

Bert是从transformer中衍生出来的预训练的模型,transformer模型已经得到广泛应用,应用的方式是先进行预训练语言模型,然后把预训练的模型适配给下游任务,以完成各种不同的任务,比如分类,生成,标记等。
1.transformer编码器
transform和LSTM最大的区别:LSTM的训练是迭代的,一个接一个字的进行训练。transform的训练是并行的,所有的字全部同时训练,这样就大大加快了计算效率,该模型使用了位置嵌入来对语言的顺序进行理解,使用子注意力机制和全连接层来进行计算。
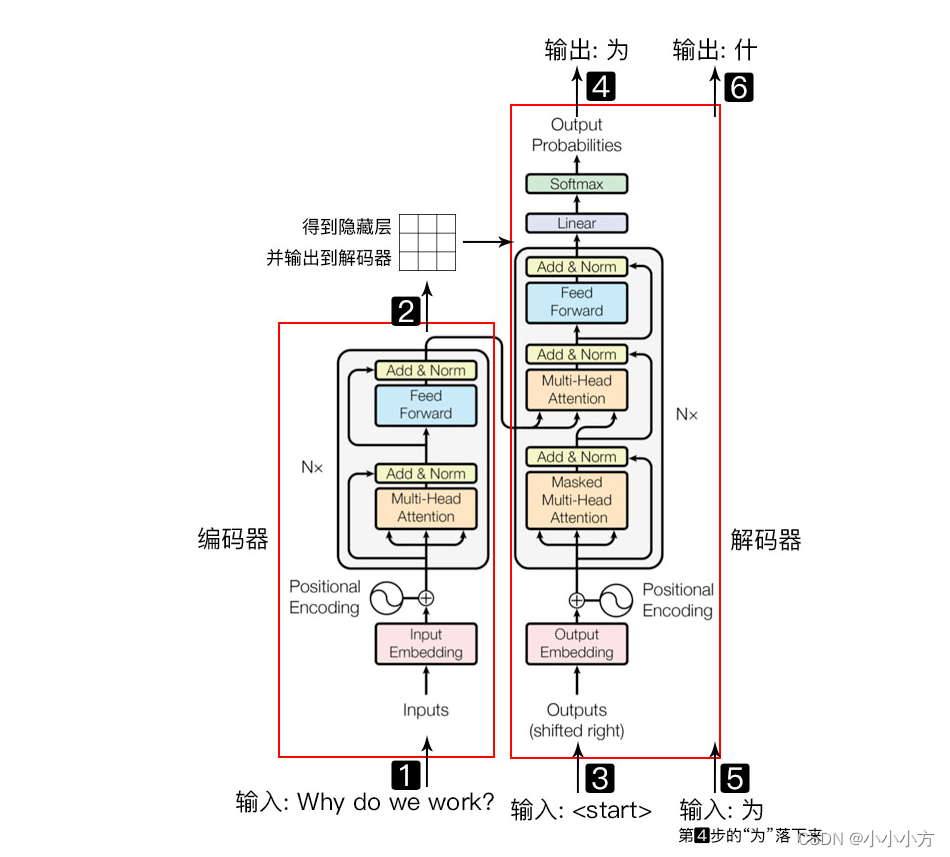
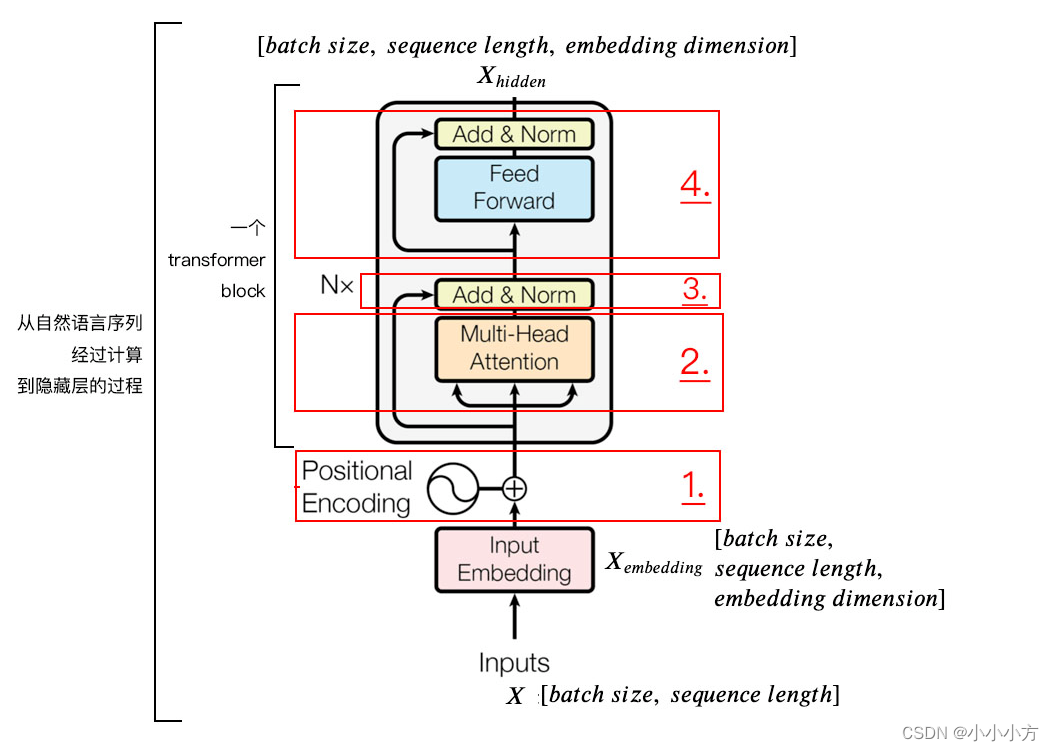
transform模型主要分为两个部分,分别是编码器和解码器。编码器负责把自然语言序列映射称为隐藏层(含有自然语言序列的数学表达),然后解码器把隐藏层在映射为自然语言序列。
transformer由self-atention和feedforwoard neural network组成
简单步骤:
1.输入自然语言序列到编码器
2.编码器输出的隐藏层,在输入到解码器
3.启动解码器
- 得到第一个字
5.将第一个字落下来再输入到解码器,得到第二个字
6.重复此过程,直到解码器输出终止符,序列生成完成。

1.1位置嵌入
由于transform模型没有循环神经网络的迭代,必须提供每个字的位置信息给transformer才能识别处语言中的顺序关系。
定义一个位置嵌入的概念,位置嵌入的维度为[max sequence length ,embedding dimension],嵌入的维度同词向量的维度,max sequence length属于超参数,指的是限定的最大单个句长。
我们一般以字为单位训练transformermoxing,不适用分词,首先要初始化字向量为[vocab size,embedding dimension].vocab size为总共的字库数量,embedding dimension为字向量的维度也就是每个字的数学表达。
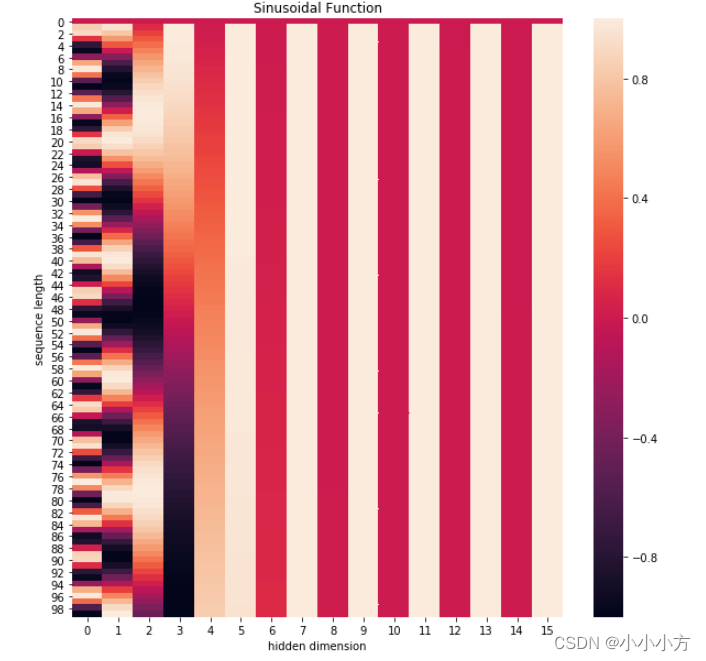
论文中使用sine和consine函数的线性变换来提供给模型位置信息。pos指的是句中字的位置,取值范围是[0,max sequence length],i指的是词向量的维度,取值范围是[0,emdedding dimension].对应着emdedding dimension维度的一组奇数和偶数的序号的维度,分别使用上面的sin和cos函数做处理,从而产生不同的周期性变化,而位置嵌入在embedding dimension维度上随着维度序号的增大,周期变化会越来越慢,从而产生一种包含位置信息的纹理,位置嵌入函数的周期从
变化,而每一个位置在embedding dimension维度上都会得到不同周期的sin和cos函数的取值组合,从而产生独一的纹理位置信息,模型从学到位置之间的依赖关系和自然语言的时序特性。
导入依赖库
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
# 归一化, 用位置嵌入的每一行除以它的模长
# denominator = np.sqrt(np.sum(position_enc**2, axis=1, keepdims=True))
# position_enc = position_enc / (denominator + 1e-8)
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
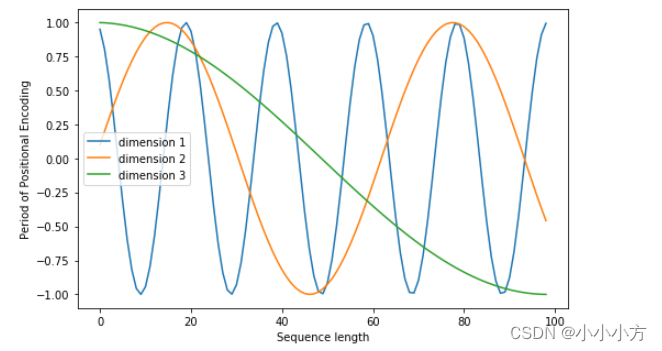
上面两张图解释,位置嵌入随着维度序号增大,周期变换会越来越慢。
1.2自注意力机制
预备知识:
(1)注意力机制是通过训练得到一个加权,自注意力机制是通过权重矩阵来自发的找到词与词之间的关系,需要给每个input一个tensor(张量),然后通过tensor之间的乘法得到input之间的关系。
(2)padding 可以控制输出的尺寸,同时避免了边缘信息被舍弃的问题。
(3)mask(掩码)相当于在原始张量上盖上一层膜,从而屏蔽或选择一些特定元素,用于构建张量的过滤器。可以用于数据的预处理、模型中间层和模型损失计算上,具体的算法实现细节是根据实际需求进行设计。
(4)batch size 指的是句子的个数
(5)所谓自注意力机制是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重,然后再以权重和的形式来计算得到整个句子的隐含向量表示。该机制的缺陷是:模型在当前位置的信息进行编码时,会过度的将注意力集中在自身的位置,提出多头注意力机制来解决这个问题。
(6)多头注意力就是在多个不同的投影空间中建立不同的投影信息,将输入矩阵,进行不同的投影,得到许多输出矩阵后,将其拼接在一起。
(7)点积的集合意义:两个向量越相似,它们之间的点积就越大,否则越小
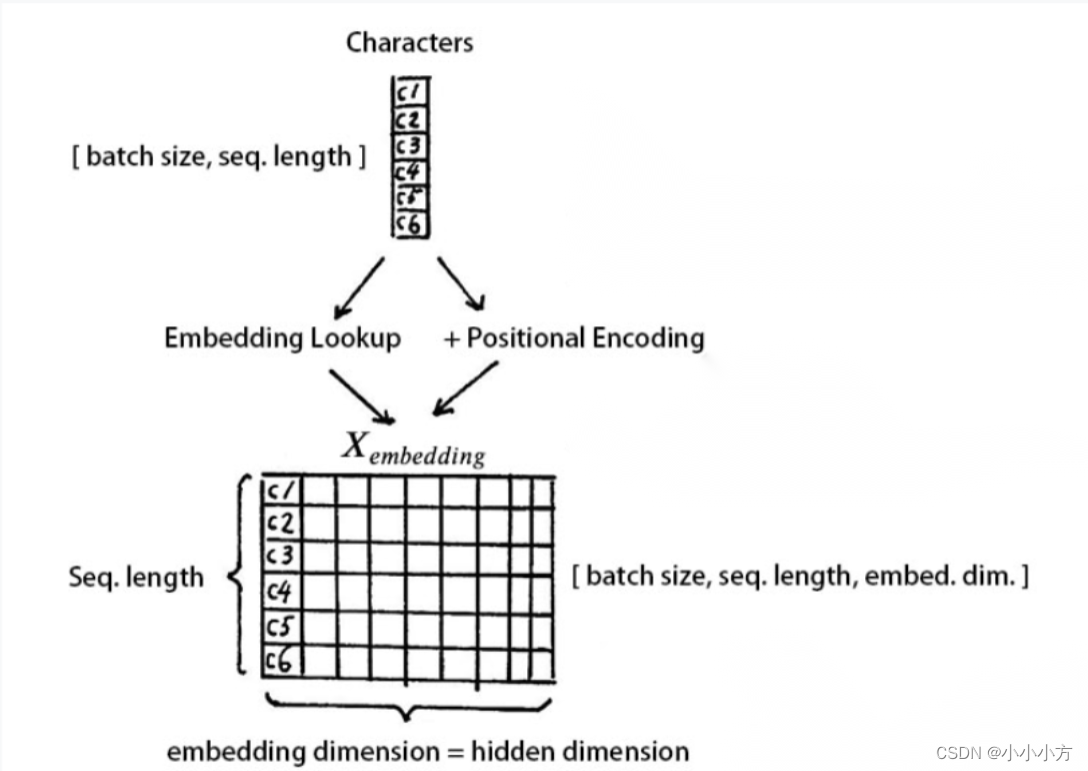
假设句子X的维度是 [batch size,sequence legth],(可以先不去在意batch size的值)
将字转换成相应的嵌入,然后与位置嵌入元素相加
Xembedding的维度为[batch size,sequence length ,embedding dimension]
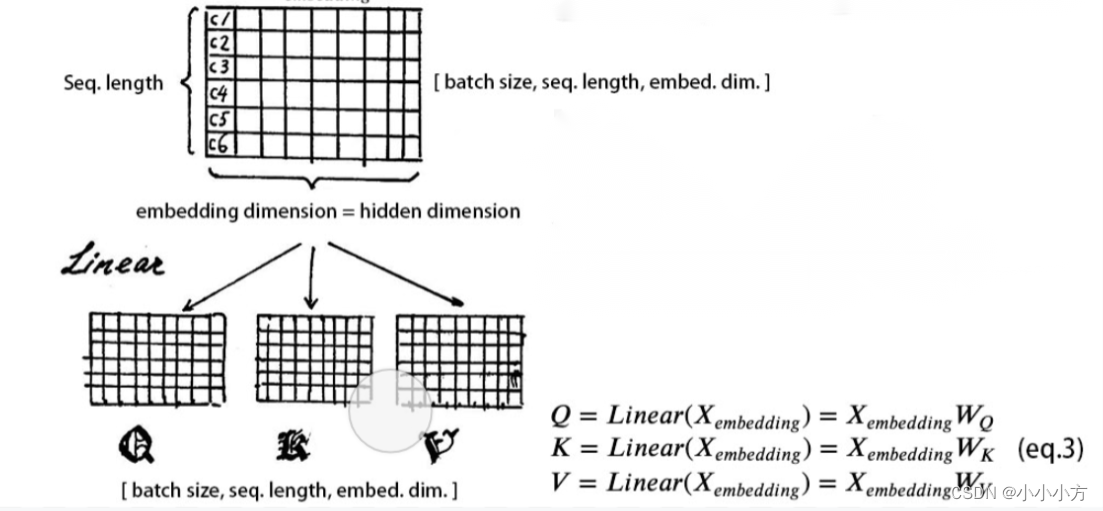
为了学到多重含义的表达对X做线性映射,分配三个权重
,形成三个矩阵Q,K,V,和线性变换之前的维度保持一致。
Q:表示query,自己用的,查找和其他输入之间的关系
K:表示key,给别人使用的,其他输入和自己之间的关系
V:表示value
使用多头注意力机制来提取多重语义,使用注意力机制来提取多重语义的含义,首先定义一个超参数h也就是head的数量(embedding dimension必须可以整除h),将embedding dimension分成h份。
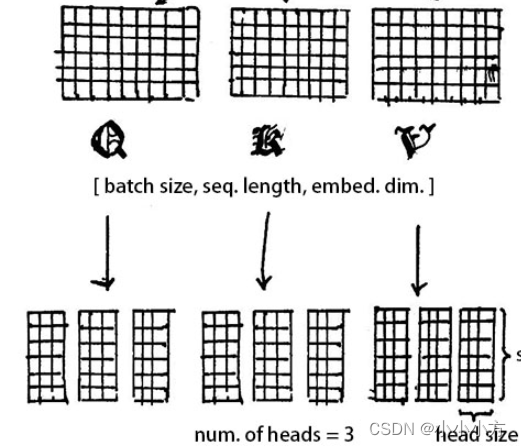
分割之后Q,K,V的维度变成[batch size,sequence length ,h,embeding dimesnsion/h]
我们拿出一组heads进行计算
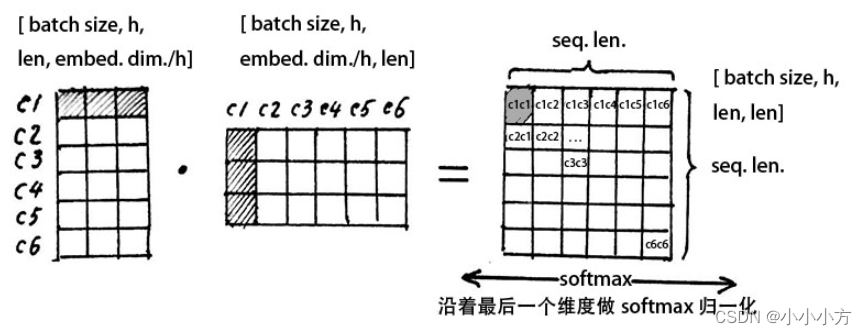
先计算Q与K的转置的点积,代表第一个字的c1行与第一个字的c1列相乘,得到一个数值,即第一个字与第一个字的注意力机制,然后一次计算c1c2,c1c3…,注意力矩阵的第一行就是指的是第一个字与其余输入字(这里是6)的哪几个比较相关。
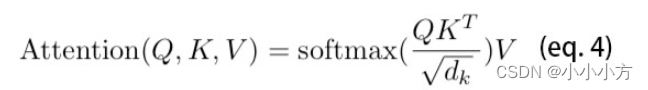
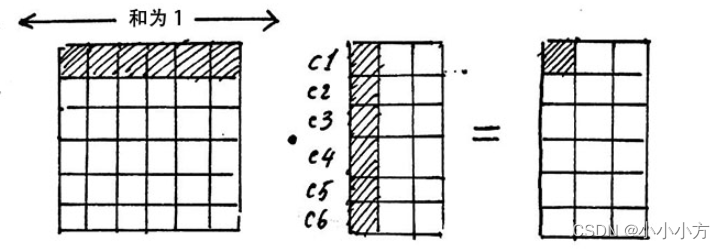
最后得到的attention就是V矩阵的一个线性组合,只不过是根据Q和K的相似性加了一个权重并进行了softmax,使得每个字根其他所有字的注意力权重的和为1,
是为了把注意力矩阵变成标准正态分布。
attention mask
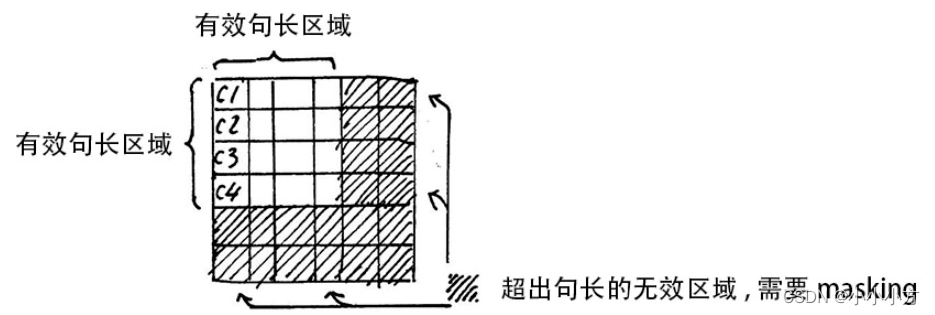
每一个mini batch都是有多个不等长的句子组成的,需要按照这个minibatch中最大的句长对剩余的句子进行补齐长度,使用0来进行填充,这个过程叫做padding.但是在进行sofmax的时候就会产生问题,e0=1,是有值的,这样padding部分就参与了运算,就等于让无效的部分参与了运算,会产生很大的隐患,使用mask让这些无效的区域不参与运算,给无效区域加一个很大的负数的偏置。
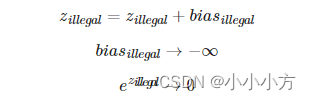
经过上诉的方法避免无效区域参与运算。
LayerNormalization和残差连接
残差连接的思想:将输出表述为输入和输入的一个非线性变换的线性叠加。随着网络深度的增加,带来很多问题,梯度消散,梯度爆炸等。深度学习依靠误差的链式反向传播来进行参数更新,一旦其中某一个倒数很小,多次连乘之后梯度可能越来越小,对于深层网络,传递到浅层机会就没有了,但是如果使用了残差,就相当于每一个倒数加上了一个恒等项去,此时就算原来的导数很小,仍然能够有效的反向传播。
在上一步得到了经过注意力矩阵加权之后的V,也就是Atterntion(Q,K,V),我们对它进行转置,使其和Xembedding的维度一致,然后把它们加起来做残差连接,直接进行元素相加
在之后的运算中,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接反传到最初始层:
通俗的讲,batch normalization是对batch当中的每一个样本加起来做标准化处理,layer noemalization是相对的,是batch normalization当中每个样本内部的embdding_dim上的标准化。
LayerNorm:作用是把神经网网络中隐藏层归一化为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用:
以矩阵中的行为单位求均值:
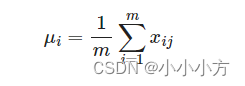
以矩阵中的列为单位求方差:

然后利用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归一化的数值。
是为了防止除0,之后引入两个可训练参数,来弥补归一化过程中损失掉的信息,一般将初始化为全1,将初始为全0.
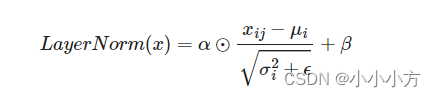
总结

这是up主1espresso讲解视频中的内容,因为在学习所以根据自己的能力做的笔记,文章中的图也是来自于视频中,对于一些知识的理解也比较浅。
Original: https://blog.csdn.net/weixin_56368033/article/details/124915352
Author: 小小小方
Title: Transformer之编码器
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/628241/
转载文章受原作者版权保护。转载请注明原作者出处!