

如有错误,恳请指出。
文章目录
Hyperparameter evolution超参数演化是一种使用遗传算法(GA)进行优化的超参数优化方法。ML 中的超参数控制训练的各个方面,为它们找到最佳值可能是一个挑战。由于 1) 高维搜索空间 2) 维度之间的未知相关性,以及 3) 评估每个点的适应度的昂贵性质,网格搜索等传统方法很快就会变得难以处理,这使得 GA 成为超参数搜索的合适候选者。
以上是官方文档的介绍:Hyperparameter Evolution,其实简单的来说,就是使用遗传算法来对超参数已经交叉变异以获得更好的结果,而不需要传统的网格搜索。这个想法其实在之前yolov3-spp中也介绍过,对于anchor聚类结果使用遗传算法来获取更好的anchor设置,笔记见:使用kmeans与遗传算法聚类anchor
至此,在整个yolov5项目中,其实对遗传算法使用了在两个地方中,一个是对anchor进行变异优化;另外一个就是这篇笔记所介绍的,对超参数进行变异优化。
- 遗传算法介绍
具体介绍可以参考:遗传算法详解 附python代码实现,这里稍微提取一些概念。
- 简要
遗传算法是用于解决最优化问题的一种 搜索算法。从名字来看,遗传算法借用了生物学里达尔文的进化理论:”适者生存,不适者淘汰”,将该理论以算法的形式表现出来就是遗传算法的过程。 - 种群和个体的概念
遗传算法启发自进化理论,而我们知道进化是由种群为单位的,种群是什么呢?维基百科上解释为:在生物学上,是在一定空间范围内同时生活着的同种生物的全部个体。显然要想理解种群的概念,又先得理解个体的概念,在遗传算法里, 个体通常为某个问题的一个解,并且该解在计算机中被编码为一个向量表示。求最大值问题的一个可能解,也就是遗传算法里的个体,把这样的一组一组的可能解的集合就叫做 种群。 - 编码、解码与染色体的概念
在上面个体概念里提到个体(也就是一组可能解)在计算机程序中被 编码为一个向量表示,而在我们这个问题中,个体是x , y的取值,是两个实数,所以问题就可以转化为如何将实数编码为一个向量表示。
只要我们能够 将不同的实数表示成不同的0,1二进制串表示就完成了编码,也就是说其实我们并不需要去了解一个实数对应的二进制具体是多少,我们只需要保证有一个映射能够将十进制的数编码为二进制即可,至于这个映射是什么,其实可以不必关心。 将个体(可能解)编码后的二进制串叫做染色体,染色体(或者有人叫DNA)就是个体(可能解)的二进制编码表示。
而在最后我们肯定要将编码后的二进制串转换为我们理解的十进制串,也就是将二进制转化为十进制,这个过程叫做 解码。 - 适应度和选择
已经得到了一个种群,现在要根据适者生存规则把优秀的个体保存下来,同时淘汰掉那些不适应环境的个体。现在摆在我们面前的问题是如何评价一个个体对环境的适应度?在我们的求最大值的问题中可以直接用可能解(个体)对应的函数的函数值的大小来评估,这样可能解对应的函数值越大越有可能被保留下来。
不同问题的适应度设置不同。遗传算法依据原则:适应度越高,被选择的机会越高,而适应度低的,被选择的机会就低。 - 交叉、变异
通过选择我们得到了当前看来”还不错的基因”,但是这并不是最好的基因,我们需要通过繁殖后代(包含有交叉+变异过程)来产生比当前更好的基因,但是繁殖后代并不能保证每个后代个体的基因都比上一代优秀,这时需要继续通过选择过程来让试应环境的个体保留下来,从而完成进化,不断迭代上面这个过程种群中的个体就会一步一步地进化。
具体地繁殖后代过程包括交叉和变异两步。交叉是指每一个个体是由父亲和母亲两个个体繁殖产生, 子代个体的DNA(二进制串)获得了一半父亲的DNA,一半母亲的DNA,但是这里的一半并不是真正的一半,这个位置叫做 交配点,是随机产生的,可以是染色体的任意位置。通过交叉子代获得了一半来自父亲一半来自母亲的DNA,但是子代自身可能发生 变异,使得其DNA即不来自父亲,也不来自母亲,在某个位置上发生随机改变,通常就是改变DNA的一个二进制位(0变到1,或者1变到0)。
*需要说明的是交叉和变异不是必然发生,而是有一定概率发生。
参考代码:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
DNA_SIZE = 24
POP_SIZE = 200
CROSSOVER_RATE = 0.8
MUTATION_RATE = 0.005
N_GENERATIONS = 50
X_BOUND = [-3, 3]
Y_BOUND = [-3, 3]
def F(x, y):
return 3*(1-x)**2*np.exp(-(x**2)-(y+1)**2)- 10*(x/5 - x**3 - y**5)*np.exp(-x**2-y**2)- 1/3**np.exp(-(x+1)**2 - y**2)
def plot_3d(ax):
X = np.linspace(*X_BOUND, 100)
Y = np.linspace(*Y_BOUND, 100)
X,Y = np.meshgrid(X, Y)
Z = F(X, Y)
ax.plot_surface(X,Y,Z,rstride=1,cstride=1,cmap=cm.coolwarm)
ax.set_zlim(-10,10)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.pause(3)
plt.show()
def translateDNA(pop):
x_pop = pop[:,1::2]
y_pop = pop[:,::2]
x = x_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(X_BOUND[1]-X_BOUND[0])+X_BOUND[0]
y = y_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(Y_BOUND[1]-Y_BOUND[0])+Y_BOUND[0]
return x,y
def crossover_and_mutation(pop, CROSSOVER_RATE = 0.8):
new_pop = []
for father in pop:
child = father
if np.random.rand() < CROSSOVER_RATE:
mother = pop[np.random.randint(POP_SIZE)]
cross_points = np.random.randint(low=0, high=DNA_SIZE*2)
child[cross_points:] = mother[cross_points:]
mutation(child)
new_pop.append(child)
return new_pop
def mutation(child, MUTATION_RATE=0.003):
if np.random.rand() < MUTATION_RATE:
mutate_point = np.random.randint(0, DNA_SIZE*2)
child[mutate_point] = child[mutate_point]^1
def get_fitness(pop):
x,y = translateDNA(pop)
pred = F(x, y)
return (pred - np.min(pred)) + 1e-3
def select(pop, fitness):
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,
p=(fitness)/(fitness.sum()) )
return pop[idx]
def print_info(pop):
fitness = get_fitness(pop)
max_fitness_index = np.argmax(fitness)
print("max_fitness:", fitness[max_fitness_index])
x,y = translateDNA(pop)
print("最优的基因型:", pop[max_fitness_index])
print("(x, y):", (x[max_fitness_index], y[max_fitness_index]))
if __name__ == "__main__":
fig = plt.figure()
ax = Axes3D(fig)
plt.ion()
plot_3d(ax)
pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE*2))
for _ in range(N_GENERATIONS):
x,y = translateDNA(pop)
if 'sca' in locals():
sca.remove()
sca = ax.scatter(x, y, F(x,y), c='black', marker='o');plt.show();plt.pause(0.1)
pop = np.array(crossover_and_mutation(pop, CROSSOVER_RATE))
fitness = get_fitness(pop)
pop = select(pop, fitness)
print_info(pop)
plt.ioff()
plot_3d(ax)
以上为完整的代码, 解码、适应度与选择、交叉变异这些步骤是遗传算法的核心模块,将这些模块在主函数中迭代起来,让种群去进化,核心的迭代代码如下所示:
pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE*2))
for _ in range(N_GENERATIONS):
crossover_and_mutation(pop, CROSSOVER_RATE)
fitness = get_fitness(pop)
pop = select(pop, fitness)
- 遗传算法进化超参数
yolov5中包含差不多30个超参数来对训练过程进行设置,如此多的超参数如果使用网格搜索来获得最佳结果是比较困难的,所以这里作者使用了遗传算法来求出一个局部最优解——获得较好的超参数结果。
2.1 实现思路
这里一般用对COCO训练的默认超参数作为初始(演化前)的超参数: hyp.scratch.yaml,其内容如下所示:
lr0: 0.01
lrf: 0.1
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 0.05
cls: 0.5
cls_pw: 1.0
obj: 1.0
obj_pw: 1.0
iou_t: 0.20
anchor_t: 4.0
fl_gamma: 0.0
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
可以看见,这一系列的超参数是控制训练过程中的一些参数设置,所以可以将其看成是一个自变量 x。对这些超参数x进行训练会得到一个结果 y,这个 y返回了7个结果,分别是: 'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss', 'val/obj_loss', 'val/cls_loss'
对于这个输入x需要判断其效果,也就是需要定义一个适应度fitness,这里定义的fitness是精确度R,召回率R,以及mAP_0.5与mAP_0.5:0.95的分数加权和,与Loss部分无关(当然可以自行改动这个fitness的定义),如下所示:
def fitness(x):
w = [0.0, 0.0, 0.1, 0.9]
return (x[:, :4] * w).sum(1)
那么如果进行变异后的x,所返回的结果y,计算得到其适应度是比当前要高的,那么就说明当前的变异是对效果是提升的,变异后的参数是可取的。这里会默认会变异300次,然后每一次变异选择当前之前变异效果最好的前n个超参数x’来作为下一次的变异结果。
这里yolov5提供了两个不同进化方式获得base hyp
- single方式: 根据每个hyp的权重随机选择一个之前的hyp作为base hyp
- weighted方式: 根据每个hyp的权重对之前所有的hyp进行融合获得一个base hyp
根据前n次效果最好的超参数x来进行变异处理,获得下一个待输入的x’,依次反复迭代300次,变异300回来获得效果最好的x。
2.2 实现代码
yolov5实现代码参考如下:
def main(opt, callbacks=Callbacks()):
...
if opt.resume and not check_wandb_resume(opt) and not opt.evolve:
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run()
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
opt = argparse.Namespace(**yaml.safe_load(f))
opt.cfg, opt.weights, opt.resume = '', ckpt, True
LOGGER.info(f'Resuming training from {ckpt}')
else:
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project)
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
if opt.evolve:
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
...
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ')
dist.destroy_process_group()
else:
meta = {'lr0': (1, 1e-5, 1e-1),
'lrf': (1, 0.01, 1.0),
'momentum': (0.3, 0.6, 0.98),
'weight_decay': (1, 0.0, 0.001),
'warmup_epochs': (1, 0.0, 5.0),
'warmup_momentum': (1, 0.0, 0.95),
'warmup_bias_lr': (1, 0.0, 0.2),
'box': (1, 0.02, 0.2),
'cls': (1, 0.2, 4.0),
'cls_pw': (1, 0.5, 2.0),
'obj': (1, 0.2, 4.0),
'obj_pw': (1, 0.5, 2.0),
'iou_t': (0, 0.1, 0.7),
'anchor_t': (1, 2.0, 8.0),
'anchors': (2, 2.0, 10.0),
'fl_gamma': (0, 0.0, 2.0),
'hsv_h': (1, 0.0, 0.1),
'hsv_s': (1, 0.0, 0.9),
'hsv_v': (1, 0.0, 0.9),
'degrees': (1, 0.0, 45.0),
'translate': (1, 0.0, 0.9),
'scale': (1, 0.0, 0.9),
'shear': (1, 0.0, 10.0),
'perspective': (0, 0.0, 0.001),
'flipud': (1, 0.0, 1.0),
'fliplr': (0, 0.0, 1.0),
'mosaic': (1, 0.0, 1.0),
'mixup': (1, 0.0, 1.0),
'copy_paste': (1, 0.0, 1.0)}
with open(opt.hyp, errors='ignore') as f:
hyp = yaml.safe_load(f)
if 'anchors' not in hyp:
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir)
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}')
for _ in range(opt.evolve):
if evolve_csv.exists():
parent = 'single'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
n = min(5, len(x))
x = x[np.argsort(-fitness(x))][:n]
w = fitness(x) - fitness(x).min() + 1E-6
if parent == 'single' or len(x) == 1:
x = x[random.choices(range(n), weights=w)[0]]
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum()
mp, s = 0.8, 0.2
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()])
ng = len(meta)
v = np.ones(ng)
while all(v == 1):
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()):
hyp[k] = float(x[i + 7] * v[i])
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1])
hyp[k] = min(hyp[k], v[2])
hyp[k] = round(hyp[k], 5)
results = train(hyp.copy(), opt, device, callbacks)
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
plot_evolve(evolve_csv)
print(f'Hyperparameter evolution finished\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
def fitness(x):
w = [0.0, 0.0, 0.1, 0.9]
return (x[:, :4] * w).sum(1)
def print_mutation(results, hyp, save_dir, bucket):
evolve_csv, results_csv, evolve_yaml = save_dir / 'evolve.csv', save_dir / 'results.csv', save_dir / 'hyp_evolve.yaml'
keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys())
keys = tuple(x.strip() for x in keys)
vals = results + tuple(hyp.values())
n = len(keys)
if bucket:
url = f'gs://{bucket}/evolve.csv'
if gsutil_getsize(url) > (os.path.getsize(evolve_csv) if os.path.exists(evolve_csv) else 0):
os.system(f'gsutil cp {url}{save_dir}')
s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n')
with open(evolve_csv, 'a') as f:
f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
print(colorstr('evolve: ') + ', '.join(f'{x.strip():>20s}' for x in keys))
print(colorstr('evolve: ') + ', '.join(f'{x:20.5g}' for x in vals), end='\n\n\n')
with open(evolve_yaml, 'w') as f:
data = pd.read_csv(evolve_csv)
data = data.rename(columns=lambda x: x.strip())
i = np.argmax(fitness(data.values[:, :7]))
f.write('# YOLOv5 Hyperparameter Evolution Results\n' +
f'# Best generation: {i}\n' +
f'# Last generation: {len(data)}\n' +
'# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) + '\n' +
'# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
yaml.safe_dump(hyp, f, sort_keys=False)
if bucket:
os.system(f'gsutil cp {evolve_csv}{evolve_yaml} gs://{bucket}')
具体过程见注释。
- Hyperparameter Evolution使用
具体介绍见:Hyperparameter Evolution
使用方式其实很简单,就是设置一些evolve参数即可
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
或者我对args进行了改动,使得可以设定迭代演化次数:
parser.add_argument('--evolve', type=int, default=300, help='evolve hyperparameters for x generations')
...
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve 10
Hyperparameter Evolution主要的遗传算子是 交叉和变异。在这项工作中,使用突变,以 80% 的概率和 0.04 的方差基于所有前几代最好的父母的组合来创造新的后代。这里结果被记录到 runs/evolve/exp/evolve.csv中,最高适应度的后代被保存为每一代 runs/evolve/hyp_evolved.yaml
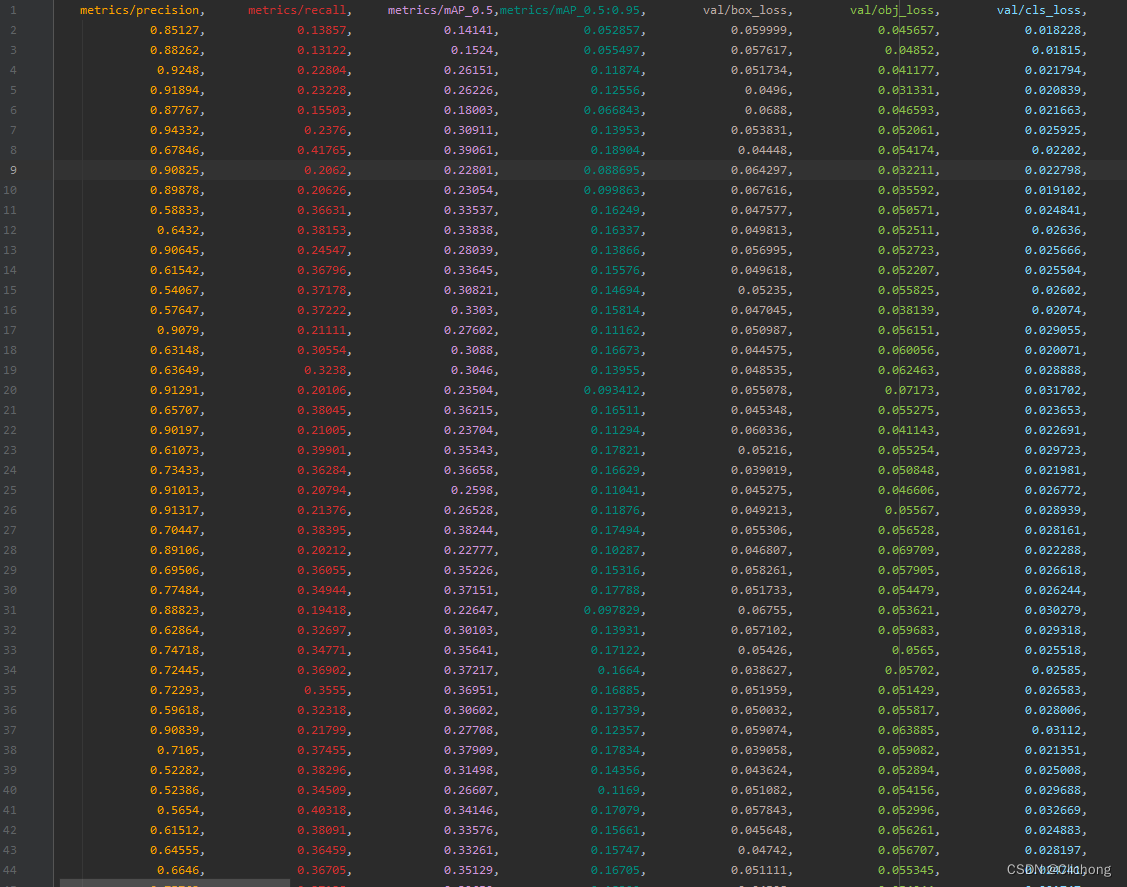
- *evolve.csv展示:

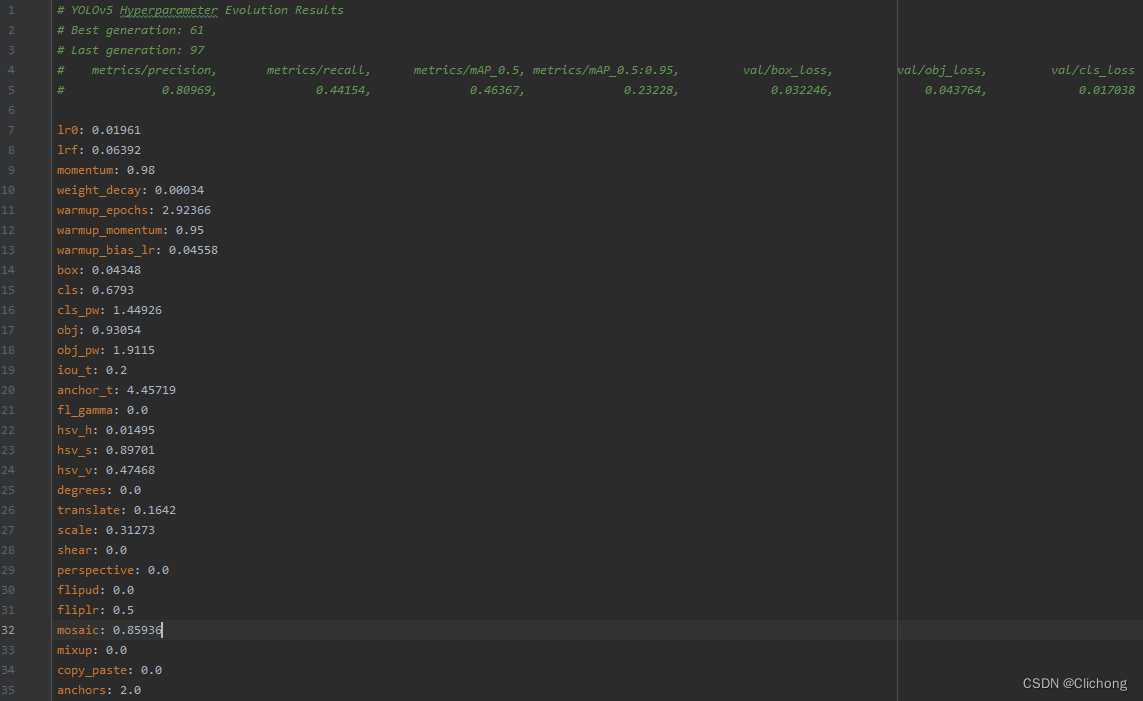
- *hyp_evolved.yaml展示:
参考资料:
2. 目标检测的Tricks | 【Trick13】使用kmeans与遗传算法聚类anchor
Original: https://blog.csdn.net/weixin_44751294/article/details/125163790
Author: Clichong
Title: YOLOv5的Tricks | 【Trick5】遗传算法实现超参数进化(Hyperparameter Evolution)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/638550/
转载文章受原作者版权保护。转载请注明原作者出处!