

1.支持向量回归SVM
(1)基本原理
支持向量机(SVM)算法因其性能优越,在图像情感分类研究中得以广泛使用,支持向量回归(SVR)算法常用于回归预测模型的构建。SVM要求数据尽可能远离超平面,而SVR要求数据尽可能位于超平面内,使所有的数据离超平面的总偏差最小。一般的回归算法思想是当预测值完全等于实际值时才判定为预测正确,而SVR算法只要预测值与实际值偏离程度在一定范围内就可以判定为预测正确,并且不需要计算误差损失。如图1-1所示,以函数为中心,在其两侧误差范围内的数值都判定为预测正确,虚线外部的值则需要计算损失。
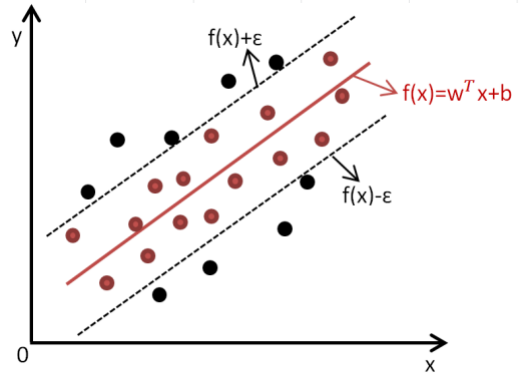

图1-1 SVR超平面数据分布示意
(2)重要参数
对于sklearn模块库中的SVR算法,kernel是算法模型中所使用的核函数类型,包括’linear’、’poly’、’rbf’、’sigmoid’和’precomputer’,SVR算法默认使用的是径向基核函数’rbf’;C是惩罚因子,表示对偏离正常值范围外数据的关注程度,C的值越大表示越不允许误差的存在,即越不想舍弃偏离点;gamma是核函数的系数,当核函数的类型为’rbf’、’poly’和’sigmoid’的时候才会被使用到。gamma的取值范围在,其值过大容易导致过拟合现象。
2.神经网络MLP
(1)基本原理
神经网络算法中的多层感知器(MLP)回归算法,可以解决单层感知器无法解决的非线性问题。最简单的MLP模型除了有输入输出层外,还需要有一层隐藏层,并且隐藏层中的每一个神经元与上一层的神经元都相连。在每个神经元的输出结果之后,需要添加一个激活函数来改变线性规则。MLP回归算法可以将特征值进行线性和非线性的连接组合,最终实现数据的预测功能。图1-2构建的MLP模型的网络结构,包含输入输出层和两层隐藏层。根据输入层特征值的维度,隐藏层的第一层为3个神经元,第二层为1个神经元。
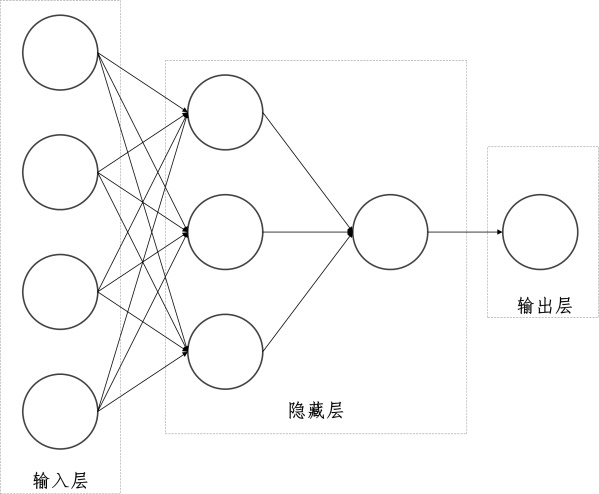
图1-2神经网络结构
(2)重要参数
对于sklearn模块库中MLPRegressor算法,hidden_layer_sizes是隐藏层中神经元的数量,其默认值为[100,],即只有一层隐藏层,且含有100个神经元;slover是权重优化的求解器,包括’lbfgs’、’sgd’和’adam’三种,其默认值为’adam’,可以根据不同规模的数据集来选择合适的优化求解器;activation是隐藏层的激活函数,包括’identity’、’logistic’、’tanh’和’relu’四种,其默认函数为’relu’; alpha是正则化项的惩罚参数,其默认值为0.0001,alpha的值越大,表示对误差的惩罚越大,即越不容忍误差的存在。
3.随机森林RF
(1)基本原理
随机森林(RF)算法是对Bagging集成算法改进后的一种优化算法,包含一系列决策树基本单元。在处理回归预测问题时,随机森林算法对多棵决策树的预测值取平均后进行集成。随机森林中每颗决策树所用到的数据和特征都是随机选取的,这就保证了每颗决策树都各不相同,提升整个随机森林的多样性。相比于决策树算法,随机森林抗干扰能力更强,模型泛化能力更强。图1-3是随机森林的具体训练过程,随机森林模型采用自助法从输入数据中重新随机采样,得到不同的训练数据后,分别训练k个不同的学习器,最终对所有的学习器的输出结果取均值得到最终预测值。

图1-3 随机森林的回归模型结构
(2)重要参数
对于sklearn模块库中的RandomForestRegressor算法,n_estimators表示随机森林中决策树的个数,即弱学习器的个数,其默认值为100,虽然决策树的数量越多,模型的预测误差越小,但与此同时过多的决策树也会增加模型运行的时间;max_depth是决策树的最大深度,即树根节点与树叶节点之间的距离,其值越大表示预测误差越小,但是决策树过深会导致过拟合现象的出现;max_features表示最大特征数,其限制了决策树开始分割的条件;min_samples_leaf是叶子节点含有的最少样本,其默认值为1,如果叶子节点的数目比样本数少,则会和同根节点一起被剪枝;min_samples_split是叶子节点可分的最小样本数,其默认为2,决定了决策树向下分枝的条件。
4.Stacking集成学习
(1)基本原理
Stacking算法是一种融合模型训练方法,它可以使用多个不同的算法模型解决同一个问题。其先将输入数据中的训练集作为第一层弱学习器的输入,分别训练多个不同的机器学习模型,分别得到它们的预测结果后,作为下一层元学习器的输入,对融合学习器进行训练,最终得到更准确的预测结果。通过多种算法模型的有效融合,Stacking集成学习模型能够克服单个模型的缺陷,优化元学习器的输入,提升预测效果,具体的集成技术如图2-4所示:
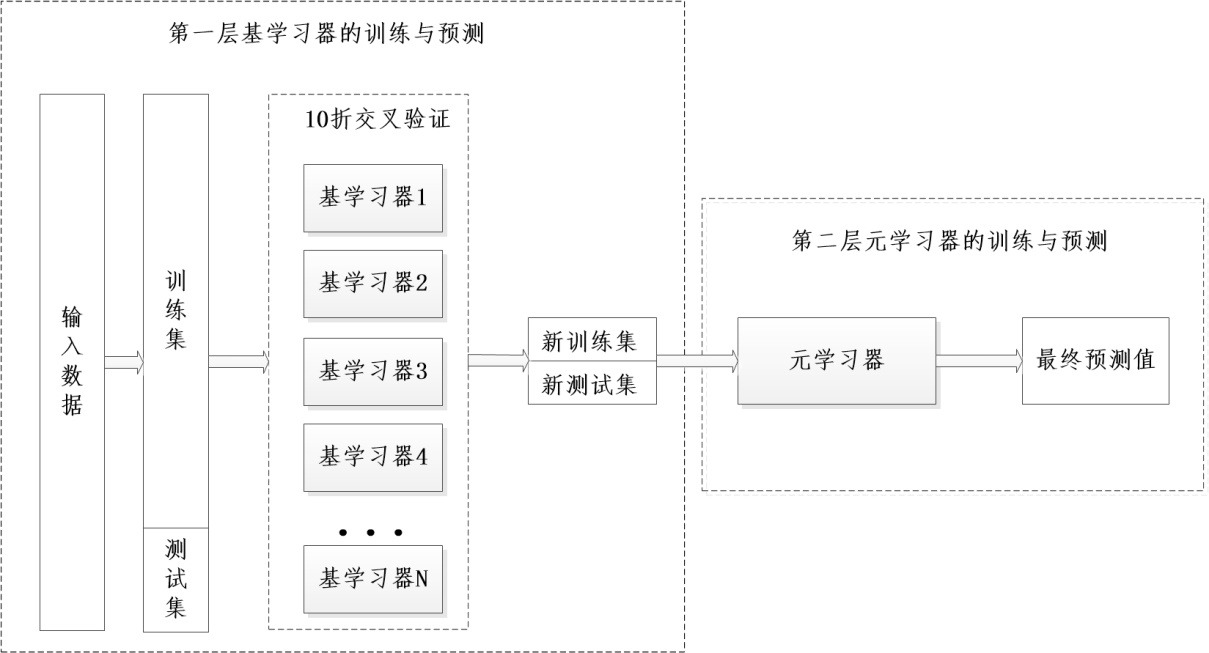
图2-4 Stacking集成模型框架
(2)重要参数
对于sklearn模块库中的StackingRegressor算法,regressors表示第一层学习器的算法模型集合,基模型的数量直接影响着模型的预测精度。
Original: https://blog.csdn.net/weixin_46837260/article/details/124011591
Author: weixin_46837260
Title: 机器学习回归算法(SVM、MLP、RF、Stacking集成学习)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/617505/
转载文章受原作者版权保护。转载请注明原作者出处!