

机器学习
文章目录
- 机器学习
* - 1.2 机器学习定义
- 1.3-4 机器学习的分类
- 2.1 模型描述(线性回归模型)
- 2.2-4 代价函数
- 2.5-6 梯度下降算法
- 2.7 线性回归的梯度下降
- 3 矩阵(涉及线性代数)
- 4.1 多功能/多元线性回归
- 4.2 多元梯度下降法
- 4.3 多元梯度下降法—特征缩放
- 4.4 多元梯度下降法—学习率
- 4.5 特征和多项式回归
- 4.6 正规方程(区别于迭代方法的直接接法)
- 4.7 正规方程在矩阵不可逆情况下的解决办法(选学)
1.2 机器学习定义
一个适当的学习问题定义如下:
从 经验E_中学习解决 任务T进行 性能度量P,并通过 性能度量P判断 任务T的表现因 经验E_提高,即经验E使得任务T得到性能改善。
- 在垃圾邮件分类问题中,
经验E指 已经标记好是否为垃圾邮件的邮件;
任务T指 要求程序划分是否为垃圾邮件并过滤垃圾邮件;
性能P指 程序划分的垃圾邮件标签与正确标签对比的正确率;
1.3-4 机器学习的分类
监督学习:从打好标签的数据中学习,即”有正确答案”
无监督学习:给定一个无标签数据集,按不同标准划分成不同的类(聚类思想),即”开放题”
分类:离散值预测输出
回归:连续值预测输出
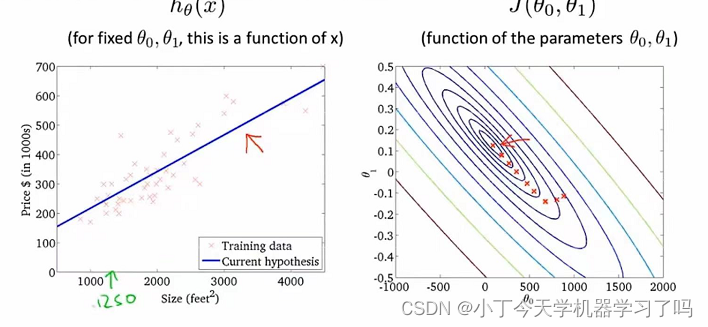
2.1 模型描述(线性回归模型)
在单变量线性回归问题中:
假设函数:输入x用于输出预测y的函数


; 2.2-4 代价函数
代价函数:平方误差和代价

为了尽可能地拟合数据,使得h(i)的值接近y(i),就要解决一个代价最小的问题,即使得
 最小。( 这里的1/2m是为了开导时刚好抵消平方 对优化结果无影响)
最小。( 这里的1/2m是为了开导时刚好抵消平方 对优化结果无影响)
如果采用简化后的假设函数


而如果是采用原本的假设函数,则代价函数分布也是呈现类似碗装,如下图

也可以使用等高线图来绘制成下图的样子:
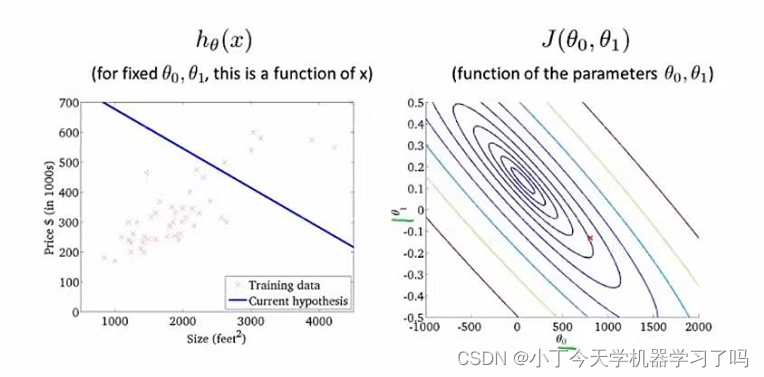
而我们要找到的 则是这个”碗”的最深位置,为使得程序找到这个位置对应的参数,引入了梯度下降算法
2.5-6 梯度下降算法
使用梯度下降算法可以用于解决最小化任意函数的问题,也可以解决面临更多参数的问题

(起始点的不同可能会有多个不同的局部最优解)

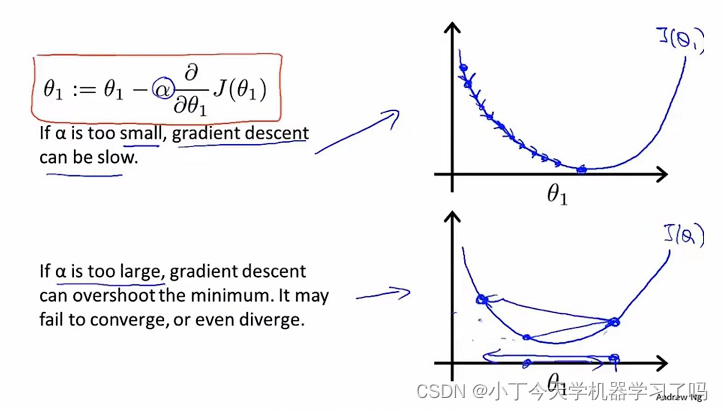
更新规则数学定义如下图:

注:
:=表示赋值
α为学习率 始终为正决定了下降的速度 以多大的速率更新这个参数θ_j
α太小,计算量大,耗时长,但是结果更精确;
α太大,计算量小,跨步大,但结果不够精确,可能跨步越过最低点和找到最低点,导致无法收敛甚至发散的局面;
如下图所示中
在参数已经处于局部最小点的位置,此时导数项为零,梯度下降法将不再更新参数
在跨过最低点的第一个点,此时斜率变大即偏导值变大导致下次更新跨步会更大,会更加远离最低点,数值越来越偏离最低点
而可以发现,越接近局部最低点时,其导数值会变得越来越小,学习率固定,则更新幅度也会也越来越小。
偏导项表示 函数沿θ_j方向的变化率
梯度下降要 实现θ_0和θ_1同步更新,必须遵守左侧顺序
右侧的算法也可以解决问题但是不属于梯度下降法
; 2.7 线性回归的梯度下降

(左侧 梯度下降法更新参数 右侧 线性回归的假设函数和平方差代价函数)
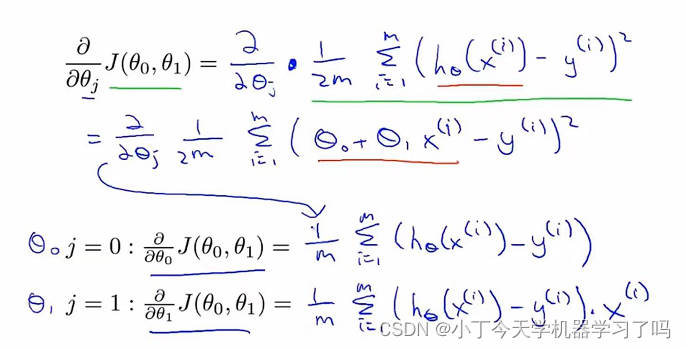
在线性回归问题中,其代价函数总是这样一个弓形函数,称为凸函数
该函数只有不存在多个局部最优解,只存在一个全局最优解
因此梯度下降法在解决线性回归问题时能很好适用总能收敛到全局最优解
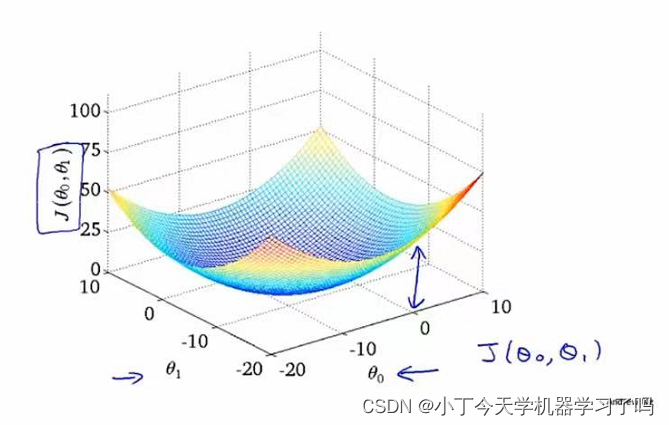
在梯度下降过程中,下降轨迹垂直于等高线
3 矩阵(涉及线性代数)
矩阵 向量 矩阵加法 乘法 单位矩阵 矩阵的逆

; 4.1 多功能/多元线性回归
利用矩阵知识 可以将多元线性回归的假设函数公式数学表示为如下:

4.2 多元梯度下降法

4.3 多元梯度下降法—特征缩放
不同特征的数值应该在一个相似范围内
在相似范围内执行梯度下降迭代次数会变少,效率会提高
可以对一些特征进行特征缩放或者归一化处理
特征值/(最大值-最小值)

均值归一化:用特征值-均值代替原本的特征值再进行归一化
使用均值归一化 是为了让进行处理后的特征值具有为0的平均值
(特征值-均值)/(最大值-最小值)
要注意 x_0不需要减均值,如果按照上述公式运算,则分母为0,无意义,则它不可能有为0的的平均值
; 4.4 多元梯度下降法—学习率
如何保证梯度下降法正常运行?
判断梯度下降算法是否收敛?
- 可绘制 横坐标为迭代次数 竖坐标为代价的图像
画出代价函数随迭代次数增加的变化曲线,进而判断是否收敛

另外也可监测迭代过程的顺利进行,及时发现异常
如下左图 代价函数随着迭代次数的增加而增加的话,通常是因为学习率α设置过大
右图所示在跨过最低点的第一个点,此时斜率变大即偏导值变大导致下次更新跨步会更大,会更加远离最低点,数值越来越偏离最低点
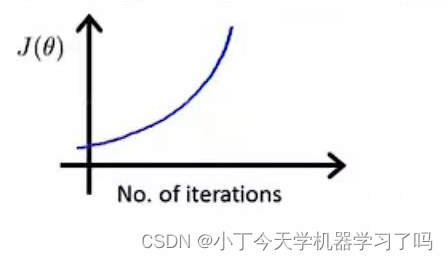
如出现反复下降又升高的情况也要使用更小的学习率α

- 可进行自动的收敛测试
若上一步迭代完的代价函数的值小于设定的一个阈值(通常很小),则判断函数已经收敛。但是一般,阈值很难选到一个合适的值
如何选择合适的学习率?
在2.5-6中可知,学习率过大或者过小都影响迭代效率
可对不同的学习率,如0.001,0.003,0.01,0.03,0.1,0.3,1…,分别绘制代价函数随迭代次数增加的变化曲线,选择一个可以使得代价函数快速下降的学习率α
4.5 特征和多项式回归
选择特征
有时候定义一个新特征能更好的解决问题
比如有长和宽,定义新特征长和宽的乘积为面积,能更好的解决预测住房价格问题
多项式回归
使用多项式函数进行多元线性回归有时可以更好的拟合数据
分别使用变量x的一次方,二次方,三次方来充当x_1,x_2,x_3,要注意进行特征缩放

; 4.6 正规方程(区别于迭代方法的直接接法)
正规方程:不同于 梯度下降法的层层迭代,一次性求得最优参数解
主要思想是代价函数分别对不同参数求偏导

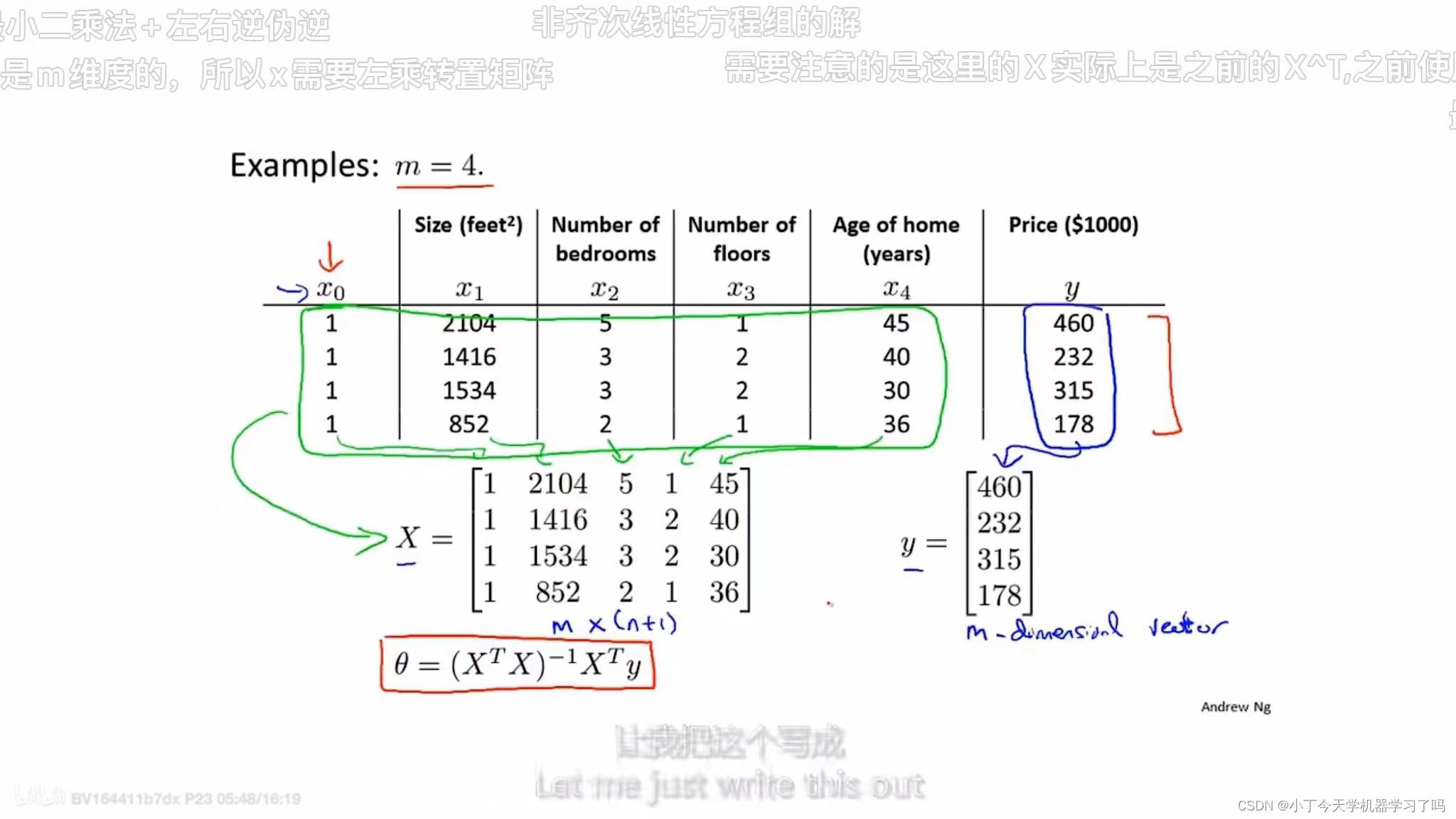

求解参数可参考西瓜书和南瓜书内容如下

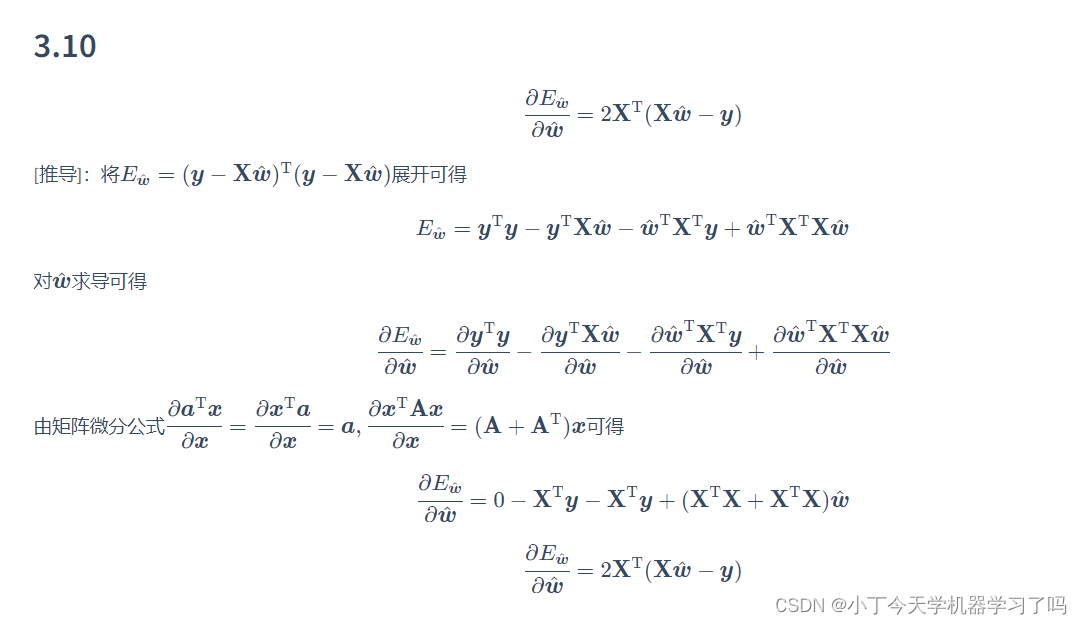

X矩阵是一个m行x(n+1)列 m为样本数 n为特征数+1
Y矩阵是一个mx1的向量
如果使用特征方程法,则不需要进行特征缩放
梯度下降法 缺点:需要进行多次选择合适的学习率,需要进行多次迭代 优点:在特征变量多的情况下可以运行的很好,通常n上万或更多时优先考虑梯度下降法
正规方程 优点:容易实现 不需要迭代或其他步骤 缺点:在特征变量多的情况下需要求解大矩阵相乘,计算量很大,实现很慢,通常n小于一万时优先考虑正规方程法
根据具体的算法和特征数目大小来选择适合的算法求参
4.7 正规方程在矩阵不可逆情况下的解决办法(选学)
不可逆矩阵又称奇异矩阵或者退化矩阵
不可逆原因:包含了多余特征,两个特征之间有线性关系,或者特征个数过多,m
———————————正在更新中—————————————
Original: https://blog.csdn.net/Ding__d/article/details/125978493
Author: 小丁今天学机器学习了吗
Title: 机器学习 1-4节 机器学习定义 模型描述 代价函数 梯度下降 多元线性回归 特征缩放法 均值归一化 判断梯度下降是否收敛 学习率 多项式回归 正规方程
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/634710/
转载文章受原作者版权保护。转载请注明原作者出处!