

文章目录
- 一:Faster R-CNN的改进
- 二:网络架构
- 三:Conv layers模块
- 四:Region Proposal Networks(RPN)模块
* - 【Module 1】
– - 【Module 2】
- 五:Semi-Fast R-CNN(RoiHead)
* - 【训练阶段】
– - 【测试阶段】
- 六:Faster R-CNN训练方法
- 七:Faster R-CNN测试方法
*
– - 八:总结
一:Faster R-CNN的改进
想要更好地了解Faster R-CNN,需先了解传统R-CNN和Fast R-CNN原理,可参考本人呕心撰写的两篇博文 R-CNN史上最全讲解 和 Fast R-CNN讲解。
回到正题,经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN。从网络命名上看就很直白,那么相较于Faster R-CNN到底Faster在哪儿里呢?答案就是:region proposal的提取方式的改变。
Fast R-CNN虽然提出了ROI Pooling的特征提取方式,很好地解决了传统R-CNN中将 Region Proposal区域分别输入CNN网络中的弊端。 但是!!!始终都是用的传统Selective Search搜索方式确定Region Proposal,训练和测试时消耗了大量时间在RP搜索上。而Faster R-CNN突破性地使用了RPN网络直接提取出RP,并将其融入进整体网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
二:网络架构


上图展示了python版本中的VGG16模型中的
faster_rcnn_test.pt的网络结构,可以清晰的看到该网络架构分为以下几个模块:
- Conv layers
该Backbone层主要用来提取输入图像中的特征,生成Feature Map以供后两个模块使用。 - Region Proposal Networks(RPN)
RPN模块用来训练提取出原图中的Region Proposal区域,是整个网络模型中最重要的一个模块。 - Semi-Fast R-CNN
Semi-Fast R-CNN是我自创的命名,因为和Fast R-CNN的head层几乎一模一样,更多叫法是RoiHead层。当通过RPN模块确定了RP后,就可以训练Fast R-CNN网络了,完成对RP区域的分类与bbox框的微调。
综上述可见, 细心的人会发现,Conv layers+Semi-Fast R-CNN不就是Fast R-CNN嘛!所以,Faster R-CNN网络实际上就是RPN + Fast R-CNN,也就是 two-stage,训练时也是对两个模块分开训练, 测试时先由RPN生成RP,再将带有RP的Feature Map输入进Fast R-CNN中完成分类和预测框回归任务。下面,我将依次对三个模块进行详细讲解。
; 三:Conv layers模块

Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型中 faster_rcnn_test.pt的网络结构为例。Conv layers部分共有13个conv层,13个relu层,4个pooling层。不太熟悉VGG16的小伙伴们要注意一下 两个细节:
- 所有的conv层都是:kernel_size=3,pad=1,stride=1
- 所有的pooling层都是:kernel_size=2,pad=0,stride=2
经过Conv layers模块后,一个MxN (800×600)大小的输入图像就变为了(M/16)x(N/16)的Feature Map! 这样Conv layers生成的feature map中都可以和原图对应起来。
四:Region Proposal Networks(RPN)模块

终于迎来了最重要的RPN模块,大家提起精神,和我一起分析!RPN说到底就是两个功能模块, 第一个功能模块是利用二分类给每个anchor打出前景得分,并利用回归计算出每个anchor与其对应的GT间的四个微调参数。 第二个功能模块则是根据第一个功能模块输出的得分和四个微调参数,得出ROI并选出合适的RP。
其实RPN只有第一个功能模块需要训练,第二个模块都是基本的选择运算,没有参数需要训练,只是为RoiHead选出训练和测试要用到的region proposal。下面我从这两个功能模块依次讲解:
; 【Module 1】
在第一模块中,将讲解如何在原图中生成anchors并进行标注,又是如何利用标注好的anchors训练RPN对每个anchor进行前景与背景的二分类与anchor位置的回归微调。下面分步骤进行讲解:
step1: generate_anchor_base
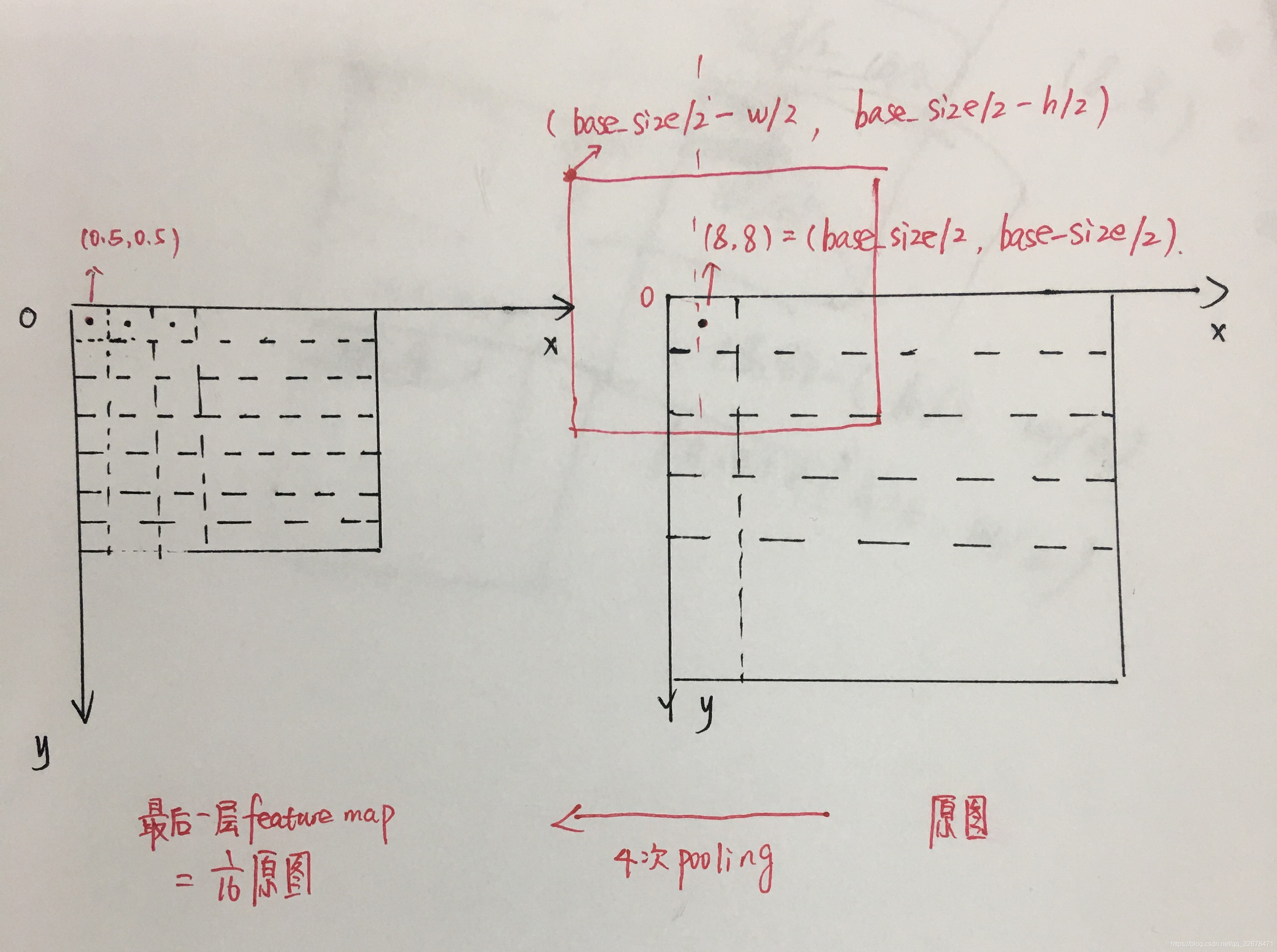
首先,我们需要使用 generate_anchor_base函数生成anchors。代码的主要实现思想:首先以特征图 feature map的左上角点为基准产生 9个anchor,三种尺度,每个尺度再对应三种比例。接着,将特征图左上角的9个anchors乘上原图的缩放比例base_size,也就是经过4个池化层后的 16倍。锚点由特征图中的 (0.5,0.5)变为了原图上的 (8,8),原图上的9个anchors的w和h也变为16倍。然后以原图左上角的anchors为基准,每隔base_size个像素,画9个anchors。画完之后,原图上大概有20000个anchors。
具体实现方法,见如下代码并附手写图:
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]):
py = base_size / 2.
px = base_size / 2.
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4),
dtype=np.float32)
for i in six.moves.range(len(ratios)):
for j in six.moves.range(len(anchor_scales)):
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
'''
这9个anchor形状应为:
90.50967 *181.01933 = 128^2
181.01933 * 362.03867 = 256^2
362.03867 * 724.07733 = 512^2
128.0 * 128.0 = 128^2
256.0 * 256.0 = 256^2
512.0 * 512.0 = 512^2
181.01933 * 90.50967 = 128^2
362.03867 * 181.01933 = 256^2
724.07733 * 362.03867 = 512^2
该函数返回值为anchor_base,形状9*4,是9个anchor的左上右下坐标:
-37.2548 -82.5097 53.2548 98.5097
-82.5097 -173.019 98.5097 189.019
-173.019 -354.039 189.019 370.039
-56 -56 72 72
-120 -120 136 136
-248 -248 264 264
-82.5097 -37.2548 98.5097 53.2548
-173.019 -82.5097 189.019 98.5097
-354.039 -173.019 370.039 189.019
'''
index = i * len(anchor_scales) + j
anchor_base[index, 0] = py - h / 2.
anchor_base[index, 1] = px - w / 2.
anchor_base[index, 2] = py + h / 2.
anchor_base[index, 3] = px + w / 2.
return anchor_base
由于后面讲解中有一些转换函数的运用,在这里先贴上,大家可以根据注释先行理解:
def loc2bbox(src_bbox, loc):
if src_bbox.shape[0] == 0:
return xp.zeros((0, 4), dtype=loc.dtype)
src_bbox = src_bbox.astype(src_bbox.dtype, copy=False)
src_height = src_bbox[:, 2] - src_bbox[:, 0]
src_width = src_bbox[:, 3] - src_bbox[:, 1]
src_ctr_y = src_bbox[:, 0] + 0.5 * src_height y0+0.5h
src_ctr_x = src_bbox[:, 1] + 0.5 * src_width
dy = loc[:, 0::4]
dx = loc[:, 1::4]
dh = loc[:, 2::4]
dw = loc[:, 3::4]
RCNN中提出的边框回归:寻找原始proposal与近似目标框G之间的映射关系,公式在上面
ctr_y = dy * src_height[:, xp.newaxis] + src_ctr_y[:, xp.newaxis]
ctr_x = dx * src_width[:, xp.newaxis] + src_ctr_x[:, xp.newaxis]
h = xp.exp(dh) * src_height[:, xp.newaxis]
w = xp.exp(dw) * src_width[:, xp.newaxis]
dst_bbox = xp.zeros(loc.shape, dtype=loc.dtype)
dst_bbox[:, 0::4] = ctr_y - 0.5 * h
dst_bbox[:, 1::4] = ctr_x - 0.5 * w
dst_bbox[:, 2::4] = ctr_y + 0.5 * h
dst_bbox[:, 3::4] = ctr_x + 0.5 * w
return dst_bbox
def bbox2loc(src_bbox, dst_bbox):
height = src_bbox[:, 2] - src_bbox[:, 0]
width = src_bbox[:, 3] - src_bbox[:, 1]
ctr_y = src_bbox[:, 0] + 0.5 * height
ctr_x = src_bbox[:, 1] + 0.5 * width
base_height = dst_bbox[:, 2] - dst_bbox[:, 0]
base_width = dst_bbox[:, 3] - dst_bbox[:, 1]
base_ctr_y = dst_bbox[:, 0] + 0.5 * base_height
base_ctr_x = dst_bbox[:, 1] + 0.5 * base_width
eps = xp.finfo(height.dtype).eps
height = xp.maximum(height, eps)
width = xp.maximum(width, eps)
dy = (base_ctr_y - ctr_y) / height
dx = (base_ctr_x - ctr_x) / width
dh = xp.log(base_height / height)
dw = xp.log(base_width / width)
loc = xp.vstack((dy, dx, dh, dw)).transpose()
return loc
def bbox_iou(bbox_a, bbox_b):
if bbox_a.shape[1] != 4 or bbox_b.shape[1] != 4:
raise IndexError
tl = xp.maximum(bbox_a[:, None, :2], bbox_b[:, :2])
br = xp.minimum(bbox_a[:, None, 2:], bbox_b[:, 2:])
area_i = xp.prod(br - tl, axis=2) * (tl < br).all(axis=2)
area_a = xp.prod(bbox_a[:, 2:] - bbox_a[:, :2], axis=1)
area_b = xp.prod(bbox_b[:, 2:] - bbox_b[:, :2], axis=1)
return area_i / (area_a[:, None] + area_b - area_i)
step2: AnchorTargetCreator
在原图中生成了近乎 20000个anchors后,使用 AnchorTargetCreator函数对它们进行标注以用于训练。代码的主要实现思想: 针对于label的标注,首先剔除掉超过原图边界的anchors,剩下将近15000个。接着,计算每一个anchor与哪个bbox的iou最大以及这个iou值, IOU>0.7的anchor为pos_anchor, IOU<0.3的anchor为neg_anchor。同时,还需计算每个bbox与哪个anchor的iou最大(其实就是矩阵中行最大和列最大的区别),每个bbox对应的最大IOU的anchors也直接设为pos_anchor。但是最后还需要在pos和neg中各随机选 128个,也就是 128个正样本和128个负样本,将128个正样本的label设置为1,将128个负样本的label设置为0,剩下的(20000-256)个anchors的labels都设为0。 针对4个回归框的参数标注,首先对超框的都设为(0,0,0,0),框内的近乎15000个anchors的4个参数就是它们与最大IOU对应的bbox的实际偏移量。具体代码见下:
class AnchorTargetCreator(object):
def __call__(self, bbox, anchor, img_size):
img_H, img_W = img_size
n_anchor = len(anchor)
inside_index = _get_inside_index(anchor, img_H, img_W)
anchor = anchor[inside_index]
argmax_ious, label = self._create_label(inside_index, anchor, bbox)
loc = bbox2loc(anchor, bbox[argmax_ious])
label = _unmap(label, n_anchor, inside_index, fill=-1)
loc = _unmap(loc, n_anchor, inside_index, fill=0)
return loc, label
def _create_label(self, inside_index, anchor, bbox):
label = np.empty((len(inside_index),), dtype=np.int32)
label.fill(-1)
argmax_ious, max_ious, gt_argmax_ious = self._calc_ious(anchor, bbox, inside_index)
调用_calc_ious()函数得到每个anchor与哪个bbox的iou最大以及这个iou值、每个bbox与哪个anchor的iou最大(需要体会从行和列取最大值的区别)
label[
max_ious < self.neg_iou_thresh] = 0
label[gt_argmax_ious] = 1
label[max_ious >= self.pos_iou_thresh] = 1
n_pos = int(self.pos_ratio * self.n_sample)
pos_index = np.where(label == 1)[0]
if len(pos_index) > n_pos:
disable_index = np.random.choice(
pos_index, size=(len(pos_index) - n_pos), replace=False)
label[disable_index] = -1
n_neg = self.n_sample - np.sum(label == 1)
neg_index = np.where(label == 0)[0]
if len(neg_index) > n_neg:
disable_index = np.random.choice(
neg_index, size=(len(neg_index) - n_neg),
replace=False)
label[disable_index] = -1
return argmax_ious, label
def _calc_ious(self, anchor, bbox, inside_index):
ious = bbox_iou(anchor, bbox)
argmax_ious = ious.argmax(axis=1)
max_ious = ious[np.arange(len(inside_index)), argmax_ious]
gt_argmax_ious = ious.argmax(axis=0)
gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])]
gt_argmax_ious = np.where(ious == gt_max_ious)[0]
return argmax_ious, max_ious, gt_argmax_ious
step3:训练RPN
生成并标注完了训练样本,终于来到了第一功能模块的训练环节。 首先对Feature Map进行 3×3卷积操作,而后分为两个分支,每一分支都先进行 1×1卷积操作,目的是压缩channel。 第一个分支的通道数压缩成 9×2,9代表每一个锚点的9个anchors,2代表每一个anchor是前景或后景的概率。 第二个分支的通道数压缩成 9×4,9代表每一个锚点的9个anchors,4代表每一个anchor的4个位置参数预测值。 每一个min-batch,只对128个负样本和128个正样本计算分类损失和回归损失( 实际上只对正样本进行回归损失计算)。损失函数如下:

分类损失函数选择的是传统的交叉熵损失函数,分类损失函数选择的是Smooth L1 Loss回归损失函数,如下:

由于在实际过程中,N c N_c N c = min_batch ,N r N_r N r = feature map的大小,两者差距过大,用参数λ平衡二者,使总的网络Loss计算过程中能够均匀考虑2种Loss。
; 【Module 2】
第二个模块则是根据第一个功能模块输出的得分和四个位置参数,得出ROI并选出合适的RP。该模块在 ProposalCreator函数中完成,代码的核心思想:通过训练好的第一个模块输出的约 20000个anchor的4个位置参数,微调原图中所有anchor,生成 20000个ROI。接着,对ROI进行裁剪,并且剔除掉裁剪后长和宽小于设定阈值的ROI。然后,根据前景score对剩余ROI进行由大到小的排序, 若用于RoiHead训练,则取 前12000个ROI,经过NMS二次筛选后只取 前2000个ROI作为最终的region proposals。 若用于RoiHead测试,则取 前2000个ROI,经过NMS二次筛选后只取 前300个ROI作为最终的region proposals。具体代码实现如下:
class ProposalCreator:
def __call__(self, loc, score, anchor, img_size,
scale=1.):
if self.parent_model.training:
n_pre_nms = self.n_train_pre_nms
n_post_nms = self.n_train_post_nms
else:
n_pre_nms = self.n_test_pre_nms
n_post_nms = self.n_test_post_nms
roi = loc2bbox(anchor, loc)
roi[:, slice(0, 4, 2)] = np.clip(roi[:, slice(0, 4, 2)], 0, img_size[0])
roi[:, slice(1, 4, 2)] = np.clip(roi[:, slice(1, 4, 2)], 0, img_size[1])
min_size = self.min_size * scale
hs = roi[:, 2] - roi[:, 0]
ws = roi[:, 3] - roi[:, 1]
keep = np.where((hs >= min_size) & (ws >= min_size))[0]
roi = roi[keep, :]
score = score[keep]
order = score.ravel().argsort()[::-1]
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
keep = non_maximum_suppression(
cp.ascontiguousarray(cp.asarray(roi)),
thresh=self.nms_thresh)
if n_post_nms > 0:
keep = keep[:n_post_nms]
roi = roi[keep]
return roi
五:Semi-Fast R-CNN(RoiHead)
介绍完了RPN模块后,最重要的RP提取任务已经完成。接下来RoiHead只要将RPN输出的RP结果作为输入,来训练和测试。我将训练阶段和测试模块分开讲解:
【训练阶段】
step1:RP中标注训练样本
如果是在训练阶段,RPN会输出大约2000个region proposals。那么如何从中选取样本并标注呢? ProposalTargetCreator函数实现了这一任务,代码的核心思想是:首先,将 2000个RP和 M个Ground Truth拼接起来, 也就是把所有的GT也都作为RP。为什么呢?
前方核能:其实答案很简单,现在是RoiHead的训练阶段,训练RoiHead的分类和二次回归能力。也就是说,需要给该网络输入带有类别标注和实际位置参数的训练数据,经过RPN选出的大范围包括实物的ROI可以作为训练数据,说实话也都是歪歪扭扭的,拿它们训练RoiHead其实主要是出于测试阶段的实际情况出发的,毕竟要从任务实际需要适应的情况出发,实际测试的时候都是RPN找出RP,RoiHead再对它们进行分类和bbox修正的,这些RP都是歪歪扭扭的。所以也就是说,拿这些样本进行分类本身就是不严谨的,不是说完完全全包裹住实物合格的类别样本。 毕竟现在是训练阶段嘛,稍微偷偷喂给网络一点”优质碳水”,未尝不可,直接把最优质的GT给它训练去,货真价实的分类样本,舒不舒服,白用白不用。
回到正题,拼接好了RP和GT后,计算它们的最大IOU所对应的那个GT的label,将(label+1)作为每一个RP的类别标注(1~20)。然后将IOU>0.5的RP中选 64个作为正样本,将 IOU<0.5的RP中选出 64个作为负样本并将负样本的label设为0, 最后将共128个正负样本打包出来,作为RoiHead的训练输入。具体的实现代码如下:
class ProposalTargetCreator(object):
def __call__(self, roi, bbox, label, loc_normalize_mean=(0., 0., 0., 0.),
loc_normalize_std=(0.1, 0.1, 0.2, 0.2)):
n_bbox, _ = bbox.shape
roi = np.concatenate((roi, bbox), axis=0)
pos_roi_per_image = np.round(
self.n_sample * self.pos_ratio)
iou = bbox_iou(roi, bbox)
gt_assignment = iou.argmax(axis=1)
max_iou = iou.max(axis=1)
gt_roi_label = label[gt_assignment] + 1
pos_index = np.where(max_iou >= self.pos_iou_thresh)[0]
pos_roi_per_this_image = int(
min(pos_roi_per_image, pos_index.size))
if pos_index.size > 0:
pos_index = np.random.choice(
pos_index, size=pos_roi_per_this_image, replace=False)
neg_index = np.where((max_iou < self.neg_iou_thresh_hi) &
(max_iou >= self.neg_iou_thresh_lo))[0]
neg_roi_per_this_image = self.n_sample - pos_roi_per_this_image
neg_roi_per_this_image = int(min(neg_roi_per_this_image,
neg_index.size))
if neg_index.size > 0:
neg_index = np.random.choice(
neg_index, size=neg_roi_per_this_image, replace=False)
keep_index = np.append(pos_index, neg_index)
gt_roi_label = gt_roi_label[keep_index]
gt_roi_label[pos_roi_per_this_image:] = 0
sample_roi = roi[keep_index]
gt_roi_loc = bbox2loc(sample_roi, bbox[gt_assignment[keep_index]])
gt_roi_loc = ((gt_roi_loc - np.array(loc_normalize_mean, np.float32)
) / np.array(loc_normalize_std,
np.float32))
return sample_roi, gt_roi_loc, gt_roi_label
step2: 正式训练
将这128个标注好的训练样本,从原图中投影到Feature Map中对应的ROI区域中,然后进入RoiPooling层,将这些大小不一的ROI区域变为同一长度的向量,再经过两层 4096 FC层,分别得到softmax21分类打分和bbox的 84个参数 (21 * 4)的预测结果,放入损失函数中进行反向传播更新网络权重,其中只计算正样本的回归框损失。损失函数和RPN的类似,这里就不再赘述了,贴上损失函数核心代码:
def _fast_rcnn_loc_loss(pred_loc, gt_loc, gt_label, sigma):
in_weight = t.zeros(gt_loc.shape).cuda()
in_weight[(gt_label > 0).view(-1, 1).expand_as(in_weight).cuda()] = 1
loc_loss = _smooth_l1_loss(pred_loc, gt_loc, in_weight.detach(), sigma)
loc_loss /= ((gt_label >= 0).sum().float())
return loc_loss
roi_cls_loss = nn.CrossEntropyLoss()(roi_score, gt_roi_label.cuda())
【测试阶段】
RoiHead的测试阶段就是将RPN中输出的300个RP,输入进网络中,最后会输出每个RP的类和4个回归框微调参数。剔除掉高于背景(0)阈值和最大类别(1~20)得分低于阈值的RP,最后根据回归参数,对筛选后剩下的RP框进行微调,得到最终的bounding box!至此,大功告成。
六:Faster R-CNN训练方法
Faster-RCNN有两种训练方式: 四步交替迭代训练和联合训练。本文主要讲解四步交替迭代的训练方式,如下所示:
1、训练RPN,使用大型数据集预训练模型初始化共享卷积和RPN权重,端到端训练RPN,用于生成Region Proposals;
2、训练Fast R-CNN,使用相同的预训练模型初始化共享卷积【注意此处是初始化一个新的与第1步结构相同的共享卷积网络,而不是第1步中训练得到的】,锁住第1步训练好的RPN权重,结合RPN得到的Proposals训练RCNN网络;
3、调优RPN,使用第2步训练好的共享卷积和RCNN,固定共享卷积层,继续训练RPN,我认为这一步相当于对第1步训练好的RPN进行微调;
4、调优Fast R-CNN,使用第3步训练好的共享卷积和RPN(固定住共享卷积层),继续对RCNN进行训练微调
5、重复上述步骤3、4,进行迭代。(一般到步骤四其实已经够了,后面迭代训练后的效果几乎无提升)
下面是一张训练过程流程图,应该更加清晰:

; 七:Faster R-CNN测试方法
接下面讲解整个网络的测试过程,即将大功告成啦!
step1:输入图像经过卷积层得到feature map
step2:feature map经过RPN得到300个RP
step3:将RP输入到RoiHead网络中
step4:得出每个RP的类别得分和bbox位置参数
step5:由得分阈值选出最终的ROI
step6:结合位置参数微调ROI的bbox框
step7:经过NMS后画出最终检测框
八:总结
Fast R-CNN尽管速度和精度上都有了很大的提升,但仍然 未能实现端到端(end-to-end)的目标检测,比如候选区域的获得不能同步进行,速度上还有提升空间。
最后附上一个超大原理流程图收尾,供大家参考:

至此我对Faster R-CNN全部流程与细节,进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。(码字不易,各位看官点个赞,手留余香~谢谢!)
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!
Original: https://blog.csdn.net/weixin_43702653/article/details/124045469
Author: 江南綿雨
Title: Faster R-CNN最全讲解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/626108/
转载文章受原作者版权保护。转载请注明原作者出处!