

一、《基于文献的药物表型实体识别及关系抽取方法研究》北京交通大学-张琛
表型实体:疾病、体症、基因、化学物质和药物名称。
信息提取的传统方法分为三步:命名实体识别、关系抽取、事件抽取。
———————————————————————————————
文章目录
*
–
+
* 一、《基于文献的药物表型实体识别及关系抽取方法研究》北京交通大学-张琛
*
– 方法一
– 方法二(备选)
– 相关工作中提到的方法(按时间顺序)
– 方法一使用的实体任务数据集信息
方法一
将关系抽取视为独立任务。关系抽取与实体识别任务分开。使用神经网络方法,采用 BiLSTM 结合 CRF,分别对中文电子病历数据集和英文医学文献摘要数据集进行训练。
之后的关系抽取任务,采用的是基于 Attetntion 机制的双向 LSTM 模型。
(0)数据预处理:采用两套标签对文本进行标注。BIO 标签和词性标签。这两个是中英文数据的共同特征。


(1)预训练词向量生成:对中文和英文分别构建词向量。
使用两种方法获得词向量。计算方法:采用 negative sample 优化的 skip-gram 模型和GloVe 模型,进行词向量的构建。
小样本时基线方法 skip-gram 效果更好一些,大样本时 GloVe更好一些。
预训练模型 Bert 和 XLnet 性能更优越。
中文而言,字向量比词向量的效果更好。
(2)组织模型输入数据:中文在字向量的基础上,加入分词特征和笔划数特征,英文采用了单词的字母组成特征。
【分词】:三种常用的 Python 中文分词工具,分别是张华平老师的 NLPIR、jieba、哈工大的 LTP。根据分词结果,仿照 BIO 标注策略为分词后的文本将结果添加标签,转化为可计算的文本特征。
【笔划数】:建立汉字笔划数字典。接着,根据字典,获取数据集中每一个字的笔划数,保存在列表中。另外,将所有的标点符号和数字的笔划数均设为 0。
【字母特征】:将 26 个英文字母进行顺序编码,获取字母与 id 的映射。然后根据英文单词中字母组成,将单词映射为一组字母 id 值的向量。例如,”word”,对应的字母 id 向量为”22,14,17,3″ 。
【中英文数据集的共同的特征】(BIO 标签和词性标签):为BIO标签建立一个字典,字典序就代表了标签顺序,按此顺序可以将标签和数字相互转换。例如,B-DRUG,I-DRUG,B-DISEASE,I-DISEASE,按序编码为 0,1,2,3。
词性标签,例如名词标签”n”,形容词标签”adj”,动词标签”v”,也作此处理,建立标签和 id 值的映射基于字识别,使用BIO标签策略。将实体名词特征和分词特征结合,共同训练。
由于句子各有长短,在维度不同的情况下无法进行计算,因此需要对齐。按照最长句子的长度进行填补,空缺部分一律补零。
(3)送入神经网络训练:BiLSTM 过程为编码的过程,CRF 过程为
解码过程。
实验部分,对不同的数据集,使用不同的输入特征。
; 方法二(备选)
应用实体识别和关系抽取任务的联合神经网络模型。该模型采用了两种方法,一是多头选择,二是对抗训练。这两种方法是针对关系抽取任务的,实体识别的方法仍然是主流的双向 LSTM 网络层结合 CRF 方法的模型。
不需额外的 POS 标记器(NLP 工具)或是其他人工提取特征,模型自动执行端到端关系提取。同时对医学文本中的关系和实体进行识别。并添加了 head 信息。
联合抽取模型是基于手动提取的功能,建议用于执行一次命名实体识别(NER)和关系抽取(RE)任务(备选)
相关工作中提到的方法(按时间顺序)
一、如果将实体提取视为独立任务,有下述方法。
1.依赖于基于词典或规则的方法:基于字典的方法,在包含每个实体类型的大量名称集合的预定义字典中提取命名实体。基于规则的方法,通过几个基于文本模式手动定义的规则来识别命名实体。
优势:常见的生物实体(如疾病和基因名称)有相对完善的词典。
缺点:基于规则的方法,预定义模式依赖于实体类的特定文本属性。实体特定的字典和模式需要耗时的过程和专家知识。
2.非结构化数据项的深度学习方法:一种基于深度学习和统计单词嵌入的领域无关方法。带有条件随机场CRF和GRAM-CNN的双向长短期记忆网络(BiLSTM)
3.基于CNN-BILSTM-CRF中性网络模型的标记语料库:以充分利用 CNN 来获取单词的呈现特征并使用 BILSTM 和 CRF 标记单词。
优点:在中文医学文本命名实体识别上实践成功。
二、如果将实体提取和关系提取视为一个任务,使用联合模型来检测实体及其关系。有下述方法。(备选)
1.基于递归神经网络(RNN)的联合模型,该模型使用双向顺序 LSTM(长-短期记忆神经网络)来建模实体和一个考虑依赖树信息的实体 LSTM 来建模实体之间的关系。
2.人工提取特征或使用NLP工具,后使用基于特征的网络模型,提取实体和实体间关系。
方法一使用的实体任务数据集信息
CCKS2017 实体任务数据集,是电子病历的部分内容。包括了病人的诊疗经过、病史特点、一般项目和出院情况四部分,每部分均有 300条记录,长度由 30 到 100 不等。
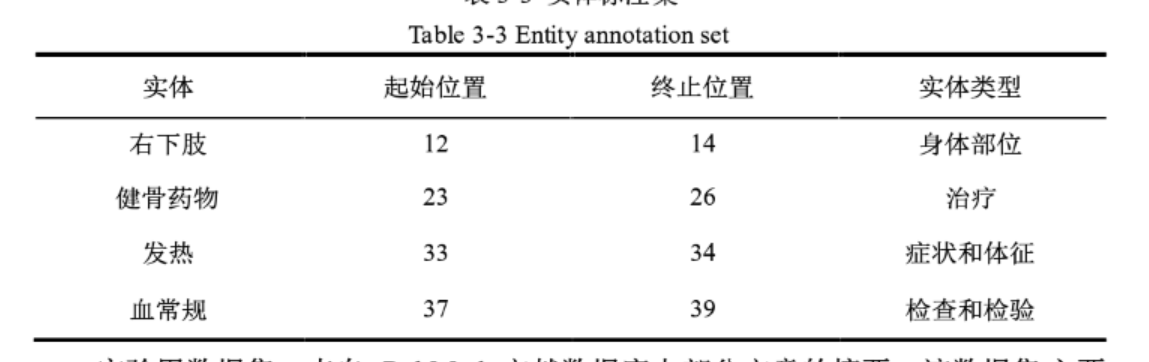
其中,诊疗经过的一条记录如下:
“入院后完善各项检查,给予右下肢持续皮牵引,应用健骨药物治疗,患者略发
热,查血常规:白细胞数 12.18*109/L,中性粒细胞百分比 92.00%。给予应用抗生素预防感染。”
其中,中文电子病历数据集分为原始记录数据集和标注数据集,原始记录分为
“一般项目”、”出院情况”、”病史特征”、”诊疗经过”四个类别,每一个类别包含
300 条原始记录和 300 条对应的标注结果。其中,标注结果文件的内容形式如表所示:
Original: https://blog.csdn.net/qq_41821608/article/details/122599085
Author: 潮一
Title: 【项目调研+论文阅读】基于医学文献的实体抽取(NER)方法研究 day5
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548487/
转载文章受原作者版权保护。转载请注明原作者出处!