

珠海某上市公司算法总监:
1、相机标定的原理与坐标系之间的转换,如何转换
2、激光三角原理,如何搭建
3、测量拟合的过程中有哪些算子,原理什么,接着问5,跌代多少次?什么情况最优,如何优化,
4、那个测量算子的优缺点?
5、如何最优的拟合圆
6、如何最优的拟合直线
7、除了标定halcon的标定方法还有哪些标定方法,分别是什么
8、相机坐标系之间是如何转换的:
宁德新能源 二面(研发部门总监)
(选型) 1、做过那些方案?项目中你那个是全权完成的,碰到的什么问题?
2、对硬件了解多少?伺服电机选型如何选,光源如何选型?镜头如何选?对打光了解吗?(完全蒙蔽)
3、机械设计有多少了解,多少要了解一些
(语言,问的少,但是问的很深) 1、c#和c++的区别是什么
2、什么是锁,有那几种锁,如何解锁,锁和内存对应起来如何?
3、多肽是什么?举例说明
4、多线程之间的交互方式有几种,如何交互,各自的优缺点是什么
5、文件读写
(算法) 1、手眼标定手推一下,(我推完后),具体流程说一下,先后顺序能不能乱?为什么
2、简述base object tool camera的两量关系,如果建立起来联系
3、简述决策树,
4、一幅图像中halcon 是如何存贮的,在opencv 中是如何存贮的?为什么要这样存?
5、什么是最大似然估计
6、什么是图像的矩,手推一下?
7、好像最近几个问题感觉你没有信心了?(我回答:不是,是在绝对的力量面前,嘶吼没有任何意义,这次面试交流是对我自己的一个清晰定位,以后会怎么做更有方向)
8、三次内插法数学原理,简单实现
9、halcon 模板匹配的原理,特征检测的关键是什么,什么是特征检测?
10、什么是滞后阈值处理,为什么这么做,用在那个方面
11、什么是极大值抑制,如何做极大值抑制,为什么要这么做?
12、c#中有没有结构体
结构是值类型,它在栈中分配空间;而类是引用类型,它在堆中分配空间,栈中保存的只是引用。


结构和类的适用场合分析:
1、当堆栈的空间很有限,且有大量的逻辑对象时,创建类要比创建结构好一些;
2、对于点、矩形和颜色这样的轻量对象,假如要声明一个含有许多个颜色对象的数组,则CLR需要为每个对象分配内存,在这种情况下,使用结构的成本较低;
3、在表现抽象和多级别的对象层次时,类是最好的选择,因为结构不支持继承。
4、大多数情况下,目标类型只是含有一些数据,或者以数据为主。
13、c#的面向对象的特性
1.封装
每个对象都包含它进行操作所需要的所有信息,封装只公开代码单元的对外接口,而隐藏其具体实现,尽量不对外公开代码。使用封装有很多好处,从设计角度来讲,封装可以对外屏蔽一些重要的信息,比如使用电脑的人只要知道怎么使用电脑就可以,不用知道这些功能具体是怎么实现的;从安全性考虑,封装使对代码的修改更加安全和容易,封装明确的指出了哪些属性和方法是外部可以访问的,这样当需要调整这个类的代码时,只要保证公有属性不变,公有方法的参数和返回值类型不变,那么就可以尽情的修改这个类,而不会影响到程序的其他部分;封装还避免了命名冲突的问题,封装有隔离作用,不同的类中可以有相同名称的方法和属性,但不会混淆,也可以减少耦合。
2.继承
继承可以使用现有类的所有功能,并在无须重新编写原来的类的情况下,对这些功能进行扩展。使用继承而产生的类被称为派生类或子类,而被继承的类则称为基类或超类或父类。继承表示一个类型派生于一个基类型,它拥有该基类型的所有成员字段和函数,其子类是对父类的扩展;接口继承是表示一个类型只继承了函数的签名,没有继承任何实现代码。继承划分了类的层次性,也可以说继承是对类的分组,父类代表的是抽象的类,更常用的类,而子类代表的是更为具体,更为细化的类;继承是实现代码重用、扩展的重要手段。所谓抽象的类是指与具体的事项相联系,但只是表达整体而不是具体概念的类,比如说形状包含正方形、长方形、圆等,这时候形状是一个抽象的概念,相当于一个父类,而正方形、长方形、圆是具体的形状,相当于是子类。
3.多态
多态是指程序中同名的不同方法共存的情况,主要通过子类对父类方法的覆盖来实现多态。这样,不同类的对象可以用同名的方法完成特定的功能,但具体的实现方法却可以不同。比如说形状包含正方形、长方形、圆等,每个形状都有面积和周长,但是不同的形状计算面积和周长的方法都不同
14、c++ 和c# 的区别和联系
不同点:
1、c++中使用指针是非常重要的,c#中是没有的
2、继承问题,c++中可以多继承,但是c#中是不能多继承的,会造成歧义,通常用接口来代替多继承
3、性能方面:C++普遍来说更快,c#相对来说就不那么好优化
4、内存回收:C++要求用户手动处理内存,但是C#运行在虚拟机中,而虚拟机会自动处理内存。
5、C#是微软研发的基于C特点的一门类似于Java的编程语言。其中C#有很多C语言的影子。C#是一门专注于windows平台开发应用程序的语言,而C/C++是兼容windows和Linux平台
6、C++可以创建独立(stand-alone)和控制台(console)程序。C#可以创建控制台,Windows,ASP.NET和移动(mobile)程序,但不能创建独立程序
15、c#可以不可多继承,如何多继承?
答案一:用接口啊,一个类可以继承自多个接口的。
答案二:C#不支持多继承,C++才支持多继承,多继承会让代码变得很乱,因此微软在设计C#的时候放弃了多继承。
碧桂园旗下-机器人公司二面:
1、介绍项目
2、模板匹配有几种?
3、模板匹配除了灰度相关性的匹配外还有那种,如何来手写一个模板匹配?
4、opencv 如何实现一维测量和二维测量
5、3D模板匹配
这家一面的问的算法的东西很多,面了大概1个小时,二面的话问的不多,在项目上问的比较细,也比较多。目前手里有两个offer,心里就不慌了。
下面10道题是这位大神的总结的,其他的都是最近面试的时候问道的题目类型,记录以做补充图像处理-最常见面试题(必问)_聪哥965-CSDN博客_图像处理面试题
1.图像预处理有哪些方法?
1 平均滤波
2 中值滤波
3 高斯滤波
4 高斯金字塔
5 拉普拉斯滤波
6 直方图均衡化
1.1 高斯滤波器原理介绍?
Opencv 笔记3 图像平滑_Σίσυφος1900的博客-CSDN博客
高斯滤波对于抑制服从正态分布的噪声效果非常好,其代价是使图像变得”模糊”。
高斯滤波器最重要的参数就是高斯分布的标准差σ,σ越大,高斯滤波器的频带就较宽,对图像的平滑程度就越好。通过调节σ参数,可以平衡对图像的噪声的抑制和对图像的模糊。
高斯滤波的模板是用高斯公式计算出来的:
计算过程:
1.利用邻域内其他像素点到邻域中心的距离,带入二维高斯函数,计算出高斯模板,常见3×3或5×5大小的高斯模板。
2.若模板为小数形式,进行归一化处理,将模板左上角值归一为1。
3.将高斯模板的中心对准待处理的图像矩阵,然后对应元素相乘后相加,没有元素的地方补零
(例如3×3高斯模板,需要对待处理图像最外层补一圈零)。
4.每个元素分别进行上述计算,得到的输出矩阵就是高斯滤波的结果。
2.图像增强有哪些方法?
OPencv 图像增强的案例_Σίσυφος1900的博客-CSDN博客
1.对比度拉升:采用了线性函数对图像的灰度值进行变换
2.Gamma校正:采用了非线性函数(指数函数)对图像的灰度值进行变换
3.直方图均衡化
将原始图像的直方图通过积分概率密度函数转化为概率密度为1(理想情况)的图像,从而达到提高对比度的作用。
直方图均衡化的实质也是一种特定区域的展宽,但是会导致整个图像向亮的区域变换。当原始图像给定时,对应的直方图均衡化的效果也相应的确定了。
4.直方图规定化
5.同态滤波器
https://blog.csdn.net/weixin_39354845/article/details/122903403
直方图均衡化、Laplace、Log、Gamma
3.图像的特征提取有哪些算法?
3.1 HOG(方向梯度直方图)
问题解析
HOG(Histogram of Oriented Gridients的简写)特征检测算法,一种解决人体目标检测的图像描述子,是一种用于表征图像局部梯度方向和梯度强度分布特性的描述符。其主要思想是: 在边缘具体位置未知的情况下,边缘方向的分布也可以很好的表示行人目标的外形轮廓。
整体流程简单描述如下:
1将输入图像(你要检测的目标或者扫描窗口)灰度化,即将彩色图转换为灰度图
2颜色空间归一化:采用Gamma校正法对输入图像进行颜色空间的标准化(归一化),目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰
3梯度计算:计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰
4梯度方向直方图:将图像划分成小cells(例如88像素/cell), 统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的描述符
5重叠直方图归一化:将每几个cell组成一个block(例如33个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征描述符。
6HOG特征:将图像image内的所有block的HOG特征描述符串联起来就可以得到该image(你要检测的目标)的HOG特征描述符,就得到最终的可供分类使用的特征向量了
答案
HOG的主要思想是:在 一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布(即梯度的统计信息,而梯度主要位于边缘的地方)很好地描述。HOG特征检测算法的几个步骤:
颜色空间归一化
梯度计算
梯度方向直方图
重叠块直方图归一化
HOG特征
8常用的图像局部特征和全局特征
常用的全局特征就是颜色,纹理,形状,直方图等,局部特征有关键点,角点等
3.2 SIFT(尺度不变特征变换)
SIFT:opencv 特征提取 -SIFT_Σίσυφος1900的博客-CSDN博客
主要步骤
1)、尺度空间的生成;
2)、检测尺度空间极值点;
3)、精确定位极值点,消除边缘响应,并剔除对比度低的点;
4)、为每个关键点指定方向参数;
5)、关键点描述子的生成。
3.3 SURF(加速稳健特征,对sift的改进)
3.4 DOG(高斯函数差分)
为了在尺度空间中找到稳定不变的极值点,在SIFT算法中使用了高斯差分(DOG)函数D(x,y,σ),定义为
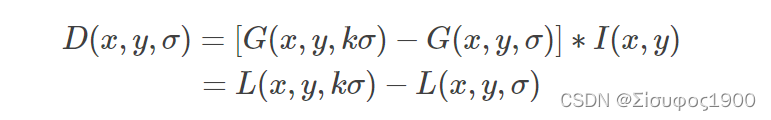
其中 kσ和 σ是连续的两个图像的平滑尺度,所得到的差分图像再高斯差分金字塔中。
选择高斯差分函数的原因如下:
- 计算简单,因为 L(x,y,σ)L(x,y,σ)是一定需要计算的,而D(x,y,σ)只需要执行减法。
- 高斯拉普拉斯算子LoG(Laplacian of Gaussian),即图像的二阶导数,能够在不同的尺度下检测到图像的斑点特征,从而检测到图像中尺度变化下的位置不动点,但是LoG的运算效率不高。而DoG是LoG的近似。DoG和LoG的关系如下述所示:
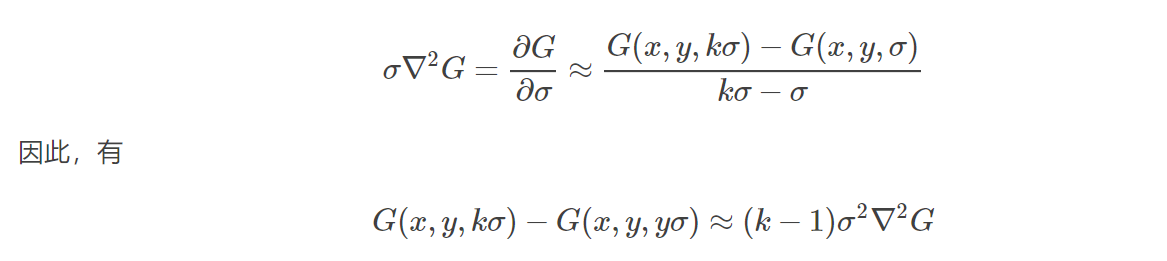
而 σ2∇2G正是尺度归一化算子的表达形式。在所有的尺度中 k-1是一个常数,当 kk趋近于1的时候误差趋近于0,但实际上这种误差对于极值的位置检测并没有什么影响
3. 通过前人的实验证明LoG提取的特征稳定性最强
3.5 LBP(局部二值模式)
3.6 HAAR
Haar特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素之和减去黑色矩形像素之和。Haar特征值反映了图像的灰度变化情况。 如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。
在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
3.7 SIFT vs HOG
共同点:都是基于图像中梯度方向直方图的特征提取方法
不同点:
SIFT提取的关键点是角点(是角点+梯度直方图),HOG提取的是边缘特征。
SIFT 特征通常与使用SIFT检测器得到的兴趣点一起使用。这些兴趣点与一个特定的方向和尺度相关联。通常是在对一个图像中的方形区域通过相应的方向和尺度变换后,再计算该区域的SIFT特征。
结合SIFT和HOG方法,可以发现SIFT对于复杂环境下物体的特征提取具有良好的特性;而HOG对于刚性物体的特征提取具有良好的特性。
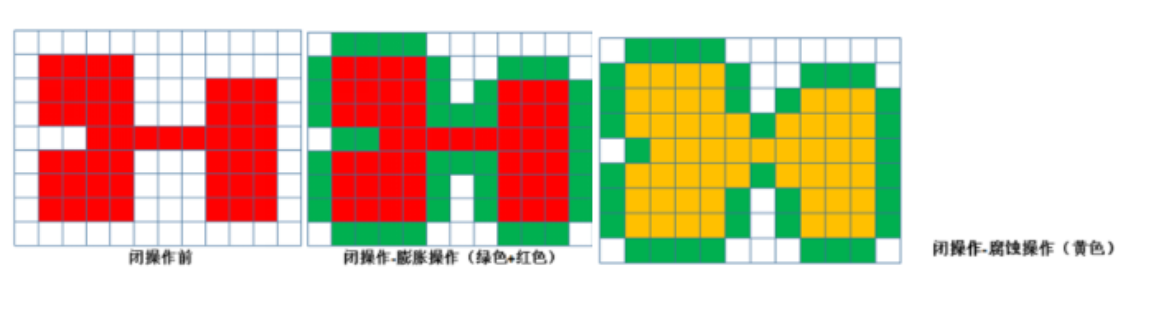
4.膨胀和腐蚀含义?开运算和闭运算先后顺序?
Opencv 笔记1 膨胀、腐蚀、morphologyEx、开、闭操作_Σίσυφος1900的博客-CSDN博客
膨胀:指使用卷积核B(可以理解为模板)对图像A(或者某部分区域)进行卷积操作,卷积核可以是任意形状或大小。膨胀是求局部最大值的操作。
当卷积核B(模板)扫描图像A与其进行卷积操作时,计算模板B覆盖的区域的最大值并将最大值赋给模板的参考点。因为图像中亮点的灰度值大,所以膨胀操作会使得图像中的高亮区域逐渐增长。

腐蚀:是膨胀的反操作,腐蚀计算的是局部区域的最小值。将卷积核B与图像A进行卷积,将B所覆盖区域的最小值赋给参考点。腐蚀操作会使得图像中亮的区域变小,暗的区域变大。

1)开运算:先对图像腐蚀后膨胀。
A○S= (AΘS)⊕ S
作用:用来消除小的物体,平滑形状边界,并且不改变其面积。可以去除小颗粒噪声,断开物体之间的粘连。
2)闭运算:先对图像膨胀后腐蚀
A●S= (A⊕S)Θ S
作用:用来填充物体内的小空洞,连接邻近的物体,连接断开的轮廓线,平滑其边界的同时不改变面积。
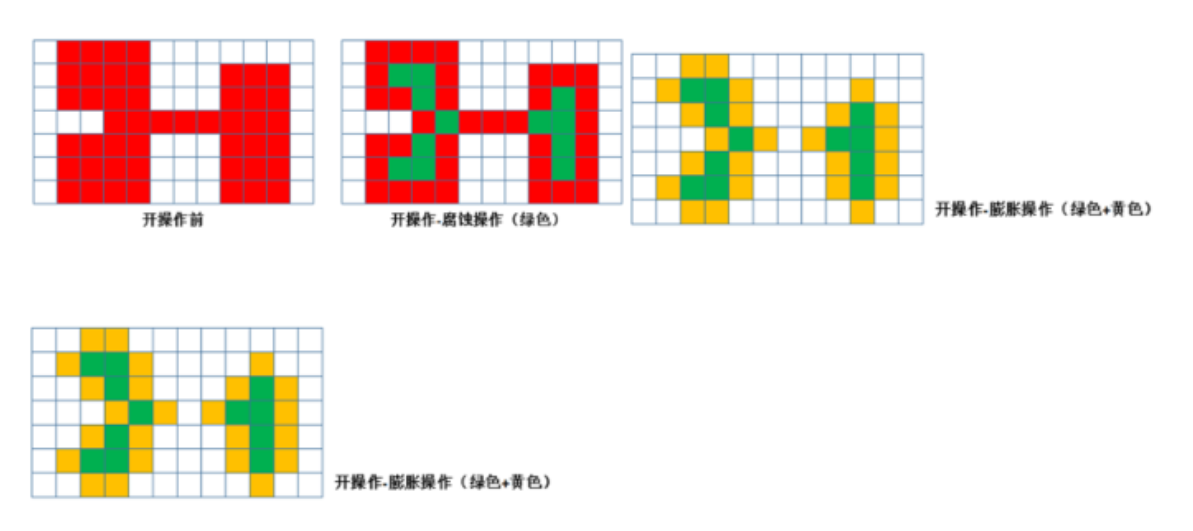
开操作
● 开操作是指:先腐蚀,在膨胀。
● 开操作可以移除较小的明亮区域、在较细的地方分离物体。
● 应用例子:通过开操作将阈值处理后的细胞分离,可以更清晰地统计细胞数目
闭操作
● 闭操作是指:先膨胀,再腐蚀。
● 闭操作可以填充物体内的细小空洞、连接邻近的明亮物体。


5.传统的边缘检测算子有哪些?
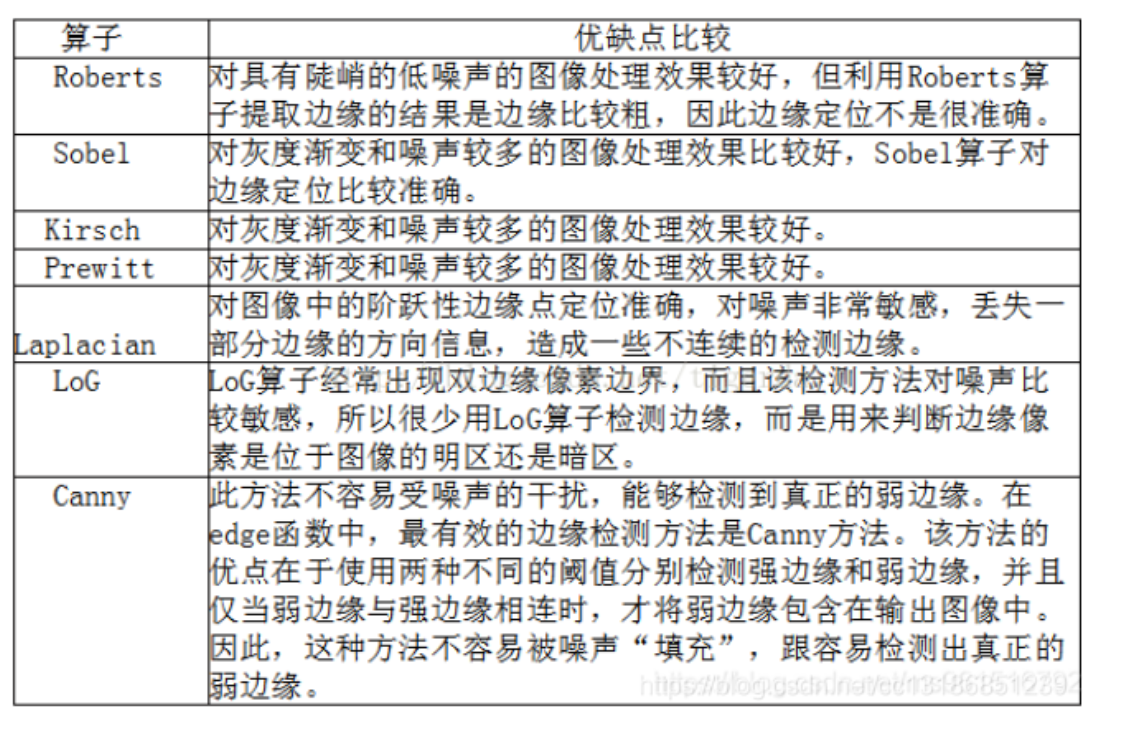
是以离散型的差分算子,用来运算图像亮度函数的梯度的近似值, Sobel算子是典型的基于一阶导数的边缘检测算子,由于该算子中引入了类似局部平均的运算,因此对噪声具有平滑作用,能很好的消除噪声的影响。Sobel算子对于像素的位置的影响做了加权,与Prewitt算子、Roberts算子相比因此效果更好。 Sobel算子包含两组3×3的矩阵,分别为横向及纵向模板,将之与图像作平面卷积,即可分别得出横向及纵向的亮度差分近似值。实际使用中,常用如下两个模板来检测图像边缘。

然后可用以下公式计算梯度方向。
若Θ = 0,即代表图像该处拥有纵向边缘,左方较右方暗
缺点:Sobel并没有将图像的主题与背景严格地区分开来,也就是没有基于图像灰度进行处理;由于没有严格地模拟人的视觉生理特征,所以提取的图像轮廓有时并不能令人满意。
5.2 加权平均算子(Isotropic Sobel)
权值反比于邻点与中心点的距离,当沿不同方向检测边缘时梯度幅度一致,就是通常所说的各向同性Sobel(Isotropic Sobel)算子。模板也有两个,一个是检测水平边沿的 ,另一个是检测垂直平边沿的 。各向同性Sobel算子和普通Sobel算子相比,它的位置加权系数更为准确,在检测不同方向的边沿时梯度的幅度一致。
5.3 罗伯茨算子(Roberts)
是一种最简单的算子,是一种利用局部差分算子寻找边缘的算子,他采用对角线方向相邻两象素之差近似梯度幅值检测边缘。检测垂直边缘的效果好于斜向边缘,定位精度高,对噪声敏感,无法抑制噪声的影响。
Roberts边缘算子是一个2×2的模板,采用的是对角方向相邻的两个像素之差。
5.4 Prewitt算子
是一种一阶微分算子的边缘检测,利用像素点上下、左右邻点的灰度差,在边缘处达到极值检测边缘,去掉部分伪边缘,对噪声具有平滑作用 。其原理是在图像空间利用两个方向模板与图像进行邻域卷积来完成的,这两个方向模板一个检测水平边缘,一个检测垂直边缘
5.5 拉普拉斯算子(Laplacian)
是一种各向同性算子,二阶微分算子,在只关心边缘的位置而不考虑其周围的象素灰度差值时比较合适。Laplace算子对孤立象素的响应要比对边缘或线的响应要更强烈,因此只适用于无噪声图象。存在噪声情况下,使用Laplacian算子检测边缘之前需要先进行低通滤波。所以,通常的分割算法都是把Laplacian算子和平滑算子结合起来生成一个新的模板。
一个二维图像函数的拉普拉斯变换是各向同性的二阶导数,定义了更适合于数字图像处理,将拉式算子表示为离散形式:
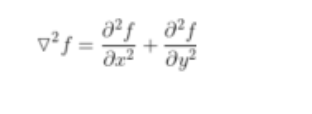
两步
1)先cv.Laplacian(image, cv.CV_16S, ksize=3)
2)再 cv.convertScaleAbs(Laplacian) 即可
5.6 Canny算子
Sobel算子检测方法对灰度渐变和噪声较多的图像处理效果较好,sobel算子对边缘定位不是很准确,图像的边缘不止一个像素;当对精度要求不是很高时,是一种较为常用的边缘检测方法。
Canny方法不容易受噪声干扰,能够检测到真正的弱边缘。优点在于,使用两种不同的阈值分别检测强边缘和弱边缘,并且当弱边缘和强边缘相连时,才将弱边缘包含在输出图像中。
Laplacian算子法对噪声比较敏感,所以很少用该算子检测边缘,而是用来判断边缘像素视为与图像的明区还是暗区。拉普拉斯高斯算子是一种二阶导数算子,将在边缘处产生一个陡峭的零交叉, Laplacian算子是各向同性的,能对任何走向的界线和线条进行锐化,无方向性。这是拉普拉斯算子区别于其他算法的最大优点。
https://www.jianshu.com/p/2a06c68f6c14
优于前面几种算法,实现麻烦,是一个具有滤波,增强,检测的多阶段的优化算子,在进行处理前,Canny算子先利用高斯平滑滤波器来平滑图像以除去噪声,Canny分割算法采用一阶偏导的有限差分来计算梯度幅值和方向,在处理过程中,Canny算子还将经过一个非极大值抑制的过程,最后Canny算子还采用两个阈值来连接边缘。
step1: 用高斯滤波器平滑图像;
step2: 用一阶偏导的有限差分来计算梯度的幅值和方向;
step3: 对梯度幅值进行非极大值抑制
step4: 用双阈值算法检测和连接边缘(双阈值筛选)
5.6.1 Canny如何极大值抑制?
通常灰度变化的地方都比较集中,将局部范围内的梯度方向上,灰度变化最大的保留下来,其它的不保留,这样可以剔除掉一大部分的点。将有多个像素宽的边缘变成一个单像素宽的边缘。即”胖边缘”变成”瘦边缘”。
Canny算子中的非极大值抑制是沿着梯度方向进行的,即是否为梯度方向上的极值点;而在角点检测等场景下说的非极大值抑制,则是检测中心点处的值是否是某一个邻域内的最大值,是,则保留,否则去除,这种情况下的非极大值抑制比较简单。
6.直方图是什么?
是用以表示数字图像中亮度分布的直方图,标绘了图像中每个亮度值的像素数;横坐标的左侧为纯黑、较暗的区域,而右侧为较亮、纯白的区域。
7.直方图的均衡化
目的:将原始图像的灰度级均匀的映射到整个灰度级范围内,得到一个灰度级均匀的图像。
实现方法:将该灰度级出来的概率累计之前灰度级的概率之和,然后乘以最大灰度值,所得即为均衡化图像。
8.如何对图像进行90度旋转?
opencv 图像旋转_Σίσυφος1900的博客-CSDN博客
img = cv2.imread(“./data/hig.jpg”)
out=cv2.transpose(img)
out=cv2.flip(out,flipCode=0) # 0:左旋转 | 1:右旋转
9.数据增强怎么处理的?
9.1 几何变换
flip:水平翻转,也叫镜像;垂直翻转
rotation:图片旋转一定的角度,这个可以通过opencv来操作,各个框架也有自己的算子
crop:随机裁剪,比如说,在ImageNet中可以将输入图片进行裁剪,然后输入。
9.2 颜色变换
hue:灰度调节
contrast:在图像的HSV颜色空间,改变H,S和V亮度分量,增加光照变化。对光照有特殊要求的可以使用
saturation:图像饱和度 exposure:增加曝光
9.3 多个区域置零
random erase:随机擦除,将图片中的某个区域置零
CutOut:和random erase 差不多,都是将图片中某个区域擦除
hide-and-seek:将图片分为k*k的网格,每个网格已一定概率的方式擦除,和random erase、CutOut差不多。
grid mask:首先准备一个mask,mask非零即一,将mask和图片相乘,这样就会擦除很多区域了。
9.4 多张图片增强
MixUp:两张图片,经过对应位置,经过线性插值,组成一张新的照片
CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。
图像旋转之后的空洞怎么补齐? 最邻近插值,双线性插值
10.图像处理基本算法
图像平滑 Opencv 笔记3 图像平滑_Σίσυφος1900的博客-CSDN博客
图像滤波算法
模型匹配
Blob分析:【数字图像处理学习笔记之三】Blob分析_zhougynui的博客-CSDN博客_机器视觉blob分析原理
Blob分析的一般步骤:
(1)图像分割:分离出前景和背景
(2)连通性分析:根据目标的连通性对目标区域进行标记,或者叫拓扑性分析
(3)特征量计算:描述了区域的几何特征,这些几何特征不依赖与灰度值
一个很简单的例子:
1.图像分割
将图像分离为目标像素和背景像素,初始分割之后一般需要进行形态学处理才能满足使用要求。常用分割方法:直接输入;硬阈值分割;软阈值分割。常用形态学处理包括:连通、膨胀、腐蚀、开操作、闭操作、顶帽变换、击中与不击中变换、交集、差异、骨架、边界等。
阈值分割又包括:
1)简单阈值分割threshold
适用范围:目标与背景之间存在灰度差(如果环境稳定,阈值可以在离线状态下一次确定)
2)动态阈值分割dyn_threshold
适用范围:背景不均一无法确定全局阈值、目标经常表现为比背景局部亮一些或者暗一些。这时候需要通过其领域来找到一个合适的阈值进行分割。确定其领域的方法是:通过一些平滑滤波算子来确定领域,例如mean_image或者binomial_filter
3)自动全局阈值方法bin_threshold
4)watersheds_threshold
2.特征量计算常用
area_center,区域面积Area和中心(Row,Column)
area_center_gray,区域面积Area和灰度中心(Row,Column)
smallest_rectangle1最小外接矩形
smallest_rectangle2最小外接仿射矩形,
compactness,紧凑度
elliptic_axis,计算region区域中的椭圆参数
intensity,计算region区域的灰度平均值和偏差
min_max_gray,最小最大灰度值
11、 opencv中RGB2GRAY是怎么实现的
答:以R、G、B为轴建立空间直角坐标系,则RGB图的每个象素的颜色可以用该三维空间的一个点来表示,而Gray图的每个象素的颜色可以用直线R=G=B上的一个点来表示。于是rgb转gray图的本质就是寻找一个三维空间到一维空间的映射,最容易想到的就是射影(即过rgb空间的一个点向直线R=G=B做垂线),事实上Matlab也是这样做的,输出的灰度图像是RGB三种颜色通道的加权和;
Gray = 0.29900 * R + 0.58700 * G + 0.11400 * B。
灰度可以说是亮度(luminance)的量化值,而RGB的定义是客观的三个波长值,转换时需要考虑人眼对不同波长的灵敏度曲线,所以系数不相等。
目前通过卷积神经网络进行检测的方法主要分为one-stage和two-stage,分别写出了解的对应的算法。
12、 数字图像中有哪些基本特征?
答:颜色特征、纹理特征、形状特征、空间关系特征等。
13、 霍夫变换的理解
霍夫变换常用来提取图像中的直线和圆等几何形状。它通过一种投票算法检测具有特定形状的物体。该过程在一个参数空间中通过计算累计结果的局部最大值得到一个符合该特定形状的集合作为霍夫变换结果。
答案
针对每个像素点,使得theta从-90度到180度,使用极坐标p = xcos(theta) + ysin(theta) 计算得到共270组(p,theta)代表着霍夫空间的270条直线。将这270组值存储到H中。
如果一组点共线,则这组点中的每个值,都会使得H(p,theta)加1。
因此找到H(p,theta)值最大的直线,就是共线的点最多的直线,H(p,theta)值次大的,是共线点次多的直线。可以根据一定的阈值,将比较明显的线全部找出来
14、 图像的插值方法有哪些?
最近邻法
双线性内插法
三次内插法
https://blog.csdn.net/weixin_39354845/article/details/122949415
15、 Graph-cut的基本原理和应用
GraphCut方法图像分割问题与图的最小割(min cut)问题相关联。
首先用一个无向图G=表示要分割的图像,V和E分别是顶点(vertex)和边(edge)的集合。此处的Graph和普通的Graph稍有不同。普通的图由顶点和边构成,如果边的有方向的,这样的图被则称为有向图,否则为无向图,且边是有权值的,不同的边可以有不同的权值,分别代表不同的物理意义。而Graph Cuts图是在普通图的基础上多了2个顶点,这2个顶点分别用符号”S”和”T”表示,统称为终端顶点。其它所有的顶点都必须和这2个顶点相连形成边集合中的一部分。
答案
根据待分割的图像,确定图的节点与边,即图的形状已确定下来,是给图中所有边赋值相应的权值,然后找到权值和最小的边的组合,就完成了图像分割。
16、 图像锐化 – sharpen
图像锐化,是使图像边缘更清晰的一种图像处理方法,细节增强(detail enhancement)我理解也包含了图像锐化,常用的做法是提取图像的高频分量,将其叠加到原图上。图像高频分量的提取有两种做法,一种是用高通滤波器,得到高频分量,另一种是通过低通滤波,用原图减低频得以高频。
直接提取高频的方法有sobel算法和laplcian算子。sobel算子是图像的一阶导数,提取的是梯度信息,分水平和垂直两种,常常用来做边缘检测、方向判别,sobel算子在斜坡处不为0,因此会产生较粗的边缘。laplcian算子是图像的二阶导,在图像开始变化和结束变化的地方值不为0,渐变时结果为0,因此laplacian比sobel算子更适合做sharpen。
除了直接提取高频的方法外,我们也可以先提取低频,原图减去低频得到高频。这种方法称为非锐化掩模(unsharpen mask),我们常使用低通滤波器(高斯、双边)对图像进行滤波,这种方法滤波器很好控制(包括大小和强弱),从而可以控制高频分量的强弱。
平滑:把图像变模糊
锐化:把图像变清晰
图像锐化主要用于增强图像的灰度跳变部分,这一点与图像平滑对灰度跳变的抑制正好相反,事实上从平滑与锐化的两种运算算子上也能说明这一点,线性平滑都是基于对图像邻域的加权求和或积分运算,而锐化则通过其逆运算导数(梯度)或有限差分来实现。
17、SIFT、HOG。SIFT是如何保持尺度不变性的
对SIFT算法的理解,尤其是尺度不变性_ChuanjieZhu-CSDN博客_尺度不变性
18、常用的图像分割算法。
19、写一个图像resize函数(放大和缩小)
20、写梯度下降代码
21、opencv里面mat有哪些构造函数
浅谈Opencv Mat类(常用构造函数和成员函数整理)_古天九等一缕的博客-CSDN博客_opencv构造mat
Mat::Mat()
无参数构造方法;
2、Mat::Mat(int rows, int cols, int type)
创建行数为 rows,列数为 col,类型为 type 的图像;
3、Mat::Mat(Size size, int type)
创建大小为 size,类型为 type 的图像;
4、Mat::Mat(int rows, int cols, int type, const Scalar& s)
创建行数为 rows,列数为 col,类型为 type 的图像,并将所有元素初始化为值 s;
5、Mat::Mat(Size size, int type, const Scalar& s)
创建大小为 size,类型为 type 的图像,并将所有元素初始化为值 s;
6、Mat::Mat(const Mat& m)
将m赋值给新创建的对象,此处不会对图像数据进行复制,m和新对象共用图像数据,属于浅拷贝;
7、Mat::Mat(int rows, int cols, int type, void data, size_t step=AUTO_STEP)
创建行数为rows,列数为col,类型为type的图像,此构造函数不创建图像数据所需内存,而是直接使用data所指内存,图像的行步长由 step指定。
8、Mat::Mat(Size size, int type, void data, size_t step=AUTO_STEP)
创建大小为size,类型为type的图像,此构造函数不创建图像数据所需内存,而是直接使用data所指内存,图像的行步长由step指定。
9、Mat::Mat(const Mat& m, const Range& rowRange, const Range& colRange)
创建的新图像为m的一部分,具体的范围由rowRange和colRange指定,此构造函数也不进行图像数据的复制操作,新图像与m共用图像数据;
10、Mat::Mat(const Mat& m, const Rect& roi)
22、如何将buffer类型转化为mat类型? 23、opencv如何读取png格式的图片?
img = cv2.imread(filepath, cv2.IMREAD_UNCHANGED)
24、opencv如何读取内存图片?
OpenCV 读取内存图片_m0_37346206的博客-CSDN博客_opencv读取内存图片
opencv 3:
char * lpFileBuf = GetFileBuf("girl.bmp");
CvMat mCvmat = cvMat(512*3, 768*3, CV_8UC1, lpFileBuf);
IplImage*IpImg = cvDecodeImage(&mCvmat, 1);
//opencv 2.0 CvMat->Mat数据转换 //Mat b = Mat(mat,true);
//opencv3.0 CvMat->Mat数据转换 //Mat image = cvarrToMat(pp);
Mat image = cvarrToMat(IpImg).clone();
cvReleaseImage(&IpImg);
opencv 4:
#include
cv::_InputArray pic_arr(bmpFileBuf, nBmpBufSize);
cv::Mat src_mat = cv::imdecode(pic_arr, cv::IMREAD_UNCHANGED);
cv::imshow("123", src_mat);
opencv从内存中读取图片可以大大减少读取文件所消耗的时间。
CvMat中的data数据只是矩阵数据的首地址,分配的内存大小为行列乘积。对该内存块的操作需要调用函数,也可以使用指针索引。
找到了 opencv加载内存中的图片数据的方法,现在记录下来。
//参数分别为 图片宽度,高度,类型,图片数据指针(unsigned char*)
//这个构造函数并没有从新分配内存
//参数分别为 图片宽度,高度,类型,图片数据指针(unsigned char*)
//这个构造函数并没有从新分配内存
CvMat mCvmat = cvMat(w, h, CV_8UC1, mImgData);
IplImage* IpImg = cvDecodeImage(&mCvmat, 1);
//opencv3.0 IplImage到Mat类型的转换的方法
Mat image = cvarrToMat(IpImg);
if (!image.data)
{
return false;
}
cvReleaseImage(&IpImg);
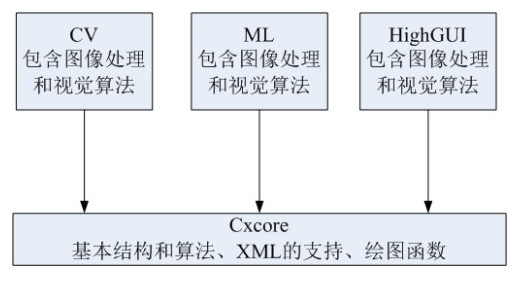
25、opencv里面有哪些库?
我们都知道 OpenCV 是一个开源的计算机视觉库,那么里面到底有哪些东西?本文将为你解答这个问题。
模块一:CV
这个模块是 OpenCV 的核心,它包含了基本的图像处理函数和高级的计算机视觉算法。
模块二:HighGUI
这个模块包含了图像和视频的基本 GUI 输入输出函数。
模块三:MILL
这个模块是计算机学习库,包含一些基于统计的分类和聚类工具。
模块四:CXCORE
这个模块包含了基本数据结构和一些最基本的函数。上面四个模块都要调用此模块。
下图可形象表述OpenCV的四大模块
【calib3d】:其实就是就是Calibration(校准)加3D这两个词的组合缩写。这个模块主要是相机校准和三维重建相关的内容。基本的多视角几何算法,单个立体摄像头标定,物体姿态估计,立体相似性算法,3D信息的重建等等。
【contrib】:也就是Contributed/Experimental Stuf的缩写, 该模块包含了一些最近添加的不太稳定的可选功能,不用去多管。2.4.8之后有新型人脸识别, 立体匹配 ,人工视网膜模型等技术。
【core】: 核心功能模块,尤其是底层数据结构和算法函数。包含如下内容:
OpenCV基本数据结构
动态数据结构
绘图函数
数组操作相关函数
辅助功能与系统函数和宏
【imgproc】: Image和Processing这两个单词的缩写组合。图像处理模块,这个模块包含了如下内容:
线性和非线性的图像滤波
图像的几何变换
其它(Miscellaneous)图像转换
直方图相关
结构分析和形状描述
运动分析和对象跟踪
特征检测
【features2】: d也就是Features2D, 2D功能框架 ,包含兴趣点检测子、描述子以及兴趣点匹配框架。包含如下内容:
特征检测和描述
特征检测器(Feature Detectors)通用接口
描述符提取器(Descriptor Extractors)通用接口
描述符匹配器(Descriptor Matchers)通用接口
通用描述符(Generic Descriptor)匹配器通用接口
【flann】: Fast Library for Approximate Nearest Neighbors,高维的近似近邻快速搜索算法库, 包含两个部分:快速近似最近邻搜索和聚类。
【gpu】: 运用GPU加速的计算机视觉模块。
【highgui】: 也就是high gui,高层GUI图形用户界面,包含媒体的I / O输入输出, 视频捕捉、图像和视频的编码解码、图形交互界面的接口等内容。
【legacy】: 一些已经废弃的代码库,保留下来作为向下兼容,包含如下相关的内容。
运动分析
期望最大化
直方图
平面细分(C API)
特征检测和描述(Feature Detection and Description)
描述符提取器(Descriptor Extractors)的通用接口
通用描述符(Generic Descriptor Matchers)的常用接口
【ml】: Machine Learning,机器学习模块, 基本上是统计模型和分类算法,包含如下内容。
统计模型 (Statistical Models)
一般贝叶斯分类器 (Normal Bayes Classifier)
K-近邻 (K-NearestNeighbors)
支持向量机 (Support Vector Machines)
决策树 (Decision Trees)
提升(Boosting)
梯度提高树(Gradient Boosted Trees)
随机树 (Random Trees)
超随机树 (Extremely randomized trees)
期望最大化 (Expectation Maximization)
神经网络 (Neural Networks)
MLData
【nonfree】: 也就是一些具有专利的算法模块 ,包含特征检测和GPU相关的内容。最好不要商用,可能会被告哦。
【objdetect】: 目标检测模块,包含Cascade Classification(级联分类)和Latent SVM这两个部分。
【ocl】: 即OpenCL-accelerated Computer Vision,运用OpenCL加速的计算机视觉组件模块。
【photo】: 也就是Computational Photography,包含图像修复和图像去噪两部分。
【stitching】: images stitching,图像拼接模块,包含如下部分。
拼接流水线
特点寻找和匹配图像
估计旋转
自动校准
图片歪斜
接缝估测
曝光补偿
图片混合
【superres】: SuperResolution,超分辨率技术的相关功能模块。
【ts】: opencv测试相关代码,不用去管他。
【video】: 视频分析组件,该模块包括运动估计,背景分离,对象跟踪等视频处理相关内容。
【Videostab】: Video stabilization,视频稳定相关的组件
26、用过opencv里面哪些函数?
opencv 图像处理函数大全_m0_37964922的博客-CSDN博客_opencv图像处理函数
LoadImage:将图像文件加载至内存;
NamedWindow:在屏幕上创建一个窗口;
ShowImage:在一个已创建好的窗口中显示图像;
WaitKey:使程序暂停,等待用户触发一个按键操作;
ReleaseImage:释放图像文件所分配的内存;
DestroyWindow:销毁显示图像文件的窗口;
CreateFileCapture:通过参数设置确定要读入的AVI文件;
QueryFrame:用来将下一帧视频文件载入内存;
ReleaseCapture:释放 Capture结构开辟的内存空间;
CreateTrackbar:创建一个滚动条;
SetCaptureProperty:设置 Capture对象的各种属性;
GetCaptureProperty:查询 Capture对象的各种属性;
GetSize:当前图像结构的大小;
Smooth:对图像进行平滑处理;
PyrDown:图像金字塔,降采样,图像缩小为原来四分之一;
Canny:Canny边缘检测;
CreateCameraCapture:从摄像设备中读入数据;
CreateVideoWriter:创建一个写入设备以便逐帧将视频流写入视频文件;
WriteFrame:逐帧将视频流写入文件;
ReleaseVideoWriter:释放 VideoWriter结构开辟的内存空间;
_MAT_ELEM:从矩阵中得到一个元素;
Abs:计算数组中所有元素的绝对值;
AbsDiff:计算两个数组差值的绝对值;
AbsDiffS:计算数组和标量差值的绝对值;
Add:两个数组的元素级的加运算;
AddS:一个数组和一个标量的元素级的相加运算;
AddWeighted:两个数组的元素级的加权相加运算(alpha运算);
Avg:计算数组中所有元素的平均值;
AvgSdv:计算数组中所有元素的绝对值和标准差;
CalcCovarMatrix:计算一组n维空间向量的协方差;
Cmp:对两个数组中的所有元素运用设置的比较操作;
CmpS:对数组和标量运用设置的比较操作;
ConvertScale:用可选的缩放值转换数组元素类型;
Copy:把数组中的值复制到另一个数组中;
CountNonZero:计算数组中非0值的个数;
CrossProduct:计算两个三维向量的向量积(叉积);
tColor:将数组的通道从一个颜色空间转换另外一个颜色空间;
Det:计算方阵的行列式;
Div:用另外一个数组对一个数组进行元素级的除法运算;
DotProduct:计算两个向量的点积;
EigenVV:计算方阵的特征值和特征向量;
Flip:围绕选定轴翻转;
GEMM:矩阵乘法;
GetCol:从一个数组的列中复制元素;
GetCols:从数据的相邻的多列中复制元素;
GetDiag:复制数组中对角线上的所有元素;
GetDims:返回数组的维数;
GetDimSize:返回一个数组的所有维的大小;
GetRow:从一个数组的行中复制元素值;
GetRows:从一个数组的多个相邻的行中复制元素值;
GetSize:得到二维的数组的尺寸,以 Size返回;
GetSubRect:从一个数组的子区域复制元素值;
InRange:检查一个数组的元素是否在另外两个数组中的值的范围内;
InRangeS:检查一个数组的元素的值是否在另外两个标量的范围内;
Invert:求矩阵的逆;
Mahalonobis:计算两个向量间的马氏距离;
Max:在两个数组中进行元素级的取最大值操作;
MaxS:在一个数组和一个标量中进行元素级的取最大值操作;
Merge:把几个单通道图像合并为一个多通道图像;
Min:在两个数组中进行元素级的取最小值操作;
MinS:在一个数组和一个标量中进行元素级的取最小值操作;
MinMaxLoc:寻找数组中的最大最小值;
Mul:计算两个数组的元素级的乘积(点乘);
Not:按位对数组中的每一个元素求反;
Normalize:将数组中元素进行归一化;
Or:对两个数组进行按位或操作;
Ors:在数组与标量之间进行按位或操作;
Reduce:通过给定的操作符将二维数组简为向量;
Repeat:以平铺的方式进行数组复制;
Set:用给定值初始化数组;
SetZero:将数组中所有元素初始化为0;
SetIdentity:将数组中对角线上的元素设为1,其他置0;
Solve:求出线性方程组的解;
Split:将多通道数组分割成多个单通道数组;
Sub:两个数组元素级的相减;
SubS:元素级的从数组中减去标量;
SubRS:元素级的从标量中减去数组;
Sum:对数组中的所有元素求和;
SVD:二维矩阵的奇异值分解;
SVBkSb:奇异值回代计算;
Trace:计算矩阵迹;
Transpose:矩阵的转置运算;
Xor:对两个数组进行按位异或操作;
XorS:在数组和标量之间进行按位异或操作;
Zero:将所有数组中的元素置为0;
ConvertScaleAbs:计算可选的缩放值的绝对值之后再转换数组元素的类型;
Norm:计算数组的绝对范数, 绝对差分范数或者相对差分范数;
And:对两个数组进行按位与操作;
AndS:在数组和标量之间进行按位与操作;
Scale:是 ConvertScale的一个宏,可以用来重新调整数组的内容,并且可以将参数从一种数据类型转换为另一种;
T:是函数 Transpose的缩写;
Line:画直线;
Rectangle:画矩形;
Circle:画圆;
Ellipse:画椭圆;
EllipseBox:使用外接矩形描述椭圆;
FillPoly、 FillConvexPoly、 PolyLine:画多边形;
PutText:在图像上输出一些文本;
InitFont:采用一组参数配置一些用于屏幕输出的基本个特定字体;
Save:矩阵保存;
Load:矩阵读取;
OpenFileStorage:为读/写打开存储文件;
ReleaseFileStorage:释放存储的数据;
StartWriteStruct:开始写入新的数据结构;
EndWriteStruct:结束写入数据结构;
WriteInt:写入整数型;
WriteReal:写入浮点型;
WriteString:写入字符型;
WriteComment:写一个XML或YAML的注释字串;
Write:写一个对象;
WriteRawData:写入多个数值;
WriteFileNode:将文件节点写入另一个文件存储器;
GetRootFileNode:获取存储器最顶层的节点;
GetFileNodeByName:在映图或存储器中找到相应节点;
GetHashedKey:为名称返回一个惟一的指针;
GetFileNode:在映图或文件存储器中找到节点;
GetFileNodeName:返回文件的节点名;
ReadInt:读取一个无名称的整数型;
ReadIntByName:读取一个有名称的整数型;
ReadReal:读取一个无名称的浮点型;
ReadRealByName:读取一个有名称的浮点型;
ReadString:从文件节点中寻找字符串;
ReadStringByName:找到一个有名称的文件节点并返回它;
Read:将对象解码并返回它的指针;
ReadByName:找到对象并解码;
ReadRawData:读取多个数值;
StartReadRawData:初始化文件节点序列的读取;
ReadRawDataSlice:读取文件节点的内容;
GetModuleInfo:检查IPP库是否已经正常安装并且检验运行是否正常;
ResizeWindow:用来调整窗口的大小;
SaveImage:保存图像;
MoveWindow:将窗口移动到其左上角为x,y的位置;
DestroyAllWindow:用来关闭所有窗口并释放窗口相关的内存空间;
GetTrackbarPos:读取滑动条的值;
SetTrackbarPos:设置滑动条的值;
GrabFrame:用于快速将视频帧读入内存;
RetrieveFrame:对读入帧做所有必须的处理;
ConvertImage:用于在常用的不同图像格式之间转换;
Erode:形态腐蚀;
Dilate:形态学膨胀;
MorphologyEx:更通用的形态学函数;
FloodFill:漫水填充算法,用来进一步控制哪些区域将被填充颜色;
Resize:放大或缩小图像;
PyrUp:图像金字塔,将现有的图像在每个维度上都放大两倍;
PyrSegmentation:利用金字塔实现图像分割;
Threshold:图像阈值化;
Acc:可以将8位整数类型图像累加为浮点图像;
AdaptiveThreshold:图像自适应阈值;
Filter2D:图像卷积;
CopyMakeBorder:将特定的图像轻微变大,然后以各种方式自动填充图像边界;
Sobel:图像边缘检测,Sobel算子;
Laplace:拉普拉斯变换、图像边缘检测;
HoughLines2:霍夫直线变换;
HoughCircles:霍夫圆变换;
Remap:图像重映射,校正标定图像,图像插值;
WarpAffine:稠密仿射变换;
GetQuadrangleSubPix:仿射变换;
GetAffineTransform:仿射映射矩阵的计算;
CloneImage:将整个IplImage结构复制到新的IplImage中;
2DRotationMatrix:仿射映射矩阵的计算;
Transform:稀疏仿射变换;
WarpPerspective:密集透视变换(单应性);
GetPerspectiveTransform:计算透视映射矩阵;
PerspectiveTransform:稀疏透视变换;
CartToPolar:将数值从笛卡尔空间到极坐标(极性空间)进行映射;
PolarToCart:将数值从极性空间到笛卡尔空间进行映射;
LogPolar:对数极坐标变换;
DFT:离散傅里叶变换;
MulSpectrums:频谱乘法;
DCT:离散余弦变换;
Integral:计算积分图像;
DistTransform:图像的距离变换;
EqualizeHist:直方图均衡化;
CreateHist:创建一新直方图;
MakeHistHeaderForArray:根据已给出的数据创建直方图;
NormalizeHist:归一化直方图;
ThreshHist:直方图阈值函数;
CalcHist:从图像中自动计算直方图;
CompareHist:用于对比两个直方图的相似度;
CalcEMD2:陆地移动距离(EMD)算法;
CalcBackProject:反向投影;
CalcBackProjectPatch:图块的方向投影;
MatchTemplate:模板匹配;
CreateMemStorage:用于创建一个内存存储器;
CreateSeq:创建序列;
SeqInvert:将序列进行逆序操作;
tSeqToArray:复制序列的全部或部分到一个连续内存数组中;
FindContours:从二值图像中寻找轮廓;
DrawContours:绘制轮廓;
ApproxPoly:使用多边形逼近一个轮廓;
ContourPerimeter:轮廓长度;
ContoursMoments:计算轮廓矩;
Moments:计算Hu不变矩;
MatchShapes:使用矩进行匹配;
InitLineIterator:对任意直线上的像素进行采样;
SampleLine:对直线采样;
AbsDiff:帧差;
Watershed:分水岭算法;
Inpaint:修补图像;
GoodFeaturesToTrack:寻找角点;
FindCornerSubPix:用于发现亚像素精度的角点位置;
CalcOpticalFlowLK:实现非金字塔的Lucas-Kanade稠密光流算法;
MeanShift:mean-shift跟踪算法;
CamShift:camshift跟踪算法;
CreateKalman:创建Kalman滤波器;
CreateConDensation:创建condensation滤波器;
ConvertPointsHomogenious:对齐次坐标进行转换;
FindChessboardCorners:定位棋盘角点;
FindHomography:计算单应性矩阵;
Rodrigues2:罗德里格斯变换;
FitLine:直线拟合算法;
CalcCovarMatrix:计算协方差矩阵;
Invert:计算协方差矩阵的逆矩阵;
Mahalanobis:计算Mahalanobis距离;
KMeans2:K均值;
CloneMat:根据一个已有的矩阵创建一个新矩阵;
PreCornerDetect:计算用于角点检测的特征图;
GetImage: Mat图像数据格式转换成IplImage图像数据格式;
MatMul:两矩阵相乘;
27、opencv里面为啥是bgr存储图片而不是人们常听的rgb?
用opencv读取图片时, 默认的通道顺序是BGR而非RGB,在RGB为主流的当下, 这种默认给我们带来了一点不便。那么, opencv 为什么要使用BGR而非RGB呢?
目前看到的一种解释说是因为历史原因:早期BGR也比较流行,opencv一开始选择了BGR,到后来即使RGB成为主流,但也不好改了。
28、讲讲HOG特征?他在dpm里面怎么设计的,你改过吗?HOG能检测边缘吗?里面的核函数是啥?那hog检测边缘和canny有啥区别? 29、如何求一张图片的均值?
30、如何写程序将图像放大缩小? 31、如何遍历一遍求一张图片的方差?
32、给定0-1矩阵,求连通域。
二值图像分析最重要的方法就是连通区域标记,它是所有二值图像分析的基础,它通过对二值图像中白色像素(目标)的标记,让每个单独的连通区域形成一个被标识的块,进一步的我们就可以获取这些块的轮廓、外接矩形、质心、不变矩等几何参数。
连通域:在图像中,最小的单位是像素,每个像素周围有8个邻接像素,常见的邻接关系有2种:4邻接与8邻接。
如果A与B连通,B与C连通,则A与C连通。在视觉上看来,彼此连通的点形成了一个区域,而不连通的点形成了不同的区域。这样的一个所有的点彼此连通点构成的集合,我们称为一个连通区域。
L = bwlabel(BW,n)。
33、
1x1卷积和的作用。
34、手推手眼标定(刚面试完,热乎的呢,答得可以)
38、双边滤波原理解析
双边滤波与高斯滤波器相比,对于图像的边缘信息能够更好的保存。其原理为一个 与 空间距离相关的高斯函数与一个灰度距离相关的高斯函数相乘。
40、投影矩阵推导
41、canny 算子如何实现
step1: 用高斯滤波器平滑图象;
step2: 用一阶偏导的有限差分来计算梯度的幅值和方向;
step3: 对梯度幅值进行非极大值抑制
step4: 用双阈值算法检测和连接边缘
42、深度学习用的是那个
43、模糊和边缘检测算子的区别,如果区分
44、PCA 梯度下降原理,数据推导,实现
OpenCV笔记20 PCA_Σίσυφος1900的博客-CSDN博客
45、SVM 支持向量积
珠海某上市公司算法总监:
46、相机标定的原理与坐标系之间的转换,如何转换
47、激光三角原理,如何搭建
48、测量拟合的过程中有哪些算子,原理什么,接着问5,跌代多少次?什么情况最优,如何优化,
49、那个测量算子的优缺点?
50、如何最优的拟合圆
51、如何最优的拟合直线
52、除了标定halcon的标定方法还有哪些标定方法,分别是什么
53、相机坐标系之间是如何转换的:
宁德新能源 二面(研发部门总监)
你是内推的吗(不是,是猎头让内推的),有没有认识的人在宁德新能源(没有)?
(选型)
1、做过那些方案?项目中你那个是全权完成的,碰到的什么问题?
2、对硬件了解多少?伺服电机选型如何选,光源如何选型?镜头如何选?对打光了解吗?(完全蒙蔽)
3、机械设计有多少了解,多少要了解一些
(语言,问的少,但是问的很深) 1、c#和c++的区别是什么
作为一款更现代的编程语言,C#被设计于与当前微软.NET框架共同工作,在客户端和web应用程序中均有涉猎。
C++是一门面向对象的语言,而C#被认为是一门面向组件(component)的编程语言。面向对象编程聚焦于将多个类结合起来链接为一个可执行的二进制程序,而面向组件编程使用可交换的代码模块(可独立运行)并且你不需要知道它们内部是如何工作的就可以使用它们。
以下是C++和C#的主要区别。
- C++将代码编译成机器码,而C#将代码编译成CLR(一种.NET框架的虚拟机组件,它会被ASP.NET所解析)。
- C++要求用户手动处理内存,但是C#运行在虚拟机中,而虚拟机会自动处理内存。
- C#不使用指针(pointer),而C++可以在任何时候使用指针。
- 虽然C++的设计是用于Unix或类Unix的系统,但是它可以运行在任何的平台上。C#虽然已标准化,但是基本上只在Windows的环境下运行。
- C++可以创建独立(stand-alone)和控制台(console)程序。C#可以创建控制台,Windows,ASP.NET和移动(mobile)程序,但不能创建独立程序
2、什么是锁,有那几种锁,如何解锁,锁和内存对应起来如何?
3、多肽是什么?举例说明
4、多线程之间的交互方式有几种,如何交互,各自的优缺点是什么
5、文件读写
(算法)
1、手眼标定手推一下,(我推完后),具体流程说一下,先后顺序能不能乱?为什么
2、简述base object tool camera的两量关系,如果建立起来联系
3、简述决策树,
4、一幅图像中halcon 是如何存贮的,在opencv 中是如何存贮的?为什么要这样存?
5、什么是最大似然估计
6、什么是图像的矩,手推一下?
7、好像最近几个问题感觉你没有信心了?(我回答:不是,是在绝对的力量面前,嘶吼没有任何意义,这次面试交流是对我自己的一个清晰定位,以后会怎么做更有方向)
8、三次内插法数学原理,简单实现
9、halcon 模板匹配的原理,特征检测的关键是什么,什么是特征检测?
10、什么是滞后阈值处理,为什么这么做,用在那个方面
11、什么是极大值抑制,如何做极大值抑制,为什么要这么做?
面试官:今天就问这么多,面试一个小时了,你有什么想问的吗?
我回答:(我自己肯定是过不了),你对我的评价是什么?
面试官:自学能力可以,但是做一个优秀的工程师还不够,对各个方面有了解但是都不深入,你这样发展下去很难做到一个专家级别。
中间又聊了很多废话,后面我要了微信,他给我推荐了几本书,每本书看三遍以上,有什么难解决的问题可以问,但是他不一定有时间回,你先好好学两年,两年以后我们再聊。
结束
1、四领域和八领域的区别?
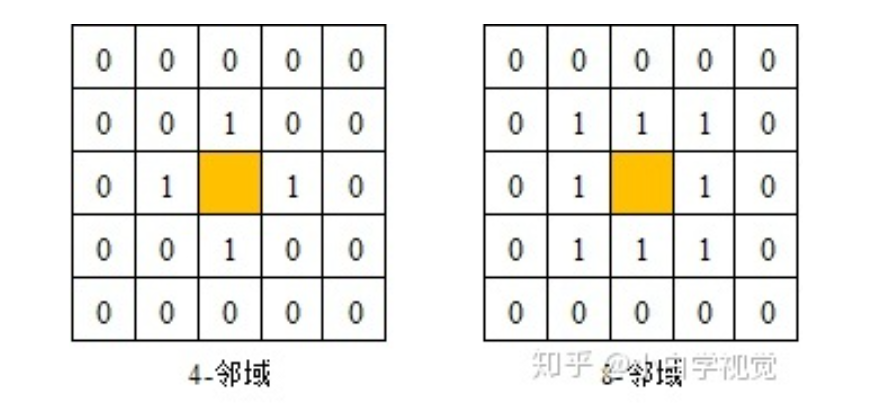
四连通是八连通的子集。也就是说在图像 处理中四连通的区域,一定是八连通
2、连通域是什么,如何理解
图像的连通域是指图像中具有相同像素值并且位置相邻的像素组成的区域
连通域分析是指在图像中寻找出彼此互相独立的连通域并将其标记出来,般情况下,一个连通域内只包含一个像素值,因此为了防止像素值波动对提取不同连通域的影响,连通域分析常处理的是二值化后的图像。
opencv 图像连通域分析_Σίσυφος1900的博客-CSDN博客
3、进程间通信方式和线程间通信方式
c++ 线程间通信方式_天行九歌-CSDN博客_c++线程间通信
答:(1)进程间通信方式:
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
信号量( semophore ) :信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( message queue ):消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存( shared memory ):共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
套接字( socket ):套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
(2)线程间通信方式:
#全局变量;
#Messages消息机制;
#CEvent对象(MFC中的一种线程通信对象,通过其触发状态的改变实现同步与通信)。
4、C++的多态
答:C++的多态性用一句话概括:在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来
调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
1):用virtual关键字申明的函数叫做虚函数,虚函数肯定是类的成员函数;
2):存在虚函数的类都有一个一维的虚函数表叫做虚表,类的对象有一个指向虚表开始的虚指针。虚表是和类对应的,虚表指针是和对象对应的;
3):多态性是一个接口多种实现,是面向对象的核心,分为类的多态性和函数的多态性。;
4):多态用虚函数来实现,结合动态绑定.;
5):纯虚函数是虚函数再加上 = 0;
6):抽象类是指包括至少一个纯虚函数的类;
纯虚函数:virtual void fun()=0;即抽象类,必须在子类实现这个函数,即先有名称,没有内容,在派生类实现内容
5、协程
答:定义:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置;
线程是抢占式,而协程是协作式;
协程的优点:
跨平台
跨体系架构
无需线程上下文切换的开销
无需原子操作锁定及同步的开销
方便切换控制流,简化编程模型
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
协程的缺点:
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU;
进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序:这一点和事件驱动一样,可以使用异步IO操作来解决。
8、TCP握手与释放
答:(1)握手
第一次握手:主机A发送握手信号syn=1和seq=x(随机产生的序列号)的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送syn=1,ack=x(x是主机A的Seq)+1,以及随机产生的确认端序列号
seq=y的包;
第三次握手:主机A收到后检查ack是否正确(ack=x+1),即第一次发送的seq+1,若正确,主机A会再发送ack=y+1,以及随机序
列号seq=z,主机B收到后确认ack值则连接建立成功;
完成三次握手,主机A与主机B开始传送数据。
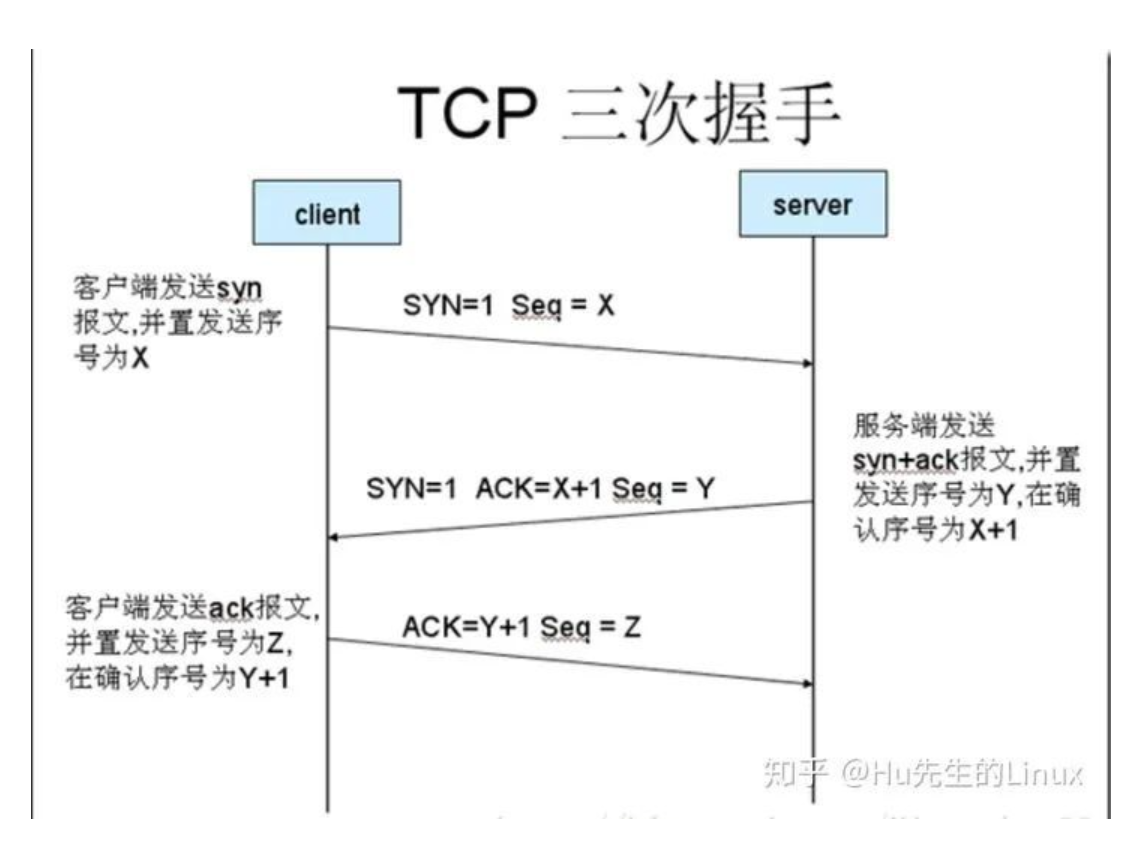
为什么需要”三次握手”?
“三次握手”的目的是”为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。具体例如:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用”三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用”三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。主要目的防止server端一直等待,浪费资源。
(2)挥手
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4);
(2) 服务器收到这个FIN,发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号;
(3) 服务器关闭客户端的连接后,再发送一个FIN给客户端(报文段6);
(4) 客户段收到服务端的FIN后,发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7);
注意:TCP连接的任何一方都可以发起挥手操作,上述步骤只是两种之一;
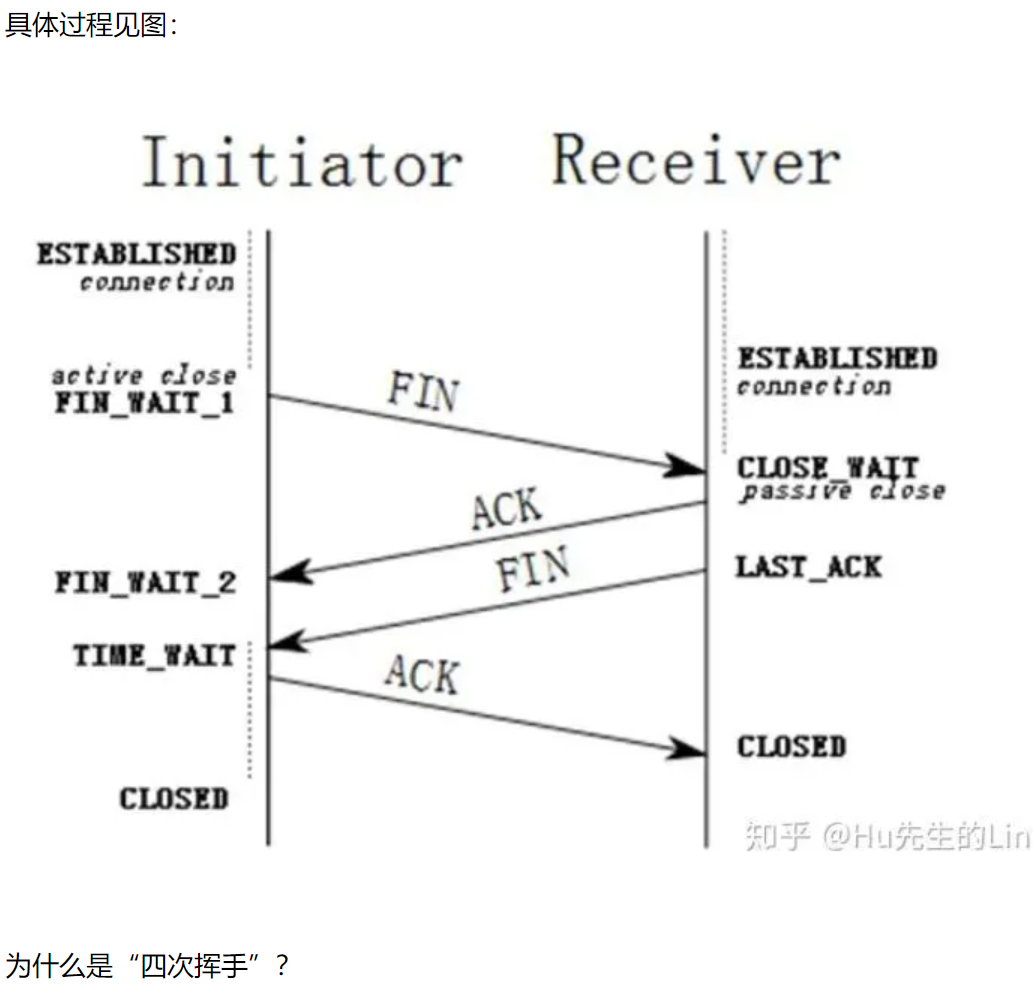
因为当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可能还需要发送一些数据给对方,再发送FIN报文给对方来表示你同意现在可以关闭连接了,故这里的ACK报文和FIN报文多数情况下都是分开发送的,也就造成了4次挥手。
握手,挥手过程中各状态介绍:
(1)3次握手过程状态:
LISTEN: 这个也是非常容易理解的一个状态,表示服务器端的某个SOCKET处于监听状态,可以接受连接了。
SYN_SENT: 当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,因此也随即它会进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。(发送端)
SYN_RCVD: 这个状态与SYN_SENT遥想呼应这个状态表示接受到了SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂,基本上用netstat你是很难看到这种状态的,除非你特意写了一个客户端测试程序,故意将三次TCP握手过程中最后一个ACK报文不予发送。因此这种状态时,当收到客户端的ACK报文后,它会进入到ESTABLISHED状态。(服务器端)
ESTABLISHED:这个容易理解了,表示连接已经建立了。
(2)4次挥手过程状态:
FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。(主动方)
FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你(ACK信息),稍后再关闭连接。(主动方)
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。(主动方)
CLOSING(比较少见): 这种状态比较特殊,实际情况中应该是很少见,属于一种比较罕见的例外状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?其实细想一下,也不难得出结论:那就是如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
CLOSE_WAIT: 这种状态的含义其实是表示在等待关闭。怎么理解呢?当对方close一个SOCKET后发送FIN报文给自己,你系统毫无疑问地会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,实际上你真正需要考虑的事情是察看你是否还有数据发送给对方,如果没有的话,那么你也就可以close这个SOCKET,发送FIN报文给对方,也即关闭连接。所以你在CLOSE_WAIT状态下,需要完成的事情是等待你去关闭连接。(被动方)
LAST_ACK: 这个状态还是比较容易好理解的,它是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,也即可以进入到CLOSED可用状态了。(被动方)
持续更新。。。。。。
Original: https://blog.csdn.net/weixin_39354845/article/details/122902581
Author: Σίσυφος1900
Title: halcon opencv 图像处理面试指南
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/633739/
转载文章受原作者版权保护。转载请注明原作者出处!