

Zero&R2D2:大规模中文跨模态基准和视觉语言框架
《Zero and R2D2:A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework》
论文地址:https://arxiv.org/pdf/2205.03860.pdf
相关博客:
【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
一、简介
视觉语言预训练( Vision-language pre-training,VLP ) (\text{Vision-language pre-training,VLP})(Vision-language pre-training,VLP )在各种的多模态下游任务中取得了巨大的成功。一般来说,VLP \text{VLP}VLP主要会学习视觉和语言的语言相关性。许多工作探索了VLP \text{VLP}VLP模型,并通过大规模的数据、Transformer \text{Transformer}Transformer这样优秀的架构、像CLIP \text{CLIP}CLIP这样的跨模态模态、硬件设备等显著的改善了各种视觉语言任务。在本文中,作者专注在大规模视觉语言数据和跨模态学习。
大规模的图像和英文文本的输入有利用VLP \text{VLP}VLP模型在下游任务的表现。然而,当前具有中文描述的视觉语言数据集存在着一些限制。举例来说,M6-Corpus \text{M6-Corpus}M6-Corpus是一个用于预训练的多模态数据集,但是目前仍然不可用。Wukong \text{Wukong}Wukong是一个用于研究中文跨模态预训练的上亿规模的数据集。虽然他们将AIC-ICC \text{AIC-ICC}AIC-ICC和MUGE \text{MUGE}MUGE这样的下游数据集与预训练合并,但是仅专注在检索任务中,并不足以构造中文的视觉语言 benchmark。另一方面,一些工作尝试翻译英文的跨模态下游数据集,像Flickr30k-CN \text{Flickr30k-CN}Flickr30k-CN。然而,它们并不包括中文成语且包含错误。从这方面来看,如何构造一个完整、公平且具有高质量中文描述的中文跨模块基准是一个待解决的问题。
本文中,作者创造了一个大规模中文跨模态基准Zero \text{Zero}Zero,包含两个预训练数据集以及5个下游数据集。具体来说,预训练数据集由一个完整的2300万版本和230万子集版本构成。完整的预训练数据集包含图像和对应的文本描述,其是通过用户的CTR \text{CTR}CTR从50亿 image-text对过滤得到的。此外,作者还提供了5个高质量的下游数据集,用于图像文本检索和图像文本匹配任务。此外,作者还提供了一个全面且人工翻译的数据集Flickr30k-CNA \text{Flickr30k-CNA}Flickr30k-CNA。
从跨模态学习的角度来看,现有的方法主要是通过预训练来探索图像和文本的关联。UNIMO \text{UNIMO}UNIMO设计了一种 single-stream框架来在大规模 image-text数据集上执行预训练任务。CLIP \text{CLIP}CLIP则设计了 dual-stream来进行视觉语言表示学习。然而,两种方法都具有相同的缺点。 single-stream架构通过少量的线性投影学习图像和文本嵌入的细粒度交互。另一方面,在 dual-stream架构中,对图像和文本之间的细粒度关联进行建模非常重要,因为相应的嵌入位于它们自己的语义空间中。需要注意,一些 image-text预训练数据可能包含噪音且不正确,这将会未到VLP \text{VLP}VLP模型。
在文本中,作者提出了一个称为R2D2 \text{R2D2}R2D2的新颖预训练框架进行跨模态学习。受推荐系统和在线广告的启发,R2D2 \text{R2D2}R2D2应用全局对比预排序(global contrastive pre-ranking) \text{(global contrastive pre-ranking)}(global contrastive pre-ranking)来获得 image-text表示,以及细粒度排序(fine-grained ranking) \text{(fine-grained ranking)}(fine-grained ranking)来增强预训练模型的能力。此外,作者还在R2D2 \text{R2D2}R2D2中引入了两路蒸馏,来增强预训练模型的能力。这两类蒸馏是由 target-guided distillation和 feature-guided distillation组成的。具体来说, target-guided distillation增加了模型从噪音标签中学习的鲁棒性,而 feature-guided distillation的目标是改善R2D2 \text{R2D2}R2D2的泛化性能。总的来说,主要贡献如下:
- 作者提出了中文视觉语言benchmark Zero \text{Zero}Zero,包含两个预训练数据集和5个下游任务数据集。作者使用5个测试集构建了一个
leaderboard,其允许研究人员进行公平的比较,并促进中文视觉语言学习的发展。 - 作者提出了一个新颖的跨模态学习框架R2D2 \text{R2D2}R2D2。具体来说,提出了pre-Ranking+Ranking \text{pre-Ranking+Ranking}pre-Ranking+Ranking策略更好的学习视觉语言表示,以及两路蒸馏来进一步增强学习能力。
- 本文提出的方法在4个公开跨模态数据集以及5个下游数据集上实现了
state-of-the-art。
二、数据集
1. 预训练数据集:Zero-Corpus
现有的数据集收集方法存在两个主要的限制。第一,从第三方搜索引擎或者网站收集到的 image-text对存在大量的噪音。第二,由于图像仅对应一个文本,因此收集到的文本数据缺乏多样性。为了克服这些缺点,作者建立了一个新的中文 image-text预训练数据集,称为Zero-Corpus \text{Zero-Corpus}Zero-Corpus。特别地,从图像搜索引擎收集的50亿个 image-text中抽取2300万个 image-text对。抽取的关键依据是最高的用户CTR \text{CTR}CTR,其表明同一个 query下,用于点击最多的图片。此外,作者还移除了不适合的图像和有害的文本描述。基于这种方法,能够减轻大规模数据中的噪音,并或者最相关和高质量的 image-text对。此外,作者还为每个图像提供多种文本信息,即 Title、 Content、 ImageQuery、 Click和 Show。为了便于消融实验,构造了一个包含230完 image-text对的小预训练数据集,其是2300完数据集的子集。
2. 下游数据集。
相较于英文的下游数据集,中文文本的下游数据集较少。作者使用搜索引擎来构造4个中文 image-text数据集,称为ICM \text{ICM}ICM、IQM \text{IQM}IQM、ICR \text{ICR}ICR和IQR \text{IQR}IQR。在这些下游数据集中,每个图像仅有一个文本对应。对于每个数据集,按照比例8:1:1来划分训练集、验证集和测试集。15个数据注释员标注了所有的 image-text对。此外,作者还提供了人工翻译的高质量数据集Flickr30k-CNA \text{Flickr30k-CNA}Flickr30k-CNA,其是由6个中英文专家人工翻译Flickr30j \text{Flickr30j}Flickr30j得到的。
- Image-Caption Matching Dataset(ICM) ICM \text{ICM}ICM是一个用于图像文本匹配的数据集。每个图像都有对应的文本,其详细的描述了图像。首先使用点击数量来过滤较少相关的对,然后数据标准者会人工执行第二次过滤,或者400000个
image-text对,包含200000个正样本和200000个负样本。 - Image-Query Match(IQM) 这是另一个图像文本匹配任务数据集。不同于ICM \text{ICM}ICM,其使用搜索的
query,而不是详细的描述文本。在这个数据集中,作者随机选择候选集中的queries,然后执行数据清洗流程。类似地,IQM \text{IQM}IQM包含200000个正样本和200000负样本。 - Image-Caption Retrieval Dataset(ICR) 在这个数据集中,使用ICM \text{ICM}ICM中描述的规则收集了200000个
image-text对。它包括image-to-text检索和text-to-image检索。 - Image-Query Retrieval Dataset(IQR) IQR \text{IQR}IQR用于图像文本检索任务。类似于IQM \text{IQM}IQM,随机挑选
queries和对应的图片作为标注的样本对。总量是200000。 - Flickr30k-CNA Dataset Flickr30k-CN \text{Flickr30k-CN}Flickr30k-CN使用机器翻译翻译了Flickr30k \text{Flickr30k}Flickr30k的训练集和验证集,并人工翻译了测试集。作者检测了机器翻译的中文语句并发现了三种类型的问题。(1) 一些句子有语言问题和翻译错误;(2) 一些句子语义较少;(3) 翻译的句子在文本语法上存在错误。此外,训练集和测试集采用不同的翻译方法阻碍模型实现更好的效果。作者汇集了6个中英文语言专家来对Flickr30k \text{Flickr30k}Flickr30k的所有数据进行重新翻译,并对每个句子进行了复查。作者称一个数据集为Flickr30k-Chinese All \text{Flickr30k-Chinese All}Flickr30k-Chinese All。
三、方法
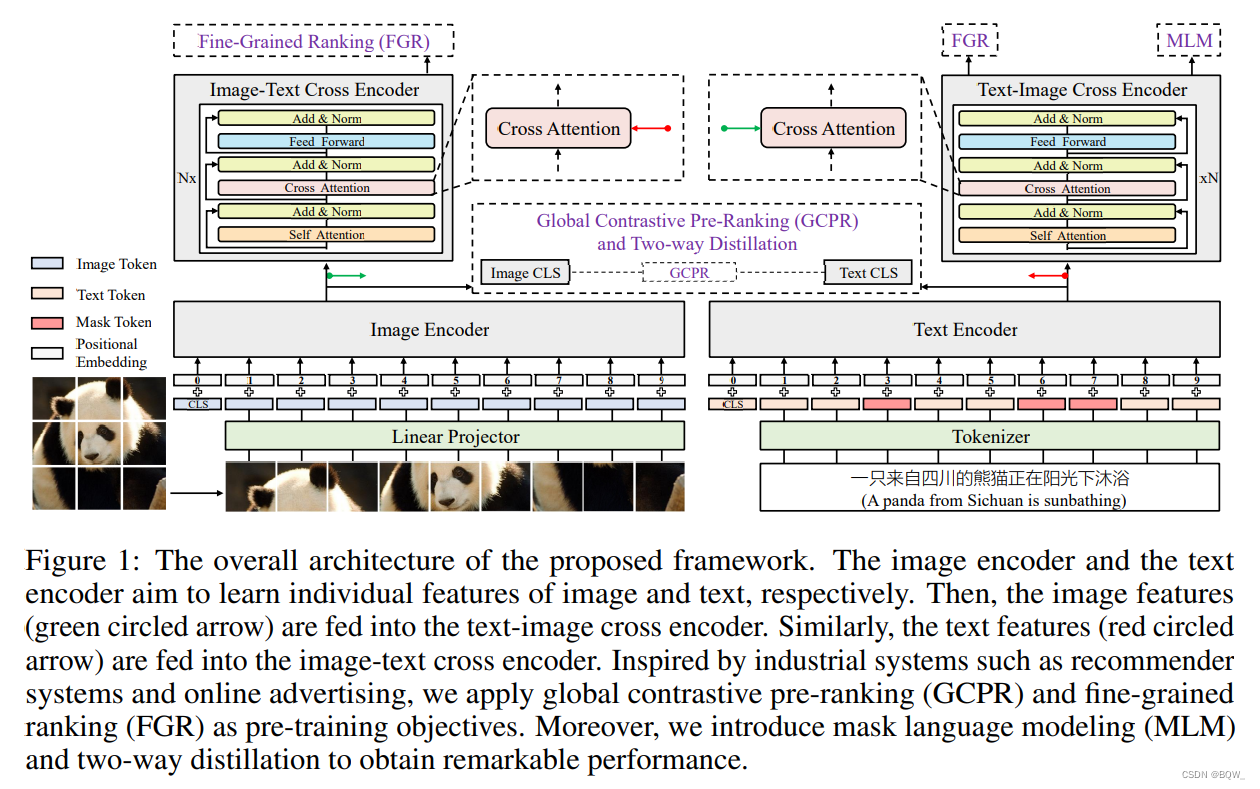

; 1. 模型结构
如上图所示,R2D2 \text{R2D2}R2D2包含了一个文本编码器、一个图像编码器和两个跨模态编码器。文本编码器和图像编码器将输入的文本和图像转换为 hidden state的序列。然后文本和图像的 hidden state在两个交叉编码器中进行交互。
- 文本编码器 应用BERT \text{BERT}BERT编码器作为文本编码器。给定一个文本序列,首先使用RoBERTa-wwm-ext \text{RoBERTa-wwm-ext}RoBERTa-wwm-ext的
tokenizer进行tokenize。这里,特殊的token T [ C L S ] \text{T}{[CLS]}T [C L S ]被添加了序列开端,并且[ S E P ] [SEP][SEP ]被添加在末尾。然后,将所有的token序列输入至文本编码器。随后,T [ C L S ] T{[CLS]}T [C L S ]的输出向量被用于文本序列的表示。 - 图像编码器 对于图像编码器,采用Vision Transformer(ViT) \text{Vision Transformer(ViT)}Vision Transformer(ViT)。首先将图像缩放为标注的尺寸并将图像划分为
patches。每个patch被线性投影并添加为位置嵌入。此外,一个可学习的I [ C L S ] \text{I}_{[CLS]}I [C L S ]被拼接子patch向量上。这个序列向量会被输入至标准的Transformer \text{Transformer}Transformer模型中来获得图像的hidden state向量列表。 - 交叉编码器 这里使用6层的Transformer \text{Transformer}Transformer作为交叉编码器,图像和文本的
hidden vectors被融合并输入至交叉编码器。特别地,线性投影层被用于改变每个图像特征和文本特征的维度,使其保证一致。然后,融合图像和文本hidden vectors作为两个交叉编码的输入。多层Transformer \text{Transformer}Transformer使用交叉注意力来融合两种模态的特征信息,并产生了最终的交叉模态输出。
2. 预训练方法
- Global Contrastive Pre-ranking 传统的对比学习目标是对齐多模态数据的表示。其最大化正样本对的相似分数,并最小化负样本对的分数。实践中,作者使用全局对比学习来完成
pre-ranking任务。当最小化负样本对分数时在k k k个GPUs \text{GPUs}GPUs上执行反向传播。对于每个图像I i \text{I}i I i 和对应的文本T i \text{T}_i T i ,image-to-text和text-to-image的相似分数定义为
s ( I i , T i ) = exp ( sim ( I i , T i ) / τ ) ∑ j = 1 n × k exp ( sim ( I i , T j ) / τ ) s ( T i , I i ) = exp ( sim ( T i , I i ) / τ ) ∑ j = 1 n × k exp ( sim ( T i , I j ) / τ ) (1) s(I_i,T_i)=\frac{\exp(\text{sim}(I_i,T_i)/\tau)}{\sum{j=1}^{n\times k}\exp(\text{sim}(I_i,T_j)/\tau)} \quad s(T_i,I_i)=\frac{\exp(\text{sim}(T_i,I_i)/\tau)}{\sum_{j=1}^{n\times k}\exp(\text{sim}(T_i,I_j)/\tau)} \tag{1}s (I i ,T i )=∑j =1 n ×k exp (sim (I i ,T j )/τ)exp (sim (I i ,T i )/τ)s (T i ,I i )=∑j =1 n ×k exp (sim (T i ,I j )/τ)exp (sim (T i ,I i )/τ)(1 )
其中,n是一个GPU \text{GPU}GPU上的batch size,k k k是GPU \text{GPU}GPU的数量,τ \tau τ是可学习参数。此外,sim ( ⋅ , ⋅ ) \text{sim}(\cdot,\cdot)sim (⋅,⋅)表示image-text样本对的cosine相似度。令D D D表示训练数据,y ( ⋅ , ⋅ ) \textbf{y}(\cdot,\cdot)y (⋅,⋅)表示真实的one-hot像度。global contrastive pre-ranking \text{global contrastive pre-ranking}global contrastive pre-ranking损失函数通过交叉熵损失函数L c ( ⋅ ) \mathcal{L}c(\cdot)L c (⋅)来计算
L GCPR = 1 2 E ( I , T ) ∼ D [ L c ( s ( I , T ) , y ( I , T ) ) + L c ( s ( T , I ) , y ( T , I ) ) ] (2) \mathcal{L}{\text{GCPR}}=\frac{1}{2}\mathbb{E}_{(I,T)\sim D}[\mathcal{L}_c(s(I,T),\textbf{y}(I,T))+\mathcal{L}_c(s(T,I),\textbf{y}(T,I))] \tag{2}L GCPR =2 1 E (I ,T )∼D L c (s (I ,T ),y (I ,T ))+L c (s (T ,I ),y (T ,I )) - Fine-Grained Ranking 正如前面提到的,应用global contrastive pre-ranking \text{global contrastive pre-ranking}global contrastive pre-ranking来获得图像和文本的独立表示。依赖于这些表示,接下来会执行Fine-Grained Ranking(FGR) \text{Fine-Grained Ranking(FGR)}Fine-Grained Ranking(FGR)损失函数来执行细粒度的排序任务。具体来说,这个任务是一个二分类任务,并且预测一个图像文本对是否匹配。形式化的来说,给定一个图像表示h I [ C L S ] \text{h}{I{[CLS]}}h I [C L S ]和一个文本表示h T [ C L S ] \text{h}{T{[CLS]}}h T [C L S ],将表示输入至全连接层g ( ⋅ ) g(\cdot)g (⋅)来获得预测概率。令y \textbf{y}y表示二分类的真实标签,然后通过平均交叉熵L c ( ⋅ ) \mathcal{L}c(\cdot)L c (⋅)的方式来计算FGR \text{FGR}FGR:
L F G R = 1 2 E ( I , T ) ∼ D [ L c ( g ( h I [ C L S ] ) , y ) + L c ( g ( h T [ C L S ] ) , y ) ] (3) \mathcal{L}{FGR}=\frac{1}{2}\mathbb{E}{(I,T)\sim D}[\mathcal{L}_c(g(h{I_{[CLS]}}),\textbf{y})+\mathcal{L}c(g(h{T_{[CLS]}}),\textbf{y})] \tag{3}L FGR =2 1 E (I ,T )∼D L c (g (h I [C L S ]),y )+L c (g (h T [C L S ]),y ) - Masked Language Modeling 在image-to-text \text{image-to-text}image-to-text交叉编码器上应用masked language modeling loss \text{masked language modeling loss}masked language modeling loss来改善模型建模图像和文本间token级别关系的能力。文本中15%的tokens被遮蔽。这些tokens被替换为[MASK] \text{[MASK]}[MASK]来避免改变文本语义。对于MLM \text{MLM}MLM任务,在大多数的VLP \text{VLP}VLP模型中前向操作时独立执行的。在本文的模型中,MLM \text{MLM}MLM任务利用遮蔽的文本和对应的图像一起用于降噪,其能够增强文本和图像的交互。因为FGR \text{FGR}FGR极大的依赖这种交互能力,作者提出了增强训练(ET) \text{(ET)}(ET),其将MLM \text{MLM}MLM任务集成至FGR \text{FGR}FGR前向操作的正
image-text对。
3. 两路蒸馏
大多数的预训练 image-text数据都是通过半监督程序收集的,可能会产生包含噪音和不正确的样本。不精确的标签是存在问题的,因为其可能误导模型。为了解决这个问题,作者提出了target-guided distillation(TgD) \text{target-guided distillation(TgD)}target-guided distillation(TgD),一个具有软目标的 teacher-student范式。为了进一步的改善预训练模型的表示,作者引入了feature-guided distillation(FgD) \text{feature-guided distillation(FgD)}feature-guided distillation(FgD),另一个基于蒸馏的 teacher-student。为了方便,将两种蒸馏合并称为两路蒸馏( two-way distillation,TwD ) (\text{two-way distillation,TwD})(two-way distillation,TwD )。
- Target-guided Distillation 为了降低从噪音标签学习噪音的风险,作者提出采用
momentum-updated encoders生成的软目标。特别地,momentum-updated encoder是蒸馏的教师模型,其包含了指数平均移动权重。维护两个队列来缓存近期的图像和文本表示。教师从相似分布中生成软标签。然后合并软标签和one-hot标签。令y ^ ( I , T ) \hat{\textbf{y}}(I,T)y ^(I ,T )和y ^ ( T , I ) \hat{\textbf{y}}(T,I)y ^(T ,I )表示最终的软标签。定义y ^ ( I , T ) \hat{\textbf{y}}(I,T)y ^(I ,T )为
y ^ ( I , T ) = α s ( I m , T ) + ( 1 − α ) y ( I , T ) (4) \hat{\textbf{y}}(I,T)=\alpha \textbf{s}(I_m,T)+(1-\alpha)\textbf{y}(I,T) \tag{4}y ^(I ,T )=αs (I m ,T )+(1 −α)y (I ,T )(4 )
其中,I m I_m I m 表示被输入至momentum-updated encoder的图像I I I。对于GCPR \text{GCPR}GCPR中的s ( I , T ) \textbf{s}(I,T)s (I ,T ),将当前mini-batch \text{mini-batch}mini-batch中的文本特征与文本队列合并(所有文本表示为T q \text{T}q T q ),并像s ( I , T q ) \textbf{s}(I,T_q)s (I ,T q )这样计算image-to-text的softmax相似度分数。这样,y ^ ( I , T ) \hat{\textbf{y}}(I,T)y ^(I ,T )也会被y ^ ( I , T q ) \hat{\textbf{y}}(I,T_q)y ^(I ,T q )替换。然后在text-to-image上执行相同的过程。考虑到队列中特征的影响力随时间下降,作者也维护了一个权重队列来标记对应位置特征的可靠性。特别地,每次迭代队列中的每个元素按0.99衰减,除了新进入的特征。此外,使用加权交叉熵损失函数L w ( ⋅ ) \mathcal{L}_w(\cdot)L w (⋅)替换等式(2)中的L c ( ⋅ ) \mathcal{L}_c(\cdot)L c (⋅),加权队列为w w w。对于target-guided distillation \text{target-guided distillation}target-guided distillation,L GCPR TgD \mathcal{L}{\text{GCPR}}^{\text{TgD}}L GCPR TgD 定义为:
L GCPR TgD = 1 2 E ( I , T ) ∼ D [ L w ( s ( I , T q ) , y ^ ( I , T q ) ; w ) + L w ( s ( T , I q ) , y ^ ( T , I q ) ; w ) ] (5) \mathcal{L}{\text{GCPR}}^{\text{TgD}}=\frac{1}{2}\mathbb{E}{(I,T)\sim D}[\mathcal{L}_w(\textbf{s}(I,T_q),\hat{\textbf{y}}(I,T_q);w)+\mathcal{L}_w(\textbf{s}(T,I_q),\hat{\textbf{y}}(T,I_q);w)] \tag{5}L GCPR TgD =2 1 E (I ,T )∼D L w (s (I ,T q ),y ^(I ,T q );w )+L w (s (T ,I q ),y ^(T ,I q );w ) - Feature-guided Distillation feature-guided distillation \text{feature-guided distillation}feature-guided distillation的目标是进一步改善预训练模型的泛化能力。类似于TgD \text{TgD}TgD,这里仍然使用
teacher-student范式来执行feature-guided distillation。下面以文本编码器为例,教师的角色是momentum-updated文本编码器,学习是文本编码器。这里,教师的权重是通过所有过去文本编码器的指数移动平均来更新的。为了进一步改善模型的能力,在输入上应用了masking策略。实践中,将完整的输入送入教师模型,并将遮蔽的输入送入学习模型。依赖于这种动量机制,使得学习的特征更加接近教师的特征。正式来说,教师和学生预测的分布P t ( T ) \mathcal{P}t(T)P t (T )、P s ( T ) \mathcal{P}_s(T)P s (T )定义如下:
P t ( T ) = exp ( ( f t ( T ) − μ ) / τ t ) ∑ i = 1 d exp ( ( f t ( T ) ( i ) − μ ( i ) ) / τ t ) , P s ( T ) = exp ( f s ( T ) / τ s ) ∑ i = 1 d exp ( f s ( T ) ( i ) / τ s ) (6) \mathcal{P}_t(T)=\frac{\exp((f_t(T)-\mu)/\tau_t)}{\sum{i=1}^d \exp((f_t(T)^{(i)}-\mu^{(i)})/\tau_t)},\quad \mathcal{P}s(T)=\frac{\exp(f_s(T)/\tau_s)}{\sum{i=1}^d\exp(f_s(T)^{(i)}/\tau_s)} \tag{6}P t (T )=∑i =1 d exp ((f t (T )(i )−μ(i ))/τt )exp ((f t (T )−μ)/τt ),P s (T )=∑i =1 d exp (f s (T )(i )/τs )exp (f s (T )/τs )(6 )
其中,f t ( ⋅ ) f_t(\cdot)f t (⋅)和f s ( ⋅ ) f_s(\cdot)f s (⋅)表示教师网络和学生网络。此外,μ \mu μ是以f t ( ⋅ ) f_t(\cdot)f t (⋅)为中心特征的动量更新均值,d d d是特征的维度。τ t \tau_t τt 和τ s \tau_s τs 分别是教师模型和学习模型的temperature参数,其可以使特征的分布更加的陡峭。显然,P s ( I ) \mathcal{P}s(I)P s (I )和P t ( I ) \mathcal{P}_t(I)P t (I )具有相似的形式。通过交叉熵损失函数来执行feature-guided distillation,损失函数L FgD L{\text{FgD}}L FgD 定义为:
L FgD = 1 2 E ( I , T ) ∼ D [ L c ( P s ( I ) , P t ( I ) ) + L c ( P s ( T ) , P t ( T ) ) ] (7) \mathcal{L}{\text{FgD}}=\frac{1}{2}\mathbb{E}{(I,T)\sim D}[\mathcal{L}c(\mathcal{P}_s(I),\mathcal{P}_t(I))+\mathcal{L}_c(\mathcal{P}_s(T),\mathcal{P}_t(T))] \tag{7}L FgD =2 1 E (I ,T )∼D L c (P s (I ),P t (I ))+L c (P s (T ),P t (T ))
模型的完整训练目标函数为
L = L GCPR TgD + L FGR + L FgD + L MLM (8) \mathcal{L}=\mathcal{L}{\text{GCPR}}^{\text{TgD}}+\mathcal{L}{\text{FGR}}+\mathcal{L}{\text{FgD}}+\mathcal{L}_{\text{MLM}} \tag{8}L =L GCPR TgD +L FGR +L FgD +L MLM (8 )
四、实验结果

Original: https://blog.csdn.net/bqw18744018044/article/details/125696046
Author: BQW_
Title: 【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/547983/
转载文章受原作者版权保护。转载请注明原作者出处!