

目标
数据库有5个事务。设min_sup=60%,min_conf=80%。
TID 购买的商品
T100 {M,O,N,K,E,Y}
T200 {D,O,N,K,E,Y}
T300 {M,A,K,E}
T400 {M,U,C,K,Y}
T500 {C,O,O,K,I,E}
算法思想
算法 Apriori。使用逐层迭代方法基于候选找出频繁集。
输入:
D:事务数据库。
min_sup:最小支持度阈值
输出:L,D中的频繁项集。
方法:
(1)=find_frequent_1_itemsets(D);
(2)for(k=2;){
(3)=aproiri_gen();
(4) for each 事务tD{
(5)=subset(,t);
(6) for each 候选c
(7) C.count++;
(8) }
(9) ={c(|c.countmin_sup)}
(10)}
(11)return L=;
pocedure apriori_gen(:frequent(k-1)itemset)
(1) for each项集
(2) for each项集
(3) if(=)(=)(=)then{
(4) c=; //连接步:产生候选
(5) If has_infrequent_subset(c,) then
(6) delete c; //剪纸步:删除非频繁的候选
(7) esle add c to ;
(8)}
(9)return ;
procedure has_infrequent_subset(c: candidate k itemset;:frequent(k-1)itemset)
//使用先验知识
(1)for each(k-1)subset s of c
(2) if sthen
(3) return TRUE
(4)return FALSE
def find_frequent_1_itemsets(data, support):
"""计算频繁一项集"""
min_sup = len(data) * support
itemsets = {}
for d in data:
for vlist in d.values():
for value in vlist:
if value in itemsets.keys():
itemsets[value] += 1
else:
itemsets[value] = 1
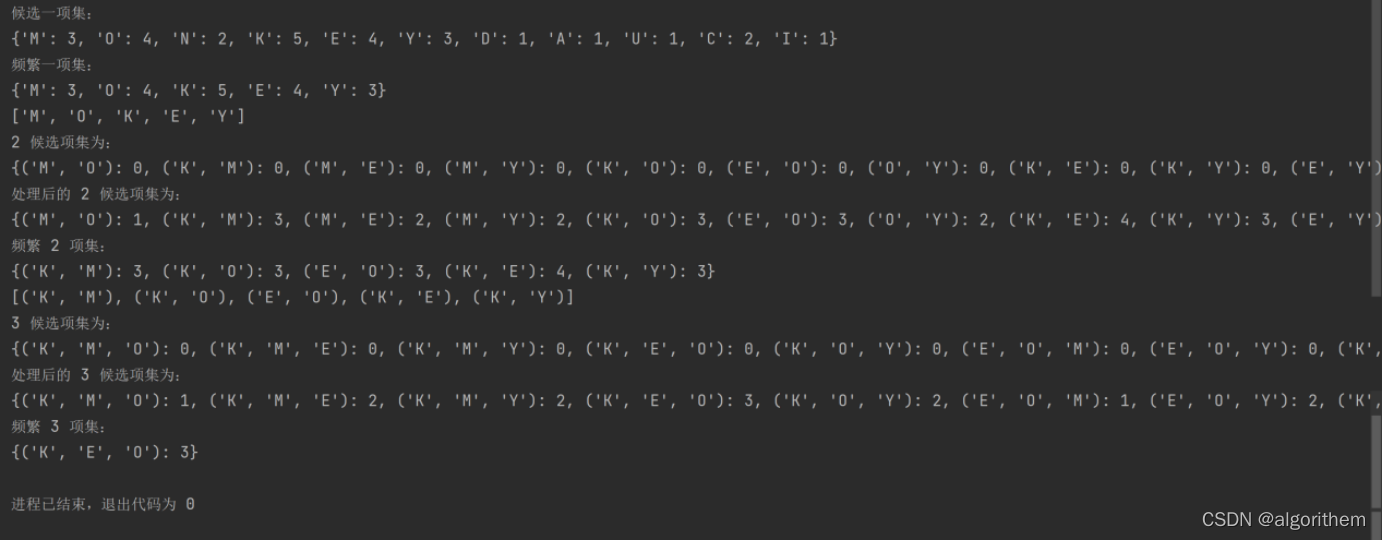
print("候选一项集:")
print(itemsets)
for key in list(itemsets.keys()):
if itemsets[key] < min_sup:
itemsets.pop(key)
print("频繁一项集:")
print(itemsets)
return itemsets
def remove_samekey(this_itemsets):
"""仅保留一个类似(k,e,m)和(e,k,m)这种相同的键"""
key_list = this_itemsets.keys()
new_list1 = []
new_list2 = []
new_itemsets = {}
for ele in key_list:
if set(ele) not in new_list1:
new_list1.append(set(ele))
else:
continue
for ele in new_list1:
new_list2.append(tuple(ele))
for ele in new_list2:
new_itemsets[ele] = this_itemsets[ele]
return new_itemsets
def find_frequent_next_itemsets(data, frequent_n_itemsets, support):
"""从n项集找n+1项集"""
min_sup = len(data) * support
n_itemlist = list(frequent_n_itemsets)
print(n_itemlist)
itemsets = {}
m = len(n_itemlist[0])
for ele1 in n_itemlist:
for ele2 in n_itemlist:
if ele1 != ele2:
if len(ele1) == 1:
if (ele1, ele2) in itemsets.keys():
continue
else:
itemsets[(ele1, ele2)] = 0
else:
for e in ele2:
if e not in ele1:
new_ele = ele1 + (e,)
if new_ele in itemsets.keys():
continue
else:
itemsets[new_ele] = 0
else:
continue
print((m + 1), "候选项集为:")
itemsets=remove_samekey(itemsets)
print(itemsets)
for item1 in data:
for item2 in itemsets.keys():
if (set(item2) set(*item1.values())):
itemsets[item2] += 1
else:
continue
print("处理后的", (m + 1), "候选项集为:")
print(itemsets)
for key in list(itemsets.keys()):
if itemsets[key] < min_sup:
itemsets.pop(key)
print("频繁", m + 1, "项集:")
print(itemsets)
return itemsets
"""对数据进行初始化"""
data = [
{"T100": ['M', 'O', 'N', 'K', 'E', 'Y']},
{"T200": ['D', 'O', 'N', 'K', 'E', 'Y']},
{"T300": ['M', 'A', 'K', 'E']},
{"T400": ['M', 'U', 'C', 'K', 'Y']},
{"T500": ['C', 'O', 'O', 'K', 'I', 'E']}
]
support = 0.6
itemsets = find_frequent_1_itemsets(data, support)
while len(itemsets)>1:
itemsets = find_frequent_next_itemsets(data, itemsets, support)
结果

以上
Original: https://blog.csdn.net/algorithem/article/details/124450856
Author: algorithem
Title: Apriori算法找出频繁项集(python)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/638777/
转载文章受原作者版权保护。转载请注明原作者出处!