

yolov5s.yaml 文件
以yolov5s.yaml 为例
其中有设置好的anchor


每一行代表在某一层的anchor. 一行的三组数字分别代表三个anchor的宽和高 基准
且小anchor 是在大特征图上,大anchor是在小特征图上。以输入图片大小640*640为例:
最终提取三个特征图大小分别为 80 X 80 , 40 X 40, 20X20
那么 [10, 13, 16,30, 33,23] 将应用在80 X 80 的特征图上
[30,61, 62,45, 59,119] 应用在 40 X40 的特征图上
[116,90, 156,198, 373,326] 在 20 X 20 的特征图上

; Detect 函数
定义在yolo.Detect里面
class Detect(nn.Module):
stride = None
onnx_dynamic = False
def __init__(self, nc=80, anchors=(), ch=(), inplace=True):
super().__init__()
self.nc = nc
self.no = nc + 5
self.nl = len(anchors)
self.na = len(anchors[0]) // 2
self.grid = [torch.zeros(1)] * self.nl
self.anchor_grid = [torch.zeros(1)] * self.nl
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2))
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch)
self.inplace = inplace
def forward(self, x):
z = []
for i in range(self.nl):
x[i] = self.m[i](x[i])
bs, _, ny, nx = x[i].shape
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training:
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i]
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
else:
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i]
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20):
d = self.anchors.device
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors.clone() * self.stride) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
由yolov5.yaml 中可知 detect 的输入为来自17, 20, 23 提取的三个特征图。参数是[nc, anchor].
详细介绍可参考yolov5 – head 源码解释
注意
1)当training 的时候,返回的是预测的偏量值,当前向推理的时候才会计算实际的bouding box.
2)在_make_grid 时候,anchor_grid 时乘了对应的stride的。 此时的self.anchors是yaml 文件的anchors除以对应特征图的stride的。
3) anchor是用于每一个点对应的三个不同bouding box的基准的。根据预测的偏量y[…, 2:4]和宽高基准self.anchor_grid可以得到预测的宽和高。 再根据x,y中心坐标便可得到bouding box.
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i]
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
Detect函数的相关问题
1)Detect 初始化的参数 [nc, anchor, ch]
首先在建立模型时: yolo.parse_model()中找到Detect
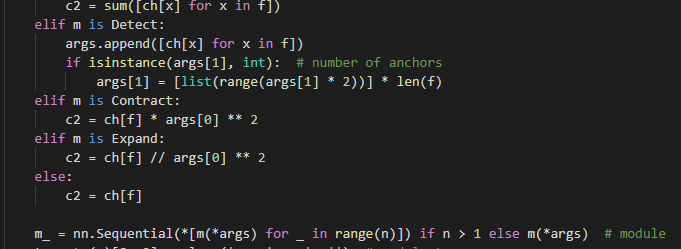
由yolov5s.yaml文件可知,Detect的args是[nc, anchors], 然后又传入args.append([ch[x] for x in f])
,在这个函数ch是对应层的输出channel 数. 则这个就是第17, 20, 23层输出的特征图的chanel数量.
在yolo.Detect() 里,我们可以看到,这三个参数是用来建立Detect的三个卷积层用来计算预测值的。
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch)
2) detect 的forward输入x为来自17, 20, 23 提取的三个特征图。
在yolo.Model._forward_once 函数里,我们可以看到整个模型的前向传播。
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], []
for m in self.model:
if m.f != -1:
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f]
if profile:
self._profile_one_layer(m, x, dt)
x = m(x)
y.append(x if m.i in self.save else None)
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
y 收集了每一层的输出结果。Detect层 m.f 为[17,20,23],则其输入为三层的特征图。
3)Detect 里面的self.anchors
上面提到,yolo.Detect inference 里面的self.anchors是yaml 文件的anchors除以对应特征图的stride的。这个是在yolo.Model()初始化时 m.anchors /= m.sride.view(-1, 1, 1)。
以yolov5s.yaml 为例, 则anchors 转化如下

if isinstance(m, Detect):
s = 256
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))])
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases()
4) autoanchor
这个功能实现在units.autoanchor.check_anchors中,通过聚类算法重新计算适合该数据集的anchors.
可参考yolov5自动anchor计算
在yolov5加入了autoanchor, 如果想用自己设置的anchor, 则需要禁止掉这个。
直接在训练时中加入 –noautoanchor就好
否则便会调用check_anchors, 利用聚类算法重新计算适合该数据集的anchors. 如果认为新生成的anchors比原来的好,便会用这个anchors替换原来的anchors.
train.py

Original: https://blog.csdn.net/weixin_44956310/article/details/121745474
Author: weixin_44956310
Title: yolov5 的 detect 层 与 anchor 机制
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/629498/
转载文章受原作者版权保护。转载请注明原作者出处!