

目录
一、线性回归
1、父亲-孩子x-y线性回归方程

2)、之后在数据分析中选择回归,并勾选一下选项
3)、结果
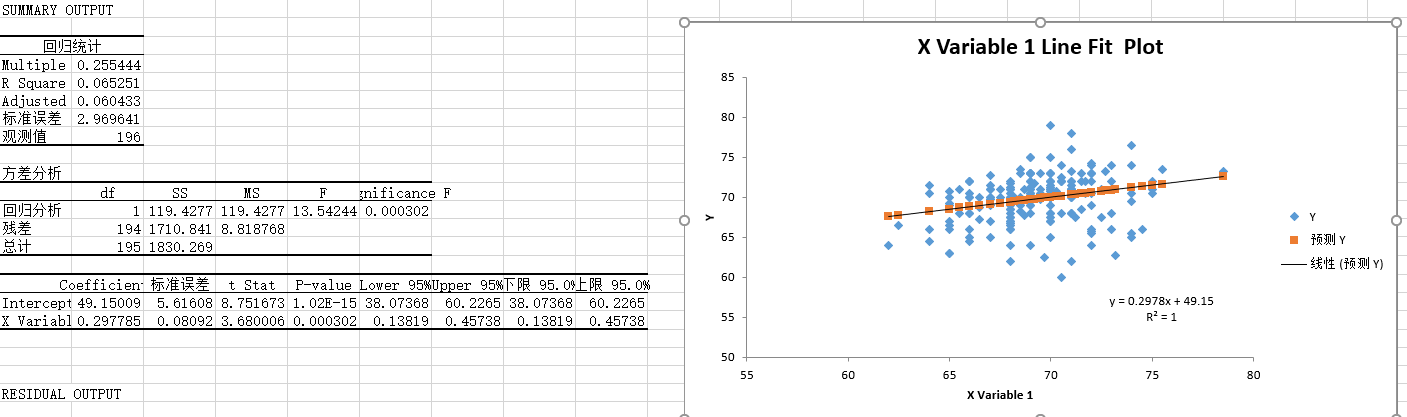
方程为y=0.2978x+49.15。其中决定系数为1,说明有极高的相关性。
如果父亲身高75,孩子身高为71.485英寸
同理,母亲的回归方程:
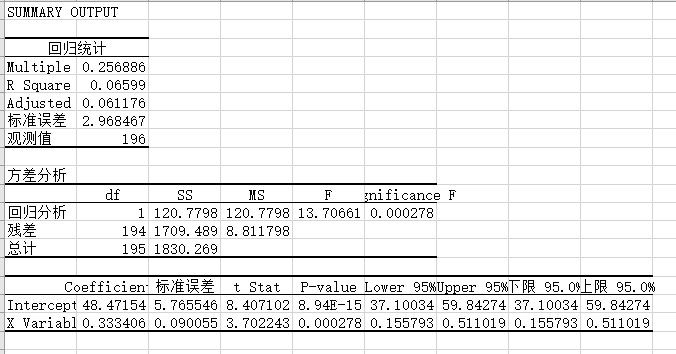
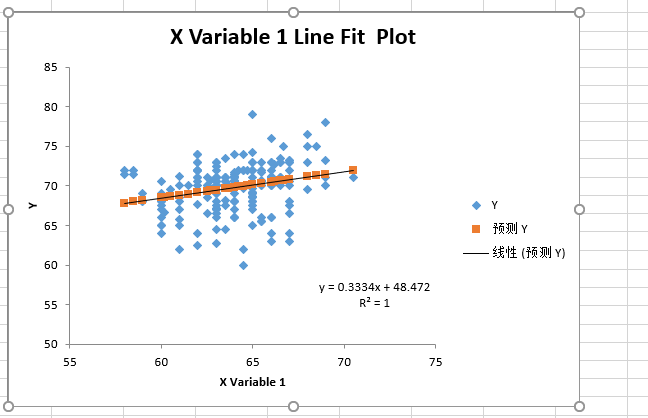
方程为y=0.3334x+48.472。其中决定系数为1,说明有极高的相关性。
由此可知,”父亲高则儿子高,父亲矮则儿子矮”(即父亲与儿子身高相关,且为正相关)、”母高高一窝,父高高一个”(即母亲的身高比父亲的身高对子女的影响更大)的习俗传说是有相关依据的。
; 二、线性回归方法的有效性判别
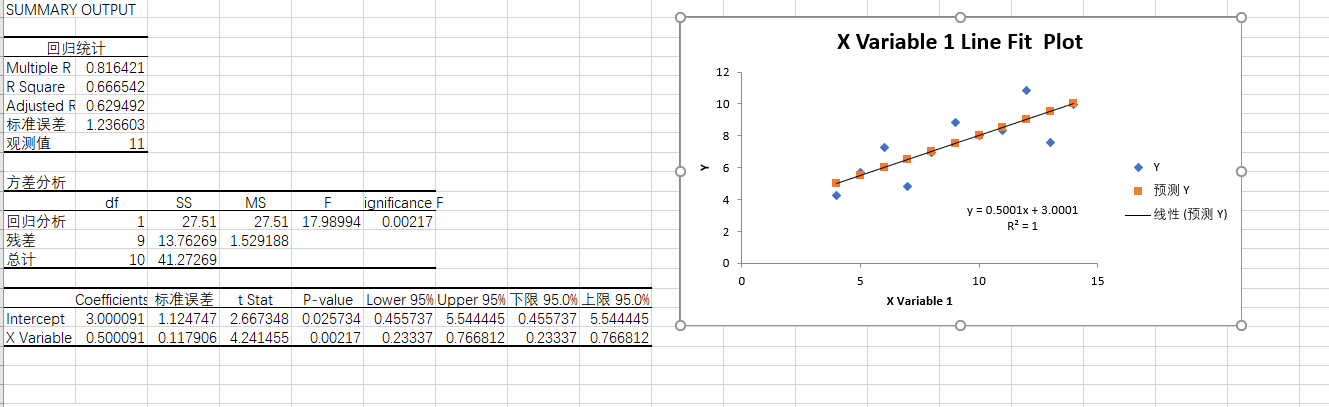
表1
从图中可以看出线性并不是很能够表现原始数据的一个变化趋势,所有该线性回归方程不成立。
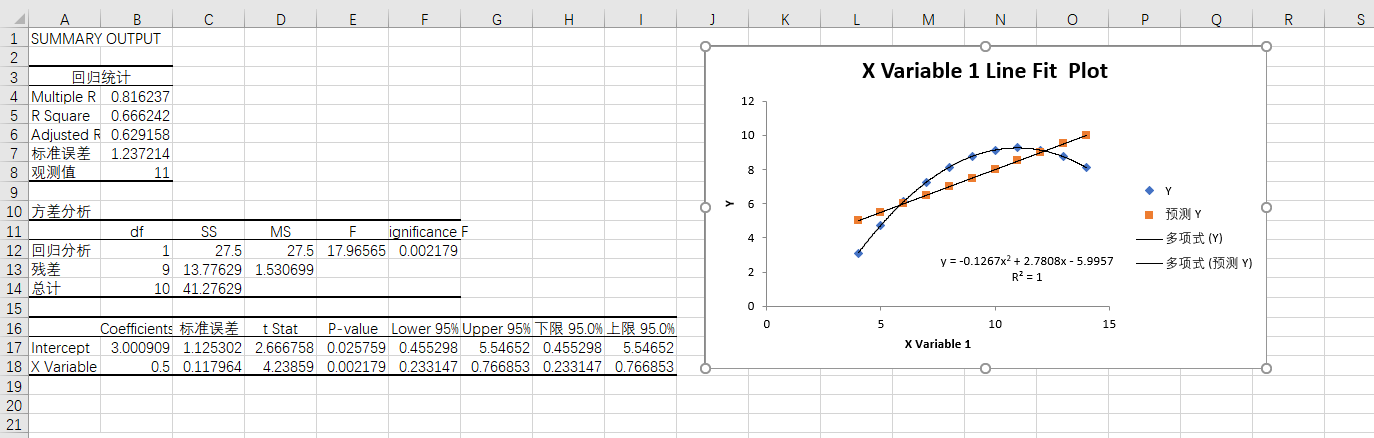
表2
从图中可以看出线性并不是很能够表现原始数据的一个变化趋势,所有该线性回归方程不成立。通过采用其他的回归曲线来测试,发现对于2次的多项式的回归方程来说,会比线性回归方程更好表现数据的变化趋势。

表3
该线性回归方程基本能够体现该数据集的一个变化情况。
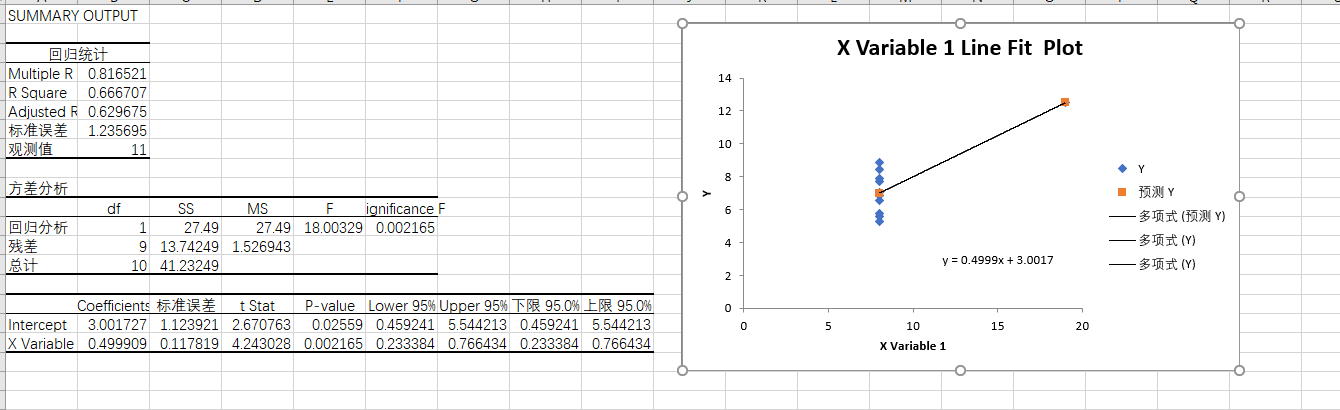
表4
该线性回归方程不成立。
三、python和Anaconda的安装
参考这个视频
如图创建虚拟环境之后等待即可。
; 四、鸢尾花数据集使用SVM线性分类
导入需要使用的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
得到数据
iris=datasets.load_iris()
X=iris.data
Y=iris.target
处理数据
X=X[:,:2]
Y1=Y[Y<2]
y1=len(Y1)
Y2=Y[Y<1]
y2=len(Y2)
X=X[:y1,:2]
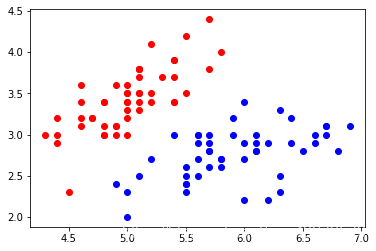
原始数据绘图
plt.scatter(X[0:y2,0],X[0:y2,1],color='red')
plt.scatter(X[y2+1:y1,0],X[y2+1:y1,1],color='blue')
plt.show()
数据归一化
standardScaler=StandardScaler()
standardScaler.fit(X)
X_standard=standardScaler.transform(X)
svc=LinearSVC(C=1e9)
svc.fit(X_standard,Y1)
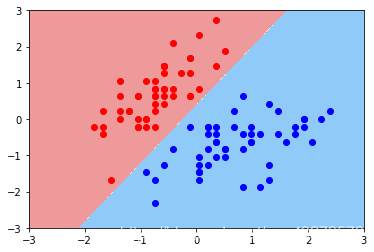
画出决策边界
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()
例化一个svc2
svc2=LinearSVC(C=0.01)
svc2.fit(X_standard,Y1)
print(svc2.coef_)
print(svc2.intercept_)
plot_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()
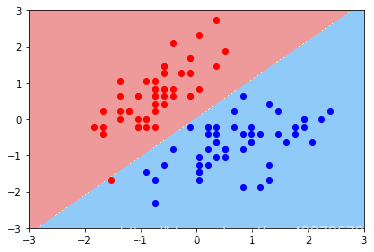
可知,C越大容错越小。
分类后的内容基础上添加上下边界
def plot_svc_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
w = model.coef_[0]
b = model.intercept_[0]
index_x = np.linspace(axis[0], axis[1], 100)
y_up = (1-w[0]*index_x - b) / w[1]
y_down = (-1-w[0]*index_x - b) / w[1]
x_index_up = index_x[(y_upaxis[3]) & (y_up>=axis[2])]
x_index_down = index_x[(y_downaxis[3]) & (y_down>=axis[2])]
y_up = y_up[(y_upaxis[3]) & (y_up>=axis[2])]
y_down = y_down[(y_downaxis[3]) & (y_down>=axis[2])]
plt.plot(x_index_up, y_up, color="black")
plt.plot(x_index_down, y_down, color="black")
plot_svc_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()
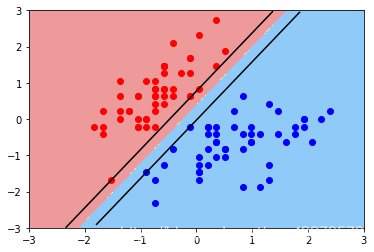
修改C值
plot_svc_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()
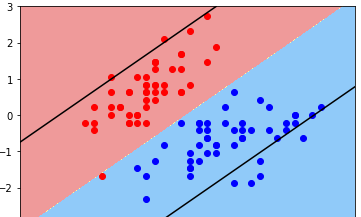
五、总结
有些回归函数不能用P值R值来说明好坏,具体情况要具体分析,常数C越大,容错空间越小,上下边界较近;常数C越小,容错空间越大,上下边界越远。
Original: https://blog.csdn.net/weixin_48547489/article/details/115027246
Author: wensea
Title: 数据的回归和分类分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635430/
转载文章受原作者版权保护。转载请注明原作者出处!