

4.8号公布了复赛获奖名单,比赛正式告一段落,为什么现在才开始写呢?其实一是最近一直很忙,二是感觉自己做的不咋地,趁今天有空就写写吧,时间一长就又不想写了。
好了胡扯到此结束,言归正传,这次比赛题目和数据下载
链接:https://pan.baidu.com/s/1RsQkTcERxgmHisMEGt62vA
提取码:60t9
初赛
1 读入数据和数据清洗
导入需要的包
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from category_encoders.leave_one_out import LeaveOneOutEncoder
from sklearn.model_selection import cross_val_score
from sklearn.decomposition import PCA
import xgboost as xgb
1 给变量命名
首先读入数据,官方给的数据是没有列名的,为了方便后续的数据处理,首先读入数据,并给数据加上列名,注意到1,11,12列数据是时间类型的,直接在读入时设置parse_dates参数传化为时间类型
df = pd.read_table(r'D:\比赛\2021年MathorCup大数据竞赛赛道A\附件\附件1:估价训练数据.txt',
parse_dates=[1, 11, 12],sep='\t', header=None, encoding='gbk')
data = pd.DataFrame(data=df)
columns = ['carid', 'tradeTime', 'brand', 'serial', 'model', 'mileage', 'color', 'cityId', 'carCode',
'transferCount', 'seatings', 'registerDate', 'licenseDate', 'country', 'maketype', 'modelyear',
'displacement', 'gearbox', 'oiltype', 'newprice']
for i in range(1, 16):
str_ = 'anonymousFeature'+str(i)
columns.append(str_)
columns.append('price')
data.columns = columns
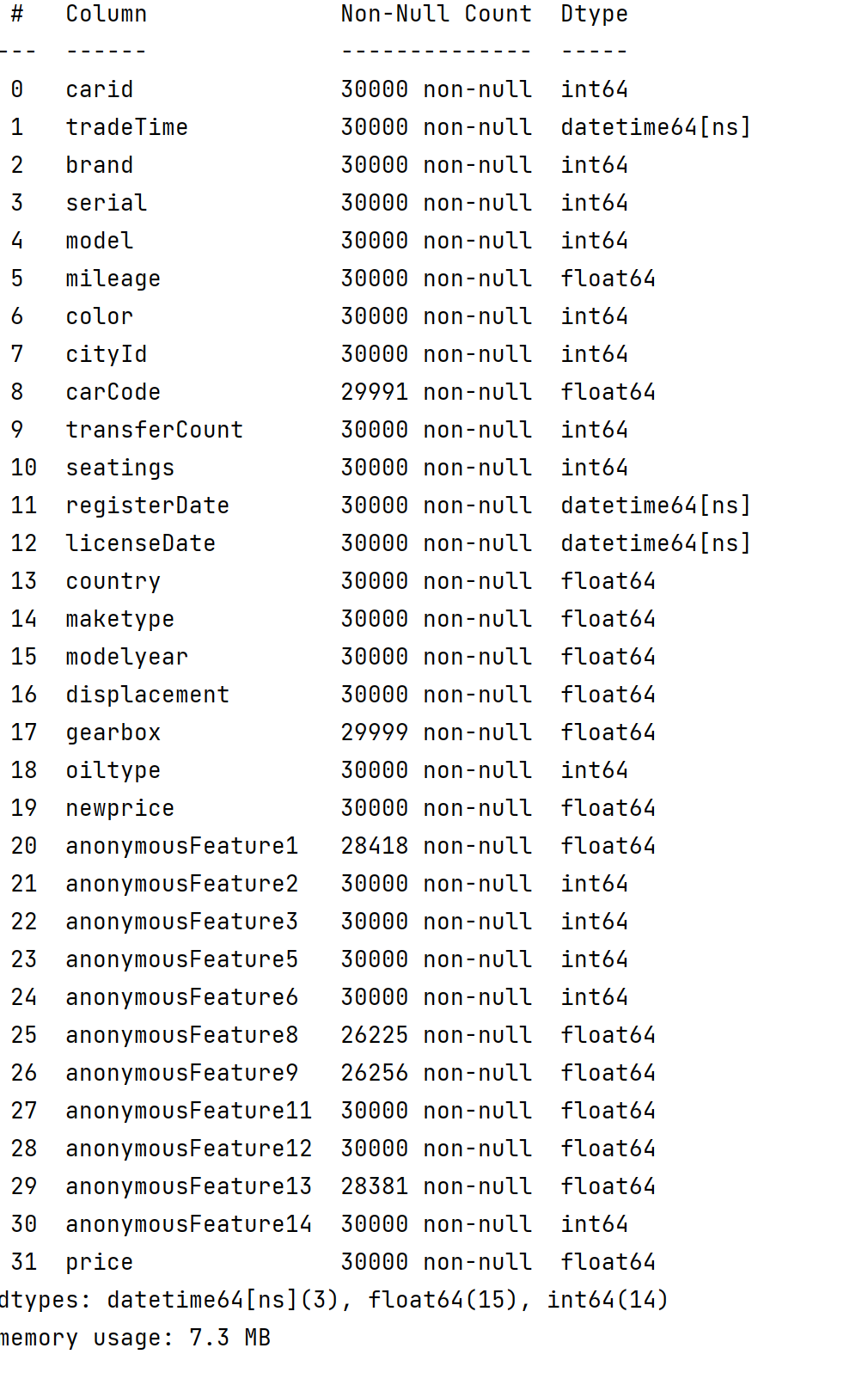
2 查看数据的类型和缺失情况
data.info()
data.isnull().sum()
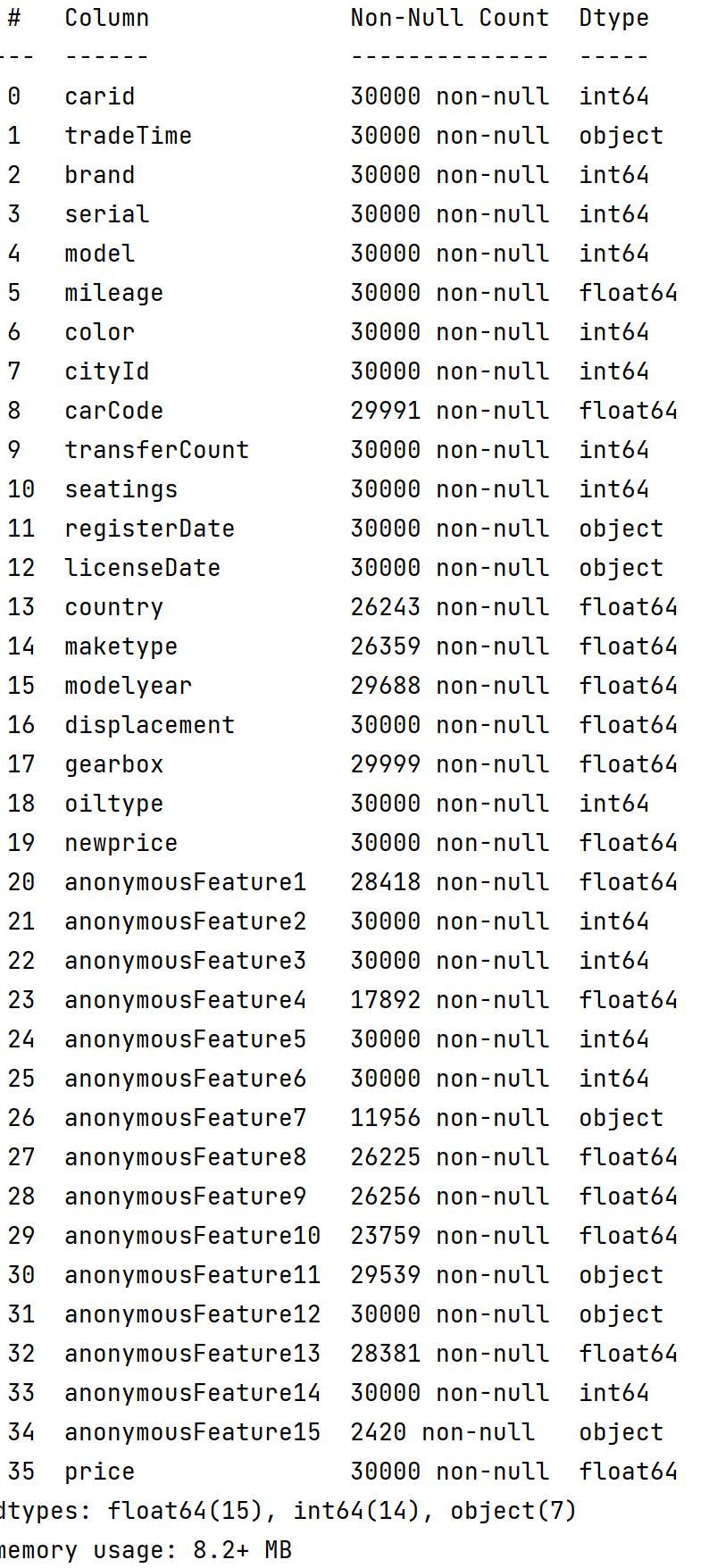

前五列’carid’, ‘tradeTime’, ‘brand’, ‘serial’, ‘model’都是id和时间,不能做中心化操作,而且通过data.iloc[:, :5].isnull().sum()

发现没有缺失值,因此不需要处理。
其他列缺失值的情况
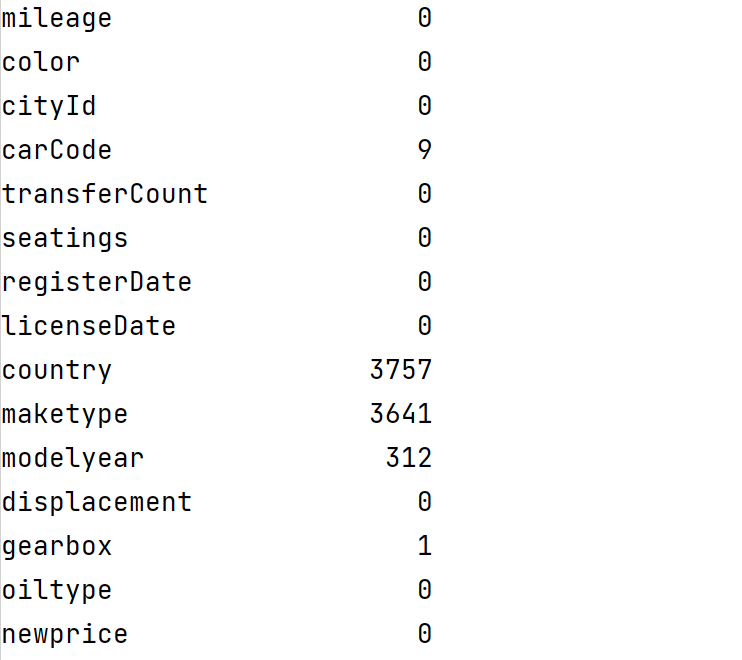
可以看出除了15个匿名特征外,carCode有9个缺失值,country有3757个缺失值maketype有3641个缺失值,modelyear有312个缺失值。gearbox有一个缺失值。
对于缺失值较少的列,如carCode和gearbox直接进行删除操作。country ,maketype 和modelyear由于缺失值较多,根据数据类型,定类数据选择使用众数填充比较适合。
nn_i = ['country', 'maketype', 'modelyear']
for i in nn:
x = int(data[i].mode())
data[i].fillna(x, inplace=True)
data_1[‘country’].unique() 可以发现
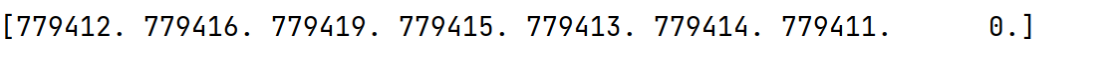
这个0导致数据量纲较大,会对后期模型的性能产生影响,因此结合所给的信息将其改为779410
data.loc[data['country']==0,'country'] = 779410
4.对15个匿名变量的分析
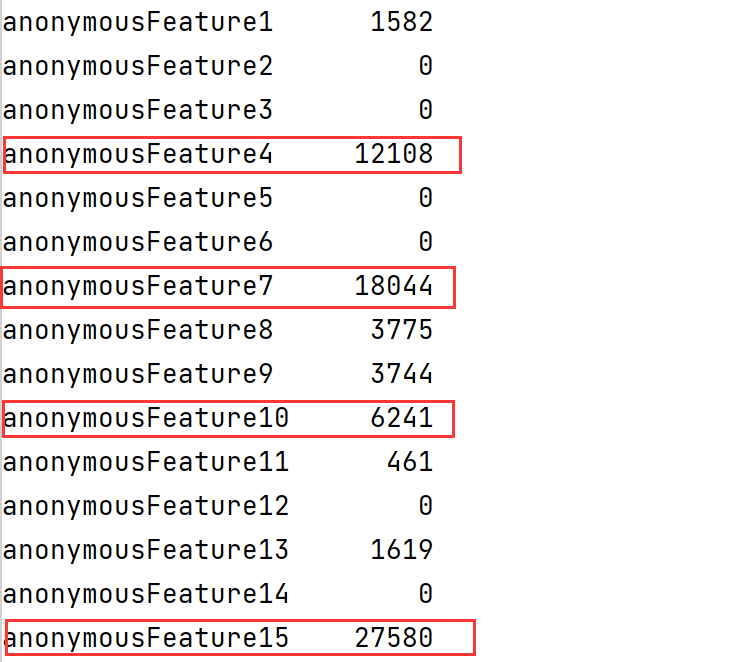
data=data.drop(['anonymousFeature4','anonymousFeature7','anonymousFeature10','anonymousFeature15'
,'anonymousFeature1','anonymousFeature8','anonymousFeature9'],axis=1)
2特征构造
4.1对anonymousFeature11

def deal_11(x):
return sum([float(x) for x in re.findall("\d",x)])
data_1['anonymousFeature11']=data_1['anonymousFeature11'].map(deal_11)
4.2对anonymousFeature12

def deal_12(x):
li=[float(x) for x in re.findall("\d+",x)]
return li[0]*li[1]*li[2]
data_1['anonymousFeature12_length']=data_1['anonymousFeature12'].apply(lambda x:int(x.split('*')[0]))
data_1['anonymousFeature12_width']=data_1['anonymousFeature12'].apply(lambda x:int(x.split('*')[1]))
data_1['anonymousFeature12_height']=data_1['anonymousFeature12'].apply(lambda x:int(x.split('*')[2]))
data_1['anonymousFeature12']=data_1['anonymousFeature12'].map(deal_12)
4.3对anonymousFeature13
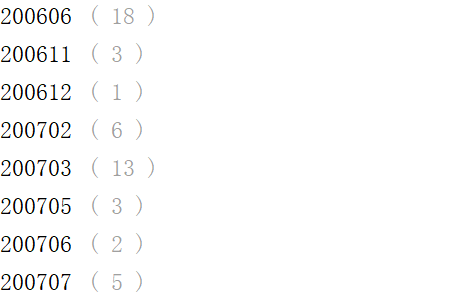
def deal_13(x):
return x[:4], x[4:6]
data_1['anonymousFeature13']=data_1['anonymousFeature13'].astype('string')
data_1['anonymousFeature13_year']=data_1['anonymousFeature13'].map(deal_13)
data_1['anonymousFeature13_month']=data_1['anonymousFeature13_year'].apply(lambda x: int(x[1]))
data_1['anonymousFeature13_year']=data_1['anonymousFeature13_year'].apply(lambda x: int(x[0]))
data_1['anonymousFeature13']=data_1['anonymousFeature13'].astype('float')
经过以上处理,数据已经全部变成数值型特征和时间类型的特征
(5)处理定类特征
对color,carCode,country,modelyear这些类别行的特征,因为是定类数据,数据之间本来应该是没有相对大小的,但是转为数值后比如1,2,3会有相对大小,会对树模型产生不好的影响。因此本组选择使用Frequency编码对定类数据进行转换,Frequency编码通过计算特征变量中每个值的出现次数来表示该特征的信息。
data['color'] = data['color'].map(data['color'].value_counts())
data['carCode'] = data['carCode'].map(data['carCode'].value_counts())
data['modelyear'] = data['modelyear'].map(data['modelyear'].value_counts())
(6)再用时间类型的特征构建新特征
①基础周期特征的拆除(年月日特征拆解)
data['tradeTime_year']=data['tradeTime'].dt.year
data['tradeTime_month']=data['tradeTime'].dt.month
data['tradeTime_day']=data['tradeTime'].dt.day
data['registerDate_year']=data['registerDate'].dt.year
data['registerDate_month']=data['registerDate'].dt.month
data['registerDate_day']=data['registerDate'].dt.day
②时间差
‘old_year’=’tradeTime’-‘registerDate’ (汽车的使用时间)
‘old_year_1’=’tradeTime’-‘licenseDate’
data_1['old_year']=data_1['tradeTime']-data_1['registerDate']
data_1['old_year']=data_1['old_year'].apply(lambda x:str(x).split(' ')[0])
data_1['old_year']=data_1['old_year'].astype(int)
data_1['old_year_1']=data_1['tradeTime']-data_1['licenseDate']
data_1['old_year_1']=data_1['old_year_1'].apply(lambda x:str(x).split(' ')[0])
data_1['old_year_1']=data_1['old_year_1'].astype(int)
经过以上处理后,特征以全部转换成数据值
(7)数值特征的处理
数据分桶,对mileage特征进行数据分桶,mileage的均值为7.14,其余统计量如下

因此分组区间为 (0,1],(1,4],(4,7.15],(7.15,10],(10,50]
bin=[0, 1, 4, 7.15, 10, 50]
data_1['mileage_bin']=pd.cut(data_1['mileage'],bins=bin,labels=False)
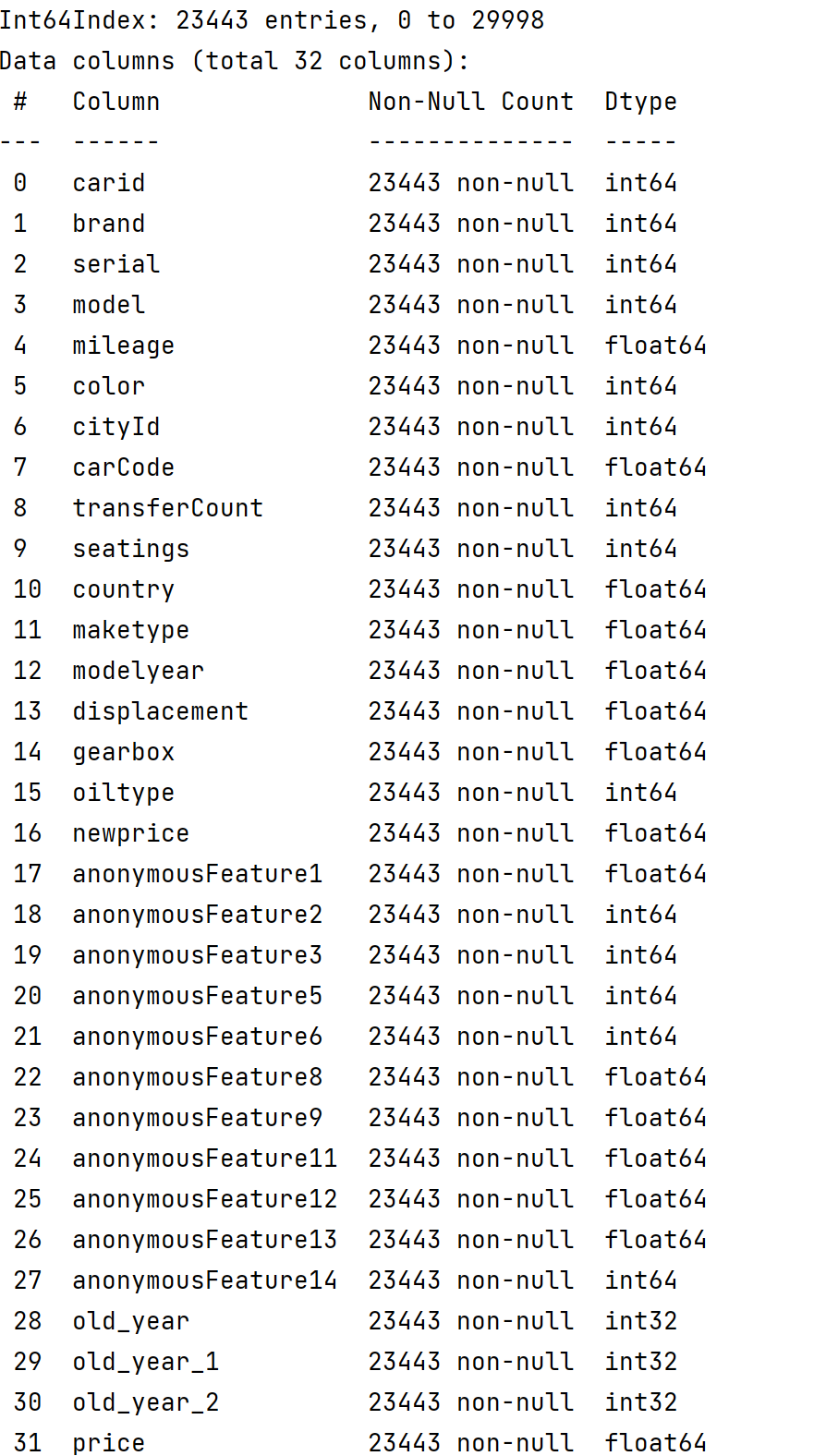
(8)清除数据中的异常值
首先查看数据的分布,找出异常值
data_2.describe()
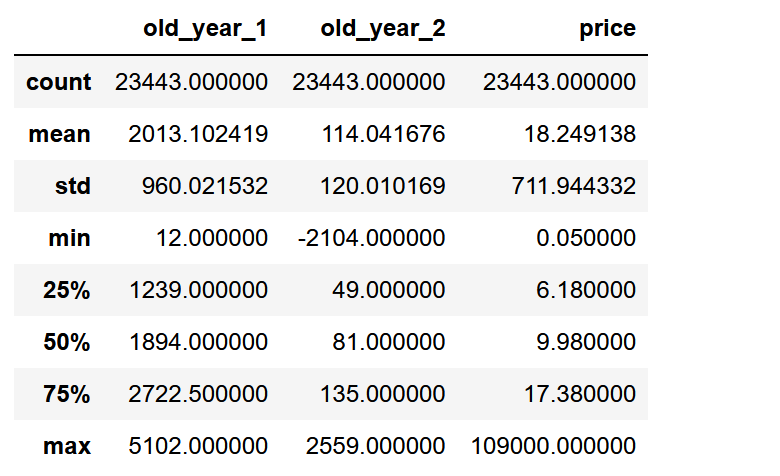
可以明显的看出,price有异常值,接下来用箱线图检测异常值,并构造函数处理异常值
data_2.describe()
data_2=data_2[data_2['price']<80]
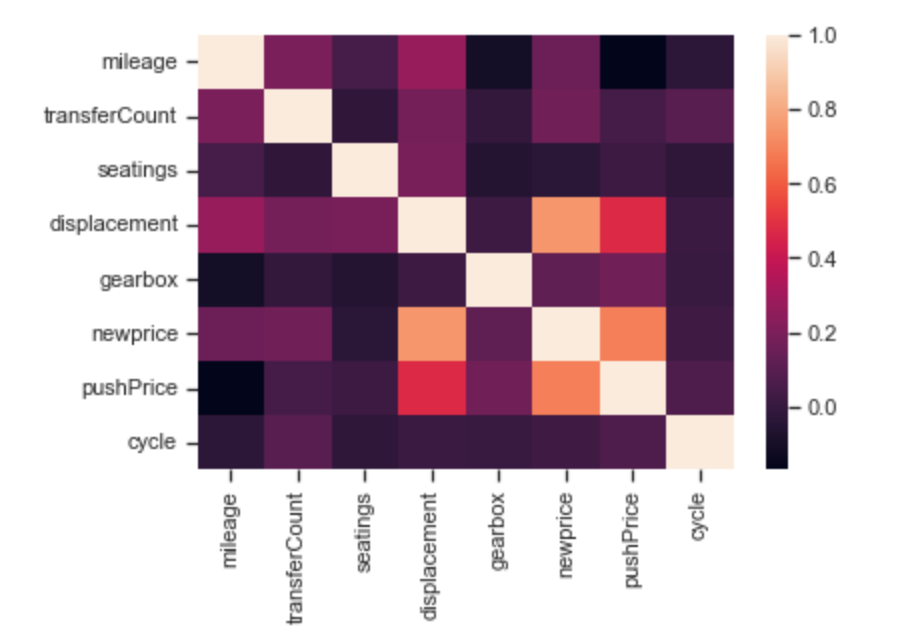
3特征选择
(1)从这些特征中选择出最合适的特征(特征选择),为模型构建做准备。
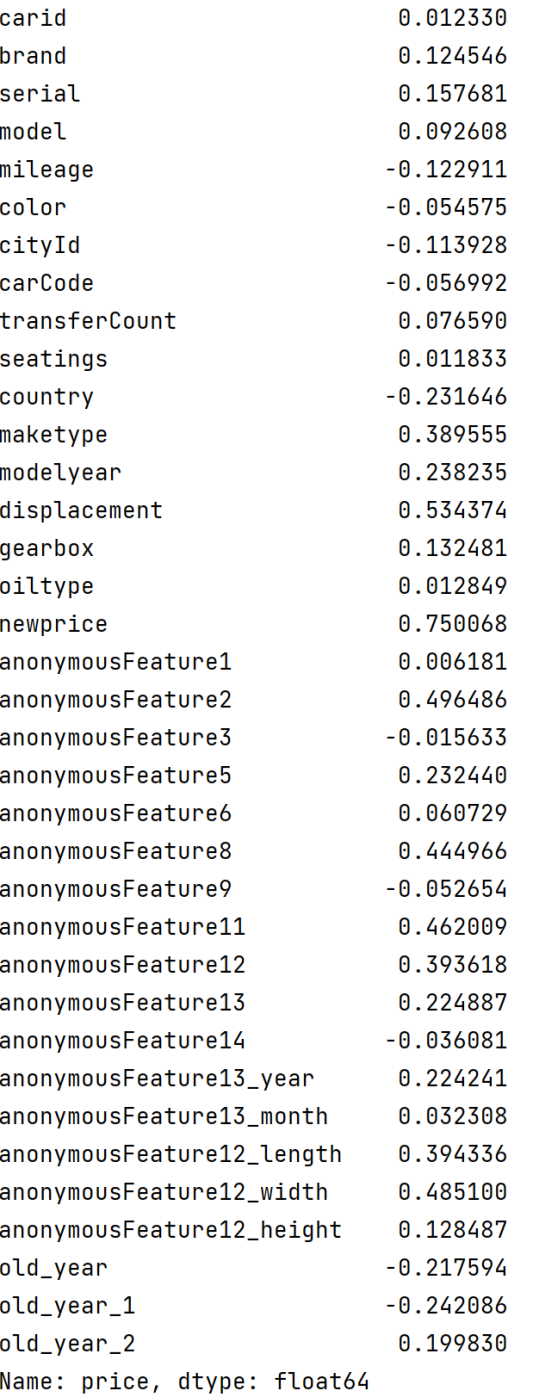
皮尔逊相关系数的特征选择
pearson = data_2.corr()
index = pearson['price'][:-1].abs() > 0.1
X = data_2.iloc[:,:-1]
X_subset = X.loc[:, index]
3模型训练预测
构建评估函数
def estimate(y_true=None,y_pred=None):
y_true=np.array(list(y_true))
y_pred=np.array(list(y_pred))
Ape=np.abs(y_pred-y_true)/y_true
Mape=sum(Ape)/len(y_true)
Ape_count=len(np.where(Ape0.05)[0])/len(Ape)
return 0.2*(1-Mape)+0.8*Ape_count
训练预测
X_train, X_test, y_train, y_test = train_test_split(X_subset,data_2['price'].to_numpy() , test_size=0.2,random_state=3)
random_model = RandomForestRegressor(n_estimators=500,random_state=33,n_jobs=-1)
random_model.fit(X_train,y_train)
y_pred = random_model.predict(X_test)
score = estimate(y_true=y_test,y_pred=y_pred)
以上基本就是初赛的模型构造模型过程,对附件二的预测已经任务二的模型等其他过程这里没有详细描述,完整的代码在附录获取。下面是复赛的模型
复赛
数据分析
导入包,并构造训练集和测试集
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import re
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.feature_selection import SelectKBest
import xgboost as xgb
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
"""
评估数据集的构造
"""
df_5 = pd.read_csv('./data/附件5:门店交易验证数据.txt', sep='\t', parse_dates=[1], header=None, encoding='utf-8')
df_2 = pd.read_csv('../data/附件2:估价验证数据.txt', sep='\t', parse_dates=[1, 11, 12], header=None, encoding='utf-8')
columns = ['carid', 'tradeTime', 'brand', 'serial', 'model', 'mileage', 'color', 'cityId', 'carCode',
'transferCount', 'seatings', 'registerDate', 'licenseDate', 'country', 'maketype', 'modelyear',
'displacement', 'gearbox', 'oiltype', 'newprice']
for i in range(1,16):
columns.append('anonymousFeature'+str(i))
df_2.columns = columns
df_5.rename(columns={0:'carid',1:'pushDate',2:'pushPrice',3:'updatePriceTimeJson'} ,inplace=True)
df_test = pd.merge(df_5, df_2, on='carid', how='left')
"""
训练集的构造
"""
df_1 = pd.read_csv('../data/附件1:估价训练数据.txt', sep='\t', parse_dates=[1, 11, 12], encoding='utf-8', header=None)
df_4 = pd.read_csv('../data/附件4:门店交易训练数据.txt', sep='\t', parse_dates=[1, 4, 5], encoding='utf-8', header=None)
columns.append('price')
df_1.columns=columns
df_4.rename(columns={0:'carid',1:'pushDate',2:'pushPrice',3:'updatePriceTimeJson',4:'pullDate',5:'withdrawDate'},inplace=True)
df_train = pd.merge(df_4, df_1, how='left', on='carid')
df_train['cycle'] = df_train['withdrawDate']-df_train['pushDate']
df_train=df_train.drop(['price', 'pullDate', 'withdrawDate'], axis=1)
df_train['cycle']=df_train['cycle'].astype('timedelta64[D]')
1 任务分析
根据题意,附件1和附件4合并作为训练集,附件5和附件2合并作为测试集根据所给的变量信息,初步判断,tradeTime, registerDate, licenseDate, pushDate,pullDate,withdrawDate为时间类型,因此在读入数据的时就直接通过设置parse_dates参数转化成时间类型(datetime64[ns] )
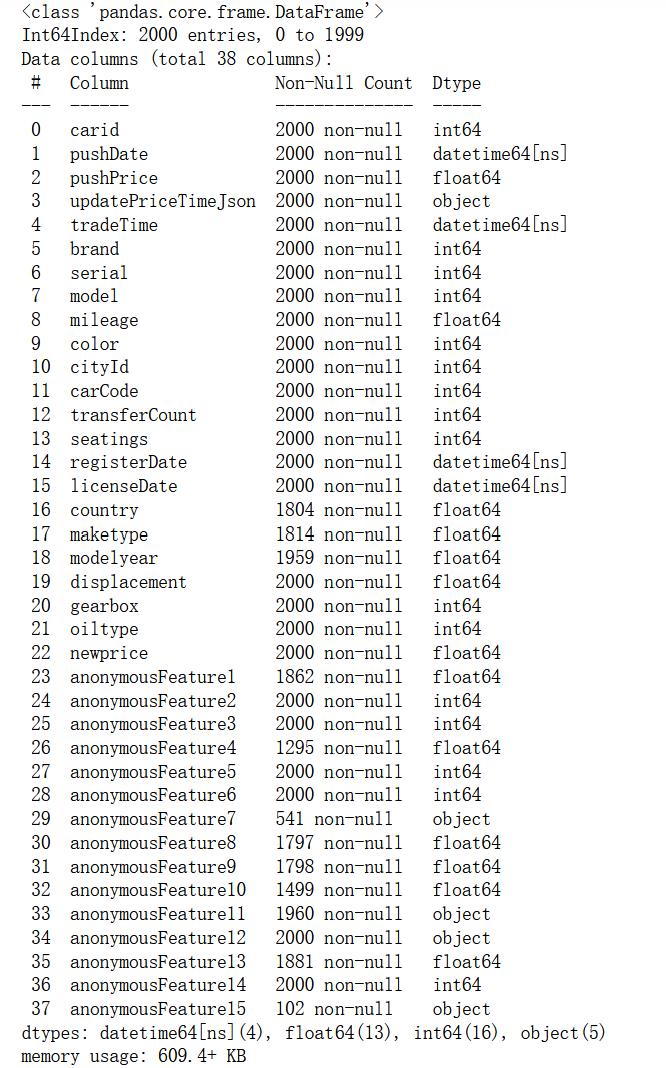
查看训练集的数据情况
df_train.info()

df_test.info()
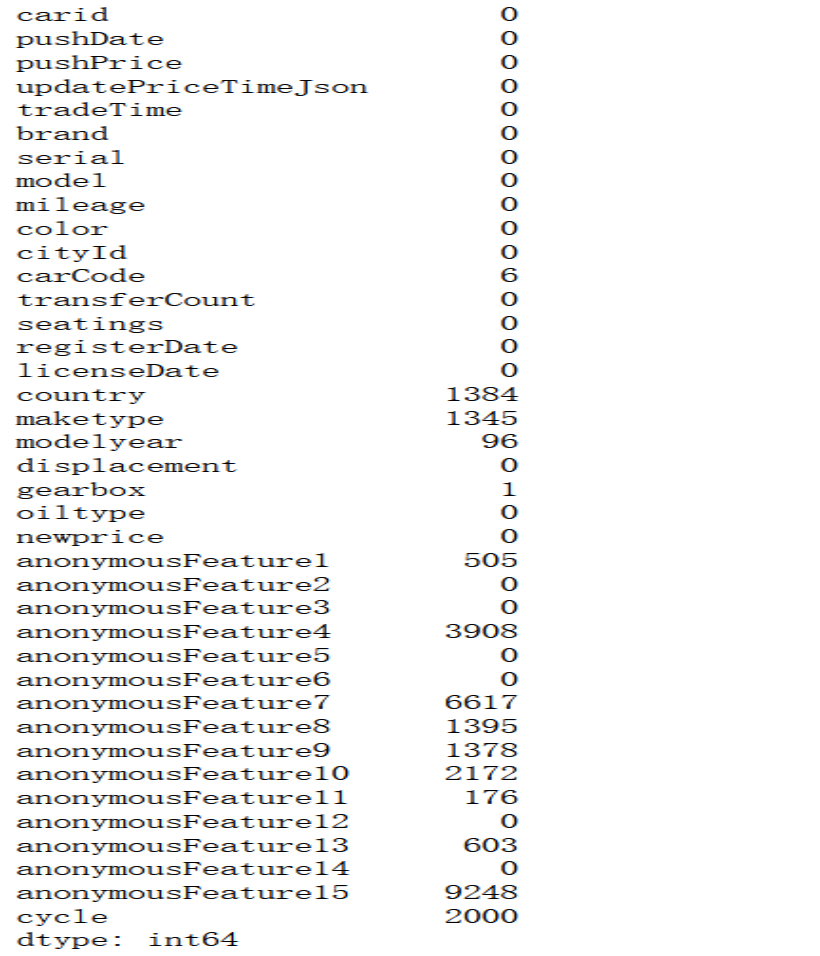
df_train.isnull().sum()
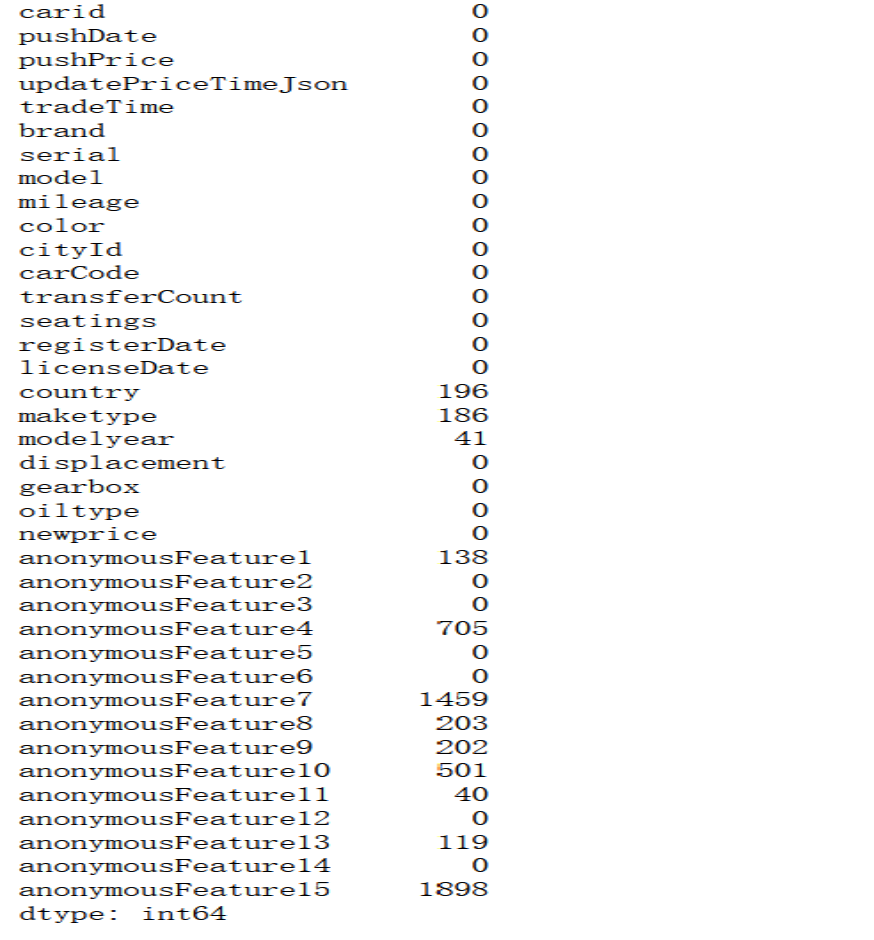
测试集的缺失值
df_test.isnull().sum()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
missing=df_train.isnull().sum()
missing=missing[missing>0]
missing.sort_values(inplace=True)
missing.plot.bar()
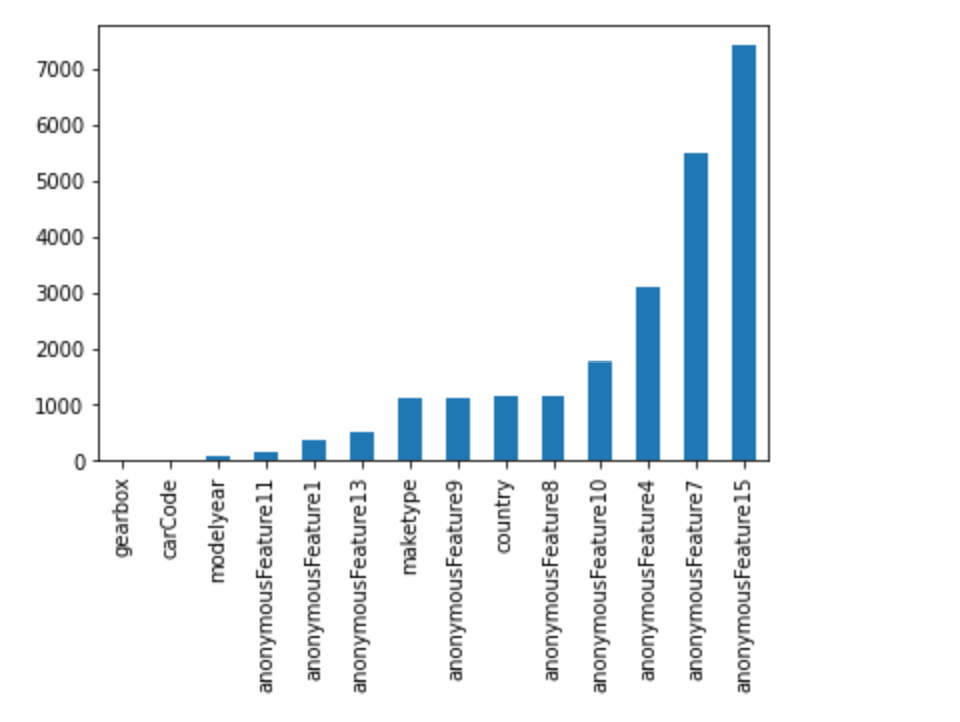
missing=df_test.isnull().sum()
missing=missing[missing>0]
missing.sort_values(inplace=True)
missing.plot.bar()
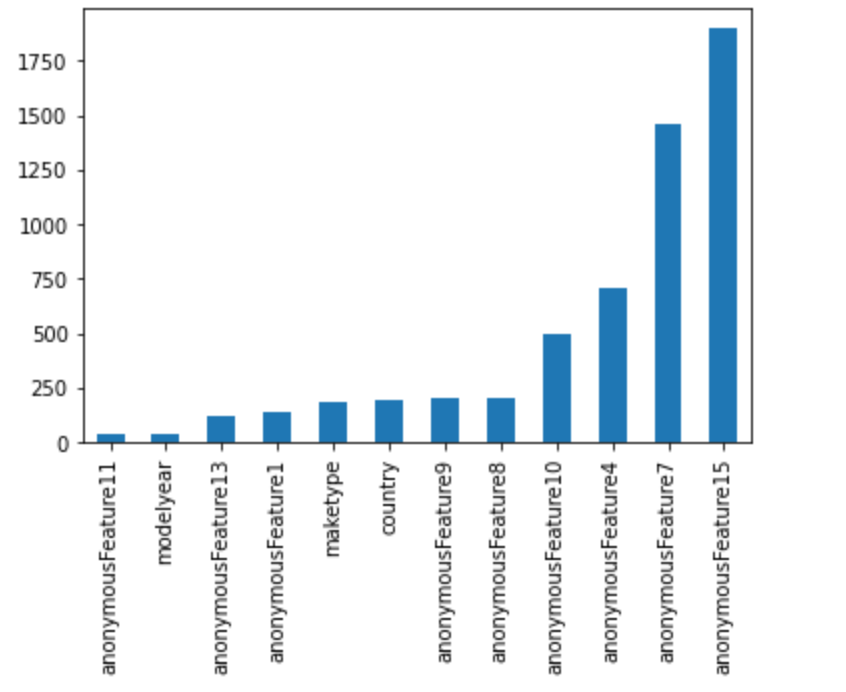
删除nan存在的过多的特征(‘anonymousFeature4′,’anonymousFeature7′,’anonymousFeature15′),
对’anonymousFeature1′,’anonymousFeature8′,’anonymousFeature9′,’anonymousFeature10’
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
columns=['anonymousFeature1','anonymousFeature8','anonymousFeature9','anonymousFeature10']
plt.figure(figsize=(50,50),dpi=80)
for i in range(4):
ax=plt.subplot(2,2,i+1)
ax=sns.kdeplot(df_train[columns[i]],color='red',shade=True)
ax=sns.kdeplot(df_test[columns[i]],color='Blue',shade=True)
ax.set_xlabel(columns[i])
ax.set_ylabel('Frequency')
ax=ax.legend(['train','test'])
plt.savefig('3.png')
plt.show()
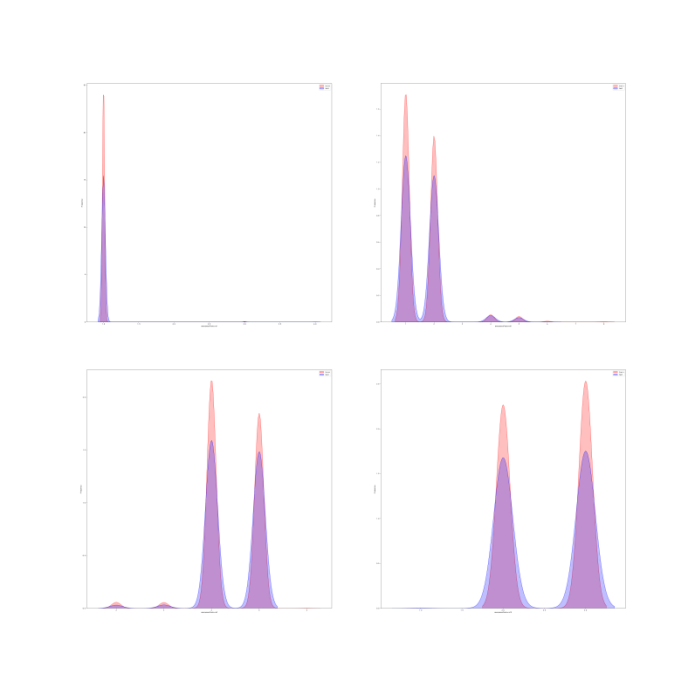
2 删除无用特征
发现anonymousFeature1的严重倾斜,一般不会对预测有什么帮助,故删除
df_train['anonymousFeature1'].value_counts(normalize=True).plot(kind='pie')
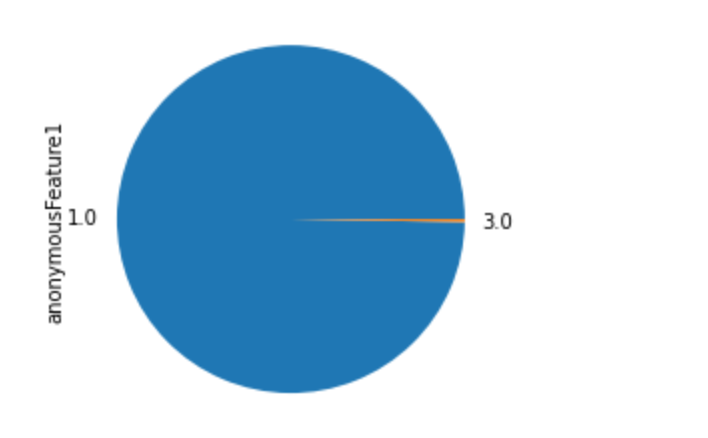
df_train['anonymousFeature1'].value_counts(normalize=True)

anonymousFeature1测试集中的分布占比
df_test['anonymousFeature1'].value_counts(normalize=True)

都出现了严重的倾斜,因此考虑直接删除此特征
3 修改异常值
country里的0根据分析应改为779410
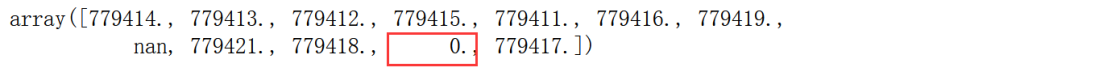
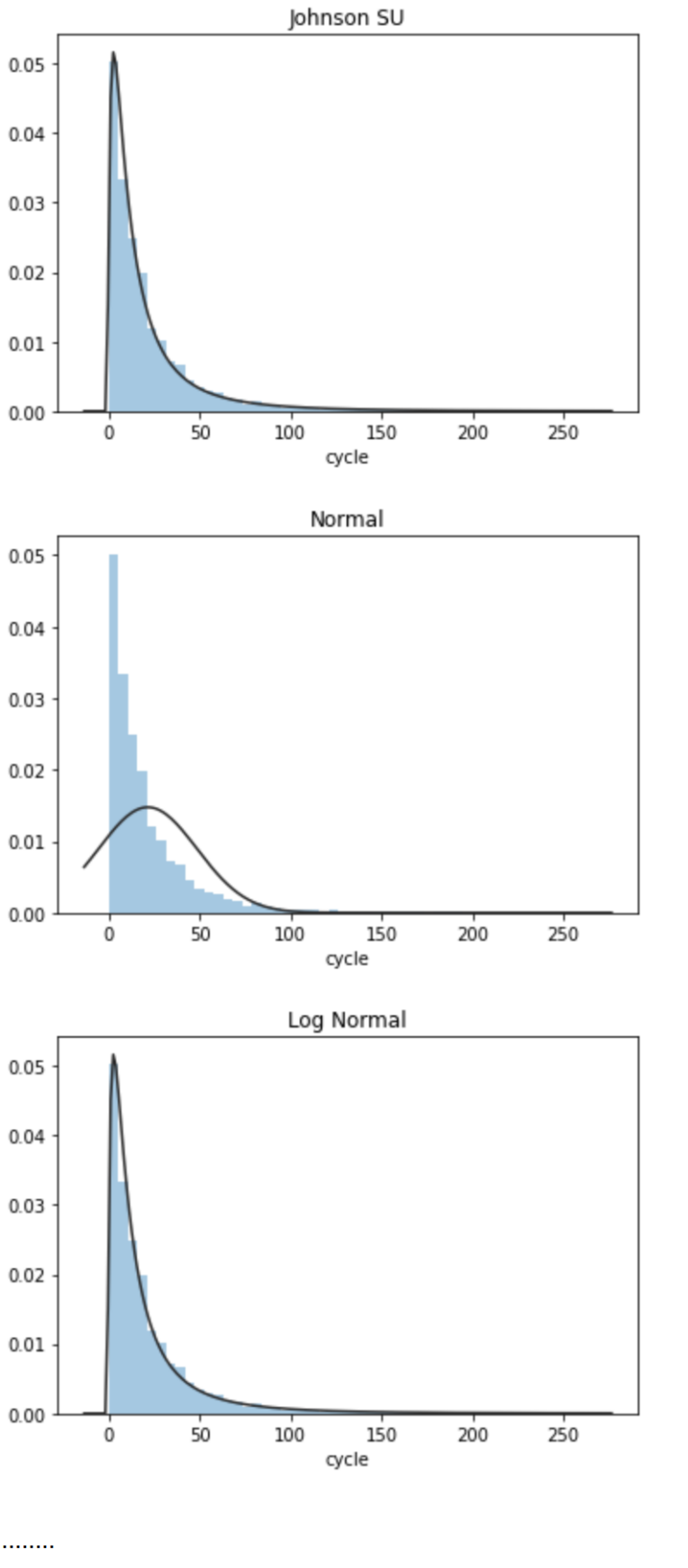
import scipy.stats as st
y = df_train['cycle']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
plt.savefig('13.jpg')
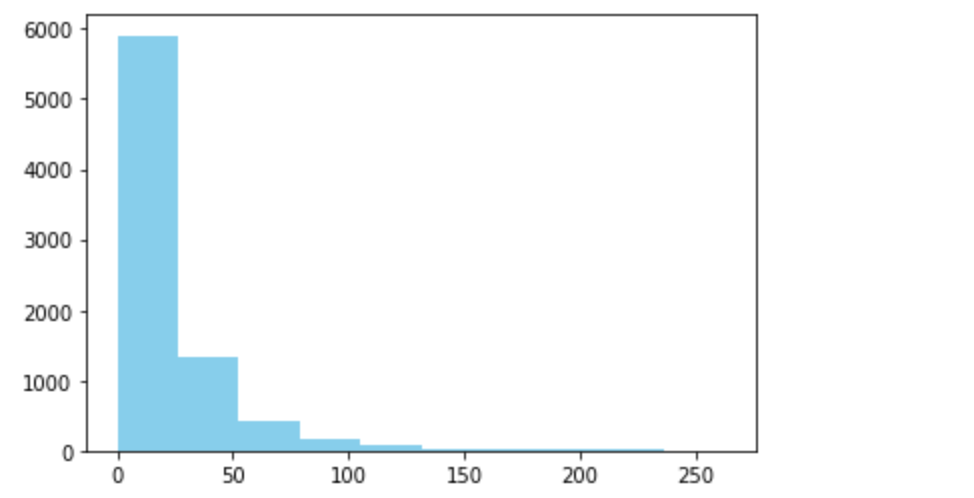
查看预测值的频次分布
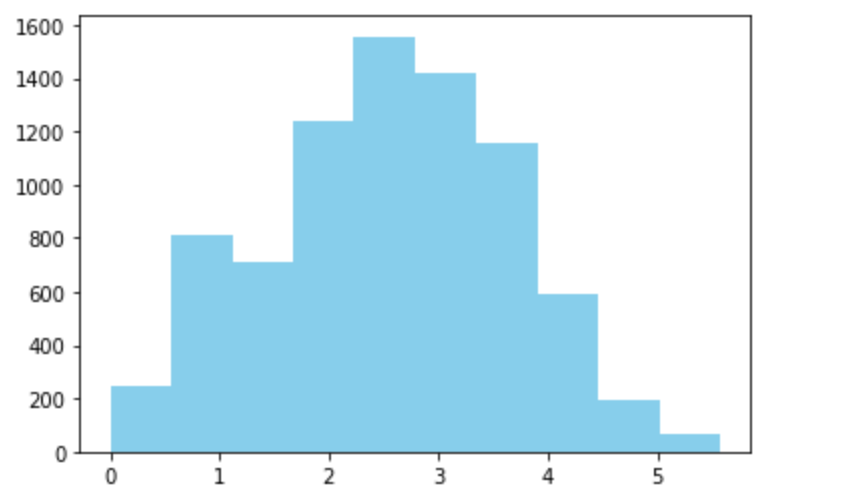
进行log变换之后的分布较均匀
plt.hist(np.log(df_train['cycle'].values+1), orientation = 'vertical',histtype = 'bar', color ='skyblue')
plt.show()
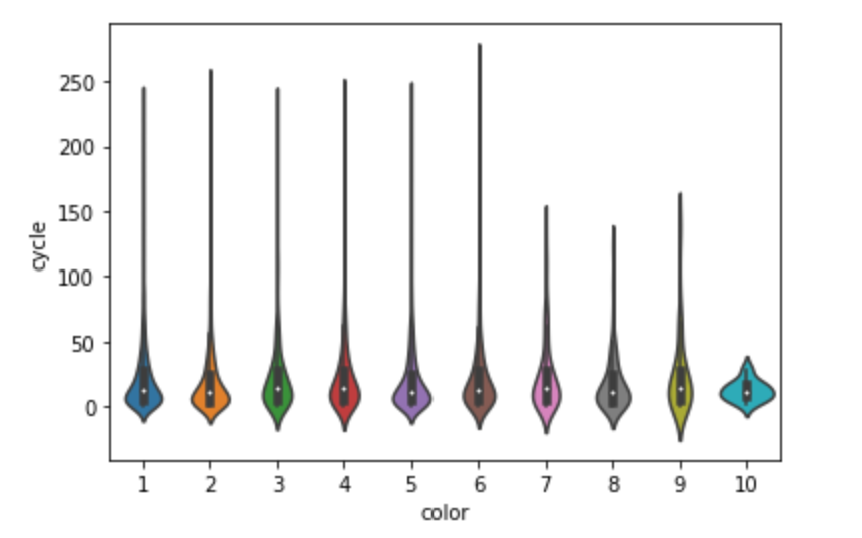
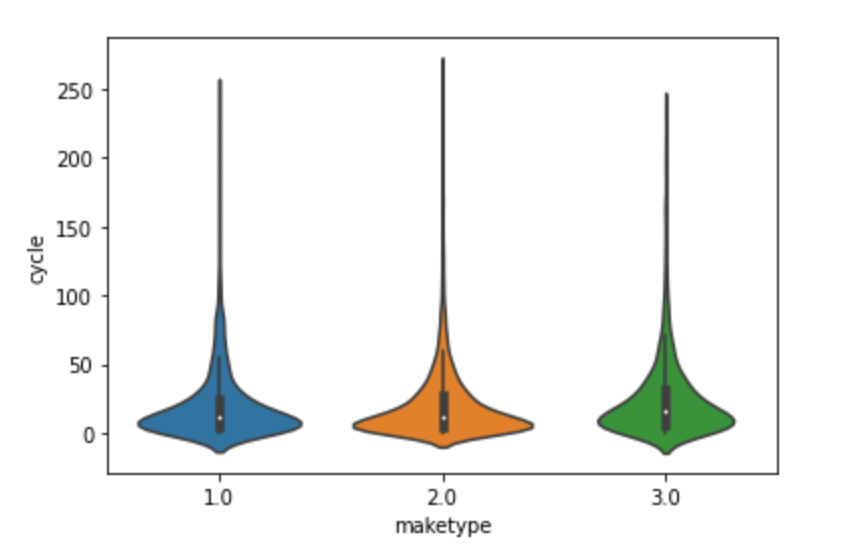
6 类别特征与cycle(成交周期)的关系
可以通过小提琴图来观测类别变量在不同类别时,cycle的分布情况
feature_num=['mileage','transferCount','seatings','displacement','gearbox','newprice','pushPrice','cycle']
feature_class=['brand','serial','model','color','cityId','carCode','country','maketype','modelyear','oiltype']
class_list = feature_class
for cla in class_list :
sns.violinplot(x=cla, y='cycle', data=df_train)
plt.show()
特征工程
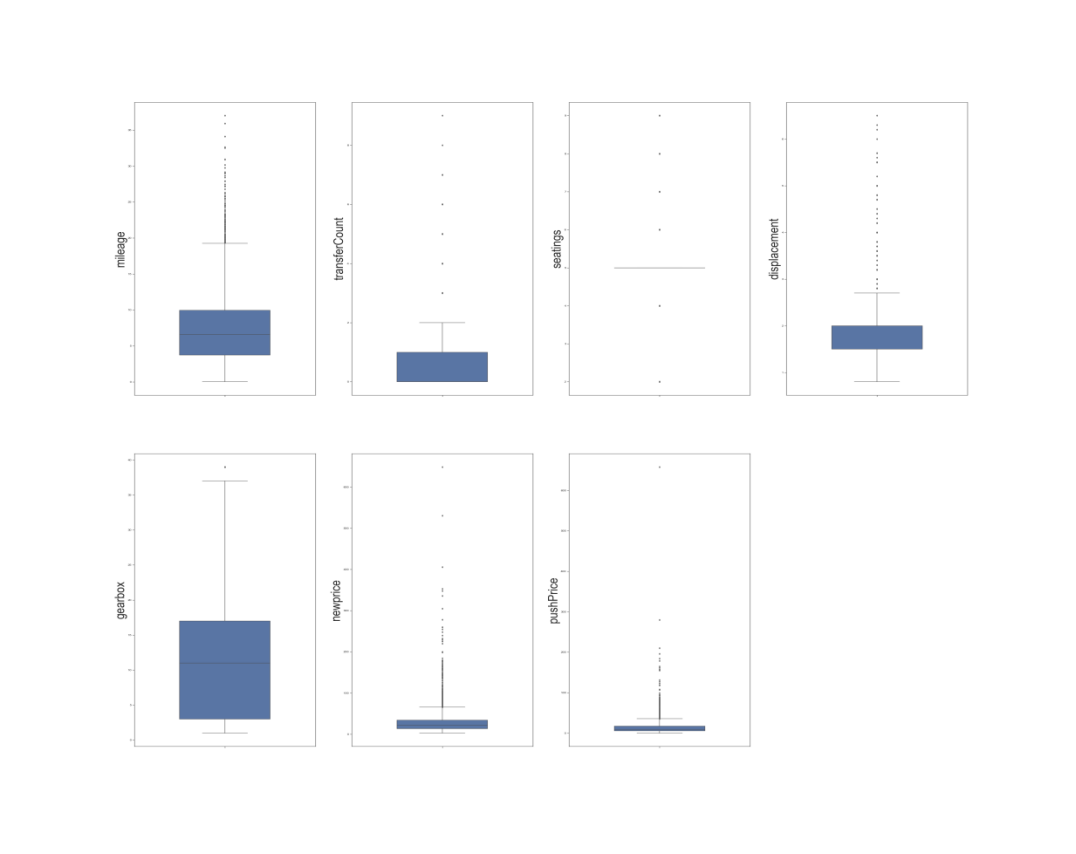
1对定量数据检测异常值
‘mileage’,’transferCount’,’seatings’,’displacement’,’gearbox’,’newprice’,’pushPrice’
nn=['mileage','transferCount','seatings','displacement','gearbox','newprice','pushPrice']
fig=plt.figure(figsize=(50,50),dpi=80)
for i in range(7):
ax=plt.subplot(2,4,i+1)
ax=sns.boxplot(y=df_train[nn[i]],orient='v',width=0.5)
plt.ylabel(nn[i],fontsize=44)
plt.savefig('4.png')
plt.show()
2构造新的特征
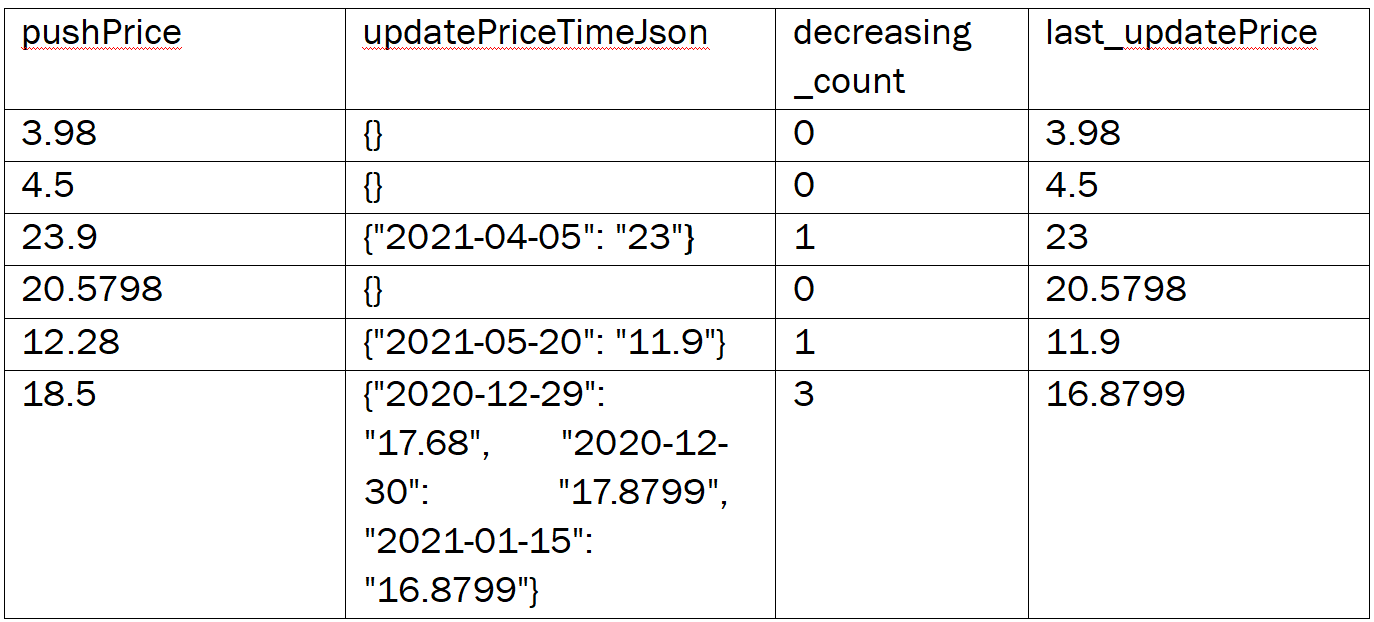
last_updatePrice:最终的价格
def f(x):
if re.findall(': ".+?"',str(x)):
res=re.findall(': ".+?"',str(x))[-1]
a=res.replace('"','').replace(':','').replace(' ','')
a=float(a)
else:
a=0.0
return a
"""
求出最终的价格
"""
df_train['last_updatePrice']=df_train['updatePriceTimeJson'].map(f)
df_train.loc[df_train['last_updatePrice']==0.0000,'last_updatePrice']=df_train.loc[df_train['last_updatePrice']==0.0000,'pushPrice']
df_test['last_updatePrice']=df_test['updatePriceTimeJson'].map(f)
df_test.loc[df_test['last_updatePrice']==0.0000,'last_updatePrice']=df_test.loc[df_test['last_updatePrice']==0.0000,'pushPrice']
降价次数
def deal(data=None):
li=[]
for i in data.index:
count=len(re.findall('\d+-\d+-\d+',str(data.loc[i,'updatePriceTimeJson'])))
li.append(count)
return li
df_train['decreasing_count']=deal(df_train)
3 构造其他特征
对anonymousFeature11,anonymousFeature12,anonymousFeature13,old_year,old_year_1的处理与上文相同,这里不再进行累述
4基础周期特征的拆除
df_train['pushDate_year'] = df_train['pushDate'].dt.year
df_train['pushDate_month'] = df_train['pushDate'].dt.month
df_train['pushDate_day'] = df_train['pushDate'].dt.day
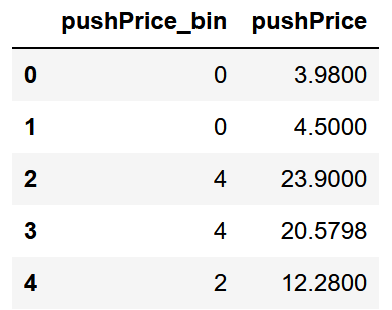
5 对连续数据进行分箱处理
bin = [i*5 for i in range(9)]
df_train['pushPrice_bin'] = pd.cut(df_train['pushPrice'], bin, labels=False)
df_test['pushPrice_bin'] = pd.cut(df_test['pushPrice'], bin, labels=False)
建模预测
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7)
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbm
lightGBM
print('Train lgb...')
model_lgb = build_model_lgb(X_train,y_train)
val_lgb = model_lgb.predict(X_test)
val_lgb=np.expm1(val_lgb)
MAE_lgb = mean_absolute_error(y_test,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_submit,y)
subA_lgb = model_lgb_pre.predict(X_)
subA_lgb=np.expm1(subA_lgb)

XGboost
print('Train xgb...')
model_xgb = build_model_xgb(X_train,y_train)
val_xgb = model_xgb.predict(X_test)
val_xgb=np.expm1(val_xgb)
MAE_xgb = mean_absolute_error(y_test,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_submit,y)
subA_xgb = model_xgb_pre.predict(X_)
subA_xgb=np.expm1(subA_xgb)
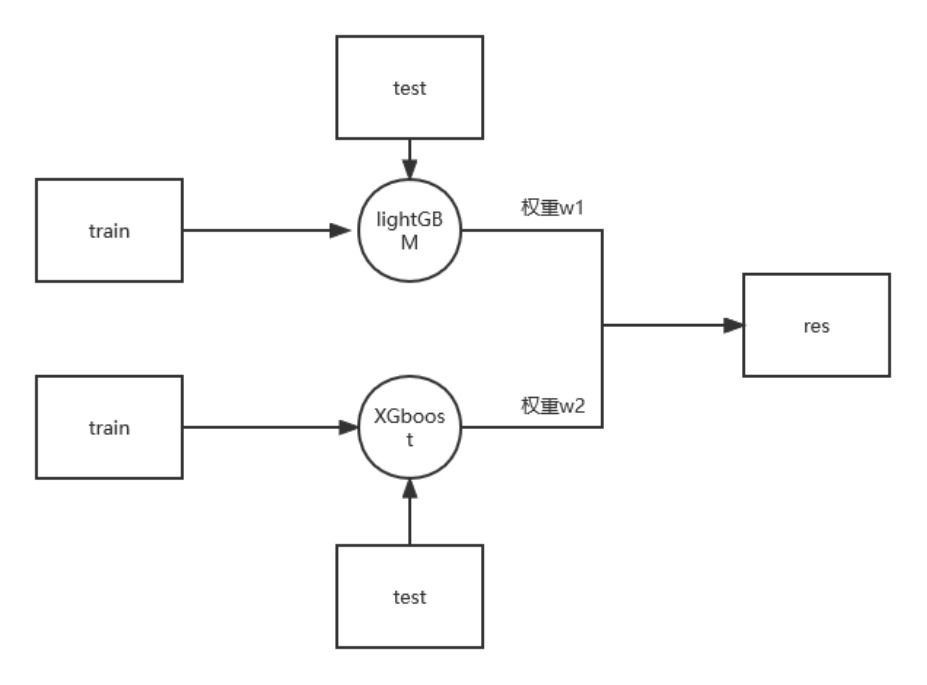
模型融合,
简单加权
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb

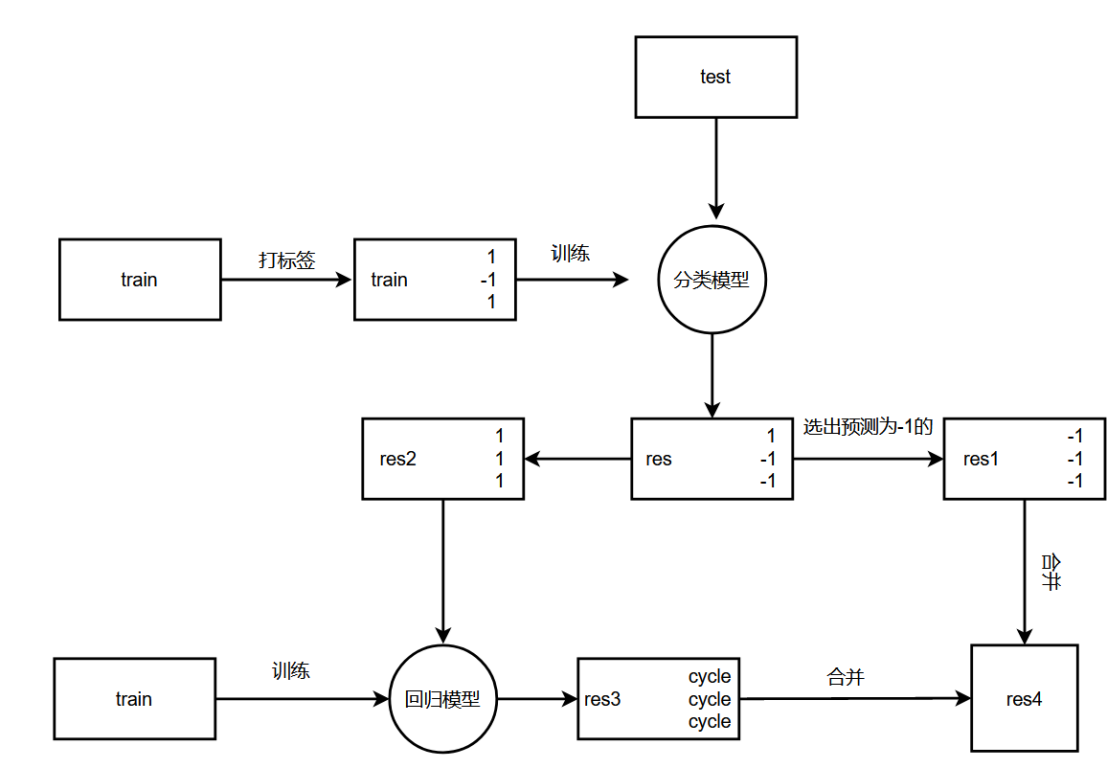
先建立一个分类模型,对卖出去和卖不出去(成交时间为空)的进行分类,将卖不出去的周期设置成-1,然后把能卖出的数据进行回归预测,最后将结果合并。
附录:
初赛:完整的代码及论文
链接:https://pan.baidu.com/s/1IV4Ii98OIdnNh5hPxrQGYg
提取码:yrvu
复赛:建模代码及论文
链接:https://pan.baidu.com/s/1of0aGBbS0Ze5zzil7dBxOA
提取码:v1jq
Original: https://blog.csdn.net/m0_52118763/article/details/124183371
Author: 开始King
Title: 2021年MathorCup高校数学建模挑战赛——大数据竞赛赛道A -思路分享
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/629750/
转载文章受原作者版权保护。转载请注明原作者出处!