

文章目录
一、岭迹图
介绍
既然要选择α的范围,我们就不可避免地要进行 α最优参数的选择 。在各种机器学习教材中,都会使用岭迹图来判断正则项参数的最佳取值。传统的岭迹图长这样,形似一个开口的喇叭图(根据横坐标的正负,喇叭有可能朝右或者朝左):


这一个
以正则化参数α为横坐标, 线性模型求解的系数w为纵坐标 的图像,其中 每一条彩色的线都是一个系数w 。其目标是建立正则化参数与系数w之间的直接关系,来观察正则化参数的变化如何影响了系数w的拟合。岭迹图认为,线条交叉越多,则说明特征之间的多重共线性越高,应该选择系数较为平稳的喇叭口所对应的α取值作为最佳的正则化参数的取值。
简单使用

import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
x = 1. / (np.arange(1,11) + np.arange(0,10)[:,np.newaxis])
y = np.ones(10)
n_alphas = 200
alphas = np.logspace(-10,-2,n_alphas)
coefs = []
for a in alphas:
ridge = linear_model.Ridge(alpha=a,fit_intercept=False)
ridge.fit(x,y)
coefs.append(ridge.coef_)
ax = plt.gca()
ax.plot(alphas,coefs)
ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1])
plt.xlabel('正则化参数alpha')
plt.ylabel('系数w')
plt.title('岭回归下的岭迹图')
plt.axis('tight')
plt.show()

历史角:
- 岭回归最初始由HoerlKennard和在170提出来用来改进多重共线性问题的模型,在这篇1970年的论文中,两位作者提出了岭迹图并且向广大学者推荐这种方法,然而遭到了许多人的批评和反抗。大家接受了岭回归,却鲜少接受岭迹图,这使得岭回归被发明了50年之后,市面上关于岭迹图的教材依然只有1970年的论文中写的那几句话(线条交叉越多,则说明特征之间的多重共线性越高)。
- *1974年, Stone发表论文,表示应当在统计学和机器学习中使用交叉验证。1980年代,机器学习技术迎来第一次全面爆发(1979年D3决策树被发明出来,1980年之后CART树,adaboost,带软间隔的支持向量,梯度提升树逐渐诞生),从那之后,除了统计学家们,几乎没有人再使用岭迹图了。在2000年以后,岭迹图只是教学中会被略微提到的一个知识点(还会被强调是过时的技术)。在现实中,真正应用来选择正则化系数的技术是交叉验证,并且选择的标准非常明确:
我们选择让交叉验证下的均方误差最小的正则化系数a。
二、交叉验证岭回归 —- klearn.linear_model.RidgeCV
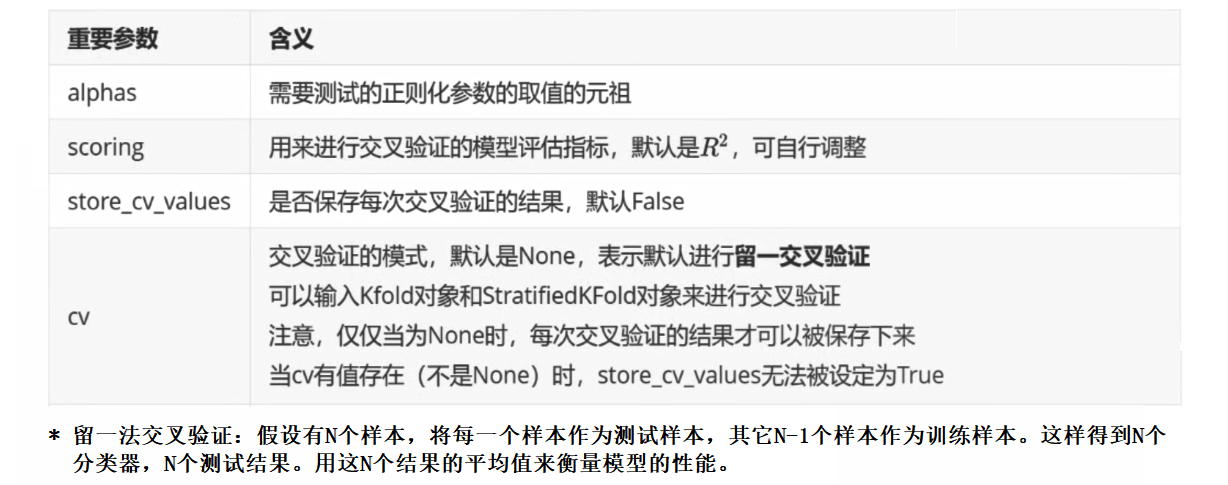
class sklearn.linear_model.RidgeCV(alphas=0.1, 1.0, 10.0, *, fit_intercept=True, normalize=False,
scoring=None, cv=None, gcv_mode=None, store_cv_values=False,
alpha_per_target=False)[source]

加利福尼亚房屋价值测试
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge,RidgeCV
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.datasets import fetch_california_housing as fch
house_value = fch()
x = pd.DataFrame(house_value.data)
y = house_value.target
x.columns = ["住户收入中位数","房屋使用年代中位数","平均房间数目","平均卧室数目","街区人口","平均入住率","街区的纬度","街区的经度"]
Ridge_ = RidgeCV(alphas=np.arange(1,1001,100),
store_cv_values=True,
).fit(x,y)
score = Ridge_.score(x,y)
cv_score = Ridge_.cv_values_
cv_score_mean = Ridge_.cv_values_.mean(axis=0)
best_alpha = Ridge_.alpha_
无论怎样更改交叉验证岭回归的参数,对于最终的最佳正则化系数都是没有影响的。
Original: https://blog.csdn.net/qq_45797116/article/details/112546868
Author: 骑着蜗牛ひ追导弹’
Title: 【skLearn 回归模型】岭回归 —- 选择最佳正则化参数 <带交叉验证的岭回归RidgeCV()>
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/634694/
转载文章受原作者版权保护。转载请注明原作者出处!