

运行YOLOv5首先需要安装深度学习环境,教程请看安装pytorch深度学习环境(GPU版)。
YOLOv5的代码在GitHub上是开源的GitHub – ultralytics/yolov5,利用其代码实现自己的目标检测需求,需要3个步骤:1.准备数据集;2.配置代码参数,训练模型;3.预测。以下笔者将带大家一步步实现自己的目标检测模型训练。
一、准备数据集
1.1 收集图片
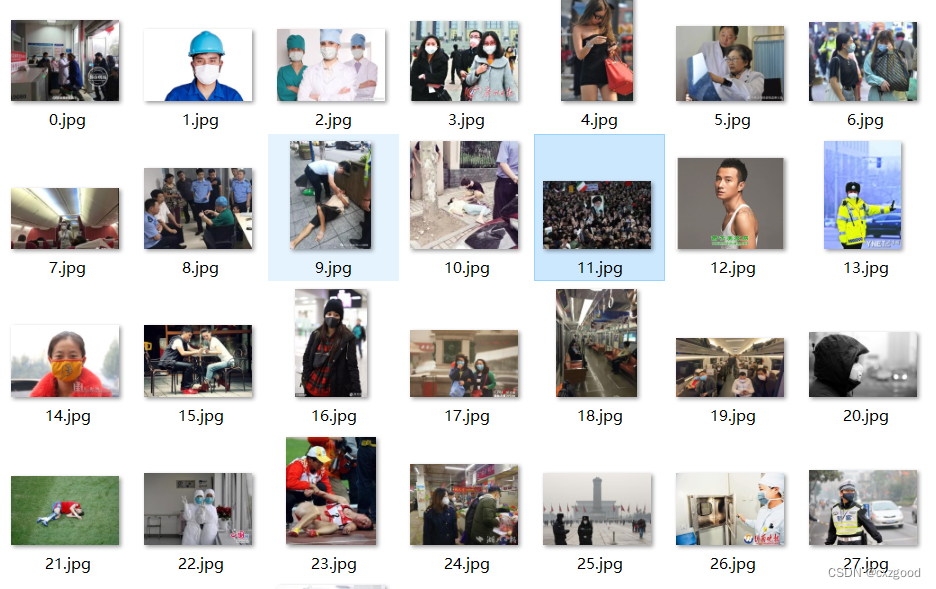

1.2 利用labelimg软件给收集到的图片打标签
1.2.1 labelimg软件的安装
labelimg软件是一款开源的数据标注工具,可以标注三种格式。①VOC标签格式的xml文件。②yolo标签格式的txt文件。③createML标签格式的json文件。
labelimg的安装很简单,我们打开cmd,输入以下命令即可:
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2.2 利用labelimg软件打标签
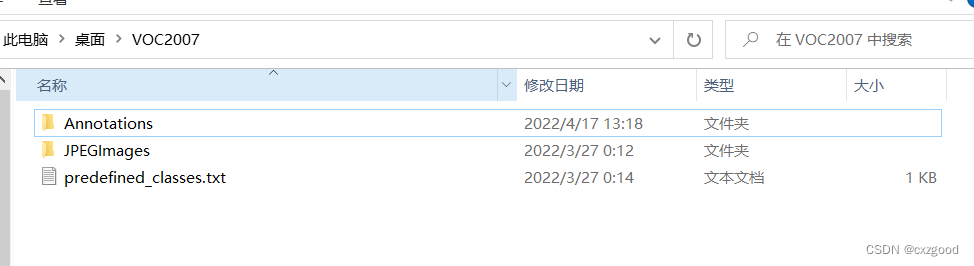
首先我们不妨建立个名为VOC2007的文件夹,里面创建一个名为JPEGImages的文件夹用以存放我们收集好的需要打标签的图片;再创建一个名为Annotations的文件夹用以存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件用以存放所要标注的类别名称。结构如下图所示:
在这里我们想要实现的是检测有没有戴口罩,因此predefined_classes.txt文件的类别只有2个,如下图所示:

然后,我们要在VOC2007的目录下(一定要是该目录下)打开cmd,输入以下命令:
labelimg JPEGImages predefined_classes.txt
这个命令的意思是利用labelimg软件给JPEGImages文件夹中的图片,按照 predefined_classes.txt 文件中的分类打标签。
打开后的界面如下图所示,其中
Open Dir是选择存放图片的文件夹,在这里我们的命令将其默认为JPEGImages文件夹;
Change Save Dir是改变存储标签的文件夹,这里我们默认为Annotations文件夹;
PascalVOC是选择标签格式,上边介绍过,主要有3种,我们通常选择PascalVOC的xml格式,YOLO格式也行,两者之间可以相互转换;
Create RectBox是产生打标签的十字位置线,对图片进行标注。
框取目标检测位置后会出现标签选择框,我们选择对应的标签即可,如下图所示。然后就可以点击Next Image对下一幅图片进行标注,直至全部图片标注完成。

两种标签格式如下图所示:
PascalVOC的xml格式:
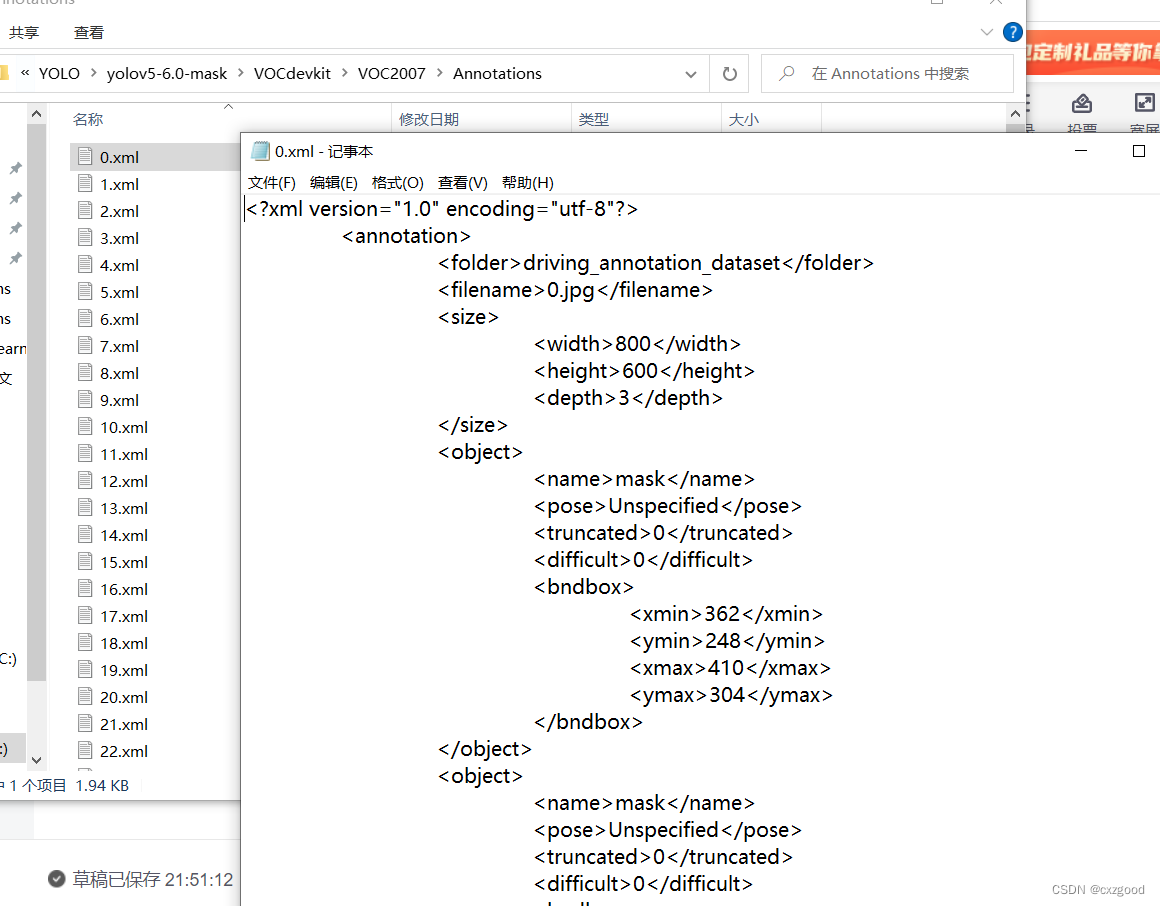
YOLO的txt格式:
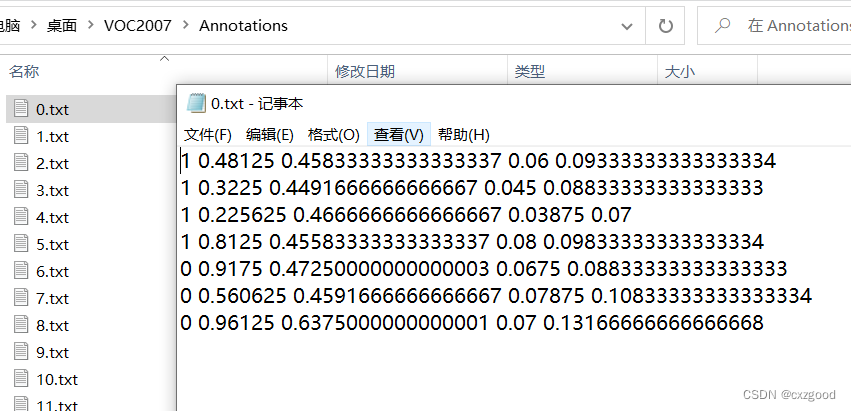
1.3 标签格式的转化及训练集和验证集的划分
1.3.1 xml格式标签转化为txt格式,并划分训练集(80%)和验证集(20%)
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["unmask", "mask"]
TRAIN_RATIO = 80 %训练集的比例
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
1.3.2 txt标签格式转化为xml格式,然后再利用1.3.1的方法划分数据集
from xml.dom.minidom import Document
import os
import cv2
def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "unmask", # 创建字典用来对类型进行转换
'1': "mask", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "VOCdevkit/VOC2007/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "VOCdevkit/VOC2007/YOLO/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "VOCdevkit/VOC2007/Annotations/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
如果标签是txt格式,在转换过程中需要注意几个问题:
1.根据代码最后几行可知,txt便签应存放在YOLO文件夹中;
2.转换成xml格式的标签将存放在Annotations文件夹中;
3.如果出现.shape的报错,检查一下YOLO文件夹中是否存在class.txt文件,删除即可。
这样,准备数据集的部分就完成了。
二、配置代码参数,训练模型
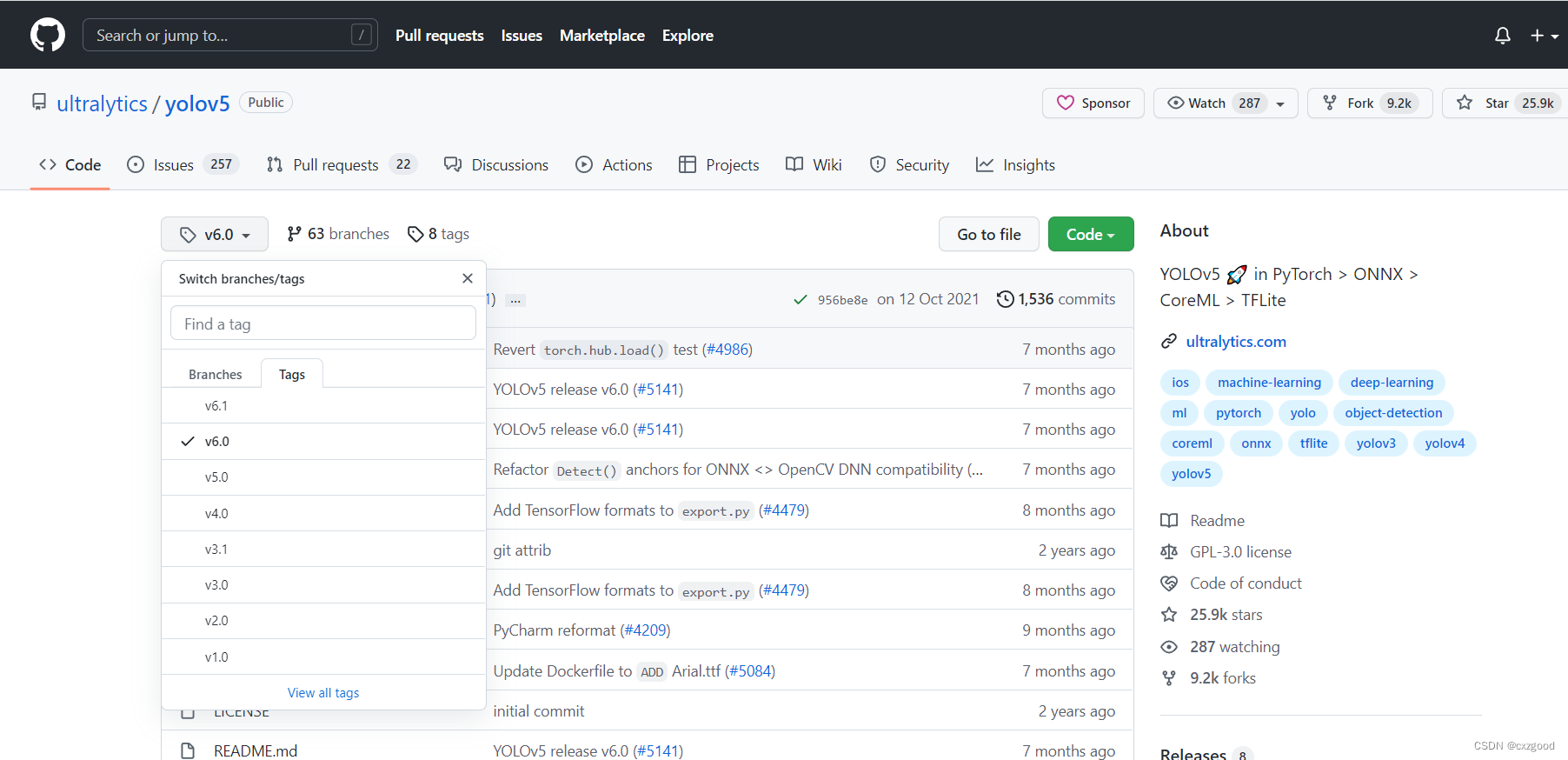
2.1 下载源代码
YOLOv5的代码在GitHub上是开源的GitHub – ultralytics/yolov5,我们可以在网站上下载源代码。如下图所示,在这里我们选择了v6.0版本 。
2.2 加入数据集
将自己准备好的数据集放入项目目录下的VOCdevkit文件夹中,利用1.3中介绍的标签转换和数据集划分方法划分数据集,如下图所示:
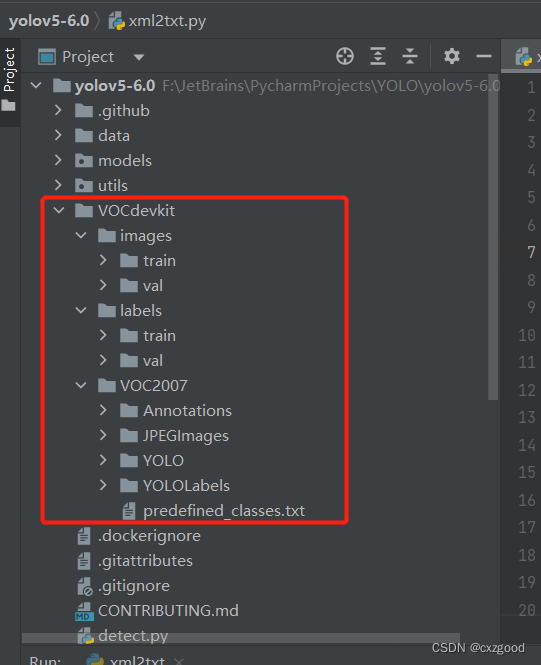
2.3 配置代码参数
1.在pycharm右下角选择配置好的pytorch环境,如果还未安装环境,请参考以前的文章;
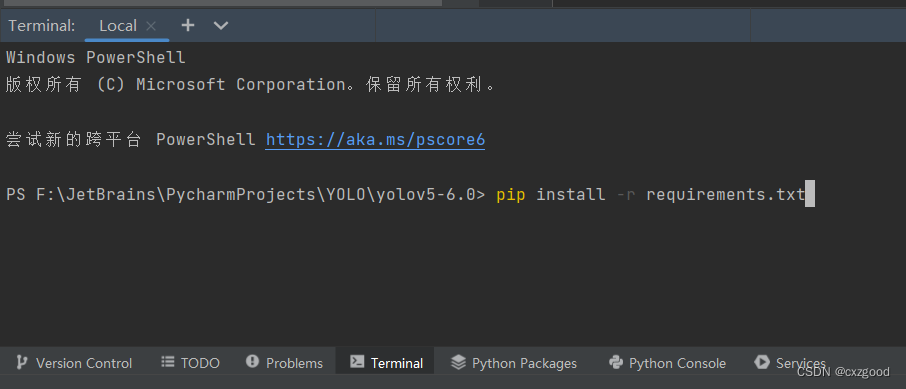
2.安装yolov5需要的依赖库。打开pycharm的命令终端,输入以下命令,如图所示:
pip install -r requirements.txt
3.下载预权重文件。网站预权重下载,这里我们使用yolov5s.pt,下载好放置于项目目录下。
4.修改数据配置文件。
①data文件夹下的VOC.yaml文件在该目录下复制一份,命名为mask.yaml,参照下图进行修改。
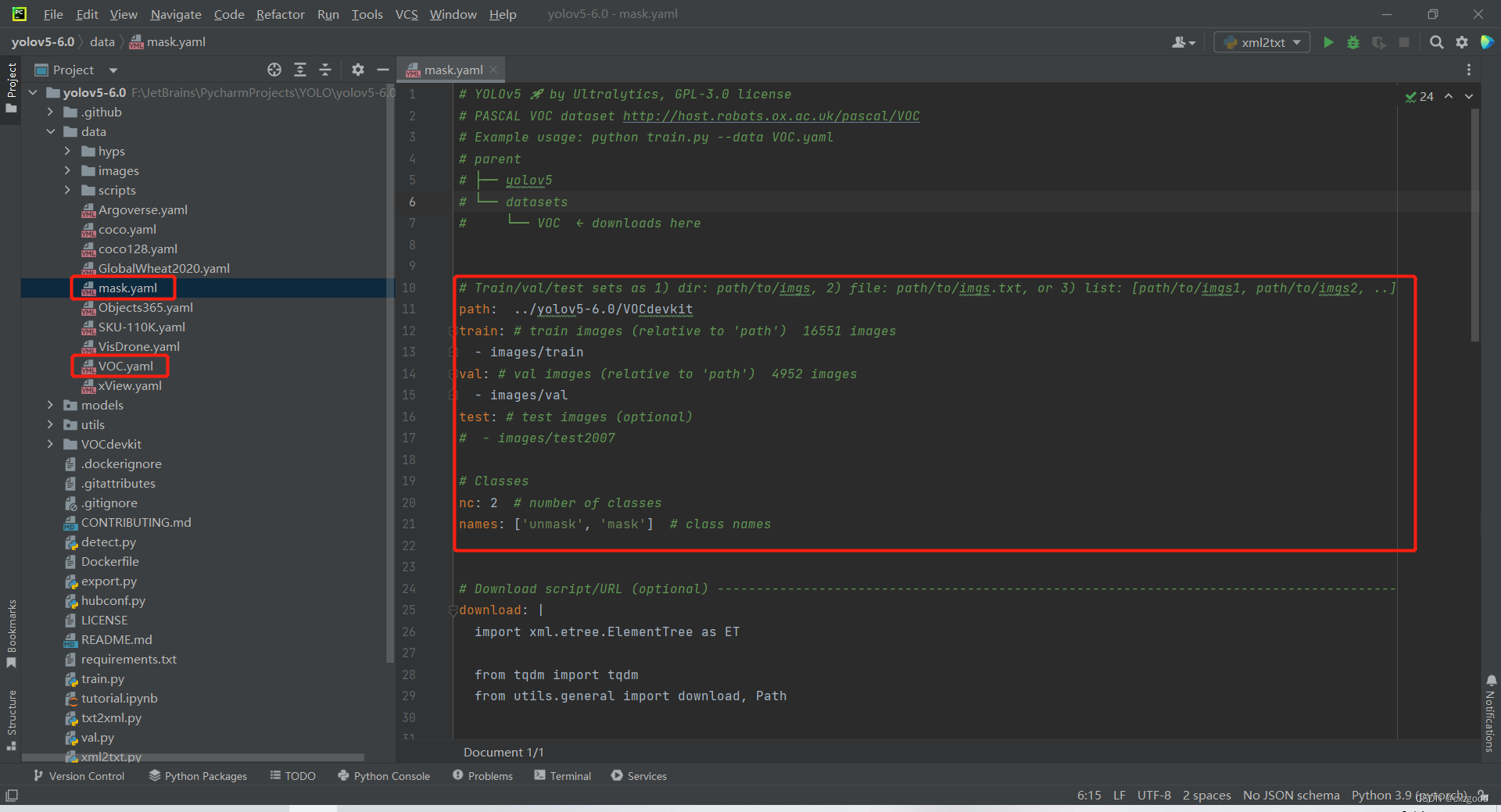
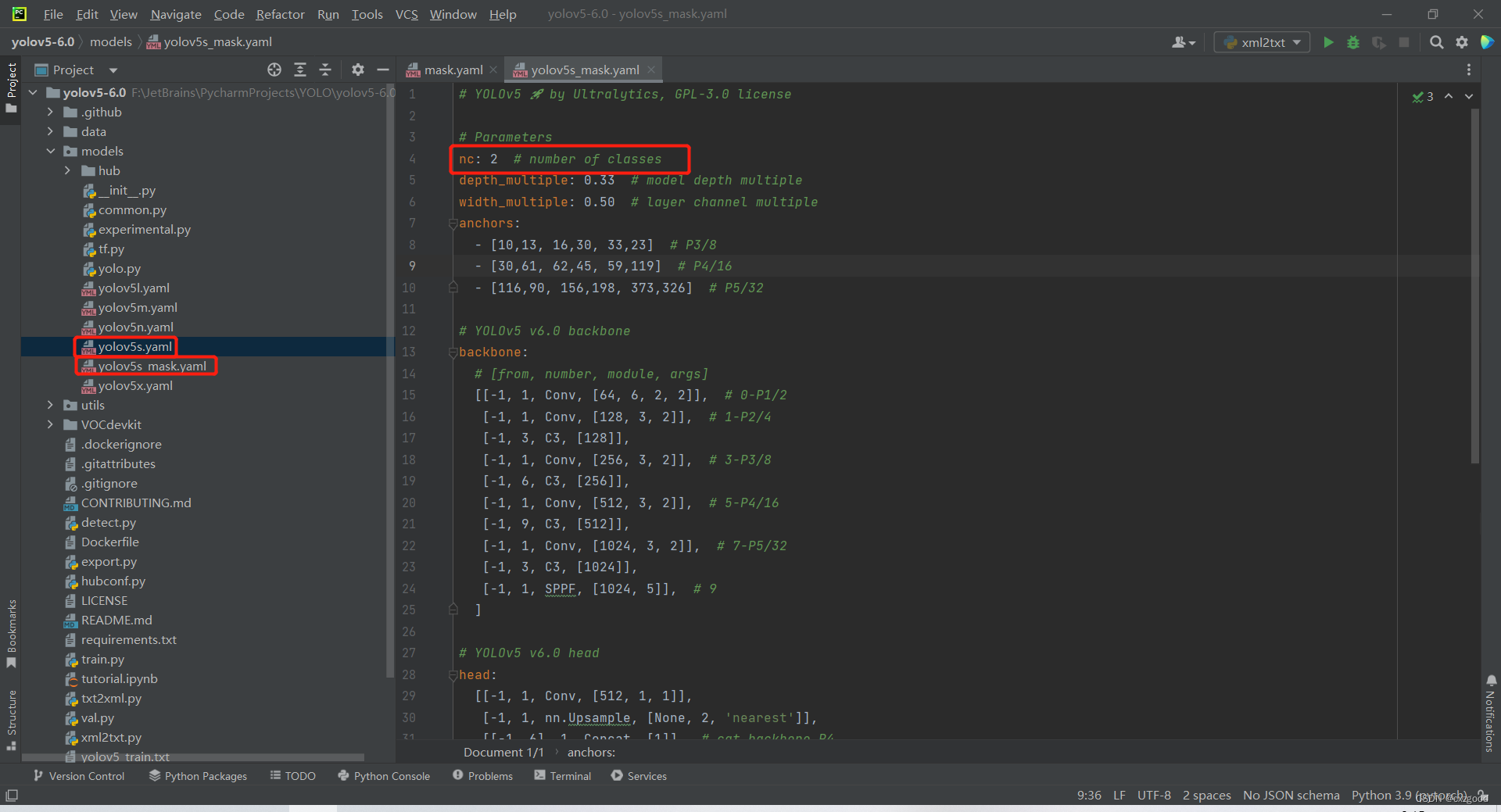
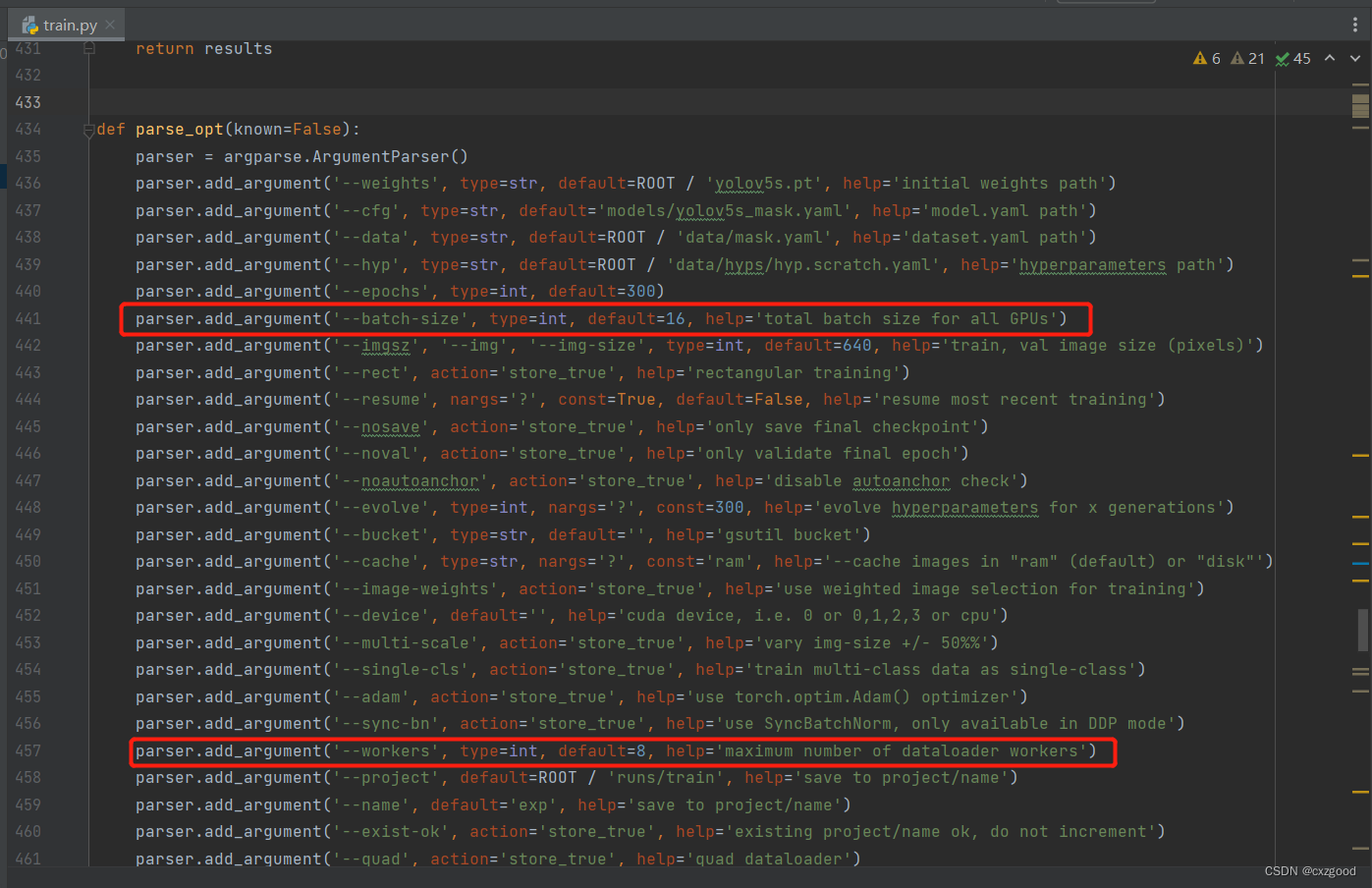
5.train文件参数设置
如下图所示,436行是设置预权重文件,437行和438行是设置数据配置文件,440行设置迭代次数(可根据需求自行设定)。
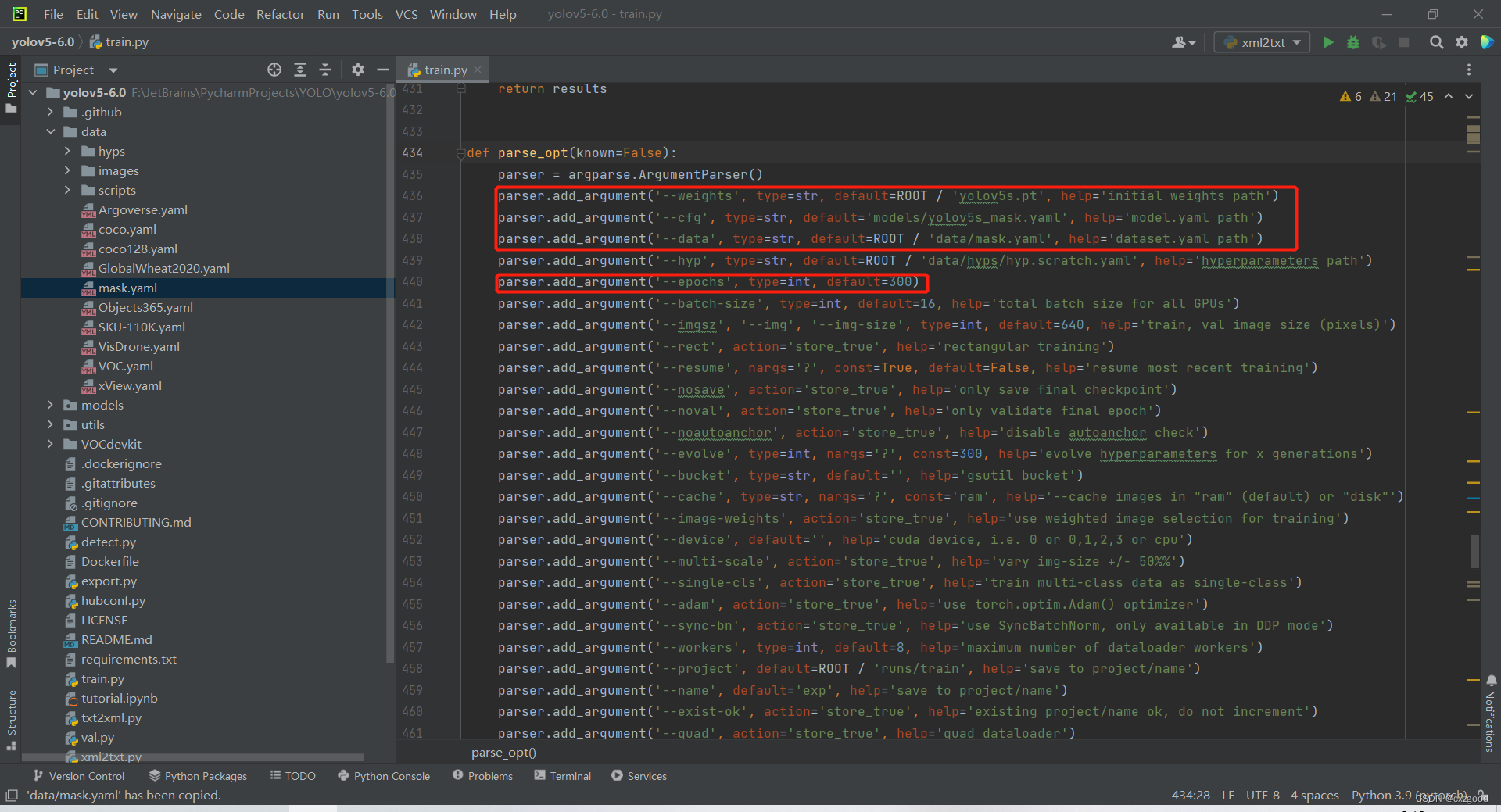
以上参数配置完成后,就可以运行train.py文件进行训练。但可能会碰到一下问题:
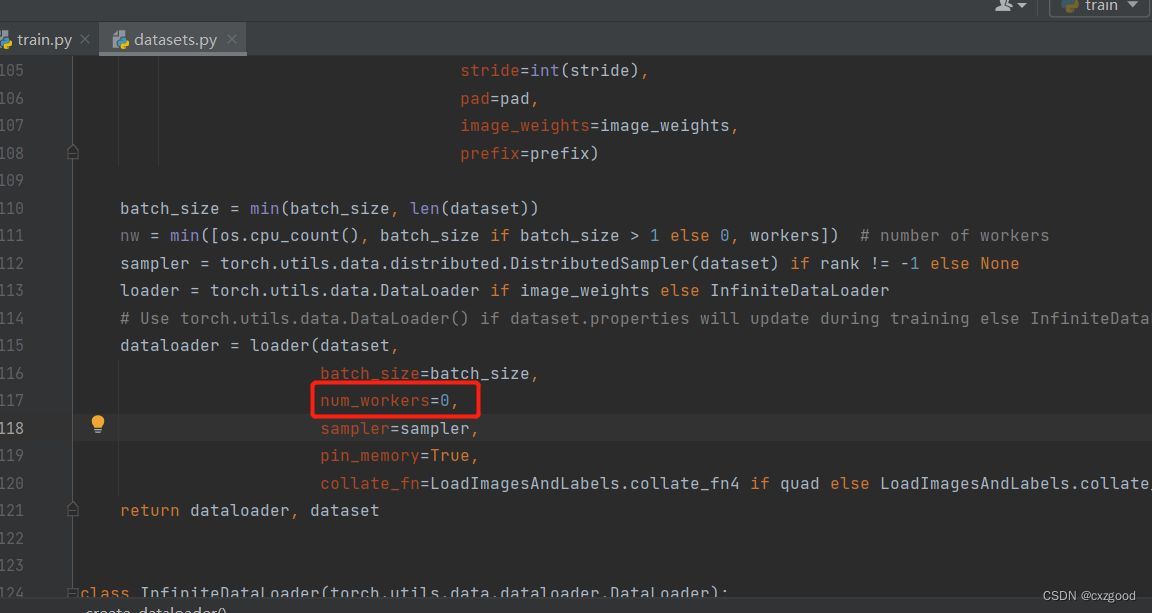
问题一:

这是说明虚拟内存不够了。我们可以通过修改utils路径下的datasets.py文件,将里面第117行的num_workers参数nw改完0就可以了。
问题二:

这说明GPU显存溢出。我们可以通过减小batch-size和workers参数大小来解决。
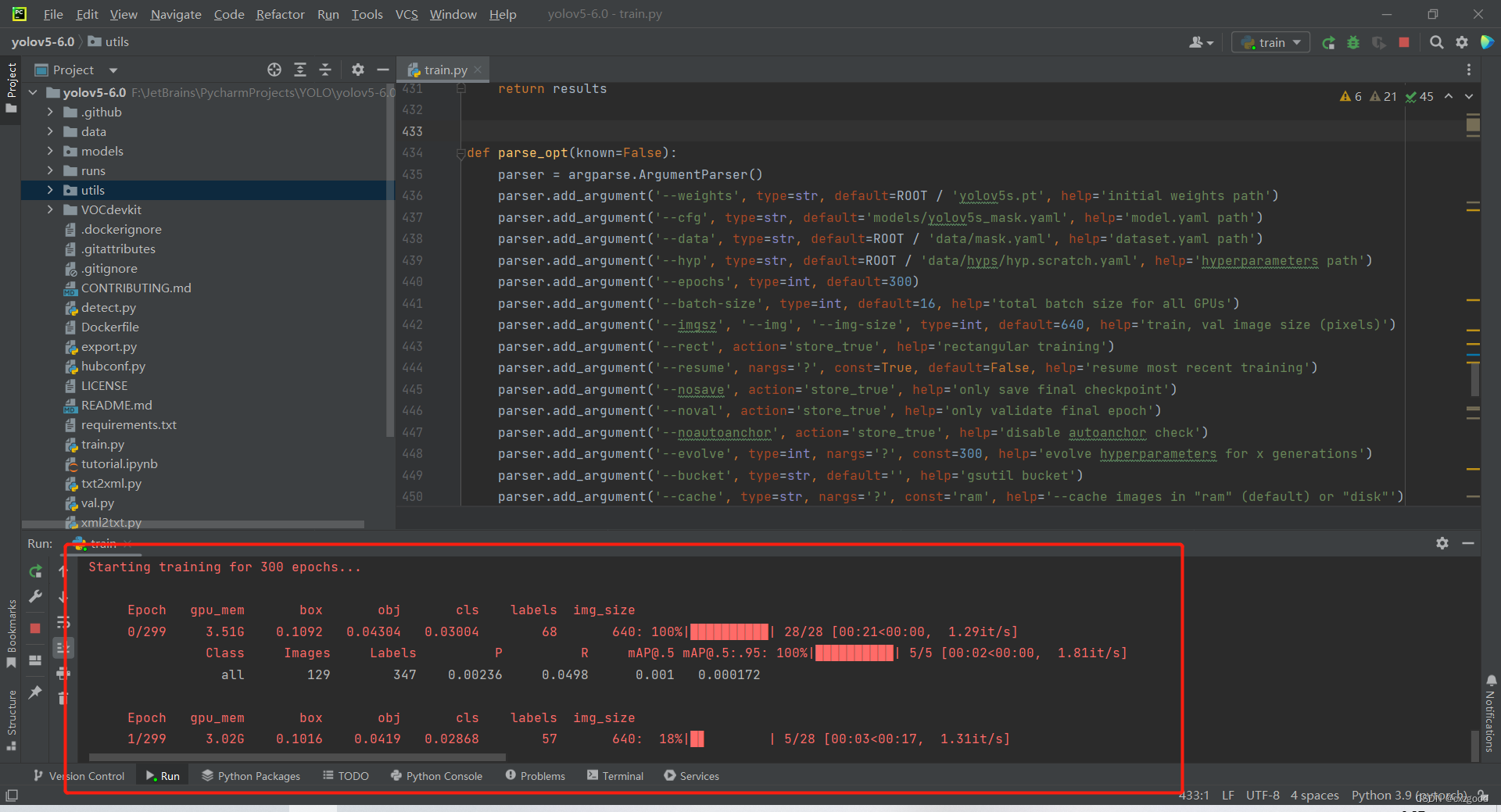
完成以上参数配置后,我们就可以训练自己的数据了。运行train.py文件,Run栏如下图所示即表明开始训练了。
三、预测
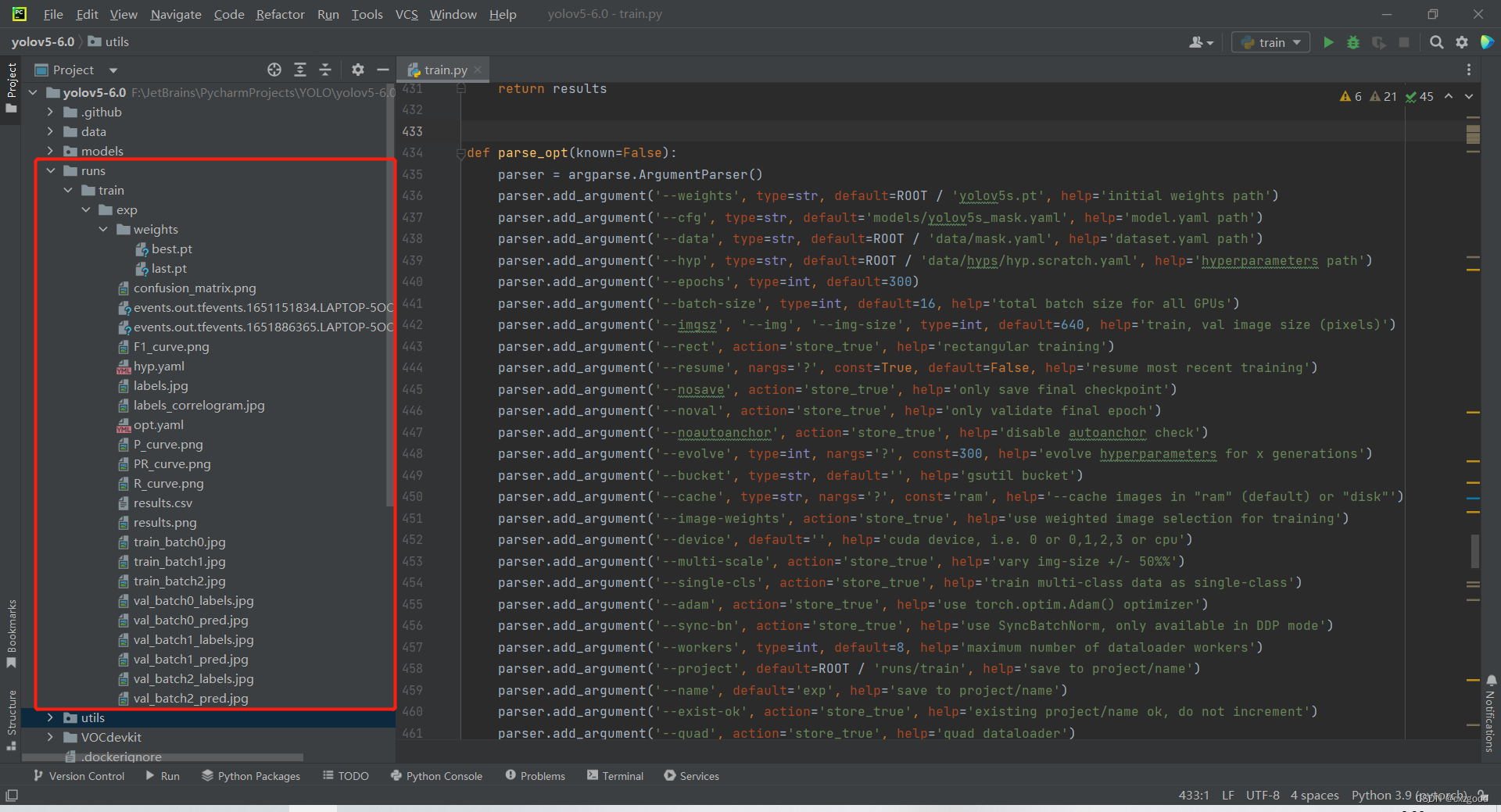
完成训练后,项目将出现runs/train/exp文件夹,里边包含训练好的权重数据和其他参数文件,如下图所示:
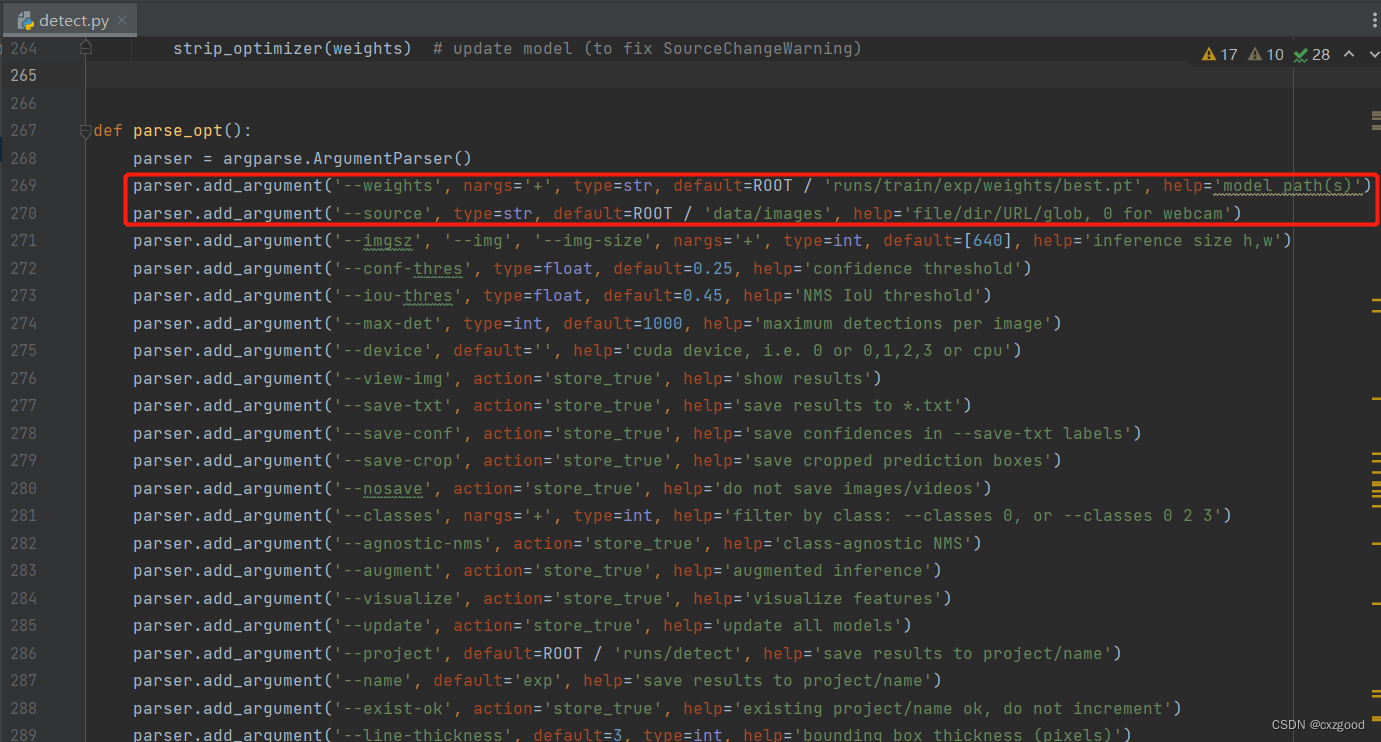
然后我们打开detect.py文件,修改如下参数。269行是设置训练好权重文件,270行是设置我们待检测的图片文件夹或特定图片或调用摄像头,0表示调用摄像头。
设置完成后,运行detect.py文件即可,检测结果保存在runs\detect\exp文件夹中。
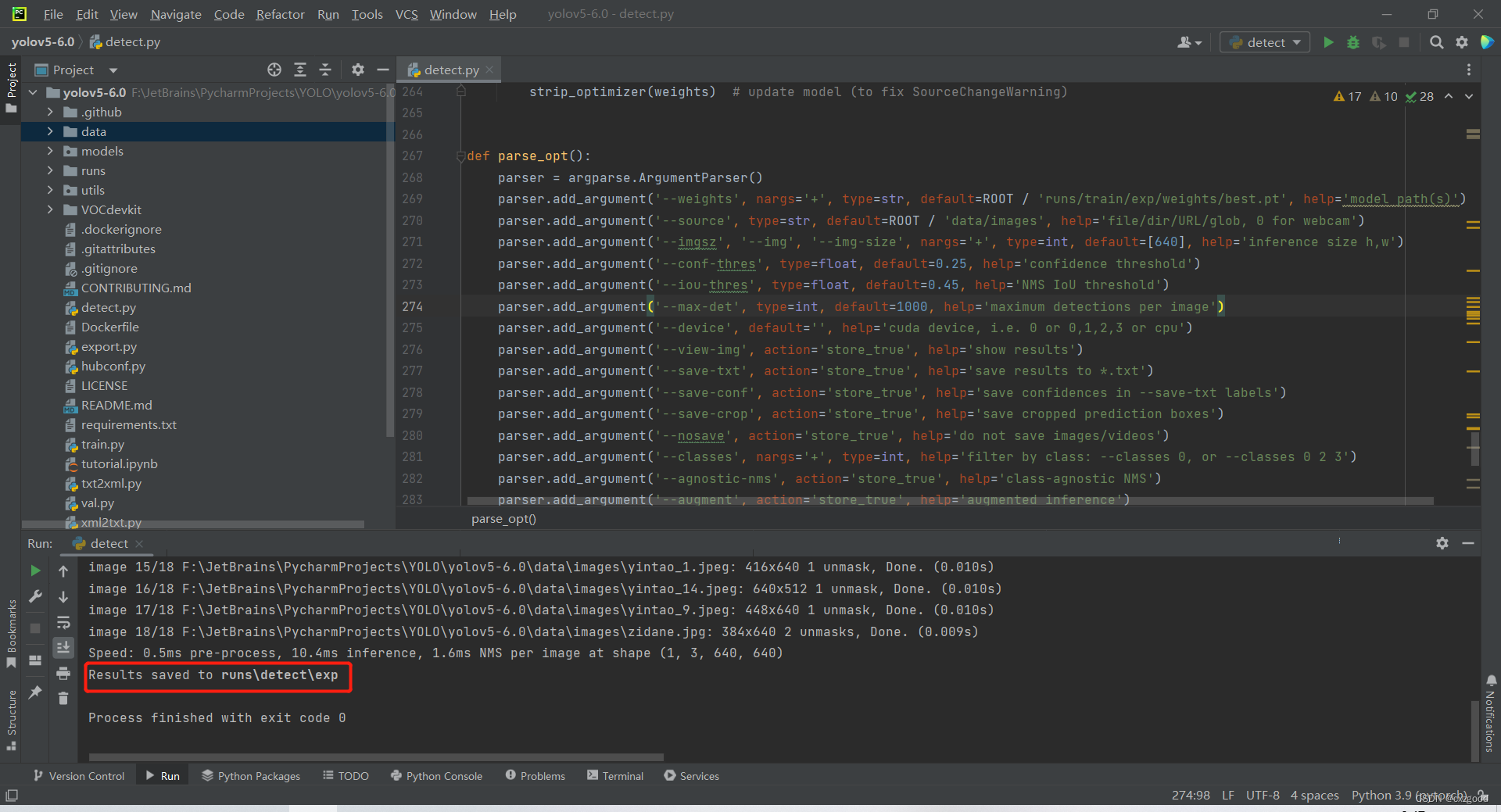
检测结果如下所示:

这样,我们就完成了一个基于YOLOv5训练自己的目标检测数据集的实验项目。感觉检测结果是不是很惊喜呢,可能也会觉得过程很繁琐或者不清晰。熟能生巧,大家多做实践,很快就能掌握其中的要点。好的,谢谢大家,如果有遇到其他问题,大家可以交流。
Original: https://blog.csdn.net/cxzgood/article/details/124618506
Author: 仲夏夜之梦xz
Title: 用YOLOv5训练自己的目标检测数据集(以口罩检测为例)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/627479/
转载文章受原作者版权保护。转载请注明原作者出处!