

信用卡欺诈检测
- 1. 数据分析与预处理
* - 1.1 数据的读取与分析
- 1.2 解决样本不均衡
- 1.3 特征标准化
- 2. 下采样方案
* - 2.1 交叉验证
- 2.2 模型评估方法
- 2.3 正则化惩罚
- 3. 逻辑回归模型
* - 3.1 参数对结果的影响
- 3.2 混淆矩阵
- 3.3 分类阈值对结果的影响
- 4. 过采样方案
* - 4.1 SMOTE算法数据生成策略
- 4.2 过采样应用效果
- 总结
假设有一份信用卡交易记录,遗憾的是数据经过了脱敏处理,只知道其特征,却不知道每一个字段代表什么含义,没关系,就当作是一个个数据特征。
在数据中有两种类别,分别是正常交易数据和异常 交易数据,字段中有明确的标识符。要做的任务就是建立逻辑回归模型,以对这两类数据进行分类,看起来似乎很容易,但实际应用时会出现各种问题等待解决。
熟悉任务目标后,第一个想法可能是直接把数据传到算法模型中,得到输出结果就好了。其实并不是这样,在机器学习建模任务中,要做的事情还是很多的,包括数据预处理、特征提取、模型调参等, 每一步都会对最终的结果产生影响。既然如此,就要处理好每一步,其中会涉及机器学习中很多细节, 这些都是非常重要的,基本上所有实战任务都会涉及这些问题,所以大家也可以把这份解决方案当作一 个套路。
- 数据分析与预处理
我们这里有一份信用卡交易记录数据,是一个.csv文件:


里面包含28万多条数据,规模很大。
; 1.1 数据的读取与分析
照常导入数分三大件:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
先使用Pandas工具包读取数据,看一下前五条数据样例:
data = pd.read_csv("creditcard.csv")
data.head()
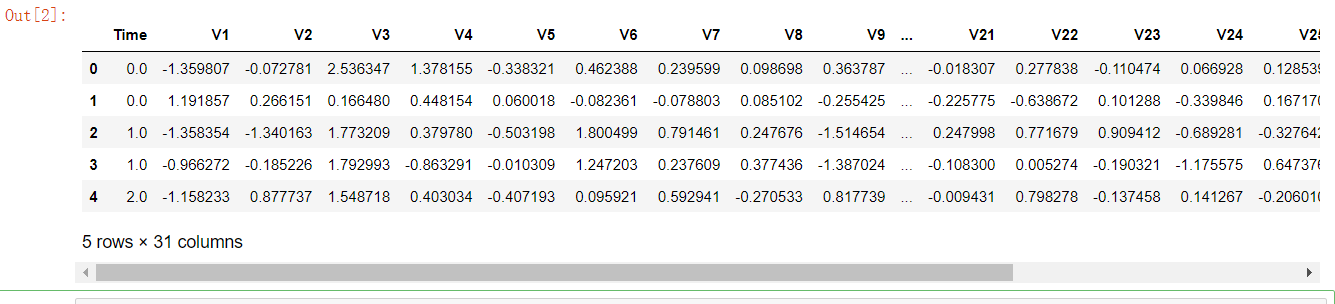

原始数据为个人交易记录,该数据集总共有31列,其中数据特征有30列,Time列暂时不考虑,Amount列表示贷款的金额,Class列表示分类结果,若Class为0代表该条交易记录正常,若Class 为1代表交易异常。
拿到这样一份原始数据之后,直观感觉可能就是认为数据已经是处理好的特征,只需要对其进行建模任务即可。但是,上述输出结果只展示了前5条交易记录并且发现全部是正常交易数据,在实际生活中似乎正常交易也占绝大多数,异常交易仅占一少部分,那么,在整个数据集中,样本分布是否均衡呢?也就是说,在Class列中,正常数据和异常数据的比例是多少?
我们绘制一份图表看一下:
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")

上述代码首先计算出Class列中各个指标的个数,也就是0和1分别有多少个。为了更直观地显示,数据绘制成条形图,从上图中可以发现,似乎只有0没有1,说明数据中绝大多数是正常数据,异常数据极少。
那到底有没有1这种情况呢?我们查看一下:


可以看到,实际上是有492条数据是Class为1的情况,492条相对于庞大的28万条微乎其微,所有我们的柱状图几乎看不到1的柱图。
这个问题看起来有点严峻,数据极度不平衡会对结果造成什么影响呢?模型会不会一边倒呢?认为所有数据都是正常的,完全不管那些异常的,因为异常数据微乎其微,这种情况出现的可能性很大。
我们的任务目标就是找到异常数据,如果模型不重视异常数据,结果就没有意义了,所以,首先要做的就是改进不平衡数据。在机器学习任务中,加载数据后,首先应当观察数据是否存在问题,先把问题处理掉,再考虑特征提取与建模任务。
1.2 解决样本不均衡
那么,如何解决数据标签不平衡问题呢?首先,造成数据标签不平衡的最根本的原因就是它们的个数相差悬殊,如果能让它们的个数相差不大,或者比例接近,这个问题就解决了。
基于此,提出以下两种解决方案。
(1)下采样。
既然异常数据比较少,那就让正常样本和异常样本一样少。例如正常样本有30万个, 异常样本只有500个,若从正常样本中随机选出500个,它们的比例就均衡了。
虽然下采样的方法看似很简单,但是也存在瑕疵,即使原始数据很丰富,下采样过后,只利用了其中一小部分,这样对结果会不 会有影响呢?
(2)过采样。
不想放弃任何有价值的数据,只能让异常样本和正常样本一样多,怎么做到呢?异常样本若只有500个,此时可以对数据进行变换,假造出来一些异常数据,数据生成也是现阶段常见的一种套路。
虽然数据生成解决了异常样本数量的问题,但是异常数据毕竟是造出来的,会不会存在问题呢? 这两种方案各有优缺点,到底哪种方案效果更好呢?需要进行实验比较。
在开始阶段,应当多提出各种解决和对比方案,尽可能先把全局规划制定完整,如果只是 想一步做一步,会做大量重复性操作,降低效率。
1.3 特征标准化
既然已经有了解决方案,是不是应当按照制订的计划准备开始建模任务呢?千万别心急,还差好多步呢,首先要对数据进行预处理,可能大家觉得机器学习的核心就是对数据建模,其实建模只是其中一 部分,通常更多的时间和精力都用于数据处理中,例如数据清洗、特征提取等,这些并不是小的细节, 而是十分重要的核心内容。目的都是使得最终的结果更好,大佬们常说:” 数据特征决定结果的上限,而模型的调优只决定如何接近这个上限。“

观察样表的数据特征可以发现,Amount列的数值变化幅度很大,而V1~V28列的特征数据的数值都比较小,此 时Amount列的数值相对来说比较大。这会产生什么影响呢?模型对数值是十分敏感的,它不像人类能够 理解每一个指标的物理含义,可能会认为数值大的数据相对更重要(此处仅是假设)。但是在数据中, 并没有强调Amount列更重要,而是应当同等对待它们,因此需要改善一下。
特征标准化就是希望数据经过处理后得到的每一个特征的数值都在较小范围内浮动,公式如下:

其中,Z为标准化后的数据;X为原始数据;Xmean为原始数据的均值;std(X)为原始数据的标准差。
如果把上式的过程进行分解,就会更加清晰明了。首先将数据的各个维度减去其各自的均值, 这样数据就是以原点为中心对称。其中数值浮动较大的数据,其标准差也必然更大;数值浮动较小的数据,其标准差也会比较小。再将结果除以各自的标准差,就相当于让大的数据压缩到较小的空间中,让小的数据能够伸张一些,对于下图所示的二维数据,就得到其标准化之后的结果,以原点为中心,各个维度的取值范围基本一致。

接下来,很多数据处理和机器学习建模任务都会用到sklearn工具包,这里先做简单介绍,该工具包提供了几乎所有常用的机器学习算法,仅需一两行代码,即可完成建模工作,计算也比较高效。不仅如此,还提供了非常丰富的数据预处理与特征提取模块,方便大家快速上手处理数据特征。它是Python中非常实用的机器学习建模工具包,在后续的实战任务中,都会出现它的身影。

sklearn工具包提供了在机器学习中最核心的三大模块(Classification、Regression、Clustering)的实现方法供大家调用,还包括数据降维(Dimensionality reduction)、模型选择(Model selection)、数据预处理(Preprocessing)等模块,功能十分丰富。
sklearn工具包还提供了很多实际应用的例子,并且配套相应的代码与可视化展示方法,简直就是一 条龙服务,非常适合大家学习与理解,如下图所示:


sklearn最常用的是其API文档,如下图所示,无论执行建模还是预处理任务,都需先熟悉其函数功能再使用。

我接下来使用sklearn工具包来完成特征标准化操作,
代码如下:
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()

上述代码使用 StandardScaler方法对数据进行标准化处理,调用时需先导入该模块,然后进行 fit_transform操作,相当于执行公式

reshape(−1,1)的含义是将传入数据转换成一列的形式(需按照函数输入要求做)。最后用drop操作去掉无用特征。上述输出结果中的normAmount列就是标准化处理后的结果,可见数值都在较小范围内浮动。
数据预处理过程非常重要,绝大多数任务都需要对特征数据进行标准化操作(或者其他预处理方法,如归一化等)。
- 下采样方案
下采样方案的实现过程比较简单,只需要对正常样本进行采样,得到与异常样本一样多的个数即可,代码如下:
X = data.iloc[:, data.columns != 'Class']
y = data.iloc[:, data.columns == 'Class']
得到所有异常样本的索引
number_records_fraud = len(data[data.Class == 1])
fraud_indices = np.array(data[data.Class == 1].index)
得到所有正常样本的索引
normal_indices = data[data.Class == 0].index
在正常样本中随机采样出指定个数的样本,并取其索引
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
random_normal_indices = np.array(random_normal_indices)
有了正常和异常样本后把它们的索引都拿到手
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
根据索引得到下采样所有样本点
under_sample_data = data.iloc[under_sample_indices,:]
X_undersample = under_sample_data.iloc[:, under_sample_data.columns != 'Class']
y_undersample = under_sample_data.iloc[:, under_sample_data.columns == 'Class']
下采样 样本比例
print("正常样本所占整体比例: ", len(under_sample_data[under_sample_data.Class == 0])/len(under_sample_data))
print("异常样本所占整体比例: ", len(under_sample_data[under_sample_data.Class == 1])/len(under_sample_data))
print("下采样策略总体样本数量: ", len(under_sample_data))
输出结果:

整体流程比较简单,首先计算异常样本的个数并取其索引,接下来在正常样本中随机选择指定个数样本,最后把所有样本索引拼接在一起即可。上述输出结果显示,执行下采样方案后,一共有984条数据,其中正常样本和异常样本各占50%,此时数据满足平衡标准。
2.1 交叉验证
得到输入数据后,接下来划分数据集,在机器学习中,使用训练集完成建模后,还需知道这个模型的效果,也就是需要一个测试集,以帮助完成模型测试工作。不仅如此,在整个模型训练过程中,也会涉及一些参数调整,所以,还需要验证集,帮助模型进行参数的调整与选择。
突然出现很多种集合,感觉很容易弄混,再来总结一下:

首先把数据分成两部分,左边是训练集,右边是测试集,如上图所示。 训练集用于建立模型,例如以梯度下降来迭代优化,这里需要的数据就是由训练集提供的。 测试集是当所有建模工作都完成后使用的,需要强调一点,测试集十分宝贵,在建模的过程中,不能加入任何与测试集有关的信息,否则就相当于透题,评估结果就不会准确。可以自己设定训练集和测试集的大小和比例,8︰2、9︰1都是常见的切分比例。
接下来需要对数据集再进行处理,如下图所示,可以发现测试集没有任何变化,仅把训练集划分成很多份。这样做的目的在于,建模尝试过程中,需要调整各种可能影响结果的参数,因此需要知道每一 种参数方案的效果,但是这里不能用测试集,因为建模任务还没有全部完成,所以验证集就是在建模过程中评估参数用的,那么单独在训练集中找出来一份做验证集(例如fold5)不就可以了吗,为什么要划分出来这么多小份呢?


在验证某一 次结果时,需要把整个过程分成10步,第一步用前9份当作训练集,最后一份当作验证集,得到一个结果,以此类推,每次都依次用另外一份当作验证集,其他部分当作训练集。这样经过10步之后,就得到 10个结果,每个结果分别对应其中每一小份,组合在一起恰好包含原始训练集中所有数据,再对最终得 到的10个结果进行平均,就得到最终模型评估的结果。这个过程就叫作 交叉验证。
交叉验证看起来有些复杂,但是能对模型进行更好的评估,使得结果更准确,从后续的实验中,大家会发现,用不同验证集评估的时候,结果差异很大,所以这个套路是必须要做的。
在sklearn工具包 中,已经实现好数据集切分的功能,这里需先将数据集划分成训练集和测试集,切分验证集的工作等到建模的时候再做也来得及,代码如下:
#from sklearn.cross_validation import train_test_split
在sklearn 0.18及以上的版本中,cross_validation包已经被废弃。
from sklearn.model_selection import train_test_split
整个数据集进行划分
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("原始训练集包含样本数量: ", len(X_train))
print("原始测试集包含样本数量: ", len(X_test))
print("原始样本总数: ", len(X_train)+len(X_test))
下采样数据集进行划分
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample
,y_undersample
,test_size = 0.3
,random_state = 0)
print("")
print("下采样训练集包含样本数量: ", len(X_train_undersample))
print("下采样测试集包含样本数量: ", len(X_test_undersample))
print("下采样样本总数: ", len(X_train_undersample)+len(X_test_undersample))
输出结果如下:

通过输出结果可以发现,在切分数据集时做了两件事:首先对原始数据集进行划分,然后对下采样数据集进行划分。我们最初的目标不是要用下采样数据集建模吗,为什么又对原始数据进行切分操作呢?这里先留一个伏笔,后续将慢慢揭晓。
2.2 模型评估方法
接下来还没到实际建模任务,还需要考虑模型的评估方法,为什么建模之前要考虑整个过程呢?因为建模是一个过程,需要优先考虑如何评估其价值,而不是仅仅提供一堆模型参数值。
准确率是分类问题中最常使用的一个参数,用于说明在整体中做对了多少。下面举一个与这份数据集相似的例子:医院中有1000个病人,其中10个患癌,990个没有患癌,需要建立一个模型来区分他们。 假设模型认为病人都没有患癌,只有10个人分类有错,因此得到的准确率高达990/1000,也就是0.99,看起来是十分不错的结果。但是建模的目的是找出患有癌症的病人,即使一个都没找到,准确率也很高。 这说明对于不同的问题,需要指定特定的评估标准,因为不同的评估方法会产生非常大的差异。
选择合适的评估方法非常重要,因为评估方法是为整个实验提供决策的服务的,所以一定 要基于实际任务与数据集进行选择。
在这个问题中,癌症患者与非癌症患者人数比例十分不均衡,那么,该如何建模呢?既然已经明确建模的目标是为了检测到癌症患者(异常样本),应当把关注点放在他们身上,可以考虑模型在异常样本中检测到多少个。对于上述问题来说,一个癌症病人都没检测到,意味着 召回率(Recall)为0。
这里提到了召回率,先通俗理解一下:就是观察给定目标,针对这个目标统计你取得了多大成绩,而不是针对整体而言。 如果直接给出计算公式,理解起来可能有点吃力,现在先来解释一下在机器学习以及数据科学领域中常用的名词,理解了这些名词,就很容易理解这些评估方法。 下面还是由一个问题来引入,假如某个班级有男生80人,女生20人,共计100人,目标是找出所有女生。现在某次实验挑选出50个人,其中20人是女生,另外还错误地把30个男生也当作女生挑选出来(这里把女生当作正例,男生当作负例)。
下表列出了TP、TN、FP、FN四个关键词的解释,这里告诉大家一个窍门,不需要死记硬背,从词表面的意思上也可以理解它们:

(1) TP
首先,第一个词是True,这就表明模型预测结果正确,再看Positive,指预测成正例,组 合在一起就是首先模型预测正确,即将正例预测成正例。返回来看题目,选出来的50人中有20个是女 生,那么TP值就是20,这20个女生被当作女生选出来。
(2) FP
FP表明模型预测结果错误,并且被当作Positive(也就是正例)。在题目中,就是错把男 生当作女生选出来。在这里目标是选女生,选出来的50人中有30个却是男的,因此FP等于30。
(3) FN
同理,首先预测结果错误,并且被当作负例,也就是把女生错当作男生选出来,题中并没有这个现象,所以FN等于0。
(4) TN
预测结果正确,但把负例当作负例,将男生当作男生选出来,题中有100人,选出认为是女生的50人,剩下的就是男生了,所以TN等于50。
上述评估分析中常见的4个指标只需要掌握其含义即可。下面来看看通过这4个指标能得出什么结 论。
•准确率(Accuracy):表示在分类问题中,做对的占总体的百分比。

•召回率(Recall):表示在正例中有多少能预测到,覆盖面的大小。

•精确度(Precision):表示被分为正例中实际为正例的比例。

上面介绍了3种比较常见的评估指标,下面回到信用卡分类问题,想一想在这份检测任务中,应当使用哪一个评估指标呢?由于目的是查看有多少异常样本能被检测出来,所以应当使用召回率进行模型评估。
; 2.3 正则化惩罚
正则化惩罚,这个名字看起来有点别扭,好好的模型为什么要惩罚呢?

先来解释一 下过拟合的含义,建模的出发点就是尽可能多地满足样本数据,在图(a)中直线看起来有点简单,没有满足大部分数据样本点,这种情况就是欠拟合,究其原因,可能由于模型本身过于简单所导致。再来看图(b),比图(a)所示模型稍微复杂些,可以满足大多数样本点,这是一个比较不错的模型。但是通过观察可以发现,还是没有抓住所有样本点,这只是一个大致轮廓,那么如果能把模型做得更复杂,岂不是更好?再来看图(c),这是一个非常复杂的回归模型,竟然把所有样本点都抓到 了,给人的第一感觉是模型十分强大,但是也会存在一个问题—模型是在训练集上得到的,测试集与训 练集却不完全一样,一旦进行测试,效果可能不尽如人意。
在机器学习中,通常都是先用简单的模型进行尝试,如果达不到要求,再做复杂一点的,而不是先用最复杂的模型来做,虽然训练集的准确度可以达到99%甚至更高,但是实际应用的效果却很差,这就是过拟合。
我们在机器学习任务中经常会遇到过拟合现象,最常见的情况就是随着模型复杂程度的提升,训练集效果越来越好,但是测试集效果反而越来越差,如下图所示:

对于同一算法来说,模型的复杂程度由谁来控制呢?当然就是其中要求解的参数(例如梯度下降中优化的参数),如果在训练集上得到的参数值忽高忽低,就很可能导致过拟合,所以正则化惩罚就是为解决过拟合准备的,即惩罚数值较大的权重参数,让它们对结果的影响小一点。
还是举一个例子来看看其作用,假设有一条样本数据是x:[1,1,1,1],现在有两个模型:
•θ1:[1,0,0,0]
•θ2:[0.25,0.25,0.25,0.25]
可以发现,模型参数θ1、θ2与数据x组合之后的结果都为1(也就是对应位置相乘求和的结果)。这是不是意味着两个模型的效果相同呢?再观察发现,两个参数本身有着很大的差异,θ1只有第一个位置有值,相当于只注重数据中第一个特征,其他特征完全不考虑;而θ2会同等对待数据中的所有特征。虽然 它们的结果相同,但是,如果让大家来选择,大概都会选择第二个,因为它比较均衡,没有那么绝对。
在实际建模中,通常要选择泛化能力更强的也就是都趋于稳定的权重参数。那么如何把控参数呢?此时就需要一个惩罚项,惩罚项会与目标函数组合在 一起,让模型在迭代过程中就开始重视这个问题,而不是建模完成后再来调整,常见的有L1和L2正则化惩罚项:
- L1正则化:

- L2正则化:

两种正则化惩罚方法都对权重参数进行了处理,既然加到目标函数中,目的就是不让个别权重太大,以致对局部产生较大影响,也就是过拟合的结果。在L1正则化中可以对|w|求累加和,但是只直接计算绝对值求累加和的话,例如上述例子中θ1和θ2的结果仍然相同,都等于1,并没有作出区分。这时候L2 正则化就登场了,它的惩罚力度更大,对权重参数求平方和,目的就是让大的更大,相对惩罚也更多。 θ1的L2惩罚为1,θ2的L2惩罚只有0.25,表明θ1带来的损失更大,在模型效果一致的前提下,当然选择整体效果更优的θ2组模型。
在惩罚项的前面还有一个 α系数,它表示正则化惩罚的力度。以一种极端情况举例说明:如果α值比较大,意味着要非常严格地对待权重参数,此时正则化惩罚的结果会对整体目标函数产生较大影响。如果α值较小,意味着惩罚的力度较小,不会对结果产生太大影响。
最终结果的定论是由测试集决定的,训练集上的效果仅供参考,因为过拟合现象十分常见。
- 逻辑回归模型
历尽千辛万苦,现在终于到建模的时候了,这里需要把上面考虑的所有内容都结合在一起,再用工具包建立一个基础模型就非常简单,难点在于怎样得到最优的结果,其中每一环节都会对结果产生不同的影响。
3.1 参数对结果的影响
在逻辑回归算法中,涉及的参数比较少,这里仅对正则化惩罚力度进行调参实验,为了对比分析交叉验证的效果,对不同验证集分别进行建模与评估分析,代码如下:
#Recall = TP/(TP+FN)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
from sklearn.model_selection import cross_val_predict
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(5,shuffle=False)
# 定义不同力度的正则化惩罚力度
c_param_range = [0.01,0.1,1,10,100]
# 展示结果用的表格
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# k-fold 表示K折的交叉验证,这里会得到两个索引集合: 训练集 = indices[0], 验证集 = indices[1]
j = 0
#循环遍历不同的参数
for c_param in c_param_range:
print('-------------------------------------------')
print('正则化惩罚力度: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#一步步分解来执行交叉验证
for iteration, indices in enumerate(fold.split(y_train_data),start=1):
# 指定算法模型,并且给定参数
lr = LogisticRegression(C = c_param, penalty = 'l1',solver='liblinear')
# 训练模型,注意索引不要给错了,训练的时候一定传入的是训练集,所以X和Y的索引都是0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# 建立好模型后,预测模型结果,这里用的就是验证集,索引为1
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# 有了预测结果之后就可以来进行评估了,这里recall_score需要传入预测值和真实值。
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
# 一会还要算平均,所以把每一步的结果都先保存起来。
recall_accs.append(recall_acc)
print('Iteration ', iteration,': 召回率 = ', recall_acc)
# 当执行完所有的交叉验证后,计算平均结果
results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('平均召回率 ', np.mean(recall_accs))
print('')
#找到最好的参数,哪一个Recall高,自然就是最好的了。
best_c = results_table.loc[results_table['Mean recall score'].astype('float32').idxmax()]['C_parameter']
# 打印最好的结果
print('*********************************************************************************')
print('效果最好的模型所选参数 = ', best_c)
print('*********************************************************************************')
return best_c
上述代码中,KFold用于选择交叉验证的折数,这里选择5折,即把训练集平均分成5份。c_param是 正则化惩罚的力度,也就是正则化惩罚公式中的a。为了观察不同惩罚力度对结果的影响,在建模的时 候,嵌套两层for循环,首先选择不同的惩罚力度参数,然后对于每一个参数都进行5折的交叉验证,最后得到其验证集的召回率结果。
在sklearn工具包中,所有算法的建模调用方法都是类似的,首先选择需要的算法模型,然后.fit()传入实际数据进行迭代,最后用.predict()进行预测。
传入数据看一下效果:
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample)
输出结果:


先来单独看正则化惩罚的力度C为0.01时,通过交叉验证分别得到5 次实验结果,可以发现,即便在相同参数的情况下,交叉验证结果的差异还是很大,其值在0.93~1.0之间浮动,但是千万别小看这几个百分点,建模都是围绕着一步步小的提升逐步优化的,所以交叉验证非常有必要。
在sklearn工具包中,C参数的意义正好是倒过来的,例如C=0.01表示正则化力度比较大,而C=100则 表示力度比较小。看起来有点像陷阱,但既然工具包这样定义了,咱们就照做就行了,所以一定要参考其API文档:

再来对比分析不同参数得到的结果,直接观察交叉验证最后的平均召回率值就可以,不同参数的情 况下,得到的结果各不相同,差异还是存在的,所以在建模的时候调参必不可少,可能大家都觉得应该 按照经验值去做,但更多的时候经验值只能提供一个大致的方向,具体的探索还是通过大量的实验进 行分析。
现在已经完成建模和基本的调参任务,只看这个90%左右的结果,感觉还不错,但是如果想知道模 型的具体表现,需要再深入分析。
3.2 混淆矩阵
预测结果明确之后,还可以更直观地进行展示,这时候混淆矩阵就派上用场了。

混淆矩阵中用到的指标值前面已经解释过,既然已经训练好模型,就可以展示其结果,这里用到 Matplotlib工具包,大家可以把下面的代码当成一个混淆矩阵模板,用的时候只需传入自己的数据即可:
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
绘制混淆矩阵
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
定义好混淆矩阵的画法之后,需要传入实际预测结果,调用之前的逻辑回归模型,得到测试结果, 再把数据的真实标签值传进去即可:
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
计算所需值
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
输出结果:

在这份数据集中,目标任务是二分类,所以只有0和1,主对角线上的值就是预测值和真实值一致的情况,深色区域代表模型预测正确(真实值和预测值一致),其余位置代表预测错误。数值10代表有10 个样本数据本来是异常的,模型却将它预测成为正常,相当于”漏检”。数值12代表有12个样本数据本来是正常的,却把它当成异常的识别出来,相当于”误杀”。
最终得到的召回率值约为0.9319,看起来是一个还不错的指标,但是还有没有问题呢?用下采样的数据集进行建模,并且测试集也是下采样的测试集,在这份测试集中,异常样本和正常样本的比例基本均衡,因为已经对数据集进行过处理。但是实际的数据集并不是这样的,相当于在测试时用理想情况来代替真实情况,这样的检测效果可能会偏高,所以值得注意的是,在测试的时候,需要使用原始数据的测试集,才能最具代表性,只需要改变传入的测试数据即可,代码如下:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(X_test.values)
计算所需值
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
输出结果:

还记得在切分数据集的时候,我们做了两手准备吗?不仅对下采样数据集进行切分,而且对原始数据集也进行了切分。这时候就派上用场了,得到的召回率值为0.925,虽然有所下降,但是整体来说还是可以的。
在实际的测试中,不仅需要考虑评估方法,还要注重实际应用情况,再深入混淆矩阵中,看看还有 哪些实际问题。上图中左下角的数值为13,看起来没有问题,说明有13个漏检的。但是,右上角有一个数字格外显眼——9145,意味着有9145个样本被误杀。好像之前用下采样数据集进行测试的时候没有注意到这一点,因为只有20个样本被误杀。但是,在实际的测试集中却出现了这样的事:整个测试集一共只有100多个异常样本,模型却误杀掉9145个,有点夸张了,根据实际业务需求,后续肯定要对检测出来的异常样本做一些处理,比如冻结账号、电话询问等,如果误杀掉这么多样本,实际业务也会出现问题。
在测试中还需综合考虑,不仅要看模型具体的指标值(例如召回率、精度等),还需要从实际问题角度评估模型到底可不可取。 问题已经很严峻,模型现在出现了大问题,该如何改进呢?是对模型调整参数,不断优化算法呢? 还是在数据层面做一些处理呢?一般情况下,建议大家先从数据下手,因为对数据做变换要比优化算法模型更容易,得到的效果也更突出。不要忘了之前提出的两种方案,而且过采样方案还没有尝试,会不会发生一些变化呢?下面就来揭晓答案。
3.3 分类阈值对结果的影响
回想一下逻辑回归算法原理,通过Sigmoid函数将得分值转换成概率值,那么,怎么得到具体的分类结果呢?默认情况下,模型都是以0.5为界限来划分类别:

可以说0.5是一个经验值,但是并不是固定不变的,实践时可以根据自己的标准来指定该阈值大小。 如果阈值设置得大一些,相当于要求变得严格,只有非常异常的样本才能当作异常;如果阈值设置得比较小,相当于宁肯错杀也不肯放过,只要有一点异常就通通抓起来。
在sklearn工具包中既可以用.predict()函数得到分类结果,相当于以0.5为默认阈值,也可以 用.predict_proba()函数得到其概率值,而不进行类别判断。
咱们可以先看一下如果不对数据进行处理,对原始数据直接建模结果:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train,y_train.values.ravel())
y_pred_undersample = lr.predict(X_test.values)
Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred_undersample)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
结果:

召回率偏低,结果显然不如我们之前做下采样数据处理效果好。
再看一下阈值对结果的影响:
用之前最好的参数来进行建模
lr = LogisticRegression(C = 0.01, penalty = 'l1',solver='liblinear')
训练模型,还是用下采样的数据集
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
得到预测结果的概率值
y_pred_undersample_proba = lr.predict_proba(X_test_undersample.values)
#指定不同的阈值
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
j = 1
用混淆矩阵来进行展示
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("给定阈值为:",i,"时测试集召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Threshold >= %s'%i)
输出结果:


代码中设置0.1~0.9多个阈值,并且确保每一次建模都使用相同的参数,将得到的概率值与给定阈值进行比较来完成分类任务。 现在观察一下输出结果,当阈值比较小的时候,可以发现召回率指标非常高,第一个子图竟然把所有样本都当作异常的,但是误杀率也是很高的,实际意义并不大。随着阈值的增加,召回率逐渐下降, 也就是漏检的逐步增多,而误杀的慢慢减少,这是正常现象。当阈值趋于中间范围时,看起来各有优缺点,当阈值等于0.5时,召回率偏高,但是误杀的样本个数有点多。当阈值等于0.6时,召回率有所下降, 但是误杀样本数量明显减少。那么,究竟选择哪一个阈值比较合适呢?这就需要从实际业务的角度出发,看一看实际问题中,到底需要模型更符合哪一个标准。
- 过采样方案
在下采样方案中,虽然得到较高的召回率,但是误杀的样本数量实在太多了,下面就来看看用过采样方案能否解决这个问题。
4.1 SMOTE算法数据生成策略
如何才能让异常样本与正常样本一样多呢?这里需要对少数样本进行生成,这可不是复制粘贴,一 模一样的样本是没有用的,需要采用一些策略,最常用的就是SMOTE算法(见下图),

其流程如下:
第①步:对于少数类中每一个样本x,以欧式距离为标准,计算它到少数类样本集中所有样本的距离,经过排序,得到其近邻样本。
第②步:根据样本不平衡比例设置一个采样倍率N,对于每一个少数样本x,从其近邻开始依次选择N 个样本。
第③步:对于每一个选出的近邻样本,分别与原样本按照如下的公式构建新的样本数据。

总结一下:对于每一个异常样本,首先找到离其最近的同类样本,然后在它们之间的距离上,取0~1中的一个随机小数作为比例,再加到原始数据点上,就得到新的异常样本。
对于SMOTE算法,可以使 用imblearn工具包完成这个操作,首先需要安装该工具包,可以直接在命令行中使用 pip install imblearn或者 conda install -c glemaitre imbalanced-learn完成安装操作。(温馨提示:安装完成后,最好重启一下,重启!重启!重启!!!不然可能会有大坑,我经历了各种各样的问题卡了几个小时,最后甚至重装了anaconda,天杀的,怪我太菜了。。。)。再把SMOTE算法加载进来,只需要将特征数据和标签传进去,接下来就得到20W+个异常样本,完成过采样方案。
; 4.2 过采样应用效果
过采样方案的效果究竟怎样呢?同样使用逻辑回归算法来看看。
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
credit_cards=pd.read_csv('creditcard.csv')
columns=credit_cards.columns
在特征中去除掉标签
features_columns=columns.delete(len(columns)-1)
features=credit_cards[features_columns]
labels=credit_cards['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.3,
random_state=0)
基于SMOTE算法来进行样本生成,这样正例和负例样本数量就是一致的了
oversampler=SMOTE(random_state=0)
os_features,os_labels=oversampler.fit_resample(features_train,labels_train)
训练集样本数量:

os_features = pd.DataFrame(os_features)
os_labels = pd.DataFrame(os_labels)
best_c = printing_Kfold_scores(os_features,os_labels)


在训练集上的效果还不错,再来看看其测试结果的混淆矩阵:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
计算混淆矩阵
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
输出结果:

得到的召回率值与之前的下采样方案相比有所下降,毕竟在异常样本中很多都是假冒的,不能与真实数据相媲美。值得欣慰的是,这回模型的误杀比例大大下降,原来误杀比例占到所有测试样本的10%左右,现在只占不到1%,实际应用效果有很大提升。
经过对比可以明显发现,过采样的总体效果优于下采样(还得依据实际应用效果具体分析),因为可利用的数据信息更多,使得模型更符合实际的任务需求。但是,对于不同的任务与数据源来说,并没有一成不变的答案,任何结果都需要通过实验证明,所以当大家遇到问题时,最好的解决方案是通过大量实验进行分析。
总结
- 在做任务之前一定要检查数据,看看数据有什么问题。在此项目中,通过对数据进行观察,发现其中有样本不均衡的问题,针对这些问题,再来选择解决方案。
- 针对问题提出两种方法:下采样和过采样。通过两条路线进行对比实验,任何实际问题出现后,通常都是先得到一个基础模型,然后对各种方法进行对比,找到最合适的,所以在任务开始之前,一定要多动脑筋,做多手准备,得到的结果才有可选择的余地。
- 在建模之前,需要对数据进行各种预处理操作,例如数据标准化、缺失值填充等,这些都是必要的,由于数据本身已经给定特征,此处还没有涉及特征工程这个概念,后续实战中会逐步引入,其实数据预处理工作是整个任务中最重、最苦的一个工作阶段,数据处理得好坏对结果的影响最大。
- 先选好评估方法,再进行建模实验。建模的目的就是为了得到结果,但是不可能一次就得到最好的结果,肯定要尝试很多次,所以一定要有一个合适的评估方法,可以选择通用的,例如召回率、准确率等,也可以根据实际问题自己指定合适的评估指标。
- 选择合适的算法,本例中选择逻辑回归算法,详细分析其中的细节,之后还会讲解其他算法,并不 一定非要用逻辑回归完成这个任务,其他算法效果可能会更好。在机器学习中,并不是越复杂的算法越实用,反而越简单的算法应用越广泛。逻辑回归就是其中一个典型的代表,简单实用,所以任何分类问题都可以把逻辑回归当作一个待比较的基础模型。
- 模型的调参也是很重要的,通过实验发现不同的参数可能会对结果产生较大的影响,这一步也是必须的。使用工具包时,建议最好先查阅其API文档,知道每一个参数的意义,再来进行实验。
打打气吧。可能有时候我们可能会感觉很枯燥,不想坚持了,但亲爱的朋友,我想告诉你,你离成功只差一个坚持。前期积累的过程注定是一段沉默的时光,也许你感觉很累,也许你甚至已经犹豫着要不要放弃,但是我可以告诉你,每一个人心中都有一只华丽、睿智、高贵的凤凰,唯有经历淬火锤炼,才能涅槃重生。
当我们踩过了众多的坑,经历了众多的艰难,我们会明白暗淡的时光会让我们逆势生长。积累到一定的程度你会发现,程序的世界真是一个神奇的世界,为了看看这个世界的风光,你会一直狂热的一路走下去。成功的路上并不拥挤,因为坚持的人不多。只有坚持了,我们才知道,这一路上有多少事情需要干,有多少东西需要学习。随着时间的推移,任何一条通往成功的道路上同行者会越来越少。把”胜者为王”改为”剩者为王”也许更能准确地表达成功与坚持的关系。生命需要一种激情,当这种激情能让别人感到你是不可阻挡的时候,就会为你的成功让路。所以,亲爱的朋友们,用你满腔的激情继续坚持吧!
Original: https://blog.csdn.net/weixin_44327634/article/details/123127727
Author: 冰履踏青云
Title: 逻辑回归算法实战之信用卡欺诈检测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639549/
转载文章受原作者版权保护。转载请注明原作者出处!