

目录
1、超级无敌通俗的YOLO系列讲解
2、论文思想
概述
YOLOv3是单阶段目标检测算法YOLO的第三个版本,广泛用于工业界,它改进了骨干网络、正负样本选取和损失函数,并引入了FPN特征金字塔多尺度预测,显著提升了速度和精度。
改进
骨干网络:DarkNet53,就是YOLO v2中的DarkNet19+Resnet。darknet53是52个卷积层+1个全连接层,但是在COCO数据集上训练好了分类的网络之后,就去掉了后面的全连接层,单纯作为全卷积网络在YOLO模型中使用,因此可以兼容任意尺度的输入。包含了大量的残差模块,由大量的1X1和3X3的卷积构成,借鉴了ResNet的做法,在各层之间建立快捷链路,通过跃层连接,解决了网络逐步深化时模型难以优化的问题,同时这样做可以利用到更多的浅层网络中的的图像细粒度信息。


正负样本选取:YOLO v3中的bbox有三类,分别是正样本、负样本和不参与损失函数计算的样本。 正样本:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正样本。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正样本。 负样本:正样本除外,与全部ground truth的IOU都小于阈值(0.5),则为负例。 不参与的部分:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为不参与的部分。
注:正样本的置信度标签是1,负样本的置信度标签是0
损失函数:包括正样本的中心定位误差,宽高定位误差,置信度误差,分类误差,还有负样本的置信度误差。其中boundingbox的位置信息使用的是均方差损失,置信度和分类用的全部都是交叉熵损失(也就是置信度越接近1 损失越小,类别损失是对所有类别单独做二分类,逐类别计算交叉熵损失,也就是一个求和,里面是类别概率*(-log))
FPN的多尺度检测方法:就是骨干网络会对输入图片进行多次下采样得到不同尺寸的feature-map,再将它们上采样和浅层网络中长宽相同的feature-map进行concat操作,得到的feature-map既拥有了深度网络的语义特征,也有了浅层网络的细粒度特征,使得模型对于小目标和密集目标的预测能力更强。多尺度指的是,将图像转换为三种不同尺度的feature-map,分别来检测大、中、小三个类型的物体,在此基础上进行分类和位置回归,这大大改善了原始YOLO网络的检测准确率。
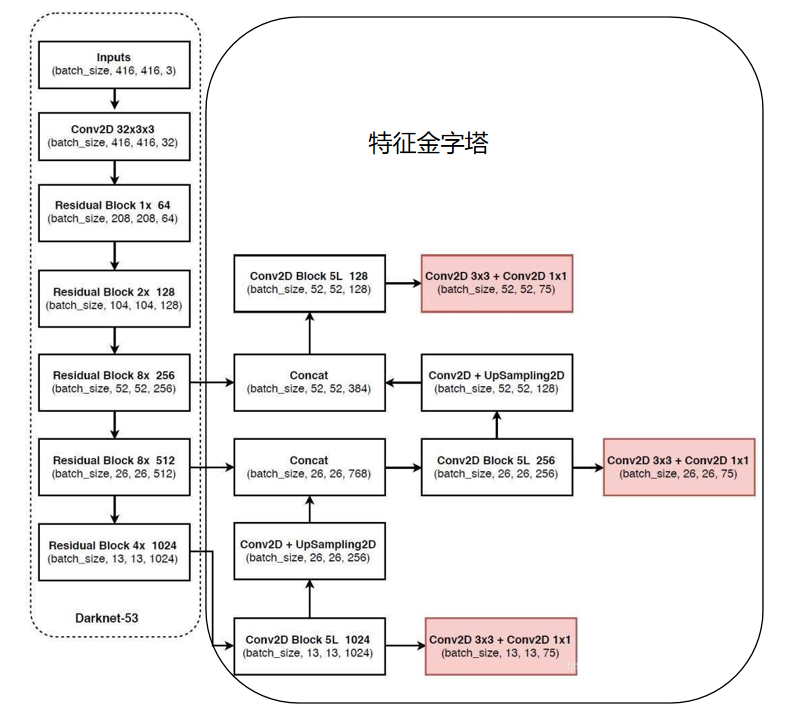
; 3、复现
学习资料:
yolov3硬核讲解(第一部分-YOLO-V3原理)
yolov3硬核讲解(第二部分-YOLO-V3网络结构+代码实现)
yolov3硬核讲解(第三部分-YOLO-V3数据制作+代码实现)
yolov3硬核讲解(第四部分-YOLO-V3训练和预测+代码实现)
Yolo.py
from torch import nn
from torch.nn import functional as Fun
import torch
class ConvolutionalLayer(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size, stride, padding, bias=False):
super(ConvolutionalLayer, self).__init__()
self.sub_module = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size, stride, padding, bias=bias),
nn.BatchNorm2d(output_channels),
nn.LeakyReLU()
)
def forward(self, x):
return self.sub_module(x)
pass
class ResidualLayer(nn.Module):
def __init__(self, input_channels, output_channels):
super(ResidualLayer, self).__init__()
self.sub_module = nn.Sequential(
ConvolutionalLayer(input_channels, output_channels, 1, 1, 0),
ConvolutionalLayer(output_channels, input_channels, 3, 1, 1)
)
def forward(self, x):
return self.sub_module(x) + x
pass
class ConvolutionalSetLayer(nn.Module):
def __init__(self, input_channels, output_channels):
super(ConvolutionalSetLayer, self).__init__()
self.sub_module = nn.Sequential(
ConvolutionalLayer(input_channels, output_channels, 1, 1, 0),
ConvolutionalLayer(output_channels, input_channels, 3, 1, 1),
ConvolutionalLayer(input_channels, output_channels, 1, 1, 0),
ConvolutionalLayer(output_channels, input_channels, 3, 1, 1),
ConvolutionalLayer(input_channels, output_channels, 1, 1, 0)
)
def forward(self, x):
return self.sub_module(x)
pass
class DownSamplingLayer(nn.Module, ):
def __init__(self, input_channels, output_channels):
super(DownSamplingLayer, self).__init__()
self.sub_module = nn.Sequential(
ConvolutionalLayer(input_channels, output_channels, 3, 2, 1)
)
def forward(self, x):
return self.sub_module(x)
class UpSamplingLayer(nn.Module):
def __init__(self):
super(UpSamplingLayer, self).__init__()
def forward(self, x):
return Fun.interpolate(x, scale_factor=2, mode='nearest')
pass
class yolo3_net(nn.Module):
def __init__(self):
super(yolo3_net, self).__init__()
self.trunk_52 = nn.Sequential(
ConvolutionalLayer(3, 32, 3, 1, 1),
DownSamplingLayer(32, 64),
ResidualLayer(64, 32),
DownSamplingLayer(64, 128),
ResidualLayer(128, 64),
ResidualLayer(128, 64),
DownSamplingLayer(128, 256),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
ResidualLayer(256, 128),
)
self.trunk_26 = nn.Sequential(
DownSamplingLayer(256, 512),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
ResidualLayer(512, 256),
)
self.trunk_13 = nn.Sequential(
DownSamplingLayer(512, 1024),
ResidualLayer(1024, 512),
ResidualLayer(1024, 512),
ResidualLayer(1024, 512),
ResidualLayer(1024, 512)
)
self.convset_13 = nn.Sequential(
ConvolutionalSetLayer(1024, 512)
)
self.detection_13 = nn.Sequential(
ConvolutionalLayer(512, 1024, 3, 1, 1),
nn.Conv2d(1024, 75, 1, 1, 0)
)
self.up_13to26 = nn.Sequential(
ConvolutionalLayer(512, 256, 1, 1, 0),
UpSamplingLayer()
)
self.convset_26 = nn.Sequential(
ConvolutionalSetLayer(768, 256)
)
self.detection_26 = nn.Sequential(
ConvolutionalLayer(256, 512, 3, 1, 1),
nn.Conv2d(512, 75, 1, 1, 0)
)
self.up_26to52 = nn.Sequential(
ConvolutionalLayer(256, 128, 1, 1, 0),
UpSamplingLayer()
)
self.convset_52 = nn.Sequential(
ConvolutionalSetLayer(384, 128)
)
self.detection_52 = nn.Sequential(
ConvolutionalLayer(128, 256, 3, 1, 1),
nn.Conv2d(256, 75, 1, 1, 0)
)
def forward(self, x):
h_52 = self.trunk_52(x)
h_26 = self.trunk_26(h_52)
h_13 = self.trunk_13(h_26)
convset_13_out = self.convset_13(h_13)
detection_13_out = self.detection_13(convset_13_out)
up_13to26_out = self.up_13to26(convset_13_out)
cat_26 = torch.cat((up_13to26_out, h_26), dim=1)
convset_26_out = self.convset_26(cat_26)
detection_26_out = self.detection_26(convset_26_out)
up_26to52_out = self.up_26to52(convset_26_out)
cat_52 = torch.cat((up_26to52_out, h_52), dim=1)
convset_52_out = self.convset_52(cat_52)
detection_52_out = self.detection_52(convset_52_out)
return detection_13_out, detection_26_out, detection_52_out
if __name__ == '__main__':
net = yolo3_net()
x = torch.randn(1, 3, 416, 416)
a, b, c = net(x)
print(a.shape, b.shape, c.shape)
dataset.py
import math
import os
import torch
from config import *
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
from util import *
from torchvision import transforms
def one_hot(cls_num,i):
rst=np.zeros(cls_num)
rst[i]=1
return rst
class YoloDataSet(Dataset):
def __init__(self):
f=open('data.txt','r')
self.dataset=f.readlines()
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
data=self.dataset[index].strip()
temp_data=data.split()
_boxes=np.array([float(x) for x in temp_data[1:]])
boxes=np.split(_boxes,len(_boxes)//5)
img = Image.open(os.path.join('data/images', temp_data[0]))
img=make_416_image(img)
w,h=img.size
case=416/w
img=img.resize((DATA_WIDTH,DATA_HEIGHT))
img_data=tf(img)
labels={}
for feature_size,_antors in anchors.items():
labels[feature_size]=np.zeros(shape=(feature_size,feature_size,3,5+CLASS_NUM))
for box in boxes:
cls,cx,cy,w,h=box
cx, cy,w,h=cx*case,cy*case,w*case,h*case
_x,x_index=math.modf(cx*feature_size/DATA_WIDTH)
_y,y_index=math.modf(cy*feature_size/DATA_HEIGHT)
for i,anchor in enumerate(_antors):
area=w*h
p_w, p_h = np.log(w / anchor[0]), np.log(h / anchor[1])
labels[feature_size][int(y_index),int(x_index),i]=np.array([1,_x,_y,p_w,p_h,*one_hot(CLASS_NUM,int(cls))])
return labels[13],labels[26],labels[52],img_data
if __name__ == '__main__':
dataset=YoloDataSet()
print(dataset[0][3].shape)
print(dataset[0][0].shape)
print(dataset[0][1].shape)
print(dataset[0][2].shape)
util.py
from PIL import Image
import torch
from torchvision import transforms
tf=transforms.Compose([
transforms.ToTensor()
])
def make_416_image(img):
w,h=img.size[0],img.size[1]
temp=max(w,h)
mask=Image.new(mode='RGB',size=(temp,temp),color=(0,0,0))
mask.paste(img,(0,0))
return mask
def iou(box,boxes,ismin=True):
box_area=(box[2]-box[0])*(box[3]-box[1])
boxex_area=(boxes[:,2]-boxes[:,0])*(boxes[:,3]-boxes[:,1])
xx1=torch.maximum(box[0],boxes[:,0])
yy1=torch.maximum(box[1],boxes[:,1])
xx2=torch.minimum(box[2],boxes[:,2])
yy2=torch.minimum(box[3],boxes[:,3])
w, h = torch.maximum(torch.tensor([0]), xx2 - xx1), torch.maximum(torch.tensor([0]), yy2 - yy1)
over_area = w * h
if ismin:
return over_area / torch.minimum(box_area, boxex_area)
return over_area / (box_area + boxex_area - over_area)
def nms(boxes,threshold=0.3):
new_boxes=boxes[boxes[:,0].argsort(descending=True)]
keep_boxes=[]
while len(new_boxes)>1:
_box=new_boxes[0]
_boxex=new_boxes[1:]
keep_boxes.append(_box)
new_boxes=_boxex[torch.where(iou(_box,_boxex)<threshold)]
if len(new_boxes) == 1:
keep_boxes.append(new_boxes[0])
return torch.stack(keep_boxes)
if __name__ == '__main__':
pass
make_data_txt.py
import math
import xml.etree.cElementTree as et
import os
from config import class_num
xml_dir = 'data/image_voc'
xml_filenames = os.listdir(xml_dir)
with open('data.txt', 'a') as f:
for xml_filename in xml_filenames:
xml_filename_path = os.path.join(xml_dir, xml_filename)
tree = et.parse(xml_filename_path)
root = tree.getroot()
filename = root.find('filename')
names = root.findall('object/name')
boxes = root.findall('object/bndbox')
data = []
data.append(filename.text)
for name, box in zip(names, boxes):
cls = class_num[name.text]
cx, cy, w, h = math.floor((int(box[2].text) - int(box[0].text)) / 2), math.floor(
(int(box[3].text) - int(box[1].text)) / 2), int(box[2].text) - int(box[0].text), int(box[3].text) - int(
box[1].text)
data.append(cls)
data.append(cx)
data.append(cy)
data.append(w)
data.append(h)
_str = ''
for i in data:
_str = _str + ' ' + str(i)
f.write(_str + '\n')
f.close()
config.py
DATA_WIDTH=416
DATA_HEIGHT=416
CLASS_NUM=20
BATCH_SIZE=6
anchors={
13: [[168,302], [57,221], [336,284]],
26: [[175,225], [279,160], [249,271]],
52: [[129,209], [85,413], [44,42]]
}
ANCHORS_AREA={
13: [x*y for x,y in anchors[13]],
26: [x*y for x,y in anchors[26]],
52: [x*y for x,y in anchors[52]]
}
num_class = {
0: 'aeroplane',
1: 'bicycle',
2: 'bird',
3: 'boat',
4: 'bottle',
5: 'bus',
6: 'car',
7: 'cat',
8: 'chair',
9: 'cow',
10: 'diningtable',
11: 'dog',
12: 'horse',
13: 'motorbike',
14: 'person',
15: 'pottedplant',
16: 'sheep',
17: 'sofa',
18: 'train',
19: 'tvmonitor'
}
class_num = {
'aeroplane': 0,
'bicycle': 1,
'bird': 2,
'boat': 3,
'bottle': 4,
'bus': 5,
'car': 6,
'cat': 7,
'chair': 8,
'cow': 9,
'diningtable': 10,
'dog': 11,
'horse': 12,
'motorbike': 13,
'person': 14,
'pottedplant': 15,
'sheep': 16,
'sofa': 17,
'train': 18,
'tvmonitor': 19
}
trainer.py
import os
from torch import nn, optim
import torch
from torch.utils.data import DataLoader
from dataset import *
from torch.utils.tensorboard import SummaryWriter
from Yolo import *
def loss_fun(output, target, c):
output = output.permute(0, 2, 3, 1)
output = output.reshape(output.size(0), output.size(1), output.size(2), 3, -1)
mask_obj = target[..., 0] > 0
mask_no_obj = target[..., 0] == 0
loss_p_fun = nn.BCELoss()
loss_p = loss_p_fun(torch.sigmoid(output[..., 0]), target[..., 0])
loss_box_fun = nn.MSELoss()
loss_box = loss_box_fun(output[mask_obj][..., 1:5], target[mask_obj][..., 1:5])
loss_segment_fun = nn.CrossEntropyLoss()
loss_segment = loss_segment_fun(output[mask_obj][..., 5:],
torch.argmax(target[mask_obj][..., 5:], dim=1, keepdim=True).squeeze(dim=1))
loss = c * loss_p + (1 - c) * 0.5 * loss_box + (1 - c) * 0.5 * loss_segment
return loss
if __name__ == '__main__':
summary_writer = SummaryWriter('logs')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dataset = YoloDataSet()
data_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=False)
weight_path = 'params/net.pt'
net = yolo3_net().to(device)
if os.path.exists(weight_path):
net.load_state_dict(torch.load(weight_path, map_location=torch.device('cpu')))
print("权重加载成功!")
opt = optim.Adam(net.parameters())
epoch = 500
total_train_step = 0
for i in range(epoch):
for target_13, target_26, target_52, img_data in data_loader:
target_13, target_26, target_52, img_data = target_13.to(device), target_26.to(device), target_52.to(
device), img_data.to(device)
output_13, output_26, output_52 = net(img_data)
loss_13 = loss_fun(output_13.float(), target_13.float(), 0.7)
loss_26 = loss_fun(output_26.float(), target_26.float(), 0.7)
loss_52 = loss_fun(output_52.float(), target_52.float(), 0.7)
loss = loss_13 + loss_26 + loss_52
opt.zero_grad()
loss.backward()
opt.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("第{}个epoch,总训练次数为{}时,损失为{}".format(i+1,total_train_step, loss.item()))
summary_writer.add_scalar('train_loss', loss.item(), total_train_step)
if (i + 1) % 100 == 0:
torch.save(net.state_dict(), "params/net_{}_path.pt".format(i+1), _use_new_zipfile_serialization=False)
print('模型保存成功')
detector.py
import os
import torch
from torch import nn
from Yolo import *
from PIL import Image, ImageDraw
from util import *
from dataset import *
from config import *
class Detector(nn.Module):
def __init__(self):
super(Detector, self).__init__()
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.weights = 'params/net.pt'
self.net = yolo3_net().to(self.device)
if os.path.exists(self.weights):
self.net.load_state_dict(torch.load(self.weights, map_location=torch.device('cpu')))
print('加载权重成功')
self.net.eval()
def forward(self, input, thresh, anchors, case):
output_13, output_26, output_52 = self.net(input)
index_13, bias_13 = self.get_index_and_bias(output_13, thresh)
boxes_13 = self.get_true_position(index_13, bias_13, 32, anchors[13], case)
index_26, bias_26 = self.get_index_and_bias(output_26, thresh)
boxes_26 = self.get_true_position(index_26, bias_26, 16, anchors[26], case)
index_52, bias_52 = self.get_index_and_bias(output_52, thresh)
boxes_52 = self.get_true_position(index_52, bias_52, 8, anchors[52], case)
return torch.cat([boxes_13, boxes_26, boxes_52], dim=0)
def get_index_and_bias(self, output, thresh):
output = output.permute(0, 2, 3, 1)
output = output.reshape(output.size(0), output.size(1), output.size(2), 3, -1)
mask = output[..., 0] >=thresh
index = mask.nonzero()
bias = output[mask]
return index, bias
def get_true_position(self, index, bias, t, anchors, case):
anchors = torch.Tensor(anchors).to(self.device)
a = index[:, 3]
cy = (index[:, 1].float() + bias[:, 2].float()) * t / case
cx = (index[:, 2].float() + bias[:, 1].float()) * t / case
w = anchors[a, 0] * torch.exp(bias[:, 3]) / case
h = anchors[a, 1] * torch.exp(bias[:, 4]) / case
p = bias[:, 0]
cls_p = bias[:, 5:]
cls_index = torch.argmax(cls_p, dim=1)
return torch.stack([torch.sigmoid(p), cx, cy, w, h, cls_index], dim=1)
if __name__ == '__main__':
detector = Detector()
detector_img='images/test_img/000010.jpg'
img=Image.open(detector_img)
_img=make_416_image(img)
temp = max(_img.size)
case = 416 / temp
_img = _img.resize((416, 416))
_img = tf(_img).to(detector.device)
_img = torch.unsqueeze(_img, dim=0)
results = detector(_img, 0.5, anchors, case)
draw = ImageDraw.Draw(img)
for rst in results:
x1, y1, x2, y2 = rst[1] - 0.5 * rst[3], rst[2] - 0.5 * rst[4], rst[1] + 0.5 * rst[3], rst[2] + 0.5 * rst[4]
print(x1, y1, x2, y2)
print('class', num_class[int(rst[5])])
draw.text((x1, y1), str(num_class[int(rst[5].item())]) + str(rst[0].item())[:4])
draw.rectangle((x1, y1, x2, y2), outline='red', width=1)
img.show()
Original: https://blog.csdn.net/qq_44173974/article/details/124402679
Author: 可乐大牛
Title: 【目标检测】YOLO v3
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/683085/
转载文章受原作者版权保护。转载请注明原作者出处!