

机器学习实战
机器学习三把斧


; 1.数据清洗

1.1缺失值的处理
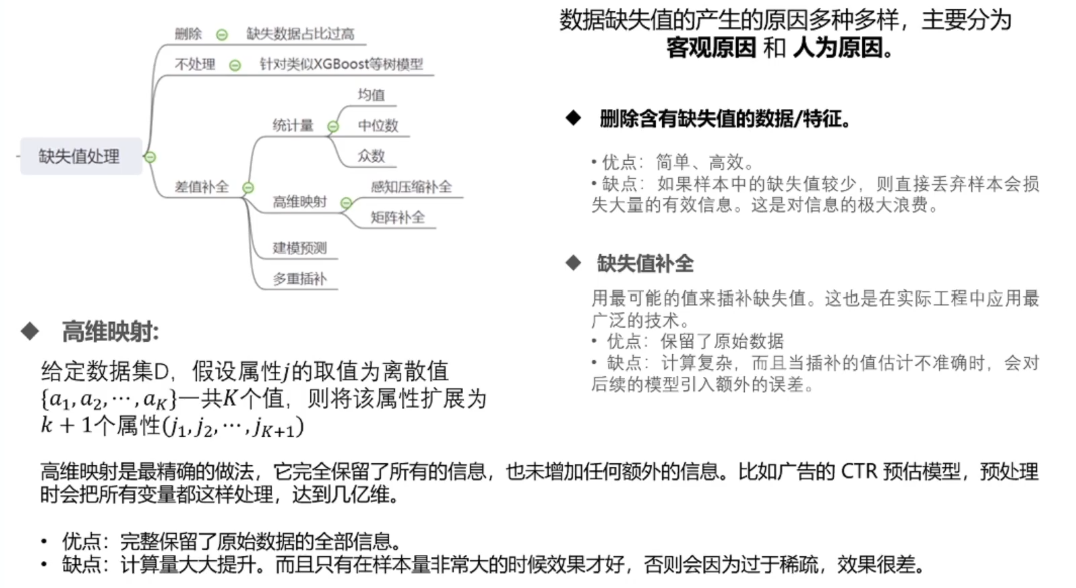
某一列的特征缺失值达到40%左右,删除这个特征值;或者某一个样本的缺失值过大,那么删除这个样本。
而当某个特征的缺失值较少的时候,不能删除这个特征。
建模预测:把缺失值当做模型的预测值,用预测的值填充缺失值
多重插补:前向填充,后项填充
高维映射:就是把缺失值作为一个新的类,只对分类的变量比较好,在广告CTR(点击率)
; 1.2异常值的处理
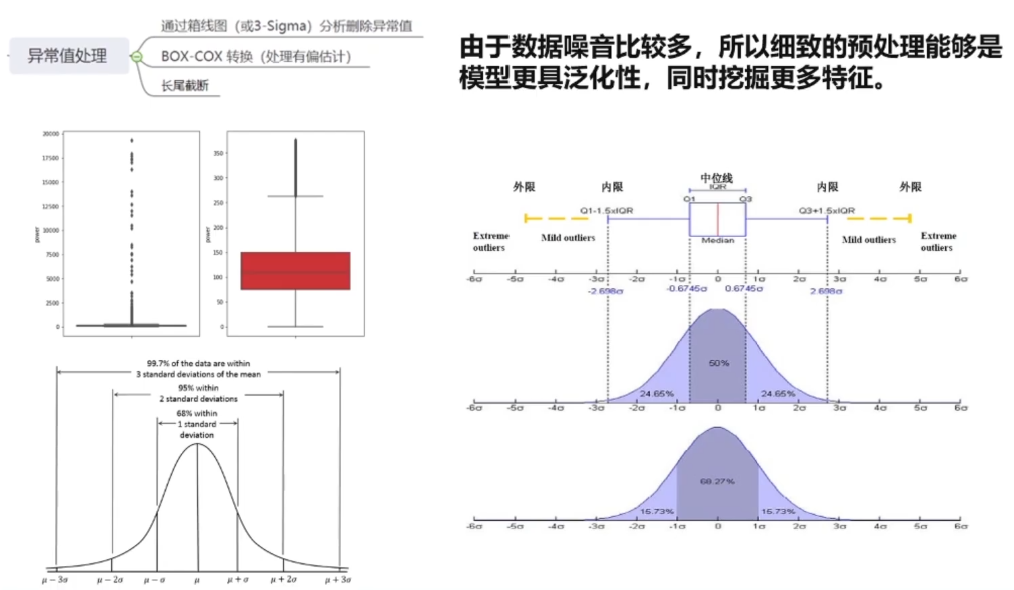
异常:真实的异常,记录的异常。
真实的异常:本来就是这个值,只是和其他样本偏移较大
记录的异常:本来是10,记录成100
1.3数据分桶

数据分桶主要就是连续数据离散化,比如年龄,0-10,10-20,20-30等,然后编号1,2,3
数据分桶可能提升树模型的鲁棒性
; 1.4数据的标准化
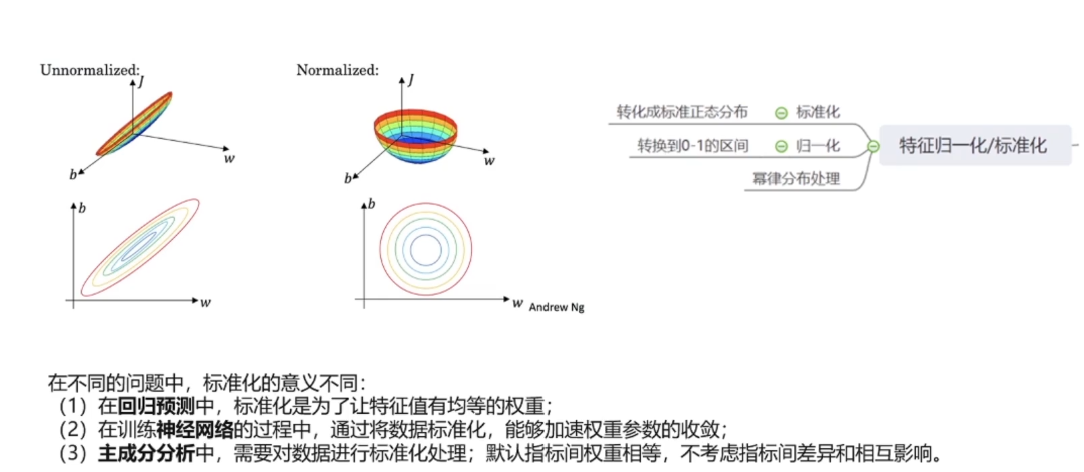
回归中标准化使用较多,分类中大部分也使用,但是分类中的决策数就不需要标准化
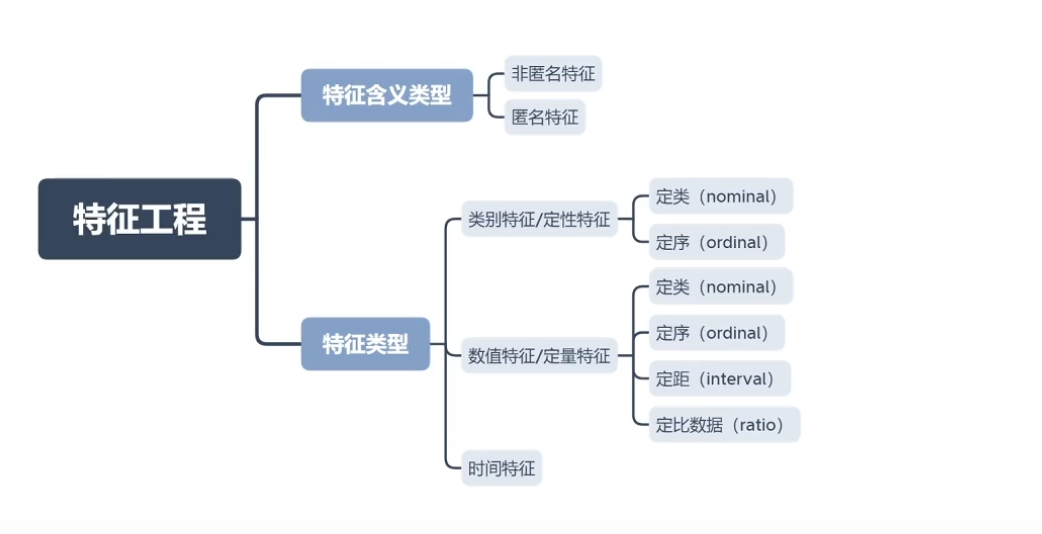
2.特征工程
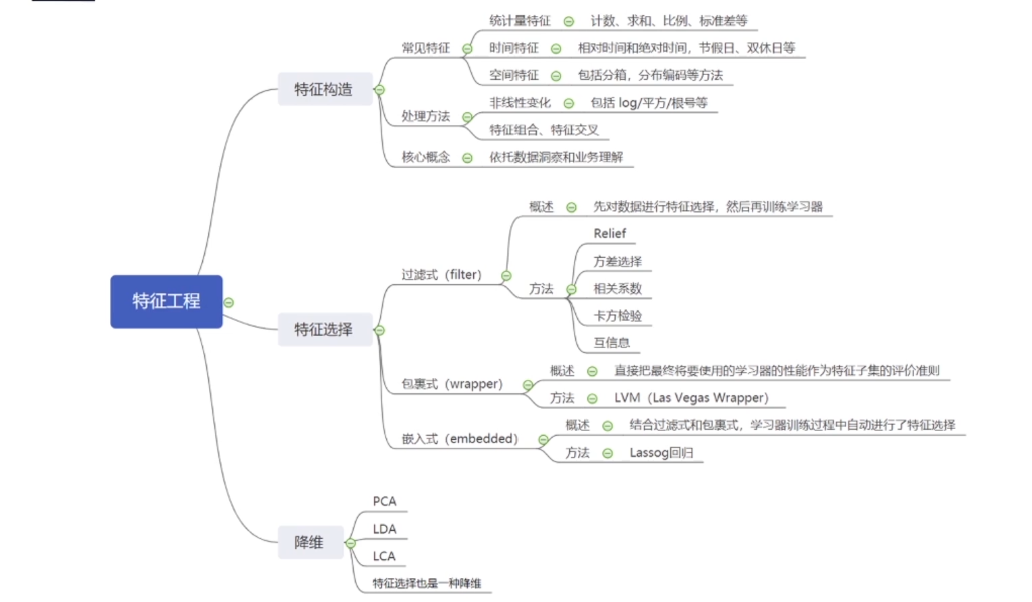
; 2.1特征构造
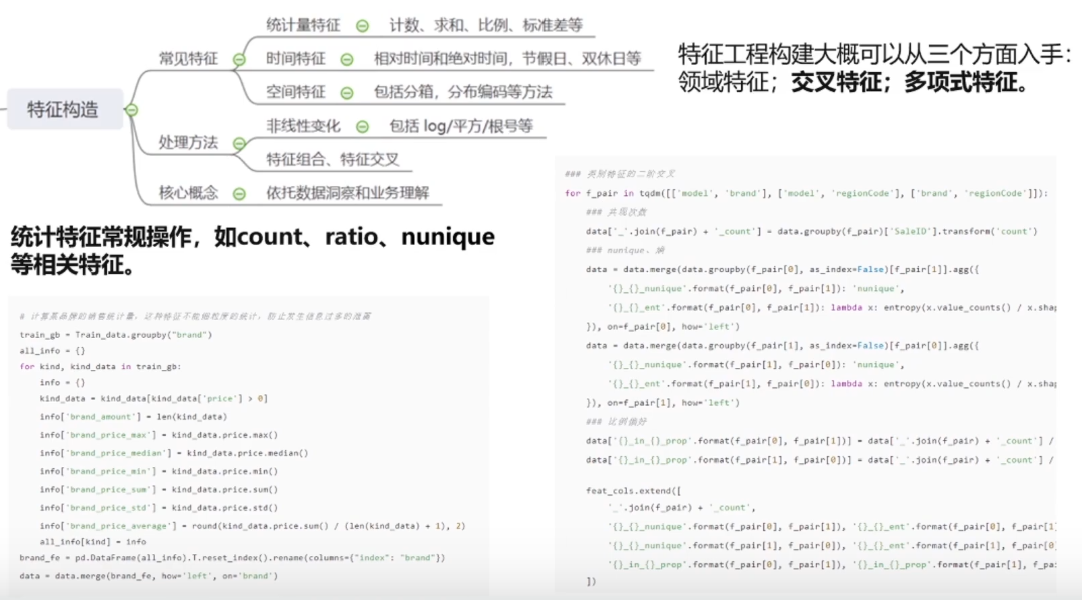
对时间的处理

比赛中要看训练集和测试集的特征分布是否一致,删去不一致的特征
2.2特征选择

可能经过特征构造后,你的特征变成成百上千,这时候就需要先进行特征过滤,用集成学习如XGboost等算出每个特征的权重。
; 2.3特征工程示例

3.模型调参
3.1理解模型

调参的时候首先要理解你使用的模型,了解模型的优点和特性,比如线性回归模型基于标签是高斯分布的
; 3.2评估性能

评估函数不同,模型的性能可能不一样,比如MSE对异常值很敏感,如果A模型误差为0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,5 ;B模型误差为1,1,1,1,1,1,1,1,1,1。用MSE判断A=25.09,B=10。而用MAE,A=5.9,B=10 。
所以如果使用MSE评估,那么就需要特别对异常值进行精确的处理。不同的评估函数重点考虑的方面是不一样的
有个评估函数后,接下来就是验证方法,比如交叉验证,留一验证,以及时间序列的切分一个时间段去预测。交叉验证是目前比较好的验证方式,但是当你的数据特别大比如几个G,预测一次都需要好久,非常需要内存的话可以考虑切分验证(80%训练,20评估)。
时间序列样本是不能做交叉验证和留一验证的,可能会存在数据信息的泄露。往往是根据时间进行切分构造一个和测试区间类似的区间预测
3.3模型调参

网格搜索特别花费时间,比如按上图如果是五折交叉验证就需要计算36*5=180次的计算。
; 4.模型集成
前面的特征工程和模型调参在比赛过程中会反复的进行,反复测试。而模型的集成一般是在比赛的后期进行
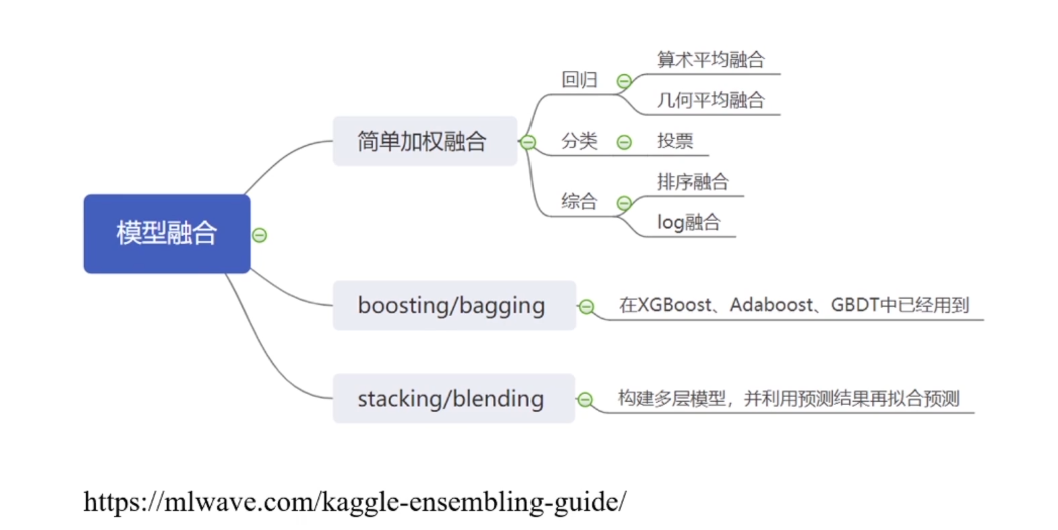
模型融合的基础是你的单模型要好,
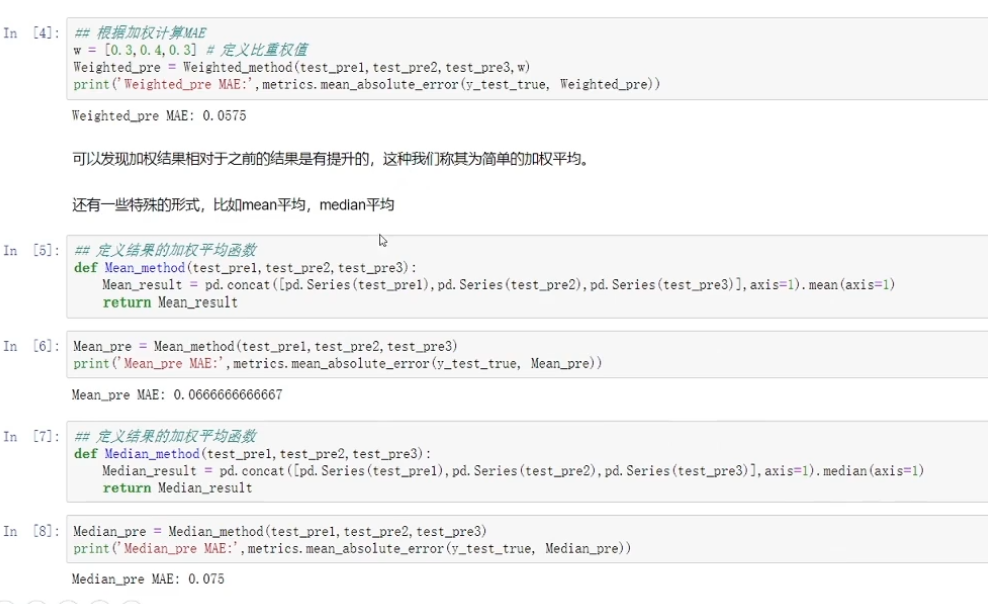
4.1简单加权融合

加权平均时模型的权重最好不要小于0.1,否则这个模型对整体的融合产生不了什么模型收益。
在线提交的时候分数差不多,但是模型的数据差异较大,融合后效果会好(比赛经验)
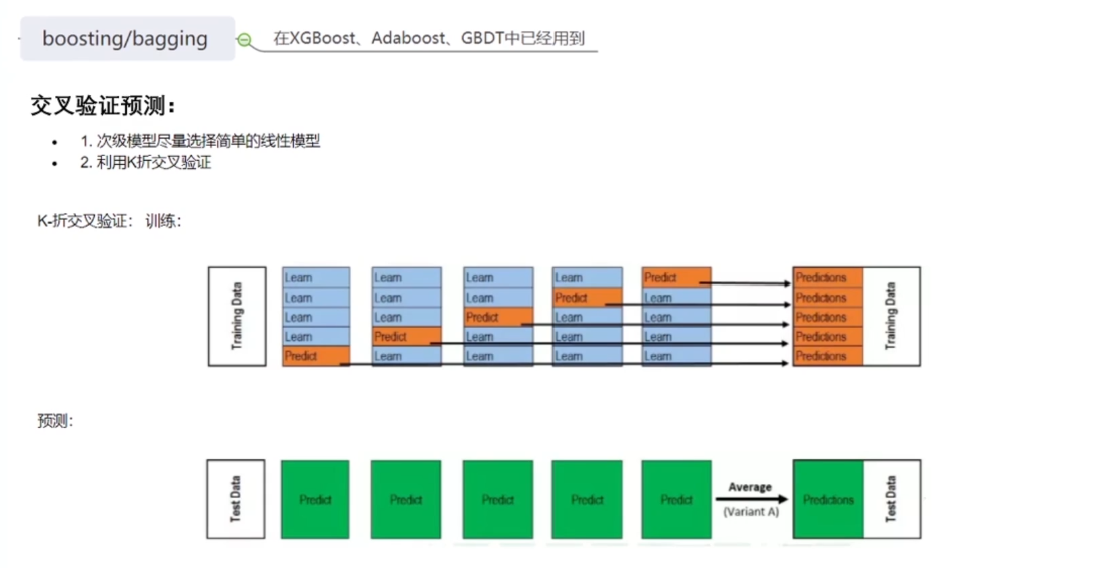
; 4.2boosting/bagging
4.3stacking/blending
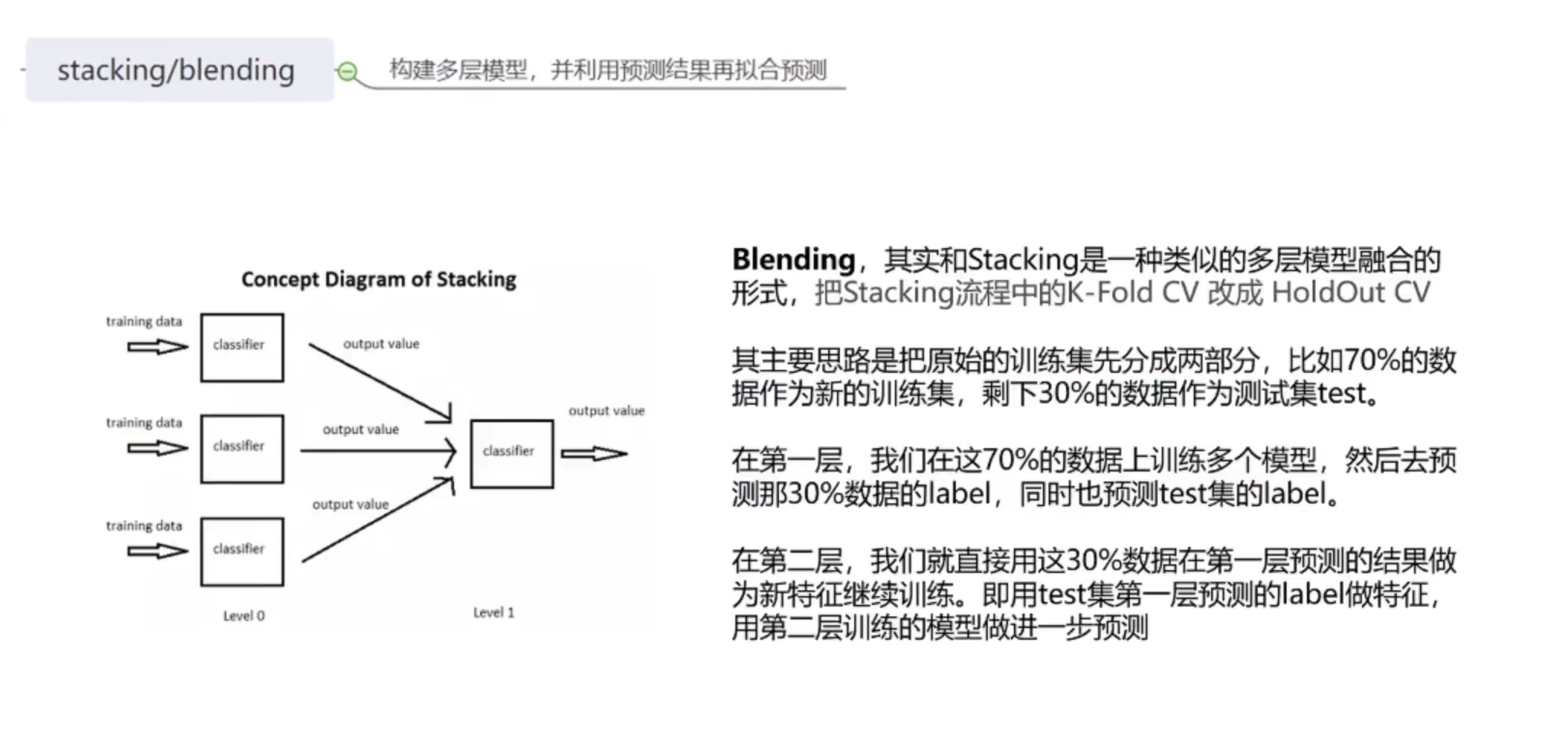
把结果放到另一个简单模型如线性模型再次进行筛选。
; 4.模型融合示例

以上的适用于数据挖掘比赛,和(cv)图像处理的有所不同
特征工程
1.特征工程介绍

; 2.类别特征

ID一般不作为特征,以上数据已经经过脱敏
2.1类别编码


类别编码一般不直接使用,因为red,blue,black本身是没有大小的,变成3,1,2后如果使用的是决策树,那么可能直接会把>2 的区分为一类
; 2.2 One-Hot编码
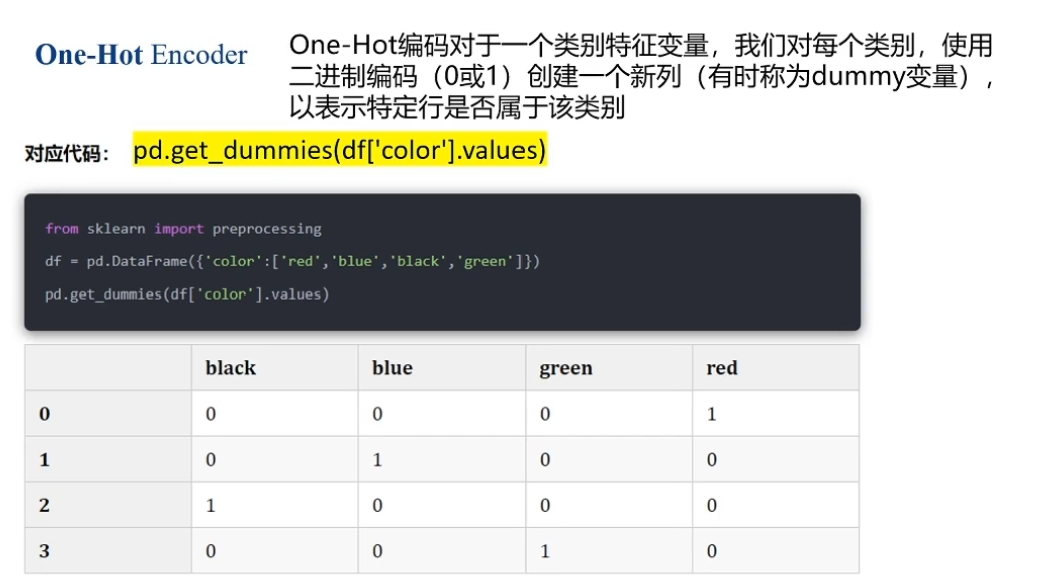
使用one-hot编码可以避免上面引入大小的问题,但是不适用于类别特别多的(如果有100个类)会导致特征分布特别稀疏
2.3 Frequency编码
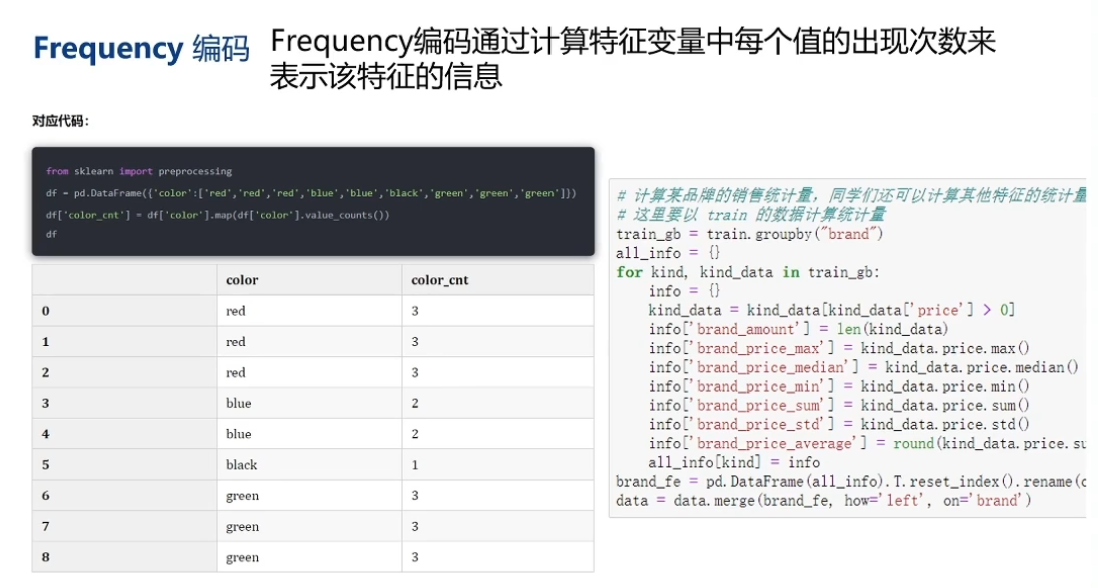
Frequency编码是数据竞赛中使用最为广泛的技术,在90%以上的数据建模的问题中都可以带来提升。因为在很多的时候,频率的信息与我们的目标变量往往存在有一定关联,例如:
- 在音乐推荐问题中,对于乐曲进行Frequency编码可以反映该乐曲的热度,而热度高的乐曲往往更受大家的欢迎;
- 在购物推荐问题中,对于商品进行Frequency编码可以反映该商品的热度,而热度高的商品大家也更乐于购买;
- 微软设备被攻击概率问题中,预测设备受攻击的概率,那么设备安装的软件是非常重要的信息,此时安装软件的count编码可以反映该软件的流行度,越流行的产品的受众越多,那么黑客往往会倾向对此类产品进行攻击,这样黑客往往可以获得更多的利益
; 2.4 Target编码

前面说Label encoder一般不直接用,但是下面这种情况可以使用,年龄段有相对大小的区分,你可以编码为1,2,3,4

3.数值特征
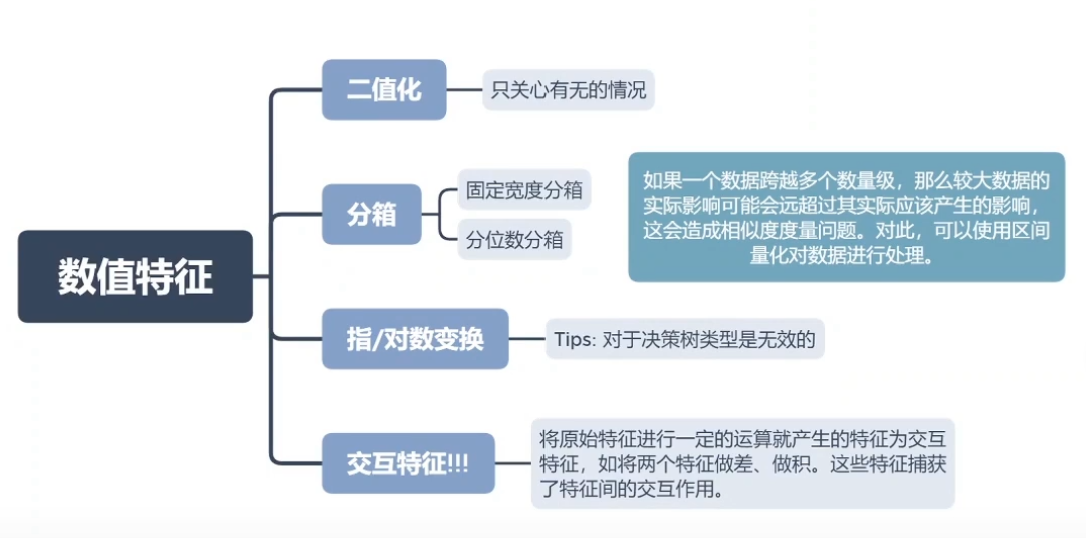
二值化,阈值threshold=n, 小于等于n的数值转为0, 大于n的数值转为1
指/对数变换对决策树没有意义,因为进行对数变化后数据的相对大小不变,小的还是小,大的还是大
交互特征是灵活性最高的,好的交互特征往往可以对模型起到很大的优化(比如020的)
index_ture = (offline_train['Date']-offline_train['Date_received']).apply(lambda x: x.days 15)
index_false_1 = (offline_train['Date']-offline_train['Date_received']).apply(lambda x: x.days > 15)
index_false_2 = offline_train['Date_received'].notnull() & offline_train['Date'].isnull()
3.1数据分桶

; 4.时间特征
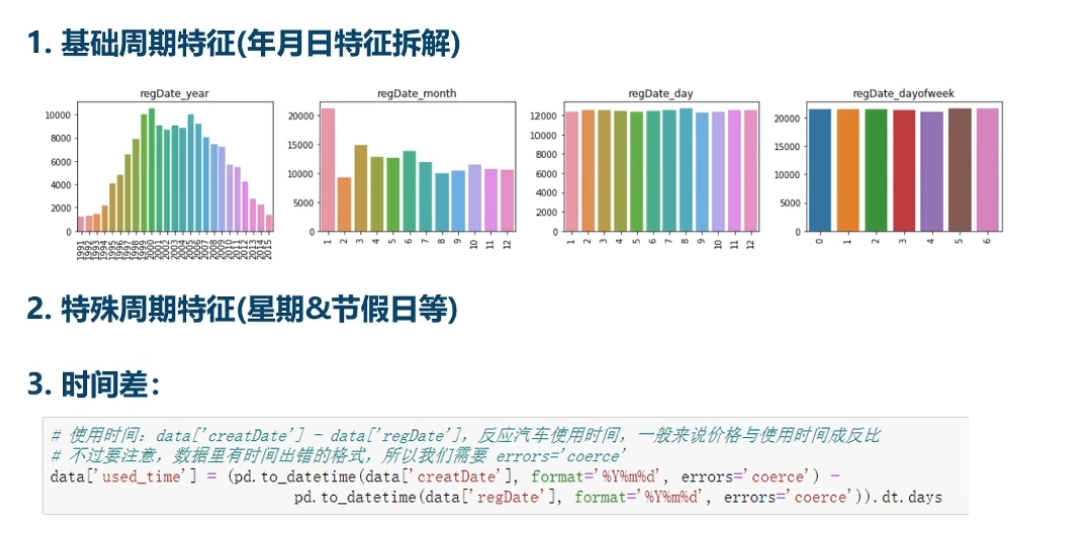
模型融合
比赛中常用的模型(基于决策树的集成学习)
1.介绍XGBoost模型
XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度。

XGBoost相对于GBDT(梯度提升树)有以下好处

; 2.参数设置

过拟合的时候加大r(gamma)的值



XGBoost的调用
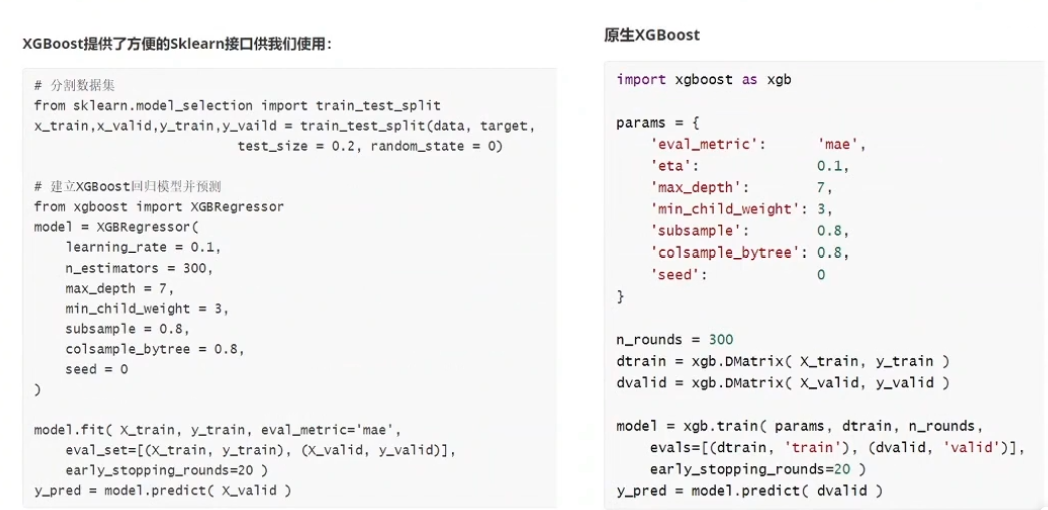
; 2.1参数优化


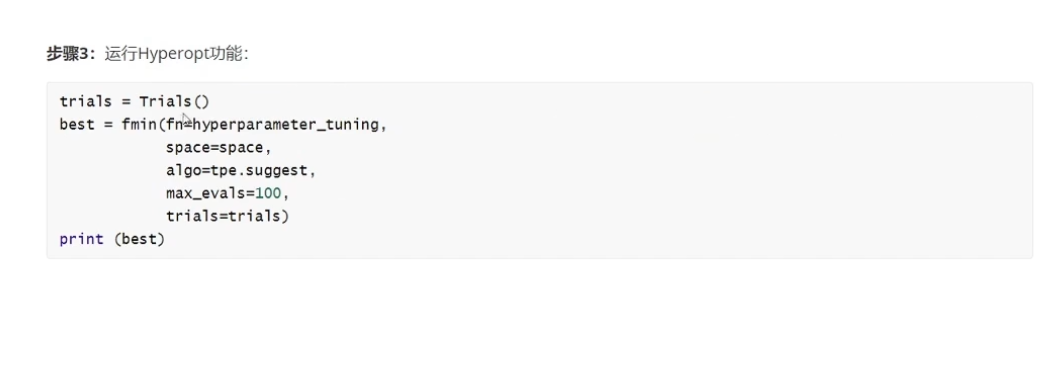
比较费时间,一般只在后期进行一次,把参数固定下来
3.LightGBM介绍




硬投票,软投票

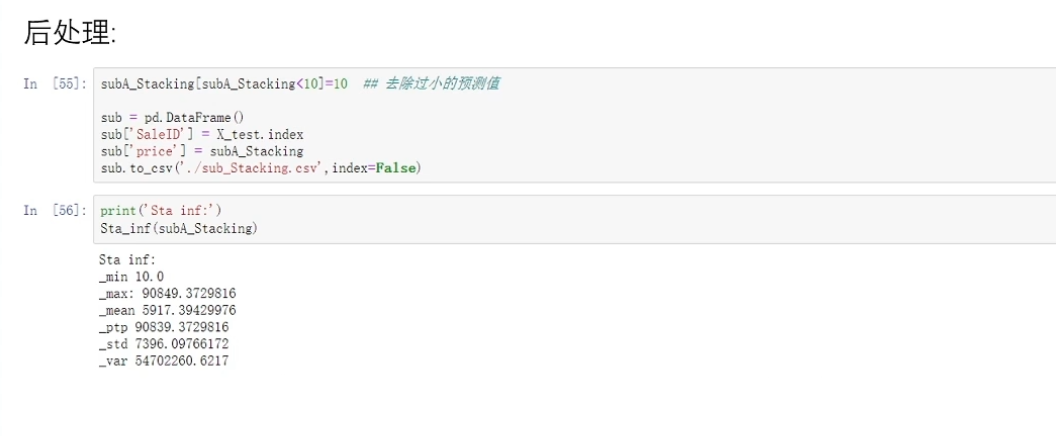
用第一层的训练结果作为特征,放到第二层(模型四)进行训练,
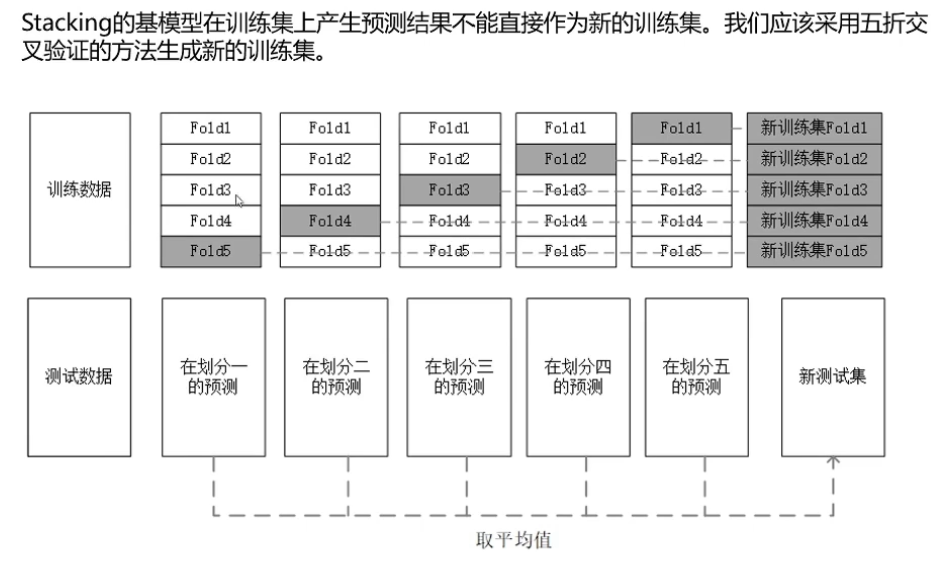
样本有偏的时候,比如负样本:正样本=10:1
那么,模型可能会更偏向于预测为负样本,这时候就要调节阈值,比如0.5改成0.3
Original: https://blog.csdn.net/m0_52118763/article/details/123743947
Author: 开始King
Title: 机器学习建模流程
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/638642/
转载文章受原作者版权保护。转载请注明原作者出处!