


目录
1.1.1批量梯度下降:每次迭代依据全体样本的误差结果更新回归系数
1.1.2随机梯度下降:每次迭代依据某个样本的误差结果更新回归系数
1.1.3小批量梯度下降:每次迭代依据部分样本的误差结果更新回归系数
6.1.1 拉格朗日乘子-无约束条件下的目标函数最优解->最优解:J(x,y)梯度为0的点
当数据集较小时,可以通过诸如求导方式一步就能求出参数w,但当数据集很大时,计算速度就会变得很慢,有时无法直接通过求导计算,这个时候可以通过迭代优化算法逐步求解。常见优化算法如下
- 梯度下降:代价函数:总误差和最小。一阶导,梯度,迭代同步更新
- 共轭梯度:线搜索算法,无需手动设置步长,
- 坐标下降:线搜索算法,无需手动设置步长,代价函数:总误差和最小。偏导,迭代逐项更新
- 牛顿迭代:线搜索算法,无需手动设置步长,二阶导
- 逐步回归: 代价函数:总误差和最小。迭代逐项更新
- 最小角回归 :目标函数:寻找与残差最大相关的特征列,迭代更新
- 拉格朗日乘法:解决含约束的优化问题
1、梯度下降
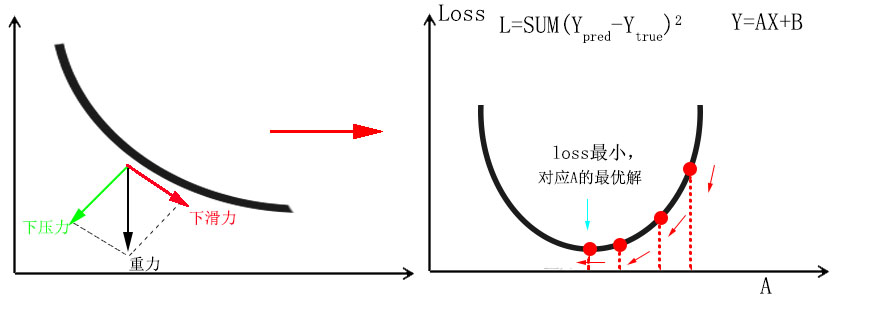
如下图所示,已知一组线性分布数据(x,y),我们想寻找出一条直线h(x)=AX+B,拟合数据。那么如何寻找出这样一条直线呢?
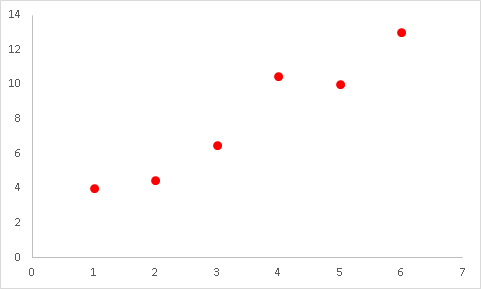
步骤如下:
- 我们只要确定系数A,截距项(偏置项)b,就可以找到这样一条直线。那么如何确定呢?我们可以用穷举法,通过无数的(A,b)组合,来构造出无数条直线,然后从中选出一条最佳直线。那么如何确定是最拟合的直线呢?
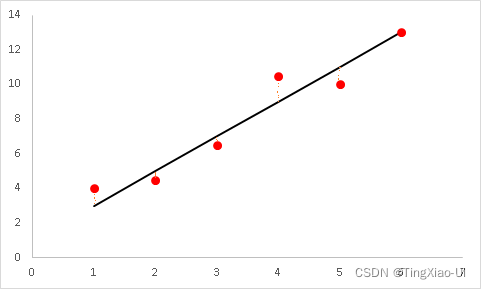
- 算一算每一条直线上的点与已知点的距离的平方差求和的数值即计算损失函数,看看哪条直线算的值最小,那么就说明这条直线最佳即最拟合,可是这样找最佳直线太费力了,无异于大海捞针,那么如何改进一下呢?
- 我们可以设计这样一个代价函数,寻找使代价函数最小时的参数(A,b),对于每一个系数(A,b)对应的代价函数值可以表示为:,其中假设函数:,这样就能找到最佳拟合直线,如下公式所示:
更一般地,设有如下数据集 X(mn:m行样本,n列特征,表示截距项),n列特征对应的权重系数为 w(n1),应变量 Y(m*1)。则有如下代价函数公式,如下所示: 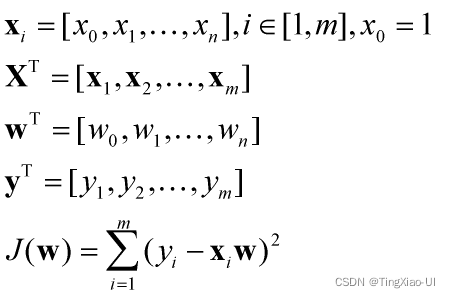
- 计算出最优参数,我们就可以找出最优拟合直线(注:这里的代价函数为凸函数,计算出解即使是局部的解也是全局最优解)。那么如何计算上面的代价函数求解出参数w*?

- 使用迭代优化方法之一:梯度下降求解
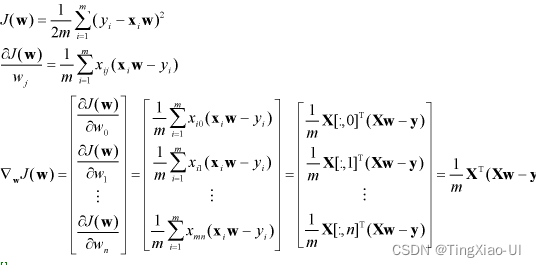 注意:这里代价函数乘以1/m,乘或不1/m不影响最终计算结果
注意:这里代价函数乘以1/m,乘或不1/m不影响最终计算结果
3.迭代更新参数,对参数矩阵 w中每个参数w分别 求偏导乘以学习率后 ,同步迭代更新w,直到到达最佳解(最优解/局部最优解),算法收敛
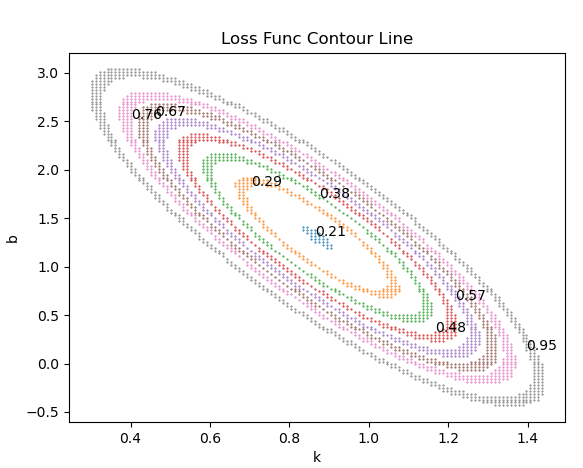
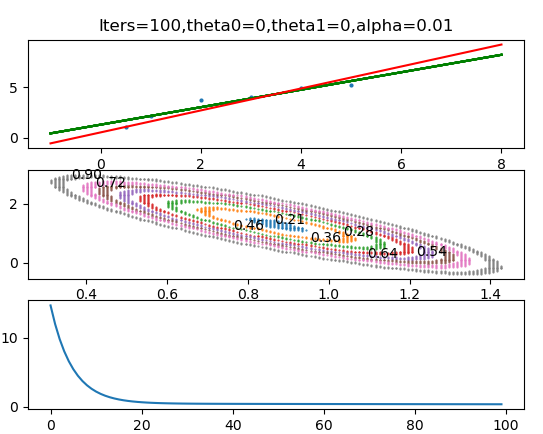
什么是梯度下降呢?在机器学习中可以简单表示为如下图所示,具体可以理解为for循环遍历具有方向的步长(步长乘以斜率/方向导数/梯度)来计算loss值,直到斜率接近0,斜率=0表明某次循环后计算的loss值最小,这样我们就找到了loss值最小时的对应的”最优解”系数A。梯度的方向即为方向导数取极值的方向或函数变化速度最快的方向,如右下图所示,系数的代价函数的二维等高线图。
注意:如下图所示,当我们迭代更新参数时,首先要设计一个初始参数
,才能进行之后的步骤
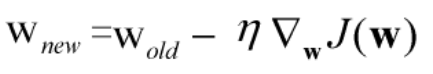
当代价函数非凸时,初始参数的不同也会影响收敛速度和最终的计算结果可能时局部最优解,,如下图所:
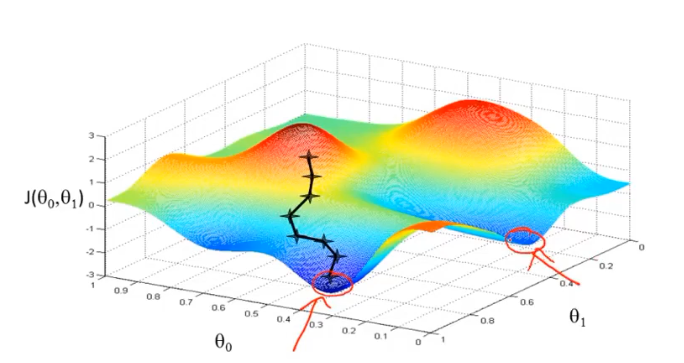
注:该图片来自吴恩达机器学习教程
而当代价函数为凸函数时, 凸函数的局部最优解就是全局最优解,如果迭代次数足够,则不需考虑初始系数取值的不同对最终的最优解位置影响,如下所示:
所以,设计模型时,为了得到全局最优解,我们要尽可能的设计目标函数为凸函数。
1.1.1批量梯度下降:每次迭代依据全体样本的误差结果更新回归系数
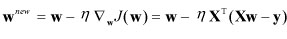
1.1.2随机梯度下降:每次迭代依据某个样本的误差结果更新回归系数

1.1.3小批量梯度下降:每次迭代依据部分样本的误差结果更新回归系数
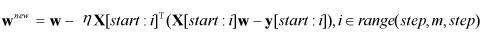
1.2算法优缺点:
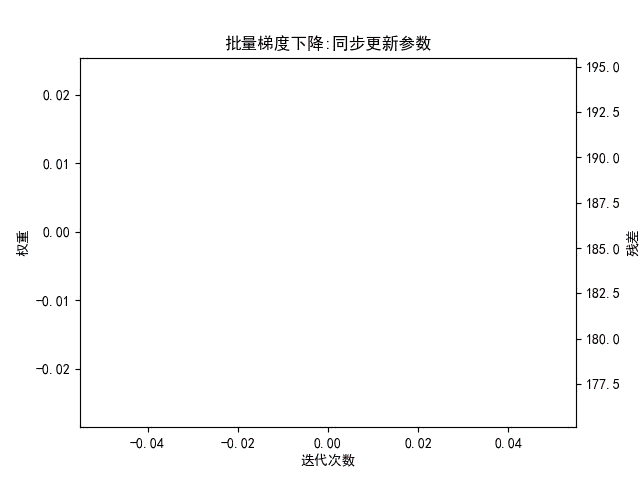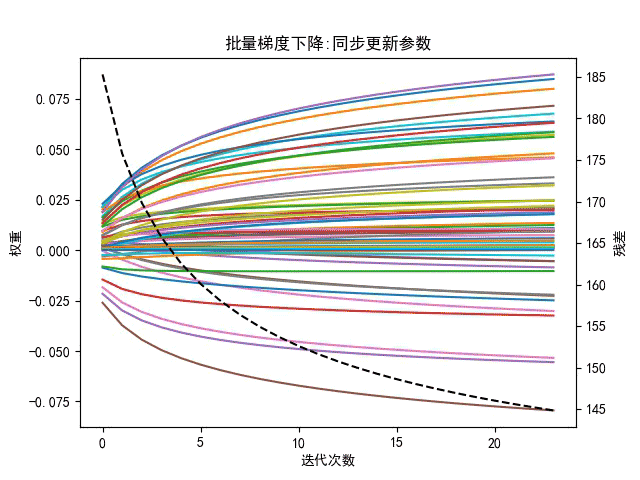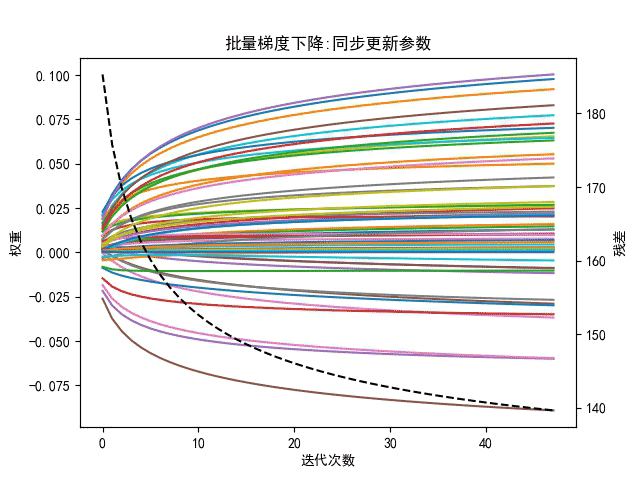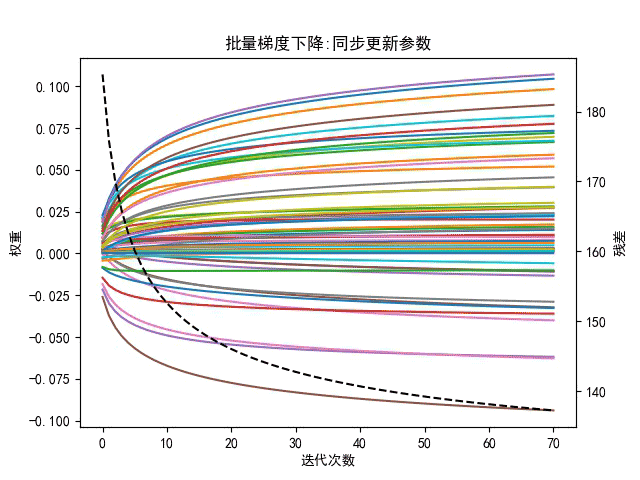
优点:梯度下降是一个有逻辑的更新递进求解的过程,前进方向(迭代方向)按照切线方向(负梯度方向),可以保证每一次前进以后,Loss值都会降低,对于大部分连续函数和曲线都可以用此方法求解,速度比穷举快。梯度下降法比较”柔和”,如下所示
注:黑色虚线表示总误差和,图像右侧Y坐标有误,应注明为误差和(懒得重画了)
梯度下降法只在小领域内是最快的,其收敛速度受学习率的影响很大,因此算法鲁棒性较差,对于一般的二次型,若条件数较大,抖动下降将成为梯度下降法的常态,所以梯度下降法的下降速度不是很快,而且还会来回跳动,收敛较慢,所以梯度下降法也很不稳定。
缺点:
- 梯度只能知道导数方向(切线方向),不能知道到最优点的还有多远,所以我们需要手动建一个固定步长*方向导数,好让它在之前参数的基础上进行更新,这个固定步长我们也可以称为学习率,算法对学习率的大小极其敏感,学习率太大:可能直接错过最低点,学习率太小:在求解的过程中相比需要很多次迭代进行求解才能到达最低点。
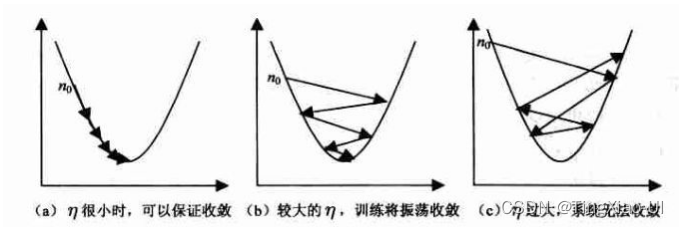
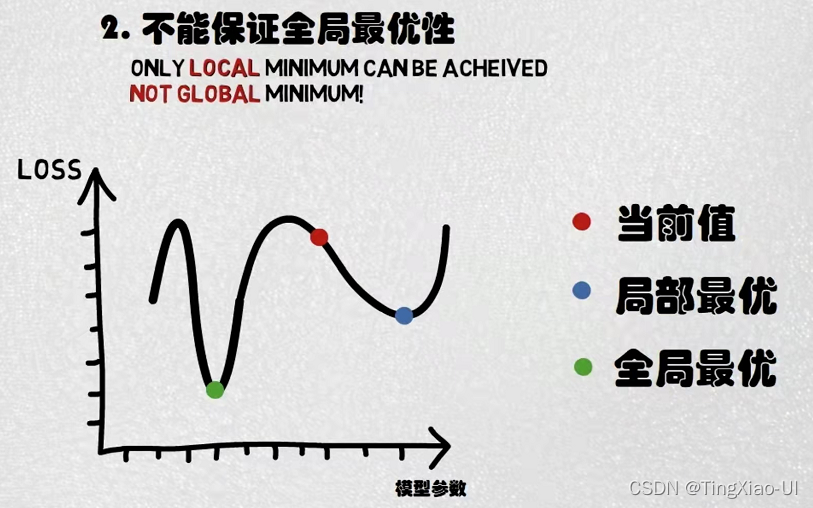
- 不能保证全局最优性,当函数存在多个波分波谷,使用梯度下降只能定位到当前波谷的最低点,而不能跳出这个范围到另一个波谷中,也就是说当前Loss还不是最小值还可以更低。所以求解逻辑回归问题时,通常需要使代价函数为凸函数。不同于线性回归问题,线性回归的代价函数(MSE)通常为凸函数,而在逻辑回归(分类)问题中,采用MSE+sigmoid函数的代价函数为非凸函数,只能找到局部最优解,因此需要保证逻辑回归的代价函数为凸函数,因此采用交叉熵函数作为逻辑回归的代价函数。
注:该图片来自网络。
2、共轭梯度法
待补充
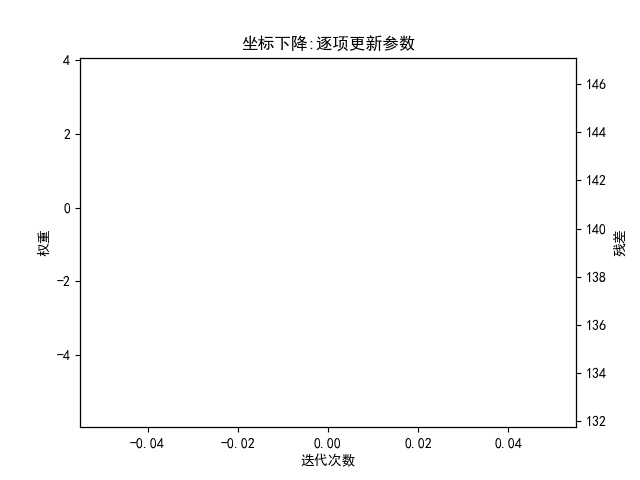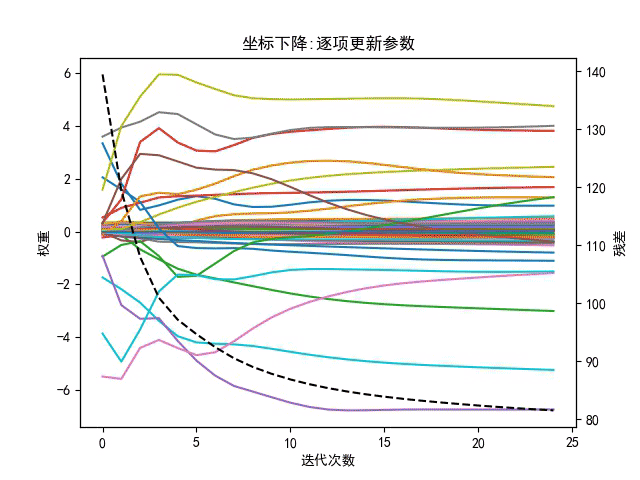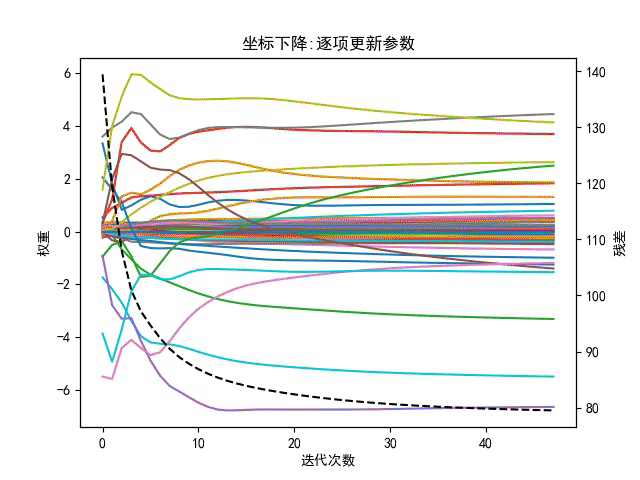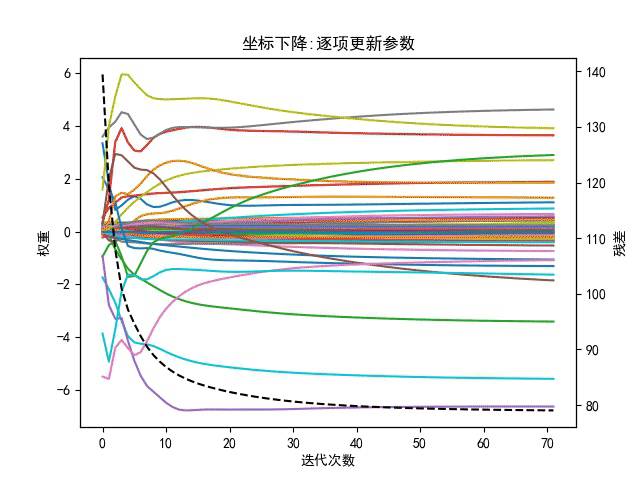
3、坐标下降
坐标轴下降法顾名思义,就是沿着坐标轴的方向下降,这和梯度下降不同,梯度下降是沿着梯度的负方向下降。不过梯度下降和坐标轴下降的共性就都是迭代法,通过启发式的方式一步一步迭代求解函数的最小值,梯度下降是同步更新参数,而坐标下降是对每个参数逐项更新。
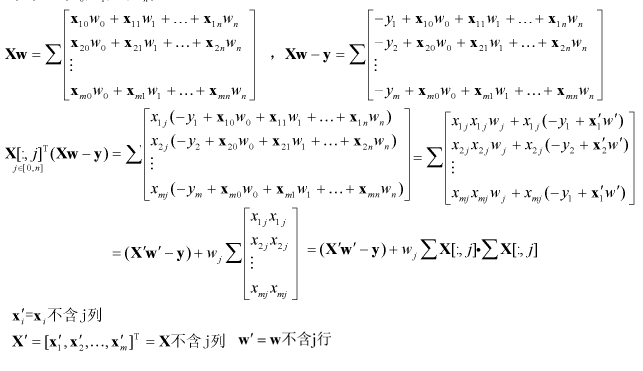
使用坐标轴下降求解,对参数 w的每个元素求偏导为0时的极值点(
)后 迭代更新参数 ,计算过程 如下所示 :
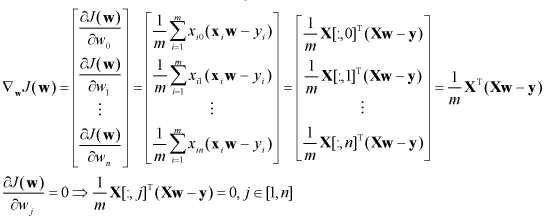
梯度下降和坐标区别:
每次迭代中:梯度下降法只沿一个(同步更新所有特征)方向(当前下降最快的方向)
while 最大次数 或者
更新
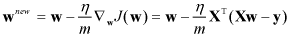
而坐标轴下降法 逐项更新每个方向zuowhile 最大次数 或者收敛程度
for j in 方向:
更新
3.1坐标下降法特点:
- 坐标轴下降法在每次迭代中,计算当前点处沿一个坐标方向进行一维搜索 ,固定其它维度的坐标方向,找到一个函数的局部极小值。而梯度下降总是沿着梯度的负方向求函数的局部最小值。
- 坐标轴下降优化方法是一种非梯度优化算法。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度下降的迭代
- 梯度下降是利用目标函数的导数来确定搜索方向的,该梯度方向可能不与任何坐标轴平行。而坐标轴下降法法是利用当前坐标方向进行搜索,不需要求目标函数的导数,只按照某一坐标方向进行搜索最小值
- 两者都是迭代算法,且每一轮迭代都需要O(mn)的计算量(m为样本数,n为维度数)
- 当多个变量之间有较强的关联性时,坐标下降不是一个很好的方法,坐标下降法会使得优化过程异常缓慢。在应用坐标下降法之前可以先使用主成分分析法(PCA)使各变量之间尽可能相互独立。
4、牛顿迭代
待补充…
5、逐步回归
逐步回归是一种线性回归模型自变量选择方法,其基本思想是将变量一个一个引入,引入的条件是其偏回归平方和经验是显著的。同时,每引入一个新变量后,对已入选回归模型的老变量逐个进行检验,将经检验认为不显著的变量删除(归零),以保证所得自变量子集中每一个变量都是显著的。此过程经过若干步直到不能再引入新变量为止。这时回归模型中所有变量对因变量都是显著(显著减小残差)的。
我们知道多元回归中的元是指自变量,多元就是多个自变量,即多个x(这里指特征列)。这多个x中有一个问题需要我们考虑,那就是是不是这多个x都对y有作用。答案就是有的时候都管用,有的时候部分管用。那对于那些没用的部分我们最好是不让它加入到回归模型里面。我们把这个筛选起作用的变量或者剔除不起作用变量的过程叫做变量选择。
如何评判一个自变量到底有用没用呢?判断依据就是对自变量进行 显著性检验。具体方法是将一个自变量加入到模型中时,有没有使残差平方和显著减少,如果有显著减少则说明这个变量是有用的,可以把这个变量加入到模型中,否则说明时无用的,就可以把这个变量从模型中删除(或者其权重置零)。有没有显著减少的判断标准就是根据F统计量来判断。
变量选择主要有:向前选择、向后剔除、逐步回归(向前选择+向后剔除)、最优子集等。
5.1、向前选择
向前选择可以理解成从零开始选择,因为模型最开始的时候是没有自变量的,具体的步骤如下:
- 拿现有的k个变量分别和y建立回归模型,最后会得到k个模型以及每个模型中变量对应的F统计量和其p_value,然后从显著的模型中挑选出F统计量最大模型对应的自变量,将该自变量加入到模型中,如果k个模型都不显著,则选择结束。
- 通过第一步我们已经得到了一个显著性变量,并把这个变量加入到了模型中。接下来再在已经加入一个变量的模型里面继续分别加入剩下的变量,能够得到k-1个模型,然后在这k-1个模型里面挑选F值最大且显著的变量继续加入模型。如果没有显著变量,则选择结束。
- 重复执行上面两步,直到没有显著性变量可以加入到模型为止
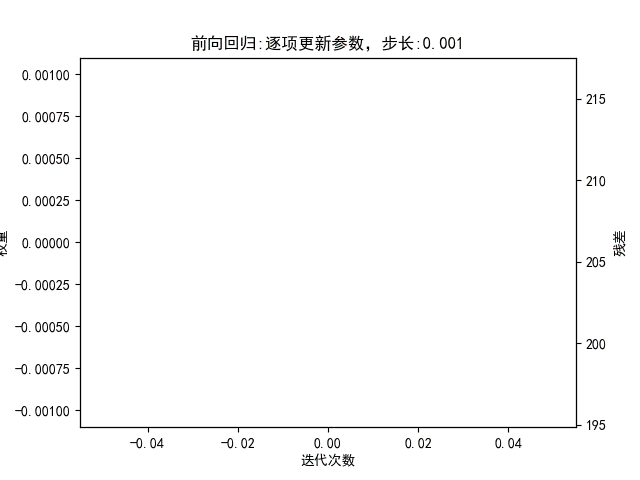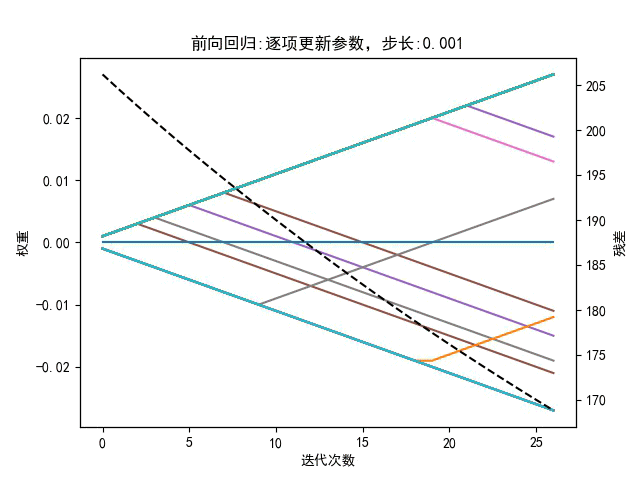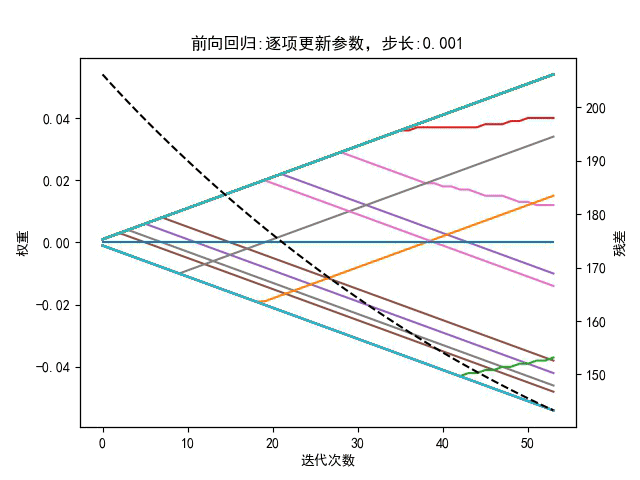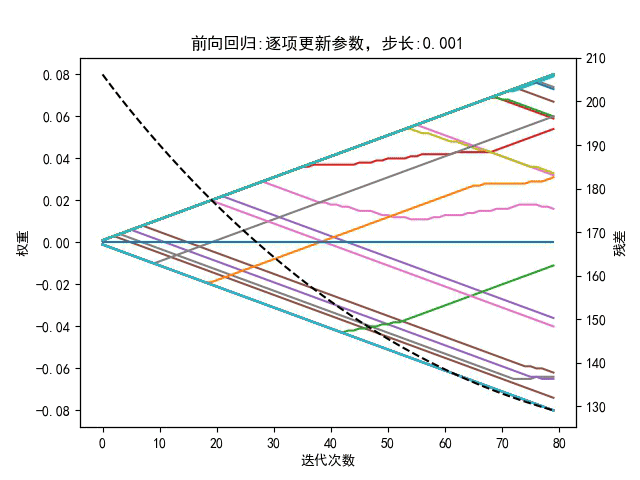
5.2、向后剔除
向后剔除是与向前选择相对应的方法,是向前选择的逆方法,具体的步骤如下:
- 将所有的自变量都加入到模型中,建立一个包含k个自变量的回归模型。然后分别去掉每一个自变量以后得到k个包含k-1个变量的模型,比较这k个模型,看去掉哪个变量以后让模型的残差平方和减少的最少,即影响最小的变量,就把这个变量从模型中删除。
- 通过第一步我们已经删除了一个无用的变量,第二步是在已经删除一个变量的基础上,继续分别删除剩下的变量,把使模型残差平方和减少最小的自变量从模型中删除。
- 重复上面的两个步骤,直到删除一个自变量以后不会使残差显著减少为止。这个时候,留下来的变量就都是显著的了。
向前选择和向后剔除都有明显的不足。向前选择可能存在这样的问题:它不能反映引进新的自变量值之后的变化情况。因为某个自变量开始被引入后得到回归方程对应的AIC最小,但是当再引入其他变量后,可能将其从回归方程中提出会是的AIC值变小,但是使用前进法就没有机会将其提出,即一旦引入就会是终身制的。这种只考虑引入而没有考虑剔除的做法显然是不全面的。类似的,向后剔除中一旦某个自变量被剔除,它就再也没有机会重新进入回归方程。
根据向前选择和向后剔除的思想及方法,人们比较自然地想到将两种方法结合起来,这就产生了逐步回归。
逐步回归是向前选择和向后踢除两种方法的结合。是这两种方法的交叉进行,即一遍选择,一边剔除。逐步回归法选择变量的过程包含两个基本步骤:
- 是引入新变量到回归模型中(向前回归)
- 从回归模型中剔出经检验不显著的变量(向后剔除
while 总误差平方和变化程度:
for j in w:#逐项遍历更新
前向回归
for sign in [-1,0,1] #向左走、向右走或不走-> w[j]增加、减小或不变
w[j] +=stepsign
loss1 =更新当前 w*[j]下的代价函数(总误差平方和)
向后剔除,特征列对应的权重参数直接置零
w[j] = 0
loss2 =更新当前 w[j]下的代价函数(总误差平方和)
判断哪种方式的代价函数降低,就选哪种方式更新当前参数 w[j]
w[j]=前向回归(-1/0/1)/后退剔除
end
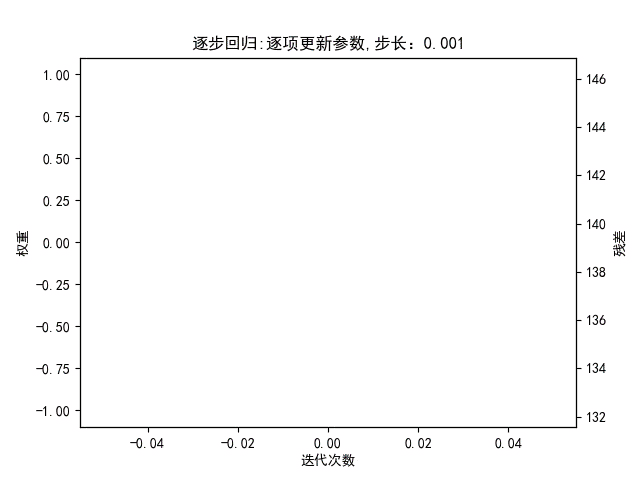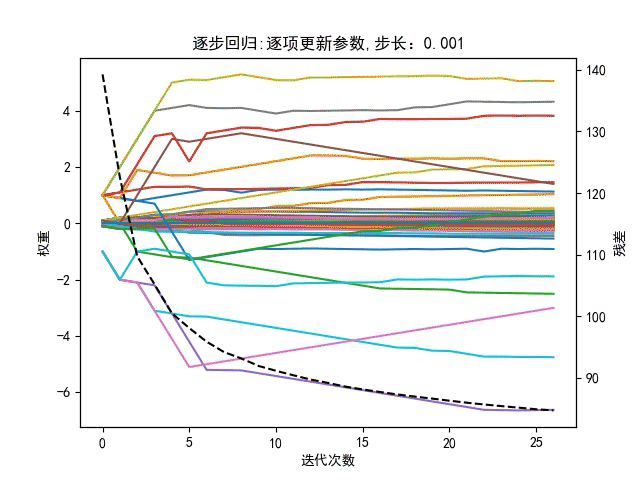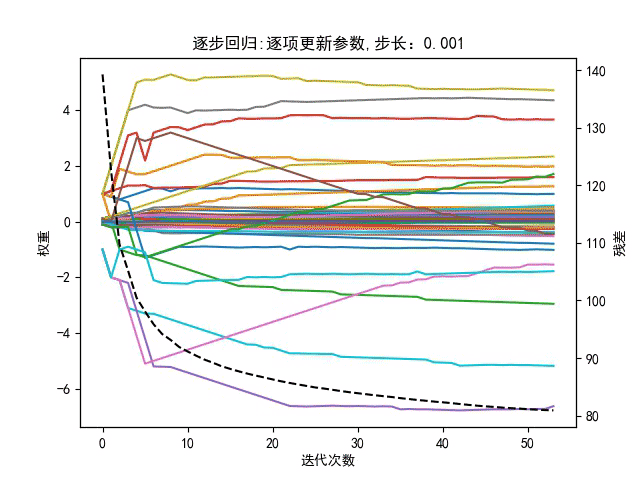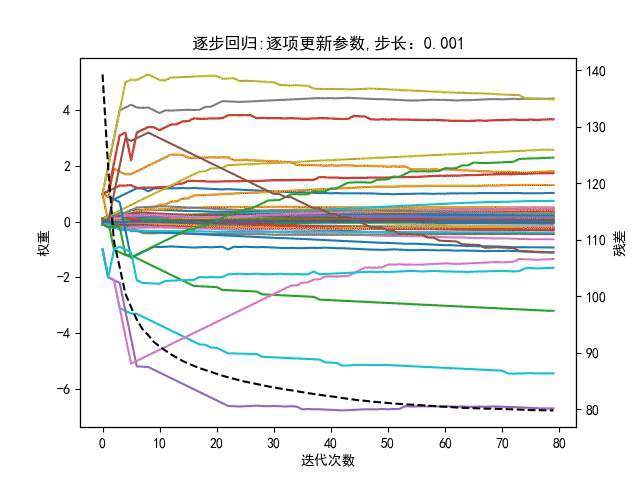
逐步回归在每次往模型中增加变量时用的是向前选择,将F统计量最大的变量加入到模型中,将变量加入到模型中以后,针对目前模型中存在的所有变量进行向后剔除,一直循环选择和剔除的过程,直到最后增加变量不能够导致残差平方和变小至前后”不在变化”为止。
6、最小角回归
关于最小角回归,首先解释”最小角”是什么。这里的角指两个向量的夹角,用来衡量两个向量的相似度,这里指线性相关性,如下所示,为余弦相似度计算方法。更多相似度计算方式见文章相似性度量方法:相关系数和相似系数
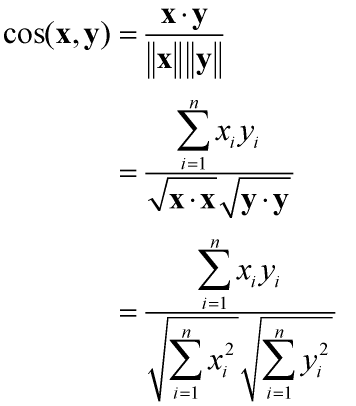
如上公式,可以得到余弦相似度和夹角成反比,向量夹角越小,其余弦相似度越高,相关性也越强,即最小角回归算法其实也可以称为最大相关回归算法,这里的相关指样本 X的特征向量(m1)与残差()的相关性,所以,最小角回归算法的目标函数是在迭代寻找与残差 最大相关的 每项特征向量,而逐项回归的目标函数是 总误差和最小*。
算法步骤如下:
- 数据预处理:标准化。初始化参数 w(n*1)为0向量
- 计算当前参数 w下的残差:
- 计算所有特征向量与残差余弦相似度,寻找与残差最大的相关的特征向量及其对应的余弦相似度,索引J
- 更新权重系数:
- 重复步骤2、3、4
注:这里计算相似度除了余弦相似度也可以用皮尔逊相关系数衡量线性相关性,在数据标准化处理后,余弦相似度和皮尔逊相关系数二者等价,且皮尔逊相关系数等价于对数据标准化处理后的协方差。具体见计算相似度的三种方法
最小角回归和逐步回归算法思路其实差不多,都是对自变量做显著性检验 ,不同的是:
对于逐步回归: 逐项更新参数w的每一个元素,更新依据总误差平方和大小,更新方式:前向回归/向后剔除
while 总误差平方和变化程度:
for j in w:#逐项遍历更新
前向回归
for sign in [-1,0,1] #向左走、向右走或不走-> w[j]增加、减小或不变
w[j] +=stepsign
loss1 =更新当前 w*[j]下的代价函数(总误差平方和)
向后剔除,特征列对应的权重参数直接置零
w[j] = 0
loss2 =更新当前 w[j]下的代价函数(总误差平方和)
判断哪种方式的代价函数降低,就选哪种方式更新当前参数 w[j]
w[j]=前向回归(-1/0/1)/后退剔除
end
对于最小角回归: 更新参数w的每一个元素(不是逐项),更新依据特征向量与残差的相关强度,更新方式:±相关系数*步长。注意这里的±表示正向关或负相关,稍后会有具体讨论
while 总误差平方和变化程度:
计算当前参数 w下的残差resid(m1)
寻找与当前残差最大相关的特征向量对应的相似度
更新该特征向量对应的参数 w*[j]=更新
end
最小角回归算法得到的参数 w,是一个稀疏向量, 每一个不为0的参数对应的特征列与残差的相关性强度均接近,即向量夹角接近。
注:部分文章称之为共角平分线,即以夹角相等的条件作为更新参数条件,这种说法很形象但不太准确,因为在计算机中是浮点数数值输出,对于浮点数谈相等是没有意义的,只能说两个浮点数大小是否接近,其距离小于某个设定的阈值时,才可以认为”相等”。
关于相关性:
首先需要强调相似度只是反映变量间是否存在 线性关系,只能表明是否线性相关,而不能通过线性相关与否来证明是否独立,因为变量间还可能存在非线性关系。
一般定义相似度或相关系数>0,认为正线性相关,即比如y随x的增长而增长,等于0表示线性不相关,小于0表示负相关,即比如y随x的增长而减小。
在机器学习-特征选择中,当样本数据存在冗余特征时,即两个特征向量之间相关性较强时,可以选择剔除其中一个或者其对应的权重参数置零,称为特征提取或特征缩放
回到最小角回归,与残差呈负相关的特征向量有什么用?可以剔除吗?即在回到最小角回归算法中,更新参数时是选取与残差正相关最强的相似度,还是也要考虑负相关强度?有如下对比图,步长是动态值,左图是更新参数时只考虑正相关相似度最大,有图是同时考虑正负相关的相似度的绝对值最大。
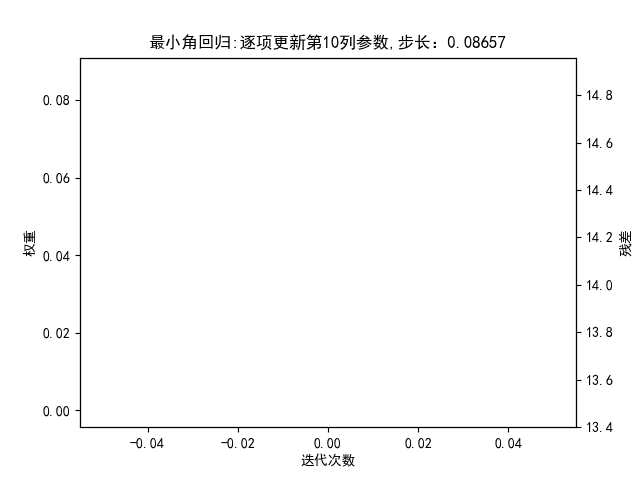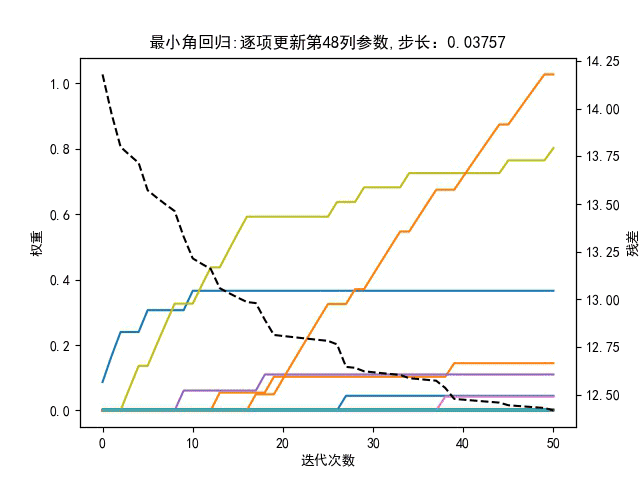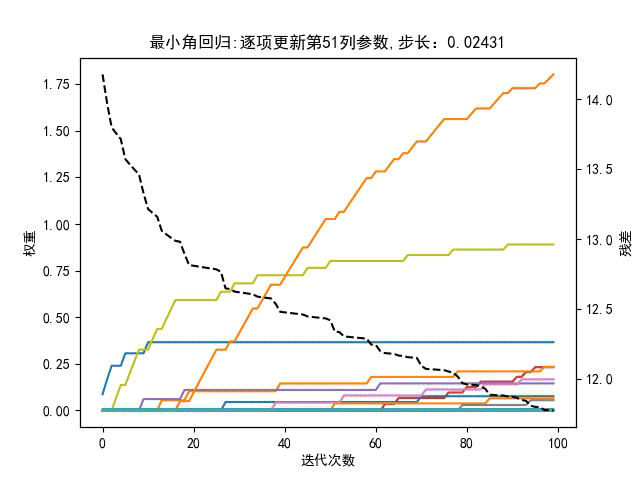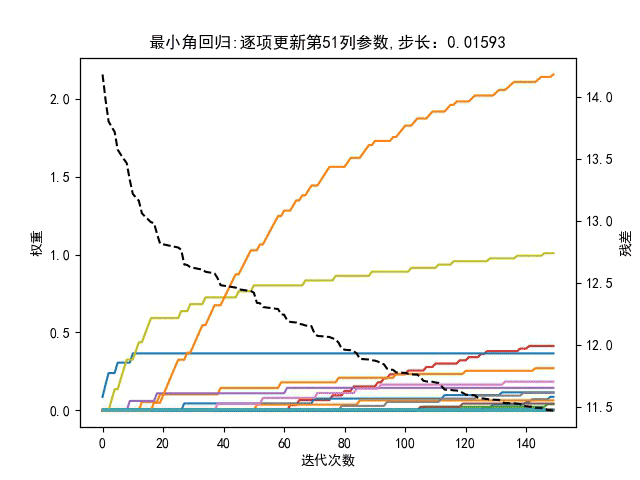
仅靠肉眼观察,貌似右边的图,在相同迭代次数下,总误差平方和曲线下降更快。所以负相关特征也是有贡献的。
此外,步长的设定对迭代算法结果也影响很大,如下所示,将动态步长设置为固定步长
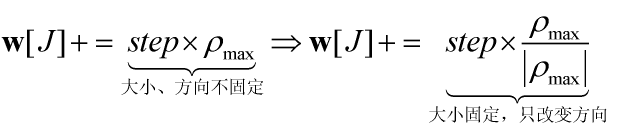
最小角回归算法效果如下:
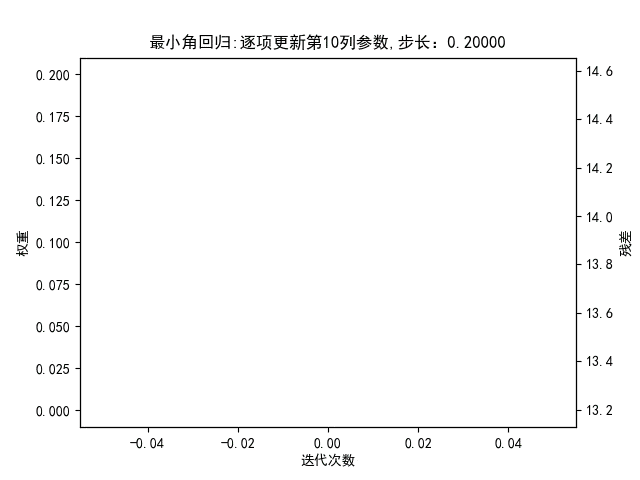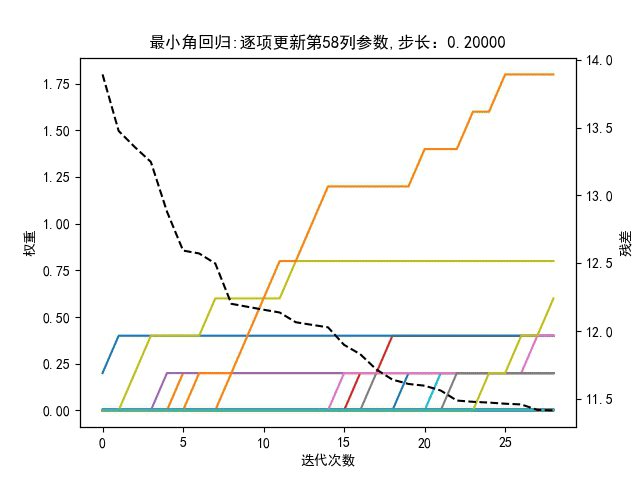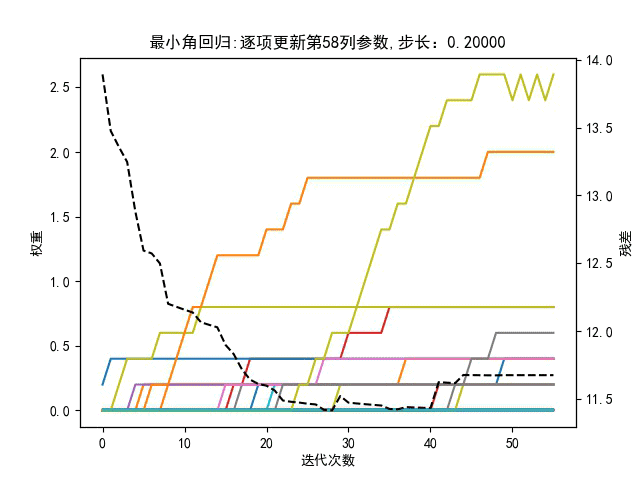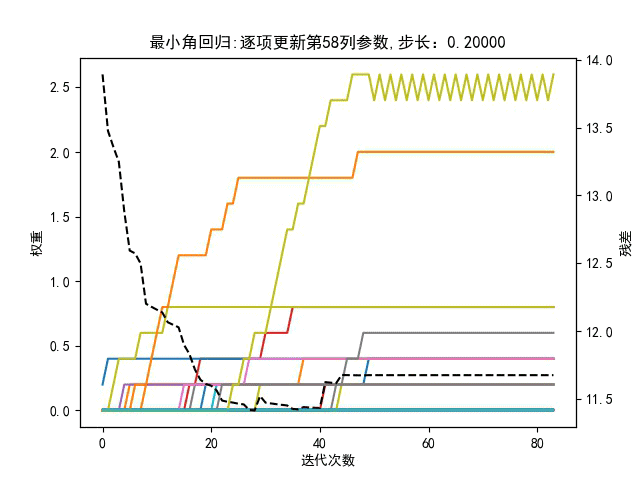
观察,此时固定的步长易使部分参数振荡,难以收敛,与梯度下降相似,如下图所示。
7、拉格朗日乘法
已知如下的模型,目标函数J(w,b)在约束g(w,b)条件下的最小值。在分类问题中可以表示为对于特征向量在决策分界面上测的点分类为类别1,下侧的点分类为类别-1,同时位于样本边界点(支持向量)的两条分界面的间隔最大。
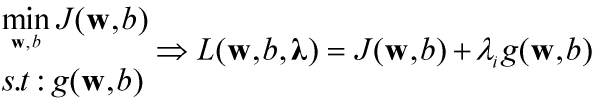
拉格朗日乘子法是一种寻找多元函数在一组约束条件下的极值的方法。通过引入拉格朗日乘子λ,可将有d个变量(w,b),k个约束条件的最优化问题转换为具有d+k个变量的无约束优化问题求解。
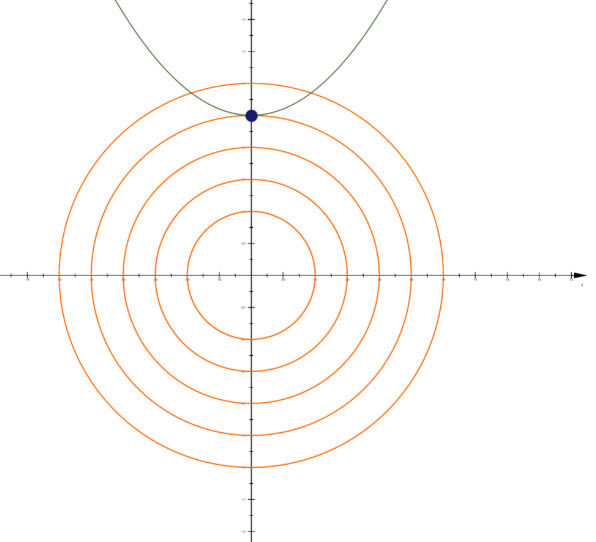
7.1.1 拉格朗日乘子-无约束条件下的目标函数最优解->最优解:J(x,y)梯度为0的点
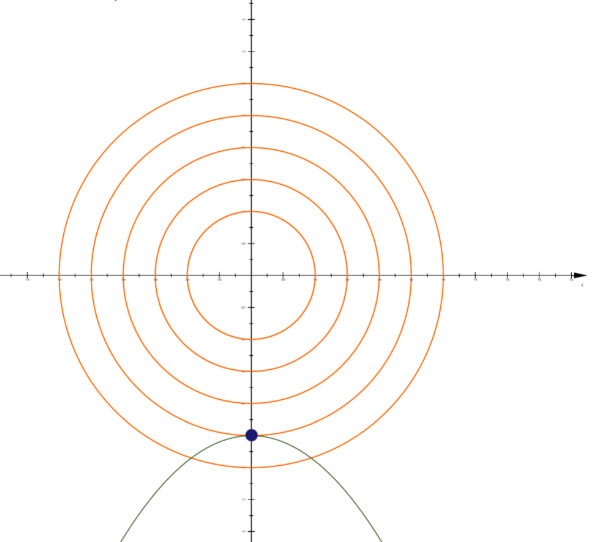
假设目标函数如下所示,J(x,y)的几何图像是一个抛物面,其在xoy面的投影是以原点为中心的同心圆环,由于目标函数J(x,y)为凸函数,凸函数的驻点(各偏导数为0的点)就是全局最优点,所以计算目标函数最小值只需求出J(x,y)关于变量的偏导数等于0的点,即目标函数J(x,y)梯度为0的点就是最优解。
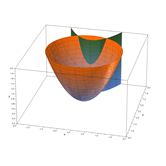

7.1.2 拉格朗日乘子-有约束条件下的目标函数最优解->最优解:g(x,y)=0
约束条件为等式约束,即g(x,y)=0,λ≠0,如下图所示,此时目标函数J(x,y)的最小值在等高线(J(x,y)在XoY面上的投影)与约束线的相切点(相切点的梯度等于0)上。
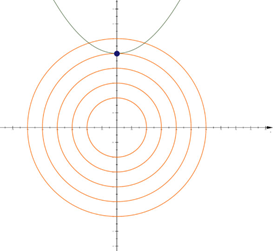
其中的λ就的拉格朗日乘子,目标函数改写为拉格朗日函数如下所示,由于目标函数J(x,y)是二次的且约束在为线性的,所以拉格朗日函数仍为凸函数。
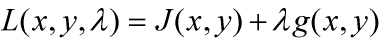
所以 约束条件为等式约束时的最优解为目标函数L(x,y,λ)梯度等于0的点,如下所示,同时表明目标函数和约束函数在切点处的梯度方向共线、方向相反,即使目标函数的梯度等于0。 g(x,y)=0, λ≠0
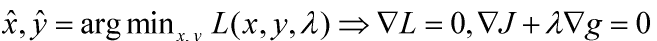
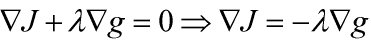
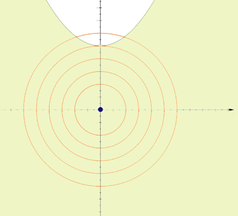
约束条件为不等式约束, g(x,y)≥0或 g(x,y)≤0,如下图所示,约束条件为含等于0的不等式约束,可行域在灰色阴影处,所以极值点只可能在约束线上,此时的不等式约束等价等式约束,即g(x,y)≥0–>g(x,y)=0,λ≠0
所以 约束条件为不等式约束时的最优解为目标函数L(x,y,λ)梯度等于0的点,如下所示
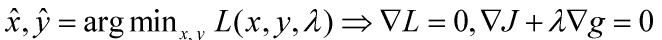
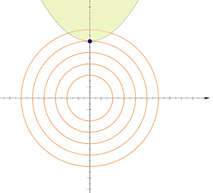
约束条件为不等式约束, g(x,y)≤0或g(x,y)≥0,如下图所示,可行域在灰色阴影处,此时极值点不在约束线上,在目标函数J(x,y)的梯度等于0的点上,此时不等式约束等价于无约束或者即拉格朗日乘子λ=0
所以此时最优解为目标函数J(x,y)梯度等于0的点,如下所示
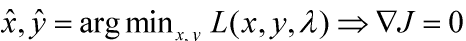
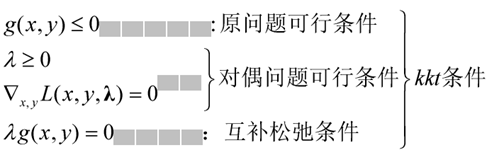
拉格朗日乘子法小结:有约束的凸优化问题改造为无约束的拉格朗日优化问题时,要考虑极值点的可行域在哪里,即约束条件g(x,y)的可行域与目标函数J(x,y)的交集情况。
- 极值点在约束线(目标函数与约束函数的切点)上:输入特征向量在分界面上
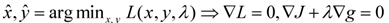
- 极值点在原始目标函数的可行域内与约束条件无关:
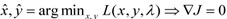
可概括为: λ g(x,y)=0(KKT性质)
如下图所示,约束条件不同,极值点分布情况也有所不同
关于拉格朗日乘子λ的取值范围,应该是λ≥0还是λ≤0,很多文献都习惯λ≥0,其实这个并没有强制性要求,λ的取值视构造拉格朗日函数方式而定,可以灵活取值,如下所示,
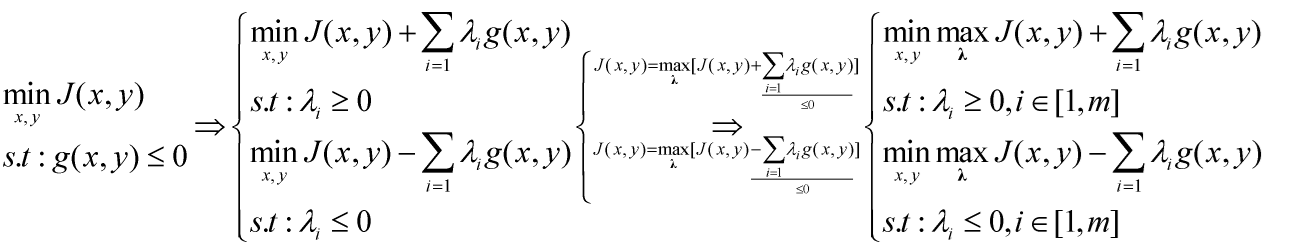
原问题是包含不等式约束的求最小值问题在这里可以等价为minmax(极小极大问题)。
7.2 拉格朗日对偶性
- 任何线性规划问题都有其对偶问题
-
性质:
-
无论原问题是否为凸,对偶问题一定为凸
- 对偶问题可以被理解为寻找原问题目标函数上界或下界的问题
- 对于原问题(minmax)得到的最优解求解的目标函数值≥对偶问题的到的最优解求解的目标函数值:minmax≥maxmin,
对于原问题(minmax),其对偶问题是在寻找原问题目标函数下界。
-
满足一定条件(凸+slater条件 )时,对偶问题与原问题的解等价(强对偶):minmax=maxmin,
-
如何根据原问题求对偶问题:
-
原问题时求极小,对偶问题就是求极大,反之同理
- 一个问题中的约束条件个数等于另一个问题中的变量数(即拉格朗日乘子类别个数:λ,β,μ…)
综上所述,原始问题可以转换为其对偶问题,求最优解x,y转换为求最优解拉格朗日乘子。相比原问题,引入的拉格朗日乘子才是要优化的变量,其他均可以用拉格朗日乘子表示。此外使用拉格朗日对偶并没有改变最优解,而是改变(减小)了算法计算复杂程度。如下公式推导
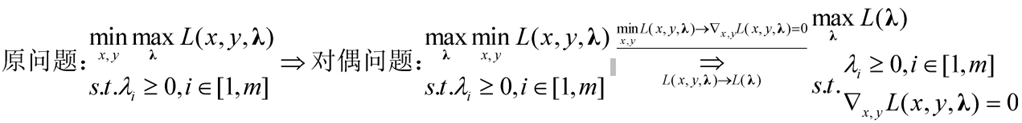
8、代码
代码见Github
Original: https://blog.csdn.net/qingtianhaoshuai/article/details/123987600
Author: TingXiao-Ul
Title: 常见迭代优化算法解析及python实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639525/
转载文章受原作者版权保护。转载请注明原作者出处!