

目录
一、鸢尾花数据集
1、问题
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
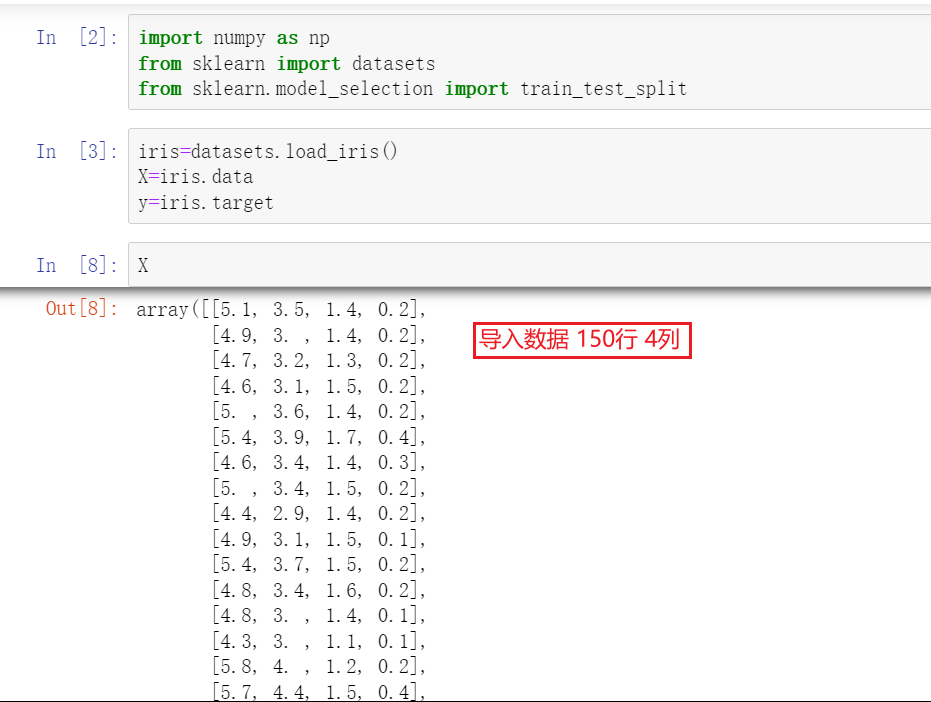

0、1、2分别代表三种鸢尾花种类

二、逻辑回归分析
1、定义:逻辑回归是一个实现分类的算法,可以实现二元分类及多元分类
逻辑回归使用一个函数来归一化y值,使y的取值在区间(0,1)内,这个函数称为 Logistic函数(logistic function),也称为 Sigmoid函数(sigmoid function)。函数公式如下:
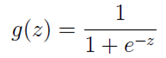
Logistic函数当z趋近于无穷大时,g(z)趋近于1;当z趋近于无穷小时,g(z)趋近于0。Logistic函数的图形如下:
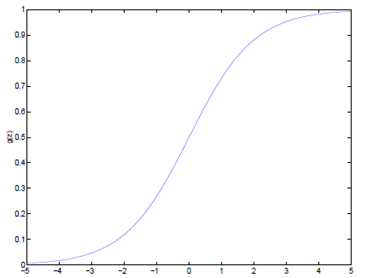
2、计算证明
首先对Sigmoid函数求导:
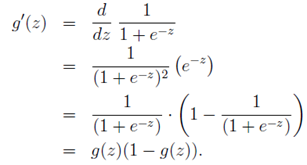
写出逻辑回归的表达式(这里的x有特殊含义表示函数值取1):
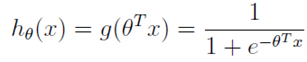
然后写出取值为0或者1的概率表达式:
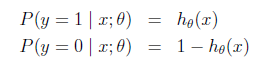
合并后便构造出每个单条样本预测正确概率的公式:
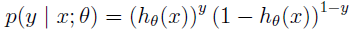
若要我们预测的全部样例正确率最高,我们自然要求得概率最大值,有两种常用的方法:
(1)极大似然估计法
(2)梯度下降法(梯度下降是求最小值,而上述需求最大值所以需要加个负号)
三、逻辑回归实现鸢尾花分类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
#载入数据集
iris = load_iris()
X = X = iris.data[:, :2] #获取花卉两列数据集
Y = iris.target
#逻辑回归模型
lr = LogisticRegression(C=1e5)#c=1e5是目标函数
lr.fit(X,Y)
#meshgrid函数生成两个网格矩阵
h = .02
#初始化逻辑回归模型并进行训练
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
print(xx,yy)
#pcolormesh函数将xx,yy两个网格矩阵和对应的预测结果Z绘制在图片上
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(8,6))
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
plt.show()
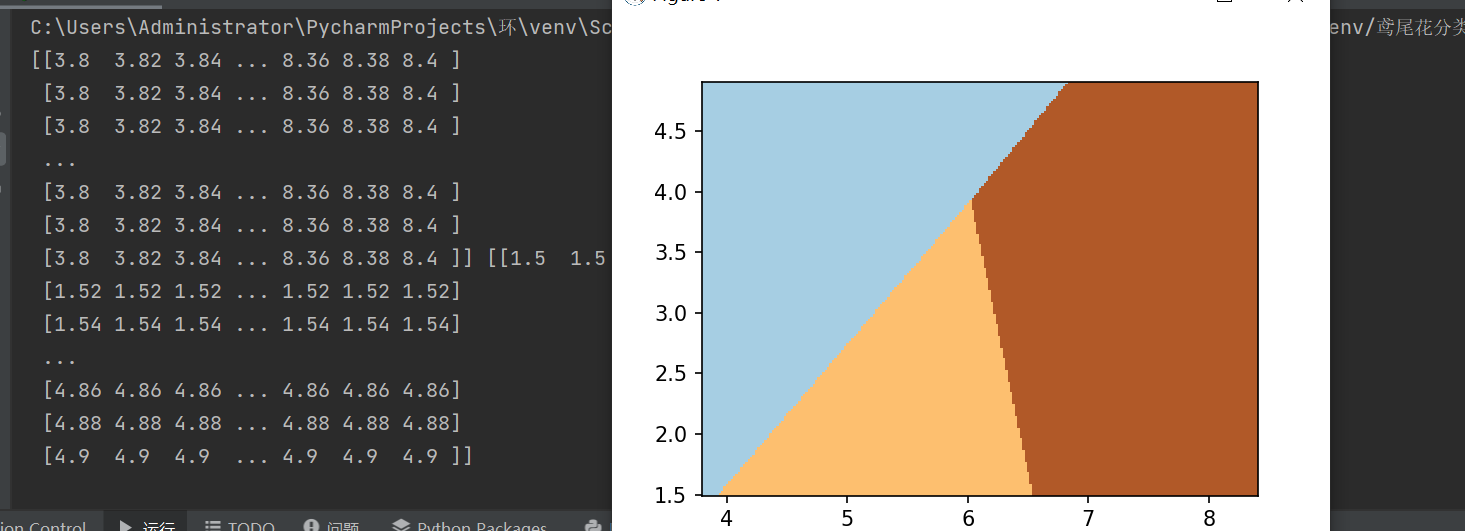
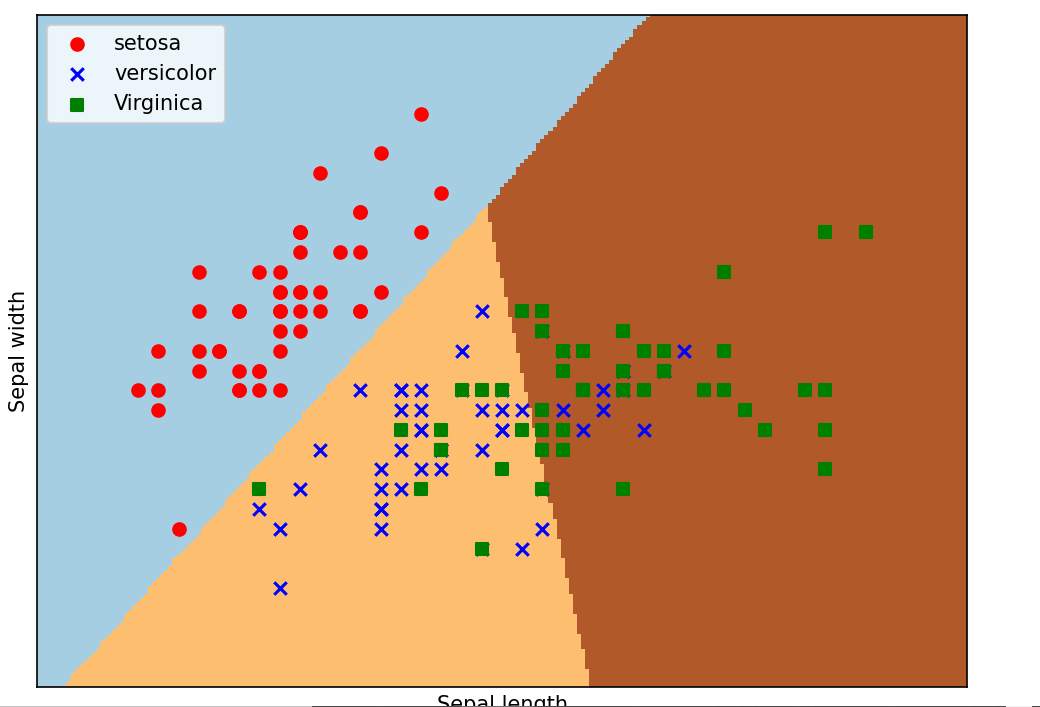
四、绘制散点图
#绘制散点图
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.legend(loc=2)
plt.show()
Original: https://blog.csdn.net/m0_62915153/article/details/122623361
Author: 一罐趣多多
Title: 笔记篇二:鸢尾花数据集分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/622809/
转载文章受原作者版权保护。转载请注明原作者出处!