

评价指标
Inception Score(IS)
计算这个 score 需要用到 Inception Net-V3,评价一个生成模型,需要考虑两个方面的性能:
- 是否清晰。
- 是否多样。
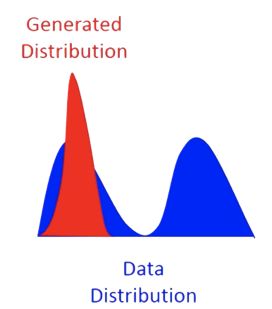
生成的图片不够清晰,说明生成模型表现欠佳。而如果生成的图片不够多样的话,只能生成有限的几种图片,即陷入了 mode collapse,也说明模型表现欠佳,如下图只学到了其中的一个分布。

IS 的评价方法如下:
把生成的图片 x 输入 Inception V3 中,将输出1000维的向量 y,向量的每个维度的值对应图片属于某类的概率。对于一个清晰的图片,它属于某一类的概率应该非常大,而属于其它类的概率应该很小。即 p ( y ∣ x ) 的熵应该很小(清晰度)。
如果一个模型能生成足够多样的图片,那么它生成的图片在各个类别中的分布应该是平均的,假设生成了10000张图片,那么最理想的情况是,1000 类中每类生成了10张。即 p ( y ) 的熵很大(多样性)。
熵代表混乱度,均匀分布的混乱度最大。
熵反映的是一个系统的混乱程度,一个系统越混乱,其熵就越大;越是有序,其熵就越小。
FID
Fréchet Inception Distance(FID)计算了真实图片和生成图片在特征层面的距离,其公式如下:
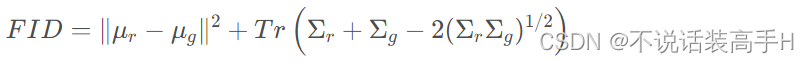
从左到右的参数依次是:真实图片的特征的均值、生成的图片的特征的均值、真实图片的特征的协方差矩阵、生成图片的特征的协方差矩阵。Tr 是矩阵的迹,主对角线上的元素和。
FID 从原始图像的计算机视觉特征的统计方面的相似度来衡量两组图像的相似度,同样是用 Inception v3 图像分类模型计算的得到的。使用 Inception v3 最后一个池化层(即全局空间池化层)的激活函数输出值,输出为 2,048 维的激活向量。因此,每个图像被预测为一个2048维特征向量。
分数越低代表两组图像越相似,或者说二者的统计量越相似,FID 在最佳情况下的得分为 0.0,表示两组图像相同。
发展历史
GAN
机器学习模型分为两大类,一类是判别模型,一类是生成模型。前者是对一个输入数据判断它的类别或者预测一个实际的数值,后者关注的是怎样生成这个数据本身。
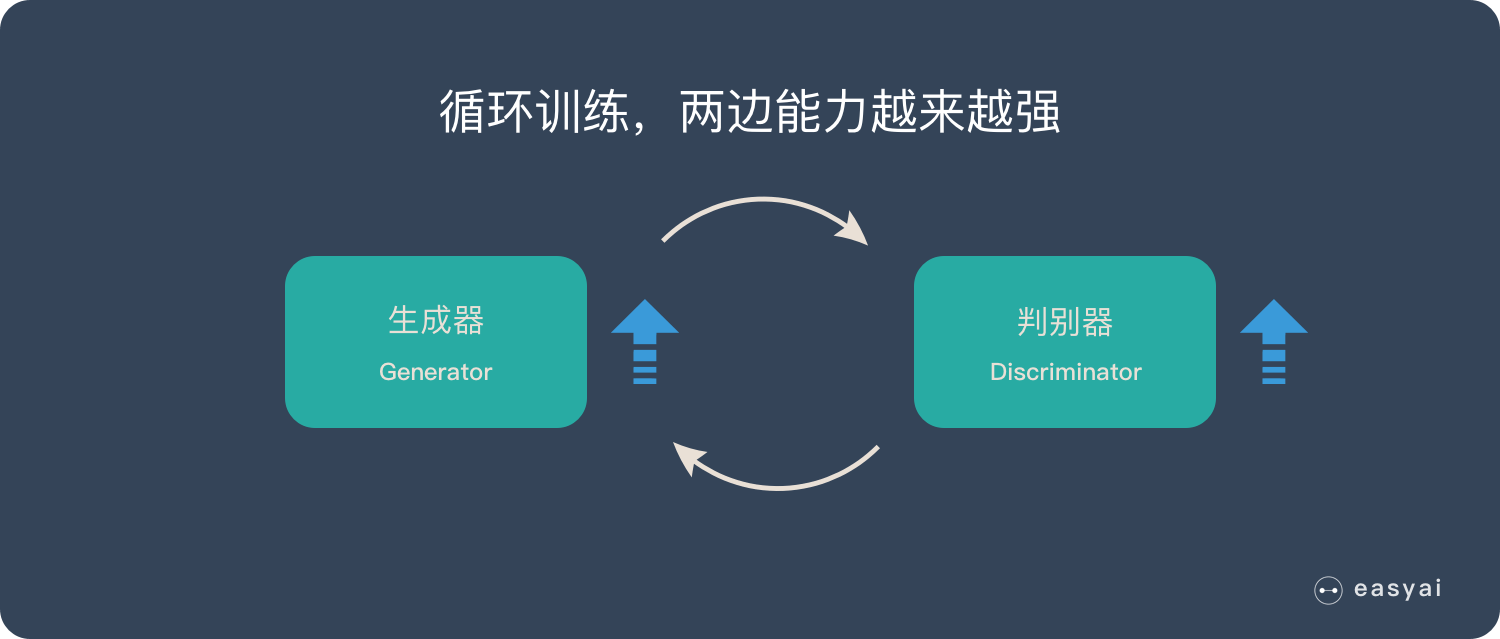
GAN 包含两个部分,第一个部分是是生成器(Generator),另一个是判别器(Discriminator),都是由 MLP 实现的。
生成器的任务是生成看起来自然真实的、与原始数据类似、用以骗过判别器的实例。输入时一个随机噪声,通过噪声生成图片。
判别器的任务是判断生成器生成的实例是真实的还是伪造的。输入时一张图片,输出为输入图片是真实图片的概率。
其损失函数为:
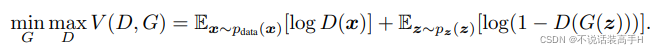
然后从式子中解释对抗,我们知道G网络的训练是希望 D(G(z)) 趋近于1,也就是正类,这样G的loss就会最小。
而D网络训练的是一个2分类,目标是分清楚真实数据和生成数据。D网络希望真实数据 x 的 D(x) 输出趋近于1,生成数据 z 的输出即 D(G(z)) 趋近于0。
这里就是体现了对抗的思想。
下面这张图是 GAN 训练中的几个阶段:
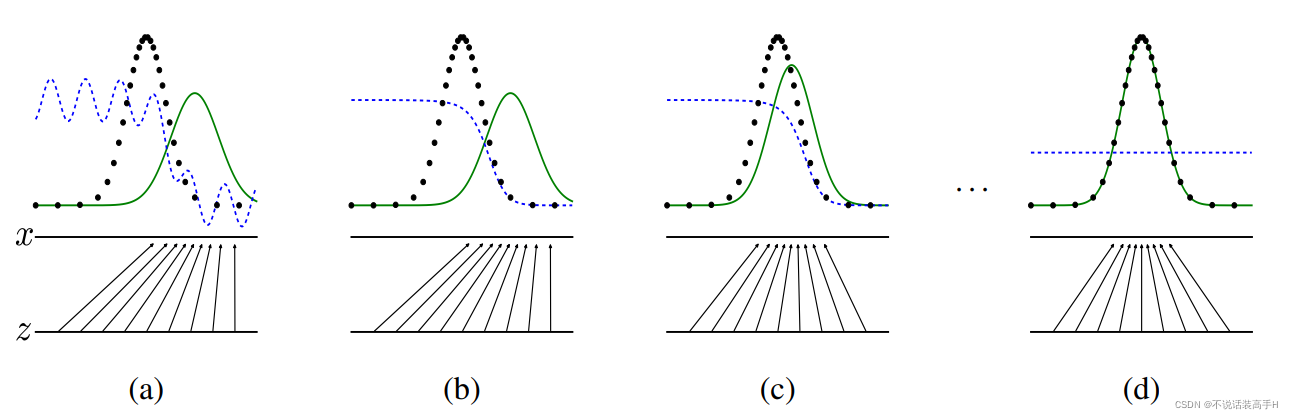
图中黑点是真实数据的分布,绿线是生成数据的分布,蓝线是判别器的判别曲线。图 a 是训练刚开始,判别器还没有特别强的判别能力,可以看到真实数据、生成数据的峰值附近判别器的打分不是很稳定。图 b 中判别器能够判别出生成数据和真实数据,各数据的峰值附近判别器能够准确判别。图 c 中生成器已经近似学习出了真实数据的分布,这时峰值附近判别器的效果已经十分糟糕。图 d 是最理想的情况,生成器完全拟合了真实数据的分布,而判别器已经躺平,两种数据判定都会输出0.5。
生成器、判别器、优化器以及损失函数的定义如下:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
生成器和判别器
generator = Generator()
discriminator = Discriminator()
参数分别放进优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
损失函数为交叉熵损失
adversarial_loss = torch.nn.BCELoss()
在每一次 iter 中训练生成器并更新参数:
训练生成器
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
gen_imgs = generator(z)
g_loss = adversarial_loss(discriminator(gen_imgs), valid) # valid 是全为1的 gt
更新生成器参数
g_loss.backward()
optimizer_G.step()
接着训练判别器并更新参数:
训练判别器
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake) # fake 是全为0的 gt
d_loss = (real_loss + fake_loss) / 2
更新判别器参数
d_loss.backward()
optimizer_D.step()
GAN 训练到最后会达到纳什均衡,即生成器生成图片的分布与真实图片相同。
纳什均衡:对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。
对于GAN,情况就是生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。
这是双方网路都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。
GAN 常见的变体有:DCGAN、CGAN、WGAN 等。
PyTorch-GAN/gan.py at master · eriklindernoren/PyTorch-GAN · GitHub
https://arxiv.org/pdf/1406.2661.pdf
DCGAN
在 GAN 的基础上,使用卷积网络替代了 MLP。
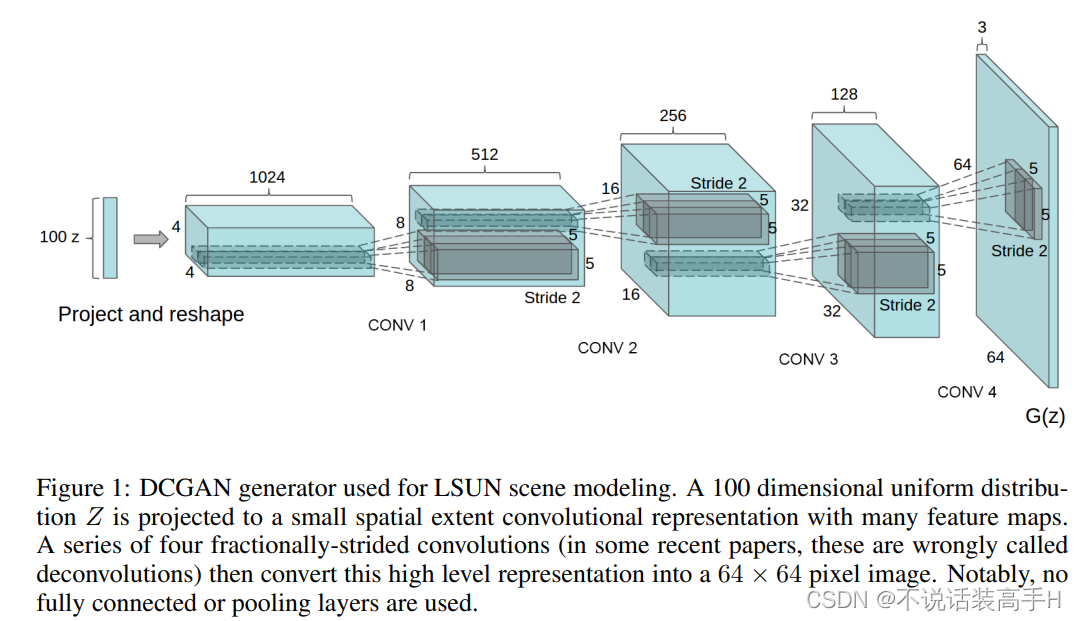
直接看代码:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
其余部分跟 GAN 几乎一模一样。
https://mp.weixin.qq.com/s/qvNT_QjQh0NkDl6bgsnfwg
https://arxiv.org/pdf/1511.06434.pdf
CGAN
全称 Conditional GAN,在 GAN 的训练中加入了类别信息,希望生成指定类别的数据。
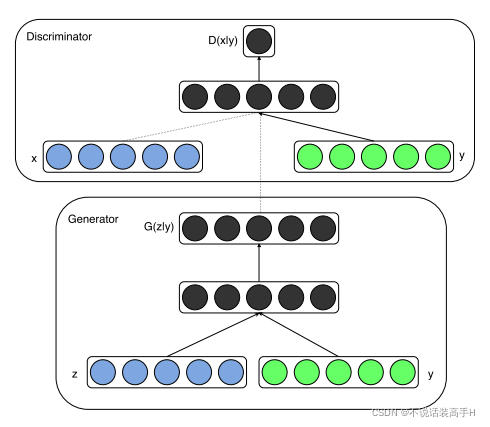
损失函数也加入了标签信息,变为了:
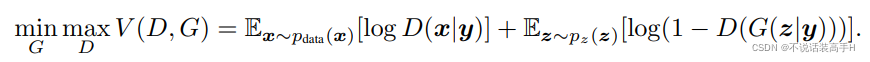
这里的 y 可以是标签,也可以是其他类型的数据。除此之外提出了一种新的标签生成方法,利用这篇文章的方法,利用词向量的特征来学习更泛化的表达。
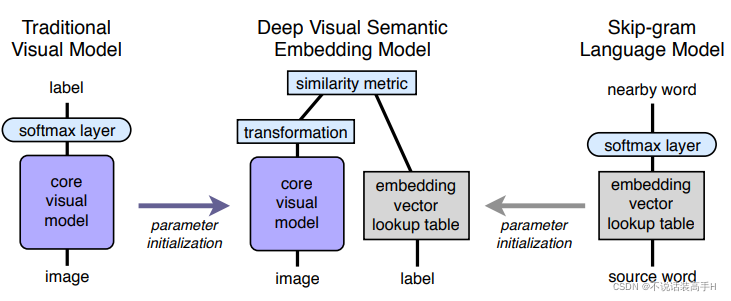
使用点积相似性(dot-product similarity)和 hinge rank loss 结合来作为该模型的损失函数,这可以使得在图像模型的输出和该图像对应的正确的标签的向量表示之间的点积相似性,要比不正确的其他标签的向量与该图像的相似性高。
输入是一张图片,输出是一组标签。具体流程是利用一个训练好的图像判别器(CNN)和一个训练好的词向量模型(skip-gram),分别抽取图像信息和标签向量化。将该图像特征作为额外的信息(即模型中绿色的 y 部分)与 x 一起喂给生成器,生成器生成对应的预测向量。对每张图片生成100个预测样本,每个样本通过计算余弦相似度计算选前20个最接近的词作为标签,然后在从这2000个词的候选集中选出最常见的10个作为这张图片的标签。
https://arxiv.org/pdf/1411.1784.pdf
WGAN
全称 Wasserstein GAN,文章从数学的角度探究了 GAN 生成器梯度消失的原因以及 GAN 损失函数种存在的不足。解决了 GAN 训练中存在的如下几个问题:
- 彻底解决 GAN 训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度。
- 基本解决了 collapse mode 的问题,确保了生成样本的多样性。
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表 GAN 训练得越好,代表生成器产生的图像质量越高。
与原始 GAN 相比,只改了四点:
- 判别器最后一层去掉 sigmoid。
- 生成器和判别器的 loss 不取 log。
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数 c。
- 不要用基于动量的优化算法(包括 momentum 和 Adam),推荐 RMSProp,SGD 也行。
使用了 Wasserstein 距离,与 KL 散度、JS 散度相比,即使两个分布没有重叠,依然能够反映他们之间距离的远近。

KL 散度和 JS 散度是突变的,要么最大要么最小,Wasserstein 距离却是平滑的。如果我们要用梯度下降法优化 θ 这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则 KL 和 JS 既反映不了远近,也提供不了梯度,但是 Wasserstein 却可以提供有意义的梯度。
https://arxiv.org/pdf/1701.07875.pdf
InfoGAN
在此之后很多的方法都可以看作是 Conditional GAN 使用监督信息来完成目标生成的例子。然而当缺少标签数据时,如何使用 GAN 来生成,就是 InfoGAN 给出了一个较好的解决方案。即在 GAN 的输入端,除了随机噪音 z 外,没有输入真实图像,而是输入一个 latent code,这个 latent code 应该隐含了我们想要生成的信息。
Thus, to be useful, an unsupervised learning algorithm must in effect correctly guess the likely set of downstream classification tasks without being directly exposed to them.
文章提到,每一个 domain 都可以由许多个变量共同作用而生成。这里的 domain 可以理解为待生成的一类目标:
For instance, when generating images from the MNIST dataset, it would be ideal if the model automatically chose to allocate a discrete random variable to represent the numerical identity of the digit (0-9), and chose to have two additional continuous variables that represent the digit’s angle and thickness of the digit’s stroke.
这样的话,每一个数字都对应一些特征的 latent code,生成这些数字就不需要监督信息了。
这篇文章将互信息(mutual information)引入 GAN 的训练,通过最大化 latent code c 和生成图像的互信息来让模型学到更加 semantic 和 meaningful 的特征:
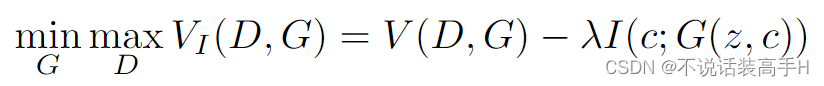
其中 V 是 GAN 原始的损失函数:
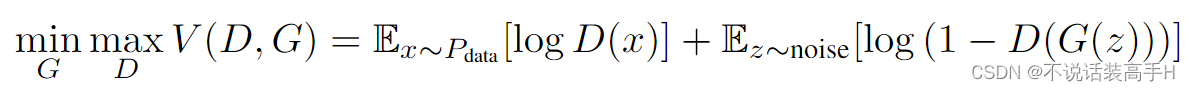
互信息(Mutual Information)是两个随机变量依赖程度的度量,可以表示为:
To cope with the problem of trivial codes, we propose an information-theoretic regularization: there should be high mutual information between latent codes c and generator distribution G(z, c). Thus I(c; G(z, c)) should be high.

实现的时候使用了变分推断的思想。
https://arxiv.org/pdf/1606.03657v1.pdf
InfoGAN:一种无监督生成方法 | 经典论文复现 | 机器之心
Text to Image
该任务的目标是根据文本描述输出图像,这里介绍论文《Generative Adversarial Text to Image Synthesis》的方法,主要有两个难点:
-
first, learn a text feature representation that captures the important visual details.
-
second, use these features to synthesize a compelling image that a human might mistake for real.
先介绍了另一篇文章中的方法,用 CNN or LSTM 来 encode 文本特征。训练时的损失函数是:
其中 vn、tn、yn 依次为图像、文本描述、类别标签,三角是 0-1 loss:
F 是 compatibility score,匹配图像和文本的 compatibility score 要比不匹配的要高:
其中:
推理时使用如下公式,得到的是 compatibility score:
分类器中的 φ 为文本 encoder,ф 为图像 encoder。
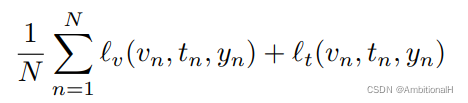
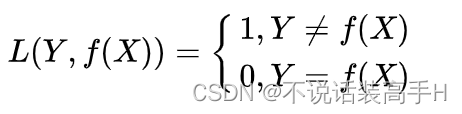
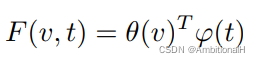
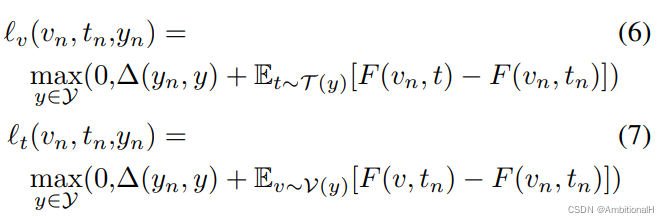
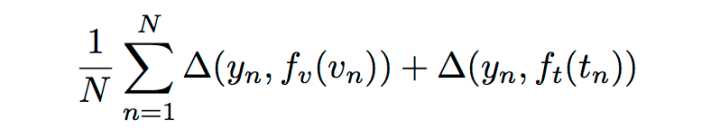
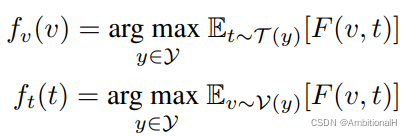
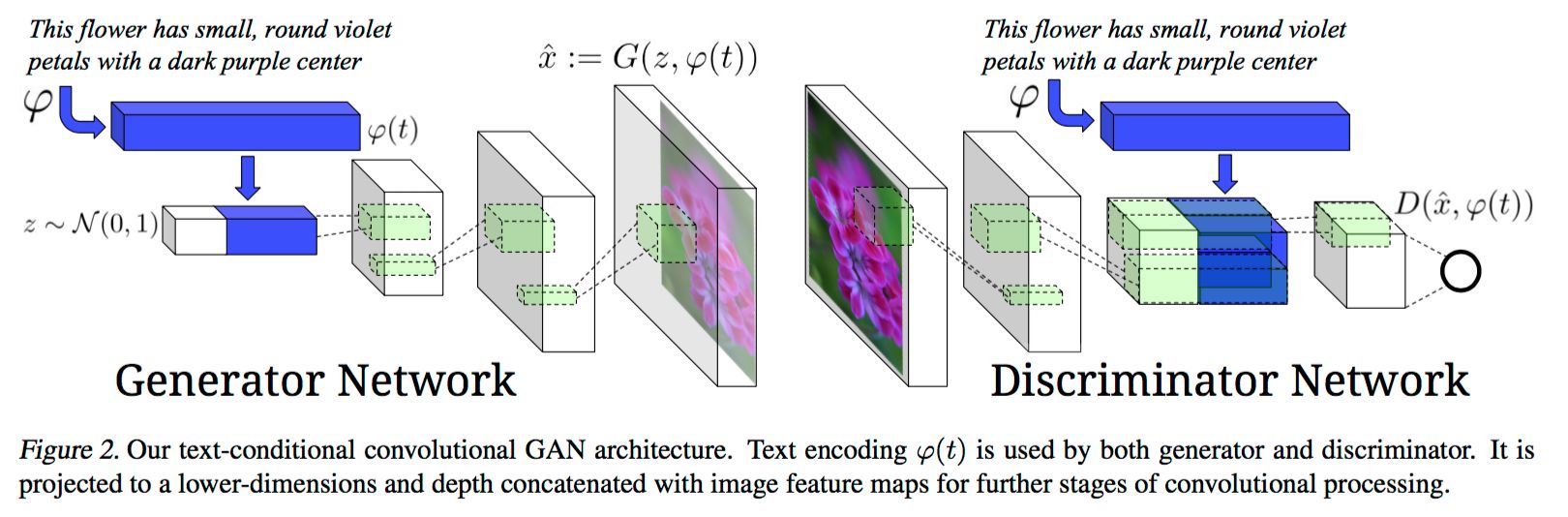
而这篇文章用到了上面这篇的文本 encoder 和 DCGAN,指出了 Conditional GAN 用于 text to image 任务的做法中的一个问题:
This type of conditioning is naive in the sense that the discriminator has no explicit notion of whether real training images match the text embedding context.
在生成器与判别器前加入文本的特征作为 condition。把文本特征经过 fc 压缩至128维后与图像特征拼接在一起送入生成器。在生成器中用拼接后的特征来生成图像,送入判别器得到最后的得分。
本文网络的训练流程为:

Matching-aware discriminator(GAN-CLS)
其判别器的输入只有两种类型:真实图像和 matching text、生成图像和 arbitrary text。为了使模型可以更好地学习文本描述和图片内容的对应关系,于是在这里给判别器增加了第三种输入:真实图像和错误文本。判别器和生成器各自的损失函数为:
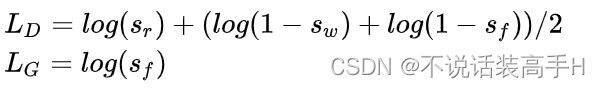
其中 s 为判别器的输出。
Learning with manifold interpolation(GAN-INT)
之后进行了一个 manifold interpolation(GAN-INT)的操作,将两个文本的特征进行差值,得到更丰富的文本特征供生成器学习,相当于稍微更改了生成器的损失函数:
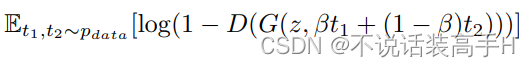
z 为随机噪音,另一个是差值后的文本特征。可以看做是训练的一个 trick。
Inverting the generator for style transfer
文中认为如果 φ 用来捕捉图像内容的话,那么随机噪音 z 应该用于捕捉风格(style)。为了证明这种猜想,作者训练了一个 CNN,用生成器生成的图片预测 style,损失函数如下:
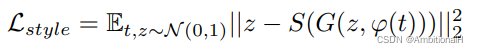
独立于 GAN 的训练,在其训练之前。用于训练输入到生成器中的随机噪音 z,这样的话 z 就包含了 style 信息,与文本特征 φ 一同输入到 GAN 的生成器中:
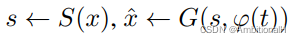
这里也可以看作是训练的 trick
GitHub – aelnouby/Text-to-Image-Synthesis at f6d47e4da06defa974390ce813f734dbee75c885
《Generative Adversarial Text to Image Synthesis》阅读笔记 – 知乎
StackGAN
与《Generative Adversarial Text to Image Synthesis》的做法类似,此前 DCGAN 的网络生成的图像分辨率都比较低:
Samples generated by existing text-to-image approaches can roughly reflect the meaning of the given descriptions, but they fail to contain necessary details and vivid object parts.
StackGAN 包含两个两个阶段的 GAN,第一阶段的对抗生成网络利用文本描述粗略勾画物体主要的形状和颜色,生成低分辨率的图片。第二阶段的对抗生成网络将第一阶段的结果和文本描述作为输入,生成细节丰富的高分辨率图片。
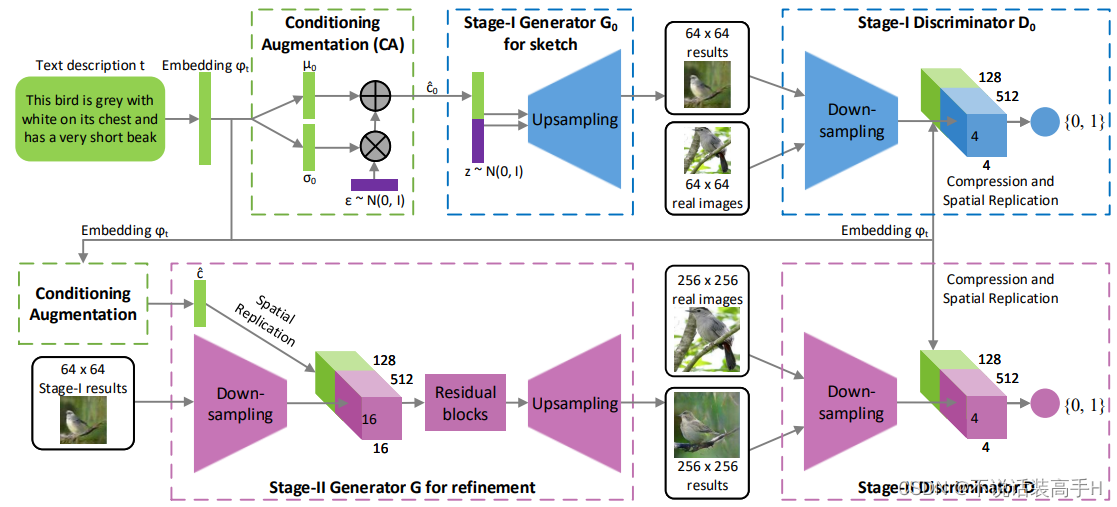
Conditioning Augmentation
作者认为直接将文本特征作为一个 latent variable 不能很好地代表整个 latent space,因此使用 Conditioning Augmentation 来处理文本特征,以期望更好地覆盖 latent space:
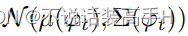
上式中 N 为高斯分布,N 的参数为文本特征的函数。为了防止过拟合或者方差太大的情况,生成器的 loss 里加入了对这个 N 的正则化:
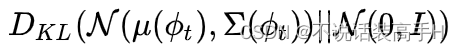
Stage-I GAN
第一阶段的 GAN 将从 N 中采样出的特征与随机噪音 z 一起输入到生成器中,判别器的输入是真实图像或者第一阶段生成的图像和输入到 N 之前的文本特征,输出判别分数。损失函数为:
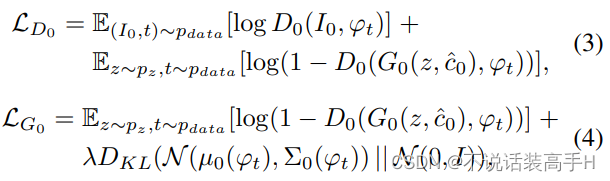
输出图像的分辨率不高,为64*64。
Stage-II GAN
第二阶段的 GAN 将第一阶段的输出图像(这时的图像内包含了随机噪音 z 内的信息,所以在这里替代了 z)和再次从 N 中采样出的特征一同输入到生成器中。判别器的输入是真实图像或生成器的输出图像和输入到 N 之前的文本特征,输出的是判别分数。其损失函数为:
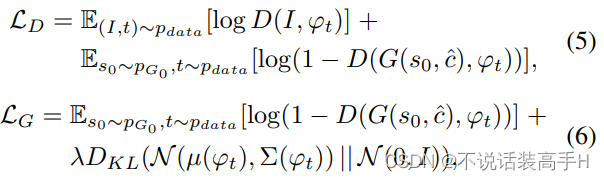
第二阶段输出的图像是高分辨率256*256的图像。
https://openaccess.thecvf.com/content_ICCV_2017/papers/Zhang_StackGAN_Text_to_ICCV_2017_paper.pdf
【论文阅读】StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN – 知乎
Image to Image(Style Transfer)
任务是根据图像生成图像,这里主要介绍论文《Image-to-Image Translation with Conditional Adversarial Networks》的方法(pix2pix)。可以归纳到风格迁移的范畴:
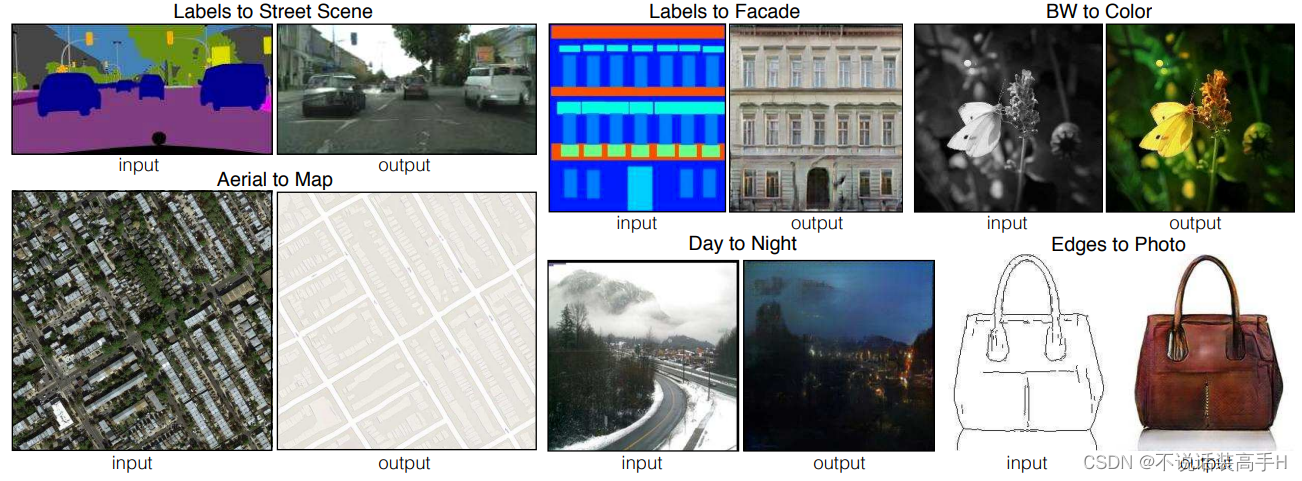
文章里包含了如下任务:

总体使用 Conditional GAN,网络的输入为成对的图像和随机噪声 z(但在代码里,网络输入只有成对的两个风格的图像),更改了目标函数:
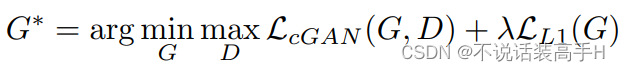
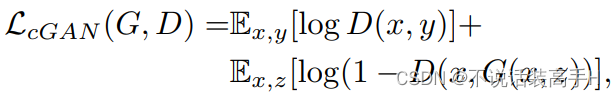
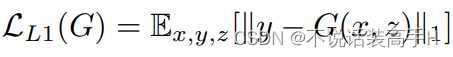
生成器的目标函数改为了 L1 损失(pixel-wise 逐像素计算),相当于生成器这时不仅仅需要骗过判别器,还需要将输出图像尽可能地规范到 gt。
Generator with skips
生成器采用 U-net 替代 encoder(MLP/卷积),文章中解释有很多低级信息(比如图像着色时输入图像的边缘信息)需要贯穿整个网络。
For many image translation problems, there is a great deal of low-level information shared between the input and output, and it would be desirable to shuttle this information directly across the net.
Markovian discriminator(PatchGAN)
文章通过实验得出,生成器使用 L1/L2 损失虽然会导致模糊的结果,但仍可以保留足够的低频信息。这样的化判别器就可以专注那些高频信息,基于此提出一个新的判别器—— PatchGAN。
For problems where this is the case, we do not need an entirely new framework to enforce correctness at the low frequencies. L1 will already do.
PatchGAN 将图像分为 N*N 的图像块,在每一块上计算出一个判别器得分,最后求平均得到最终的得分。这样做还有个好处,可以用更少的参数在分辨率大的图像上更快地运行。
GitHub – junyanz/pytorch-CycleGAN-and-pix2pix at 003efc4c8819de47ff11b5a0af7ba09aee7f5fc1
【论文笔记】Image-to-Image Translation with Conditional Adversarial Networks – 知乎
CycleGAN
和上面介绍的 pix2pix 方法一样,都属于属于风格迁移的范畴,只不过 pix2pix 训练时需要成对的两个风格的图像,比较难以获得。而 CycleGAN 生成器的输入只需要两个风格的图像而不需要严格的成对关系,有更好的实用价值。
However, obtaining paired training data can be difficult and expensive.
CycleGAN 学习到的是两个 domain(风格)之间的 mapping,而不是输入成对的数据来将一张图片的风格赋予在另一张图片的内容上,生成器的输入为两张真实图像。总的损失函数为:
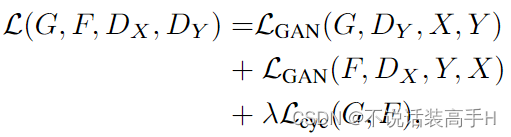
Adversarial Loss
模型包括一个生成器 G 和一个生成器 F,两个判别器 DX 和 DY:
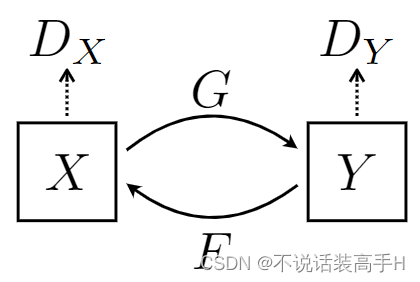
生成器 G 完成 domain X 到 domain Y 的 mapping,判别器 DY 完成对 X 和 G(X) 的判别。其损失函数为:
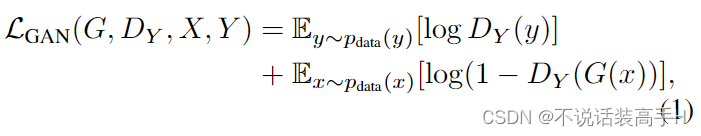
生成器 F 完成 Y 到 X 的映射,判别器 DX 完成对 Y 和 F(Y) 的判别。同样其损失函数为:
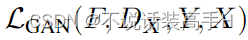
Cycle Consistency Loss
但是只用 Adversarial Loss 的话,存在如下不足:
However, with large enough capacity, a network can map the same set of input images to any random permutation of images in the target domain, where any of the learned mappings can induce an output distribution that matches the target distribution.
Thus, adversarial losses alone cannot guarantee that the learned function can map an individual input xi to a desired output yi.
如果我们希望生成器将我们的输入照片的风格转化为梵高画风,那么生成器可能从梵高的作品中随便挑一张图片来应付我们了事。
为了减少这种可能性,这里的 mapping 应该是应该可以通过 F 和 G 相互变换尽可能地变回原图,也就是如下图所示:
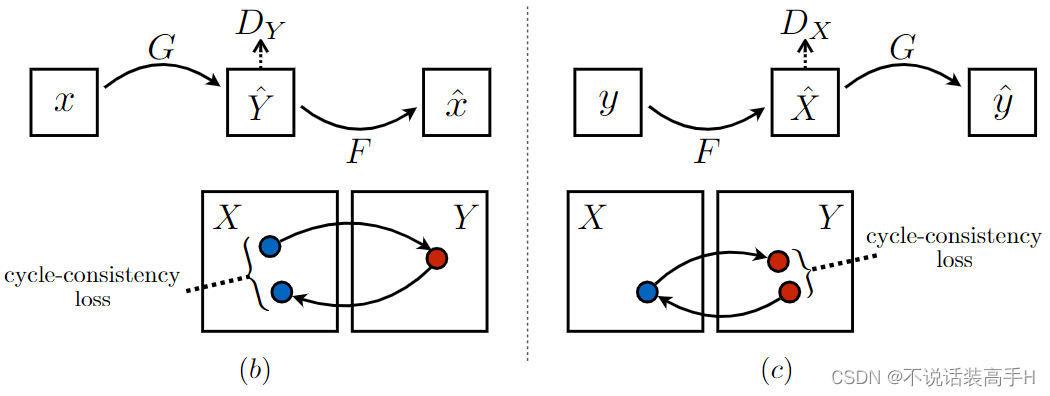
文章称这种操作为 forward cycle consistency,期望生成我们想要的 yi。损失函数为:
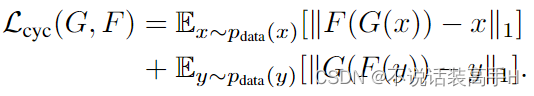
通过下图可以看出,CycleGAN 方法的效果已经逼近了 pix2pix 这种使用成对数据做监督的效果。

https://export.arxiv.org/pdf/1703.10593.pdf
https://github.com/mit-han-lab/gan-compression/blob/master/models/cycle_gan_model.py
ProGAN
如果我们希望采用 StackGAN 生成越高分辨率的图像(10241024),我们需要堆叠的 GAN 结构就会越多,这样会导致网络深度巨大。而 ProGAN 就是为了解决这个问题,核心思想就是 Pro:Progressive,从44、88到10241024逐渐地增加生成器和判别器的层数,模型的输入只有随机噪音 z 和标签。
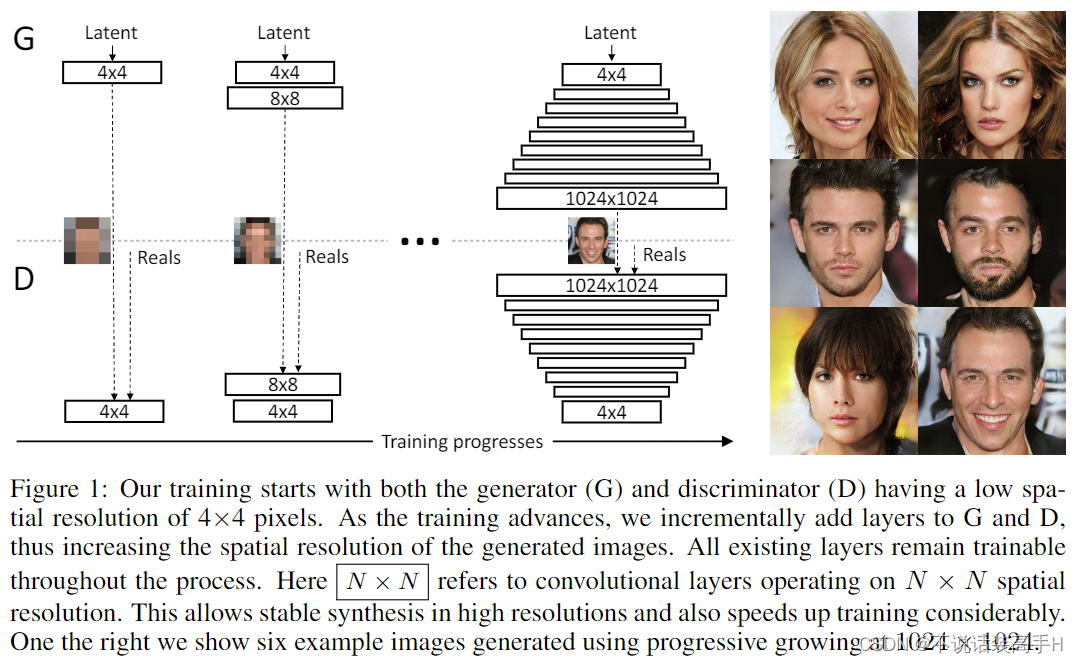
对于新加的层,我们需要让它们一点一点地加入训练,才能保证不影响已经训练好的层。文章中的做法是使用一个权重 α:
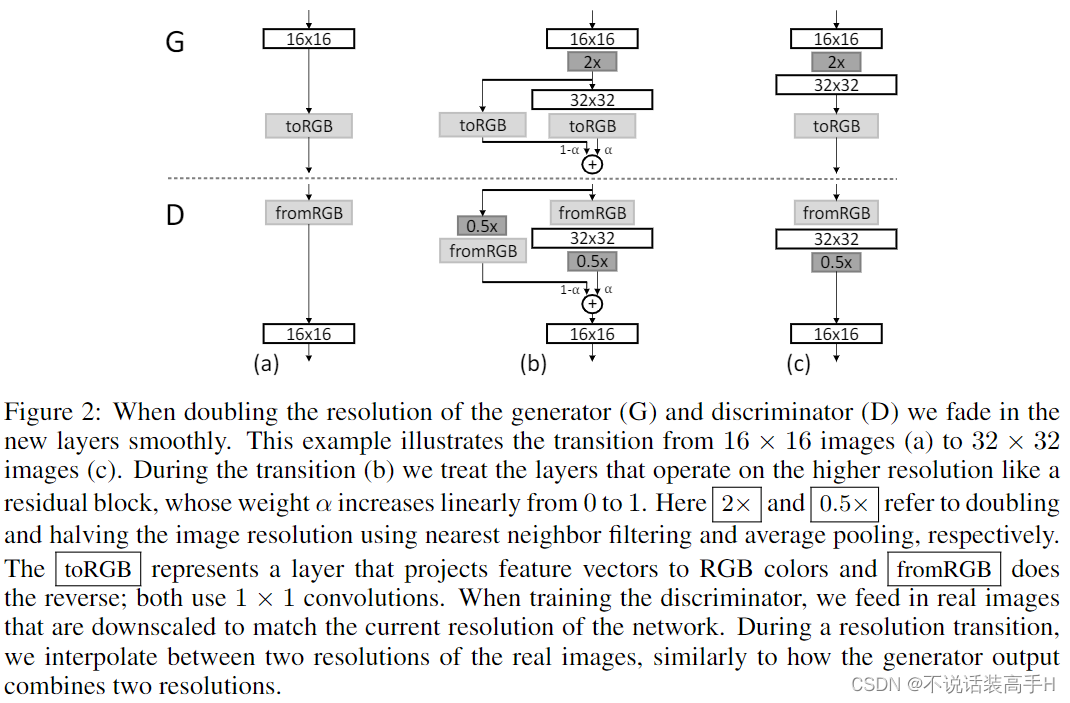
这个 α 逐渐地从0增加到1,稳定了训练。
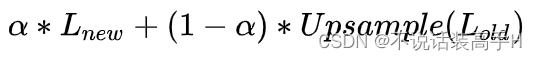
这样 Progressive 的做法使模型在早期可以先注意图像的整体结构,然后逐渐细化细节,同时加快了训练。
ProGAN:Step by step,, better than better – 知乎
https://arxiv.org/abs/1710.10196
StyleGAN
在 ProGAN 的基础上,改变了生成器,其余结构不变:
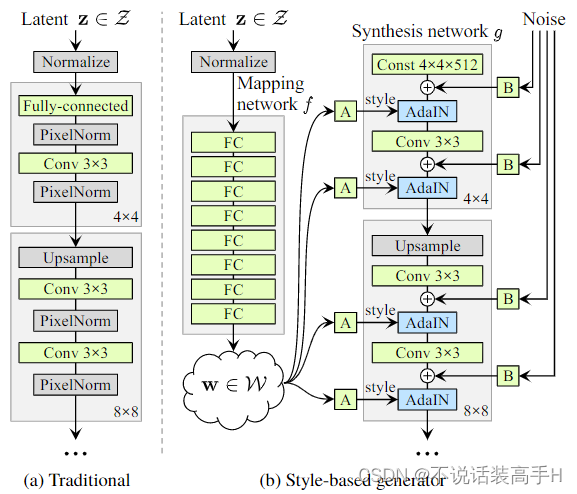
与 ProGAN 不同的是,latent code 需要经过 mapping network 来得到生成器的输入 w,每个尺度的卷积层都需要 w,最小尺度的卷积层输入是一个44512的可学习的 tensor。经过 mapping network 的目的是在特征空间内保持线性,使特征空间内的特征解耦,见后面的 Disentanglement studies。
AdaIN
IN 操作可以通过控制均值和方差来来完成特征图上风格的迁移,这样网络的其他部分就可以专注来完成内容的转变而不用考虑风格。AdaIN 没有可学习的参数,可以自适应地将输入转变成任意风格,其输入是一张图像和一个 style y:
将 IN 中可学习的参数替换成 style 的均值和标准差,来实现自适应的风格转换。
It has been known that the feature statistics in convolutional layers of a deep neural network encode the style information of an image.
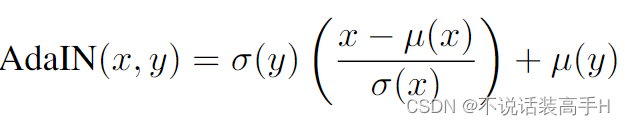
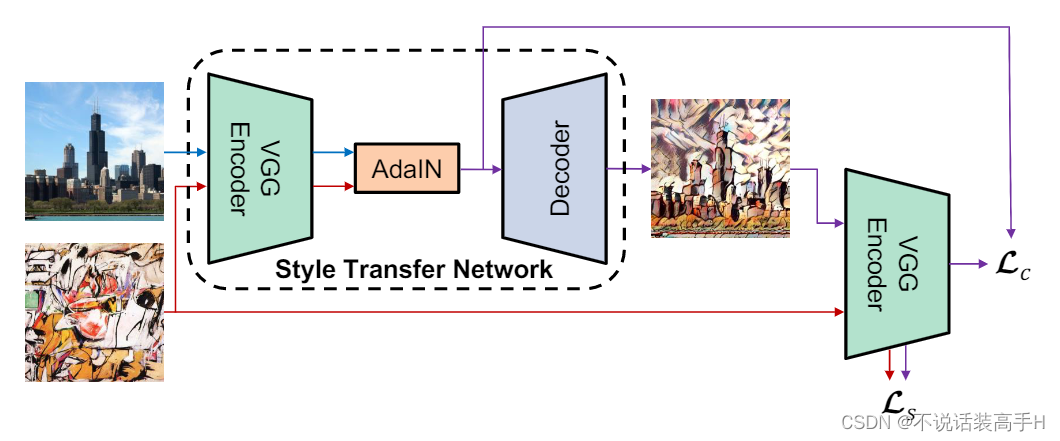
https://openreview.net/pdf?id=B1fUVMzKg
同时每个尺度还需要输入一个单通道的噪音图像(Per-Pixel),用来生成图像中的那些 stochastic detail。
Style Mixing
对于每一个卷积层,我们可以输入两个经过映射的 latent code,这种方式使得相邻尺度卷积层的 style 相关性下降,更有利于优化特征空间特征的解耦。在不同的尺度加入第二个 latent code 对最后生成的图像也有影响,越早加入越影响图像的 high-level aspects。

Stochastic variation
解释了需要输入 Per-Pixel noise 的原因,为了生成更逼真的图像,对于生成图像中的细节(比如发梢的走向)生成器往往做的不好(输出重复相似的图像)。生成器需要找到办法来合成一个伪随机的变量,用来生成这些随机的”变异”,这也增加了生成器的负担。
StyleGAN 的做法是给生成器额外输入一个 Per-Pixel noise,用来控制这些细节,同时减轻生成器的负担。文章中的实验也证明了输入的这个 Per-Pixel noise 只会影响图像的细节:

Separation of global effects from stochasticity
分析了 StyleGAN 的两个输入,经过映射后的特征 w 控制的是整体的 style 效果,Per-Pixel noise 控制的是细节的随机变异。
spatially invariant statistics (Gram matrix, channel-wise mean, variance, etc.) reliably encode the style of an image while spatially varying features encode a specific instance.
If the network tried to control, e.g., pose using the noise, that would lead to spatially inconsistent decisions that would then be penalized by the discriminator. Thus the network learns to use the global and local channels appropriately, without explicit guidance.
Disentanglement studies
此前公认对 disentanglement 的看法是 latent space 中包含很多个线性子空间,各个子空间相互独立并且单独控制各自的变异因素。但是如果数据集中某些子空间的组合缺失,而 latent space 为了尽可能覆盖更多的组合则会扭曲其自身的线性子空间来试图覆盖所有的组合,这就会使得 latent space 中的子空间变得使其变得非线性,这样的话 disentanglement 就失败了。
it should be easier to generate realistic images based on a disentangled representation than based on an entangled representation.
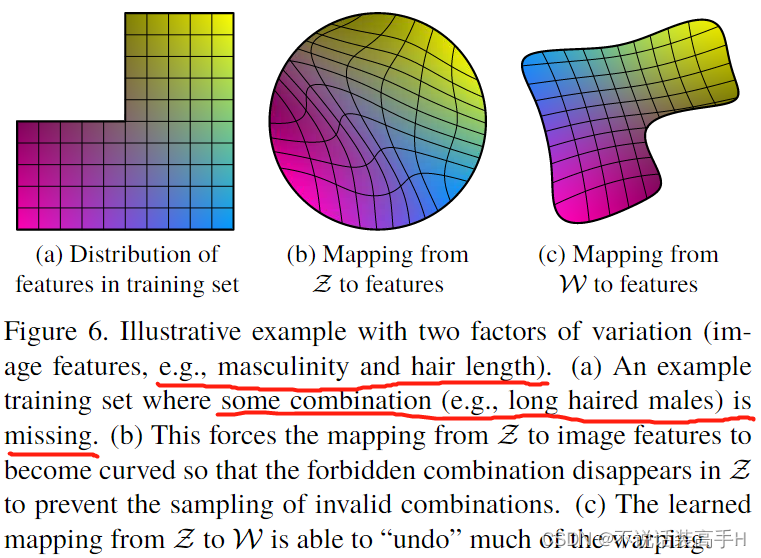
因此 mapping network 的作用就是将 latent space 内的子空间尽可能地 “undo” 回之前的样子,使其保持线性。还提出了两种度量 disentanglement 的方法:
- Perceptual path length
For example, features that are absent in either endpoint may appear in the middle of a linear interpolation path. This is a sign that the latent space is entangled and the factors of variation are not properly separated.
如果一个 latent space 解耦效果好,那么采样两个 latent code,将这两个 latent code 进行覆盖所有点的插值,这些插值生成的图片应该有很小的 Perceptual distance。
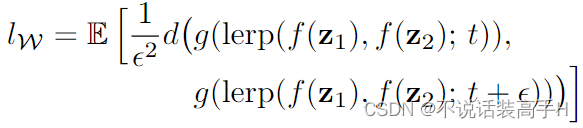
- linear separability
从零带你入门stylegan~stylegan3的技术细节_Ericam_的博客-CSDN博客_stylegan
图像生成典中典:StyleGAN & StyleGAN2 论文&代码精读 – 知乎
GitHub – tomguluson92/StyleGAN_PyTorch: The implementation of StyleGAN on PyTorch 1.0.1
GitHub – NVlabs/stylegan: StyleGAN – Official TensorFlow Implementation
A Style-Based Generator Architecture for Generative Adversarial Networks
TO BE CONTINUE
Original: https://blog.csdn.net/AmbitionalH/article/details/124456869
Author: 不说话装高手H
Title: 图像生成——总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/617571/
转载文章受原作者版权保护。转载请注明原作者出处!