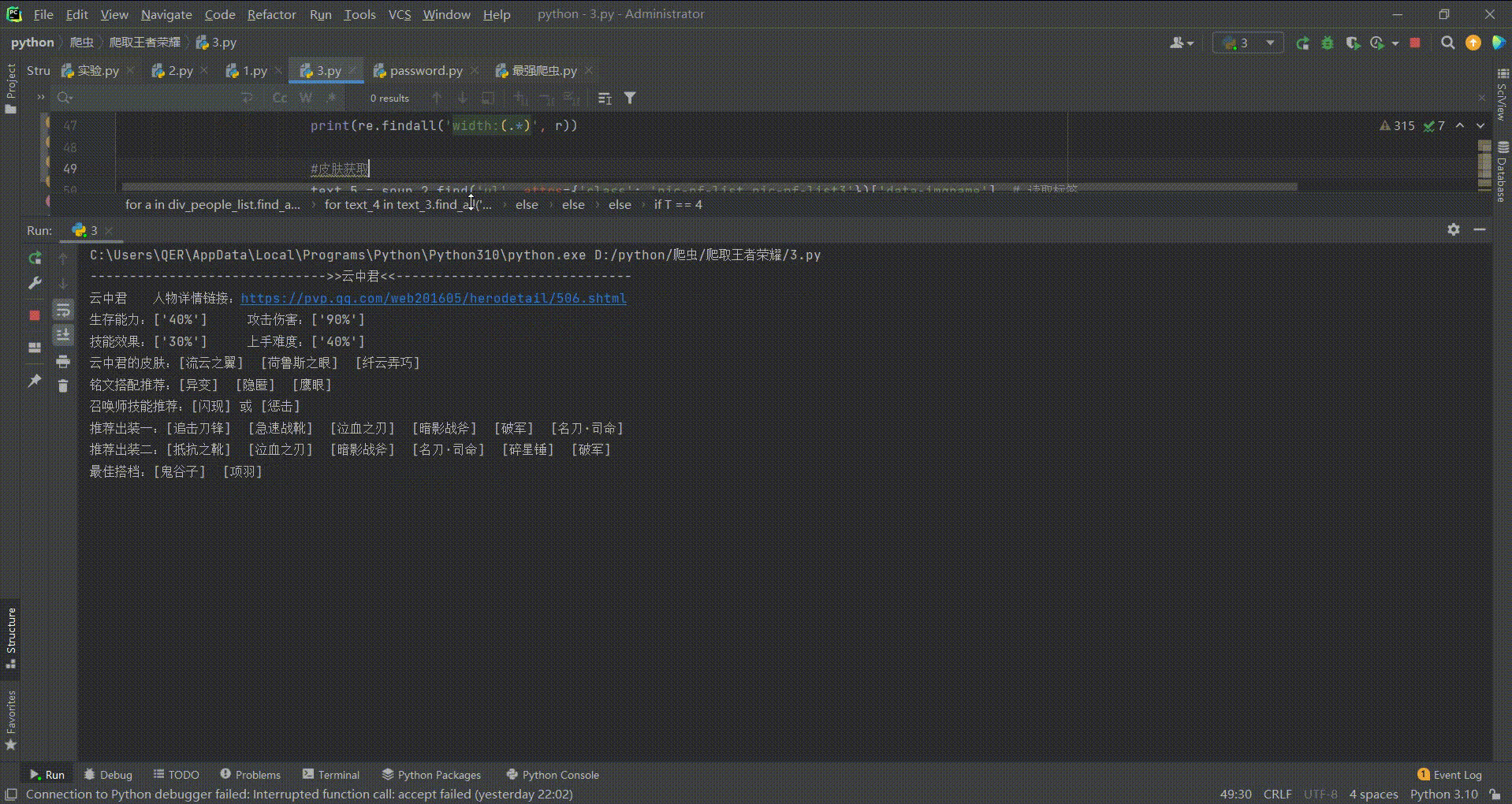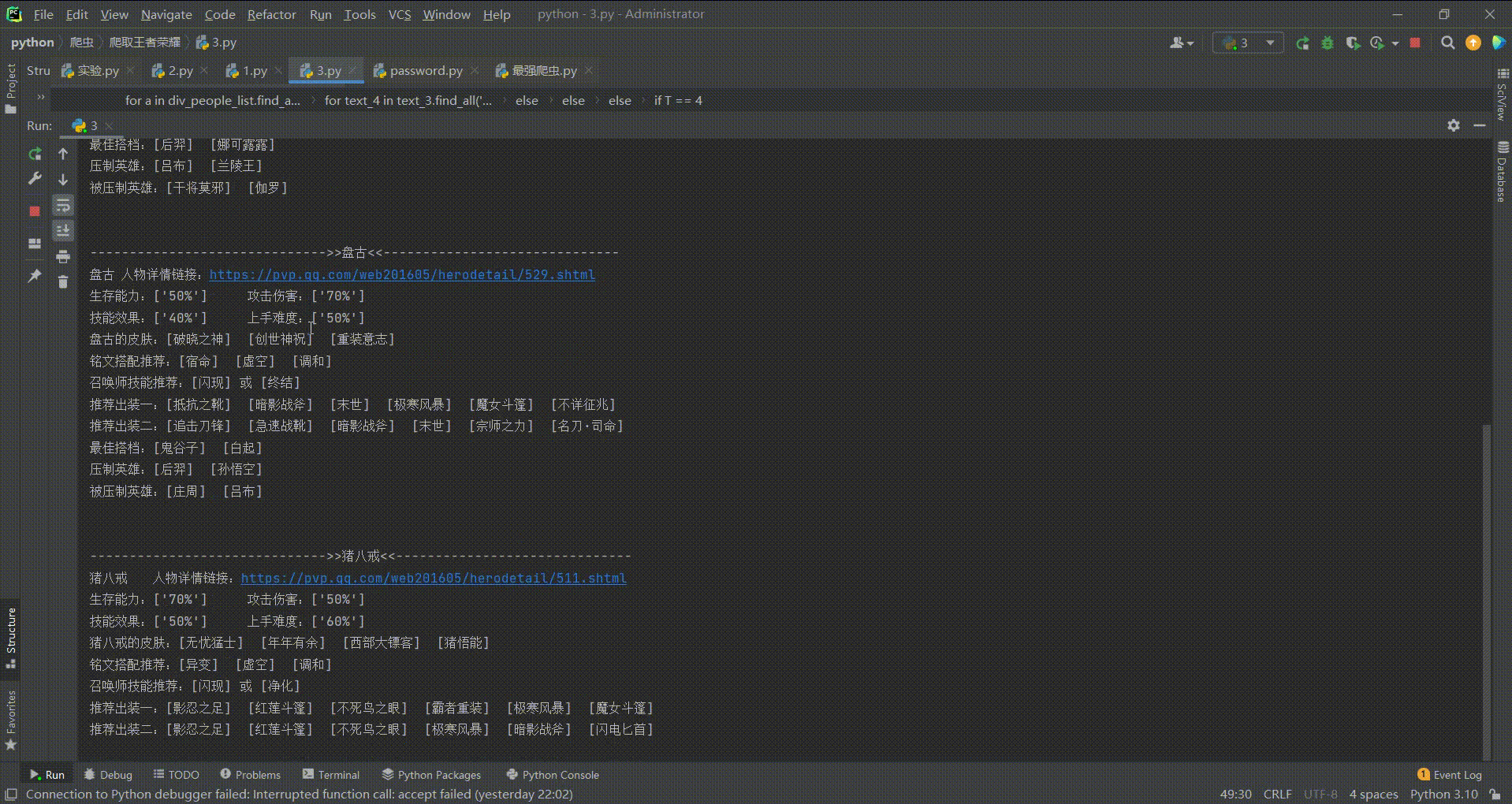
可以看到已经爬取出来了
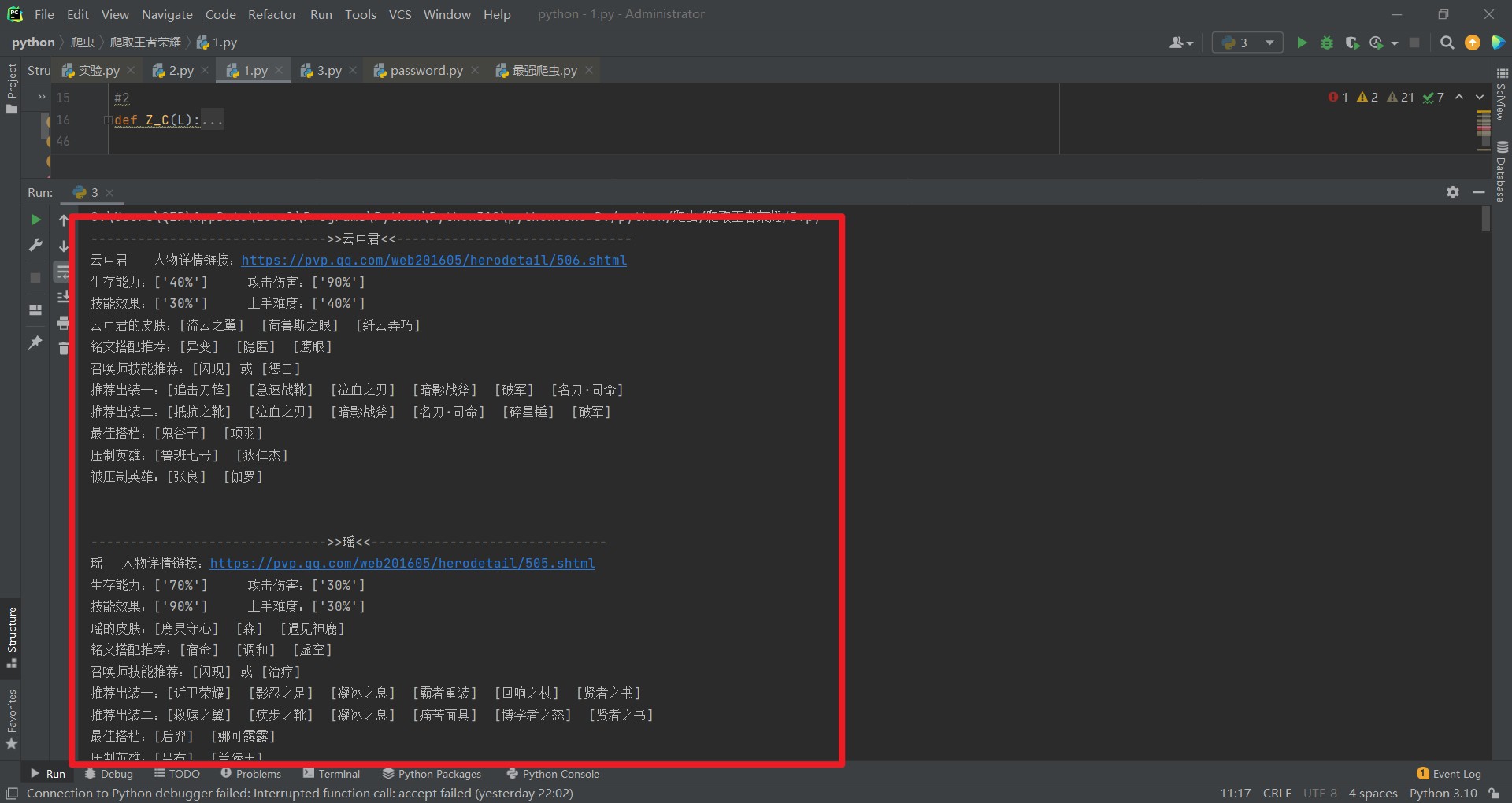
不妨点个赞在走呗!!!
Original: https://blog.csdn.net/weixin_46625757/article/details/122335702
Author: 小木_.
Title: python爬虫详解(五)——爬取王者荣耀英雄详细、攻略搭配、出装配置、铭文搭配、搭档/压制、入手详情
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639996/
转载文章受原作者版权保护。转载请注明原作者出处!