

1 sklearn中的线性回归
sklearn中的线性模型模块是linear_model,我们曾经在学习逻辑回归的时候提到过这个模块。linear_model包含了 多种多样的类和函数:普通线性回归,多项式回归,岭回归,LASSO,以及弹性网。



2 多元线性回归LinearRegression

其中右下角的2表示向量 的L2范式,也就是我们的损失函数所代表的含义。在L2范式上开平方,就是我们的 损失函数。这个式子,也正是sklearn当中,用在类Linear_model.LinerRegression背后使用的损失函数。我们往往称 呼这个式子为SSE(Sum of Sqaured Error,误差平方和)或者RSS(Residual Sum of Squares 残差平方和)。在 sklearn所有官方文档和网页上,我们都称之为RSS残差平方和,因此在我们的课件中我们也这样称呼。
最小二乘法求解多元线性回归的参数
现在问题转换成了求解让RSS最小化的参数向量 ,这种通过最小化真实值和预测值之间的RSS来求解参数的方法叫做最小二乘法。
linear_model.LinearRegression
class sklearn.linear_model.LinearRegression (fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)




回归类的模型评估指标
回归类算法的模型评估一直都是回归算法中的一个难点,但不像我们曾经讲过的无监督学习算法中的轮廓系数等等评 估指标,回归类与分类型算法的模型评估其实是相似的法则——找真实标签和预测值的差异。只不过在分类型算法 中,这个差异只有一种角度来评判,那就是是否预测到了正确的分类,而在我们的回归类算法中,我们有两种不同的 角度来看待回归的效果:
第一,我们是否预测到了正确的数值。
第二,我们是否拟合到了足够的信息。
这两种角度,分别对应着不同的模型评估指标。
是否预测了正确的数值
RSS残差平方和,它的本质是我们的预测值与真实值之间的差异,也就是从第一种角度来评估我们回 归的效力,所以RSS既是我们的损失函数,也是我们回归类模型的模型评估指标之一。但是,RSS有着致命的缺点: 它是一个无界的和,可以无限地大。我们只知道,我们想要求解最小的RSS,从RSS的公式来看,它不能为负,所以 RSS越接近0越好,但我们没有一个概念,究竟多小才算好,多接近0才算好?为了应对这种状况,sklearn中使用RSS 的变体,均方误差MSE(mean squared error)来衡量我们的预测值和真实值的差异:

均方误差,本质是在RSS的基础上除以了样本总量,得到了每个样本量上的平均误差。有了平均误差,我们就可以将 平均误差和我们的标签的取值范围在一起比较,以此获得一个较为可靠的评估依据。在sklearn当中,我们有两种方 式调用这个评估指标
一种是使用sklearn专用的模型评估模块metrics里的类mean_squared_error,
另一种是调用 交叉验证的类cross_val_score并使用里面的scoring参数来设置使用均方误差。


是否拟合了足够的信息
对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型 能够捕捉到数据的”规律”,比如数据的分布规律,单调性等等,而是否捕获了这些信息并无法使用MSE来衡量。
我们希望找到新的指标,除了判断预测的 数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。 在我们学习降维算法PCA的时候,我们提到我们使用方差来衡量数据上的信息量。如果方差越大,代表数据上的信息 量越多,而这个信息量不仅包括了数值的大小,还包括了我们希望模型捕捉的那些规律。为了衡量模型对数据上的信 息量的捕捉,我们定义了
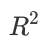 来帮助我们:
来帮助我们:

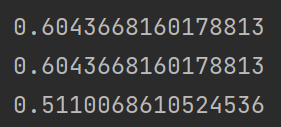
 可以使用三种方式来调用,一种是直接从metrics中导入r2_score,输入预测值和真实值后打分。第二种是直接从 线性回归LinearRegression的接口score来进行调用。第三种是在交叉验证中,输入”r2″来调用。
可以使用三种方式来调用,一种是直接从metrics中导入r2_score,输入预测值和真实值后打分。第二种是直接从 线性回归LinearRegression的接口score来进行调用。第三种是在交叉验证中,输入”r2″来调用。

多重共线性:岭回归与Lasso
多重共线性与相关性
多重共线性如果存在,则线性回归就无法使用最小二乘法来进行求解,或者求解就会出现偏差。幸运的是,不能存在多重共线性,不代表不能存在相关性——机器学习不要求特征之间必须独立,必须不相关,只要不是高度相关或者精确相关就好。
多重共线性是一种统计现象,是指线性模型中的特征(解释变量)之间由于存在精确相关关系或高度相关关系, 多重共线性的存在会使模型无法建立,或者估计失真。多重共线性使用指标方差膨胀因子(variance inflation factor,VIF)来进行衡量(from statsmodels.stats.outliers_influence import variance_inflation_factor), 通常当我们提到”共线性”,都特指多重共线性。 相关性是衡量两个或多个变量一起波动的程度的指标,它可以是正的,负的或者0。当我们说变量之间具有相关 性,通常是指线性相关性,线性相关一般由皮尔逊相关系数进行衡量,非线性相关可以使用斯皮尔曼相关系数或 者互信息法进行衡量。
多重共线性的存在会造成模型极大地偏移,无法模拟数据的全貌,因此这是必须解决的 问题。为了保留线性模型计算快速,理解容易的优点,我们并不希望更换成非线性模型,这促使统计学家和机器学习 研究者们钻研出了多种能够处理多重共线性的方法,其中有三种比较常见的:

我们的核心会是使用第三种方法:改进线性回归来处理多重共线性。为此,一系列算法,岭回归, Lasso,弹性网就被研究出来了。接下来,我们就来看看这些改善多重共线性问题的算法。
岭回归,又称为吉洪诺夫正则化(Tikhonov regularization)。通常来说,大部分的机器学习教材会使用代数的形式 来展现岭回归的原理,这个原理和逻辑回归及支持向量机非常相似,都是将求解 的过程转化为一个带条件的最优化 问题,然后用最小二乘法求解。然而,岭回归可以做到的事其实可以用矩阵非常简单地表达出来。
岭回归在多元线性回归的损失函数上加上了正则项,表达为系数ω 的L2范式(即系数ω 的平方项)乘以正则化系数α 。如果你们看其他教材中的代数推导,正则化系数会写作λ ,用以和Lasso区别,不过在sklearn中由于是两个不同的 算法,因此正则项系数都使用α来代表。岭回归的损失函数的完整表达式写作:

linear_model.Ridge
class sklearn.linear_model.Ridge (alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver=’auto’, random_state=None)



虽然岭回归和Lasso不是设计来提升模型表现,而是专注于 解决多重共线性问题的,但当 在一定范围内变动的时候,消除多重共线性也许能够一定程度上提高模型的泛化能 力。 但是泛化能力毕竟没有直接衡量的指标,因此我们往往只能够通过观察模型的准确性指标和方差来大致评判模型的泛 化能力是否提高。
选取最佳的正则化参数取值
我们使用交叉验证来选择最佳的正则化系数。在sklearn中,我们有带交叉验证的岭回归可以使用,我们来 看一看:
class sklearn.linear_model.RidgeCV (alphas=(0.1, 1.0, 10.0),fit_intercept=True, normalize=False, scoring=None, cv=None, gcv_mode=None, store_cv_values=False)
可以看到,这个类与普通的岭回归类Ridge非常相似,不过在输入正则化系数的时候我们可以传入元祖作为正则化 系数的备选,非常类似于我们在画学习曲线前设定的for i in 的列表对象。来看RidgeCV的重要参数,属性和接口:



非线性问题:多项式回归

使用分箱处理非线性问题
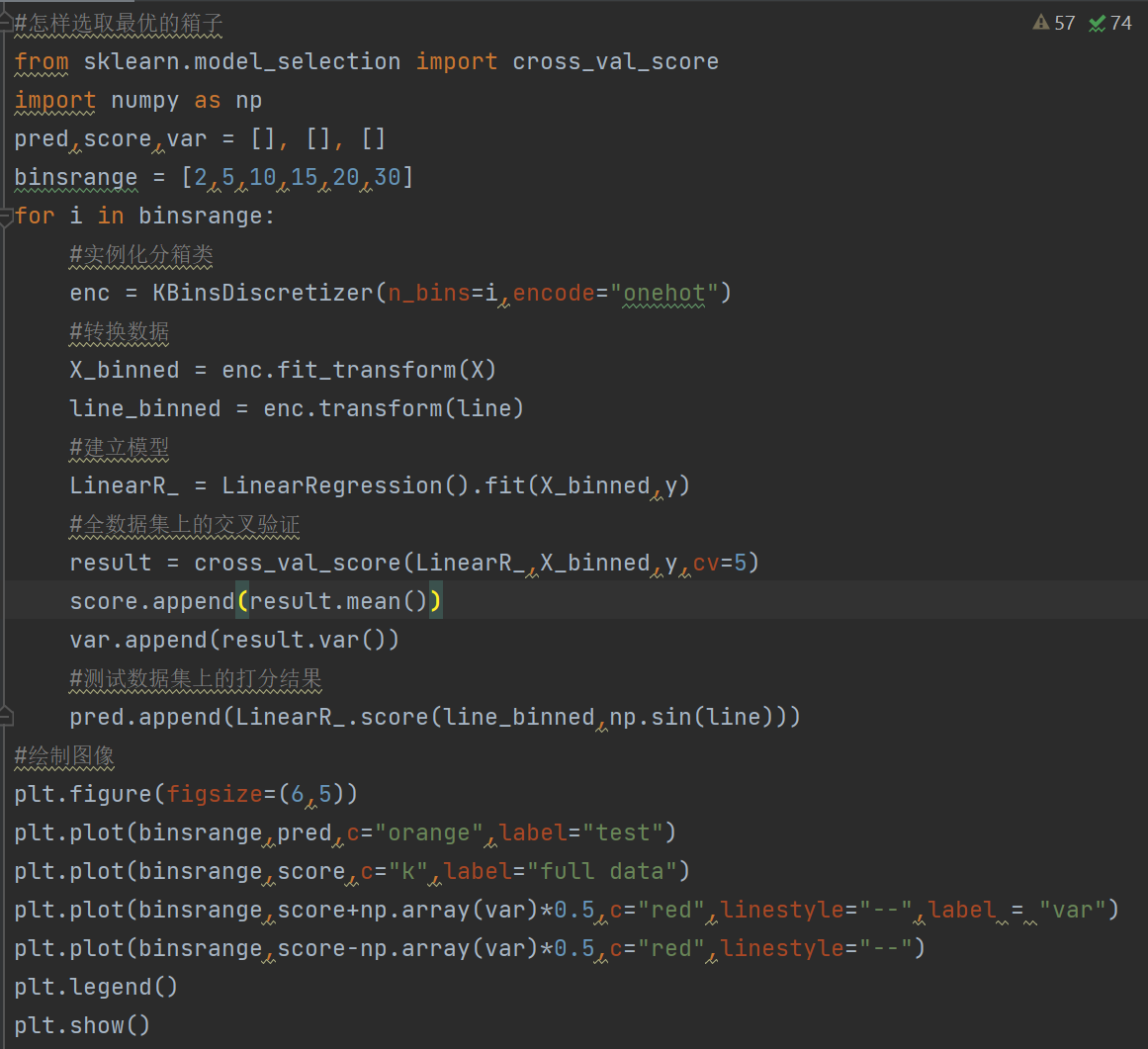
让线性回归在非线性数据上表现提升的核心方法之一是对数据进行分箱,也就是离散化。与线性回归相比,我们常用 的一种回归是决策树的回归。




在这个例子中,我们设置的分箱箱数为10,不难想到这个箱数的设定肯定会影响模型最后的预测结果,我们来看看不 同的箱数会如何影响回归的结果:

多项式回归PolynomialFeatures
除了分箱之外,另一种更普遍的用于解决”线性回归只能处理线性数据”问题的手段,就是使用多项式回归对线性回归 进行改进。这样的手法是机器学习研究者们从支持向量机中获得的:支持向量机通过升维可以将非线性可分数据转化 为线性可分,然后使用核函数在低维空间中进行计算,这是一种”高维呈现,低维解释”的思维。那我们为什么不能让 线性回归使用类似于升维的转换,将数据由非线性转换为线性,从而为线性回归赋予处理非线性数据的能力呢?当然 可以。

接下来,我们就来看看线性模型中的升维工具:多项式变化。这是一种通过增加自变量上的次数,而将数据映射到高 维空间的方法,只要我们设定一个自变量上的次数(大于1),就可以相应地获得数据投影在高次方的空间中的结 果。这种方法可以非常容易地通过sklearn中的类PolynomialFeatures来实现。我们先来简单看看这个类是如何使用 的。
class sklearn.preprocessing.PolynomialFeatures (degree=2, interaction_only=False, include_bias=True)

多项式回归处理非线性问题


Original: https://blog.csdn.net/weixin_58975360/article/details/124284392
Author: CHEN的小喵
Title: sklearn-线性回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/614485/
转载文章受原作者版权保护。转载请注明原作者出处!