

17 | 如何正确地显示随机消息?
场景:从一个单词表中随机选出三个单词。
表的建表语句和初始数据的命令如下,在这个表里面插入了 10000 行记录:
CREATE TABLE words (
id int(11) NOT NULL AUTO_INCREMENT,
word varchar(64) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=0;
while i
内存临时表
用 order by rand() 来实现这个逻辑,随机排序取前 3 个。
select word from words order by rand() limit 3;
虽然这个 SQL 语句写法很简单,但执行流程却有点复杂的。
使用 explain 命令查看语句的执行情况


Extra 字段显示 Using temporary,表示的是需要 使用临时表;Using filesort,表示的是需要 执行排序操作。因此这个 Extra 的意思就是, 需要临时表,并且需要在临时表上排序。
Q:对于临时 内存表的排序来说,它会选择全字段排序算法还是rowid算法?
A:回顾一下上一篇文章的一个结论: 对于 InnoDB 表来说,执行全字段排序会减少磁盘访问,因此会被优先选择。
对于内存表,回表过程只是简单地根据数据行的位置,直接访问内存得到数据,根本不会导致多访问磁盘。优化器没有了这一层顾虑,那么它会优先考虑的,就是 用于排序的行越小越好了,所以,MySQL 这时就会选择 rowid 排序。
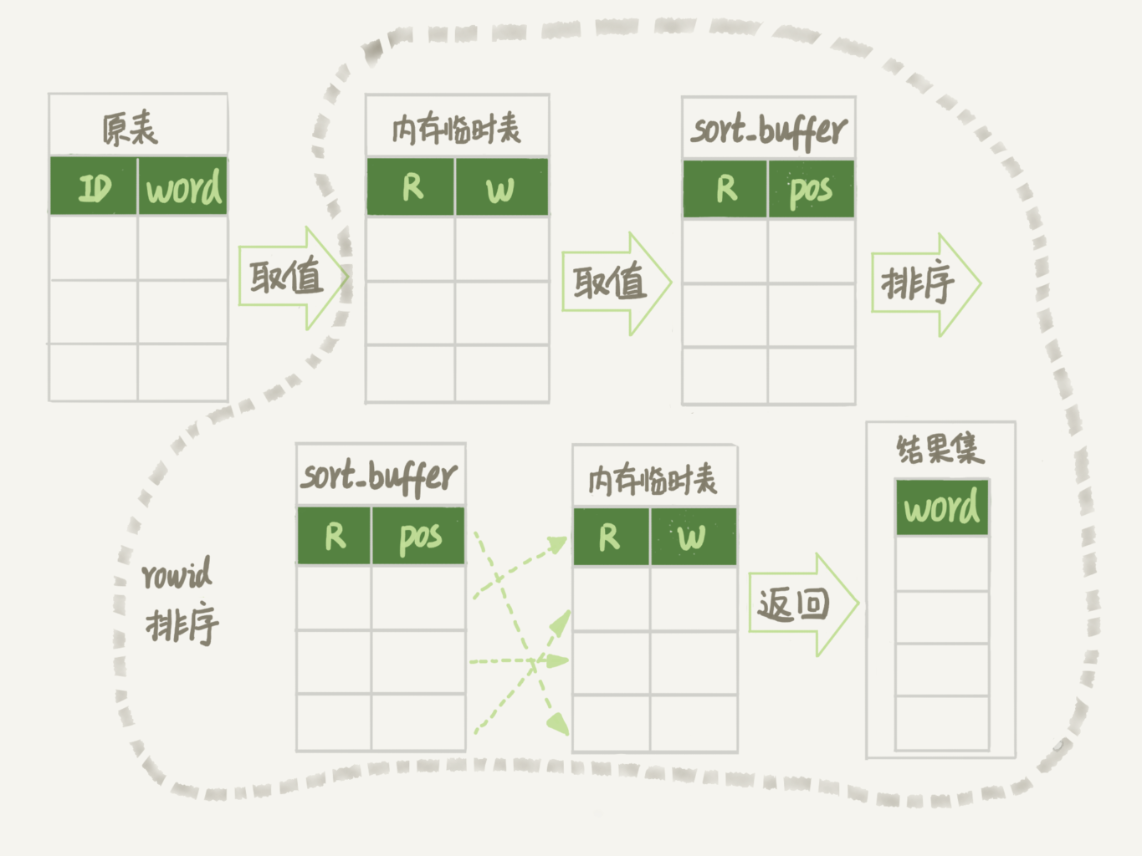
这条语句的执行流程是这样的:
- 创建一个临时表。 这个临时表使用的是 memory 引擎,表里有两个字段,第一个字段是 double 类型,为了后面描述方便,记为字段 R,第二个字段是 varchar(64) 类型,记为字段 W。 并且,这个表没有建索引。
- 从 words 表中,按主键顺序取出所有的 word 值。对于每一个 word 值, 调用 rand() 函数生成一个大于 0 小于 1 的随机小数,并把这个随机小数和 word 分别存入临时表的 R 和 W 字段中,到此,扫描行数是 10000。
- 现在临时表有 10000 行数据了, 接下来要在这个没有索引的内存临时表上,按照字段 R 排序。
- 初始化 sort_buffer。sort_buffer 中有两个字段,一个是 double 类型,另一个是整型。
- 从内存临时表中一行一行地取出 R 值和 位置信息,分别存入 sort_buffer 中的两个字段里。这个过程要对内存临时表做全表扫描,此时扫描行数增加 10000,变成了 20000。
- 在 sort_buffer 中根据 R 的值进行排序。注意,这个过程没有涉及到表操作,所以不会增加扫描行数。
- 排序完成后,取出前三个结果的位置信息,依次到内存临时表中取出 word 值,返回给客户端。这个过程中,访问了表的三行数据,总扫描行数变成了 20003。
通过慢查询日志(slow log)来验证分析得到的扫描行数是否正确。
Query_time: 0.900376 Lock_time: 0.000347 Rows_sent: 3 Rows_examined: 20003
SET timestamp=1541402277;
select word from words order by rand() limit 3;
完整的排序执行流程图
MySQL 的表是用什么方法来定位”一行数据”
如果把一个 InnoDB 表的主键删掉,是不是就没有主键,就没办法回表了?
其实不是的。如果你创建的表没有主键,或者把一个表的主键删掉了,那么 InnoDB 会自己生成一个 长度为 6 字节的 rowid 来作为主键
如果你创建的表没有主键,或者把一个表的主键删掉了,那么 InnoDB 会自己生成一个长度为 6 字节的 rowid 来作为主键。
这也就是排序模式里面,rowid 名字的来历。实际上它表示的是: 每个引擎用来唯一标识数据行的信息。
- 对于有主键的 InnoDB 表来说,这个 rowid 就是 主键 ID(上一节的ID);
- 对于没有主键的 InnoDB 表来说,这个 rowid 就是由系 统生成的;
- MEMORY 引擎不是索引组织表。在这个例子里面,你可以认为 它就是一个数组。因此, 这个 rowid 其实就是数组的下标。
小结
order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。
磁盘临时表
tmp_table_size 这个配置限制了内存临时表的大小,默认值是 16M。 如果临时表大小超过了 tmp_table_size,那么内存临时表就会转成磁盘临时表。
磁盘临时表使用的引擎默认是 InnoDB,是由参数 internal_tmp_disk_storage_engine 控制的。
当使用磁盘临时表的时候,对应的就是 一个没有显式索引的 InnoDB 表的排序过程。
为了复现这个过程,把 tmp_table_size 设置成 1024,把 sort_buffer_size 设置成 32768, 把 max_length_for_sort_data 设置成 16。
set tmp_table_size=1024;
set sort_buffer_size=32768;
set max_length_for_sort_data=16;
/* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* 执行语句 */
select word from words order by rand() limit 3;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
OPTIMIZER_TRACE 的结果如下:
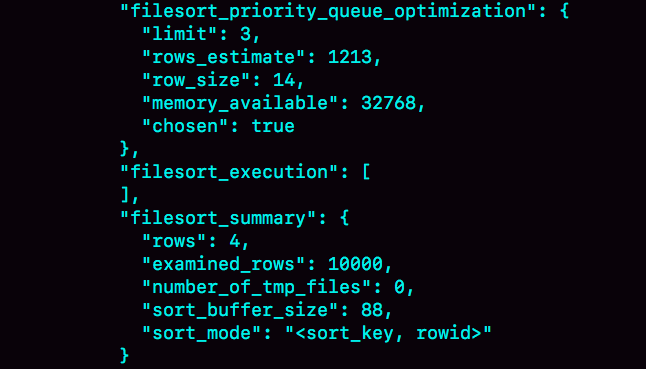
因为将 max_length_for_sort_data 设置成 16, 小于 word 字段的长度定义,所以我们看到 sort_mode 里面显示的是 rowid 排序,这个是符合预期的,参与排序的是 随机值 R 字段和 rowid 字段组成的行。
Q:R 字段存放的随机值就 8 个字节,rowid 是 6 个字节,数据总行数是 10000,这样算出来就有 140000 字节,超过了 sort_buffer_size 定义的 32768 字节了。但是,number_of_tmp_files 的值居然是 0,难道不需要用临时文件吗?
A:这个 SQL 语句的排序确实没有用到临时文件,采用是 MySQL 5.6 版本引入的一个新的排序算法,即: 优先队列排序算法
优先队列排序算法
现在的 SQL 语句,只需要取 R 值最小的 3 个 rowid。但是,如果使用归并排序算法的话,虽然最终也能得到前 3 个值,但是这个算法结束后,已经将 10000 行数据都排好序了。也就是说,后面的 9997 行也是有序的了。但查询并不需要这些数据是有序的,这 浪费了非常多的计算量。
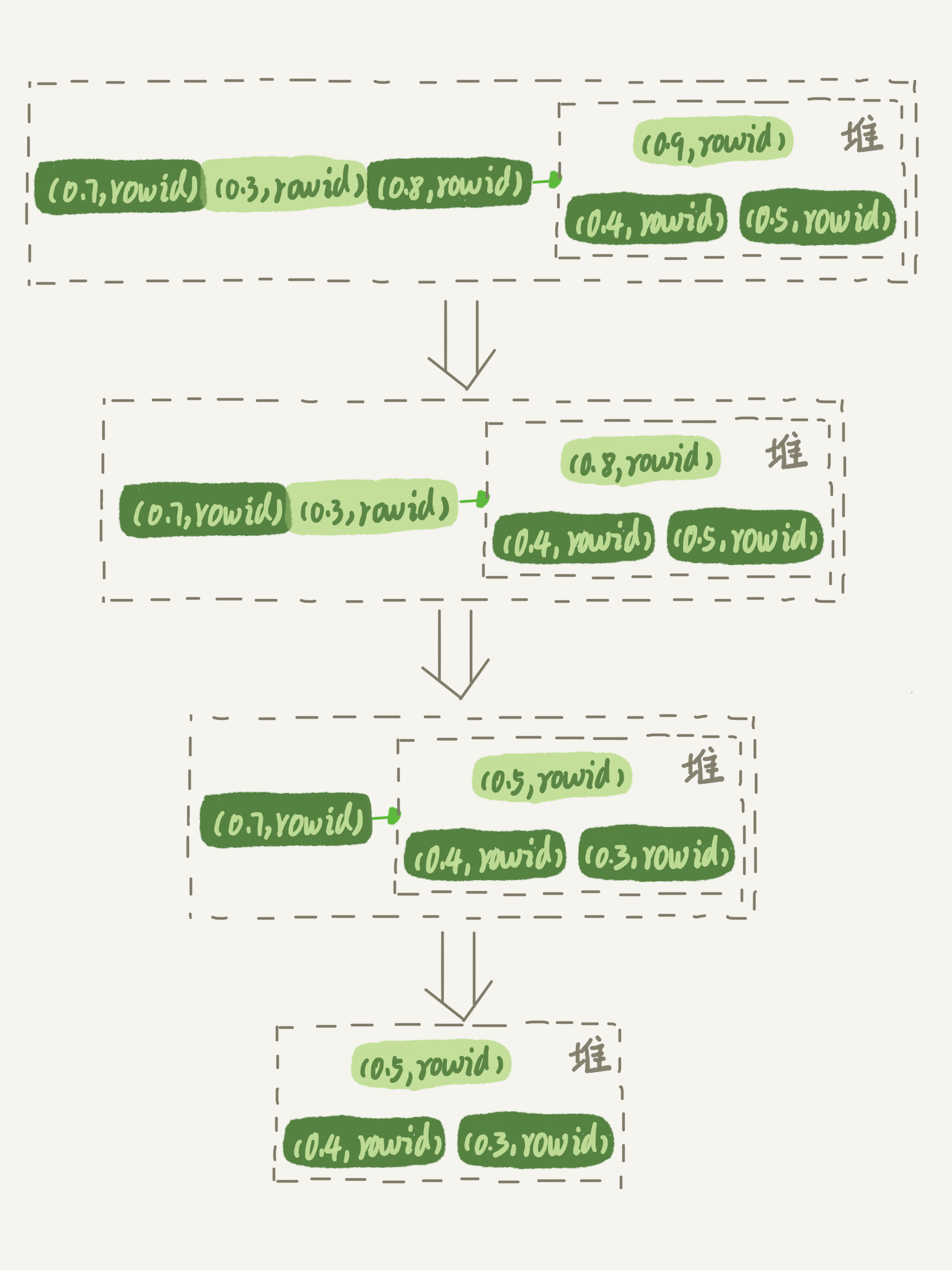
优先队列算法,就可以精确地只得到三个最小值,执行流程如下:
- 对于这 10000 个准备排序的 (R,rowid),先取前三行,构造成一个堆;(可以设想成这是一个由三个元素组成的数组)
- 取下一个行 (R’,rowid’),跟当前堆里面最大的 R 比较,如果 R’小于 R,把这个 (R,rowid) 从堆中去掉,换成 (R’,rowid’);
- 重复第 2 步,直到第 10000 个 (R’,rowid’) 完成比较。
优先队列排序过程的示意图如下,模拟 6 个 (R,rowid) 行,通过优先队列排序找到最小的三个 R 值的行的过程。整个排序过程中,为了最快地拿到当前堆的最大值, 总是保持最大值在堆顶,因此这是一个最大堆。
上面的OPTIMIZER_TRACE 结果中,filesort_priority_queue_optimization 这个部分的 chosen=true,就表示使用了优先队列排序算法,这个过程不需要临时文件,因此对应的 number_of_tmp_files 是 0。
这个流程结束后,我们构造的堆里面,就是这个 10000 行里面 R 值最小的三行。然后,依次把它们的 rowid 取出来,去临时表里面拿到 word 字段,这个过程就跟上一篇文章的 rowid 排序的过程一样了。
Q:上一篇也用了limit,为什么没有用优先队列排序算法?
select city,name,age from t where city='杭州' order by name limit 1000 ;
A:
这条 SQL 语句是 limit 1000,如果使用优先队列算法的话,需要维护的堆的大小就是 1000 行的 (name,rowid),超过了设置的 sort_buffer_size 大小,所以只能使用归并排序算法。
tmp_table_size 管是内存临时表还是磁盘临时表
sort_buffer_size 管归并还是其他
max_length_for_sort_data 控制是否是全字段
小结:
不论是使用哪种类型的临时表, order by rand() 这种写法都会让计算过程非常复杂,需要大量的扫描行数,因此排序过程的资源消耗也会很大。
随机排序方法
尽量将业务逻辑写在业务代码中,让数据库只做”读写数据”的事情
简化问题,如果只随机选择 1 个 word 值,可以怎么做:
方法一:
- 取得这个表的主键 id 的最大值 M 和最小值 N;
- 用随机函数生成一个最大值到最小值之间的数 X = (M-N)*rand() + N;
- 取不小于 X 的第一个 ID 的行。
select max(id),min(id) into @M,@N from t ;
set @X= floor((@M-@N+1)*rand() + @N);
select * from t where id >= @X limit 1;
这个方法效率很高,因为取 max(id) 和 min(id) 都是不需要扫描索引的,而第三步的 select 也可以用索引快速定位, 可以认为就只扫描了 3 行。但实际上,这个算法本身 并不严格满足题目的随机要求,因为 I D 中间可能有空洞, 因此选择不同行的概率不一样,不是真正的随机。
比如你有 4 个 id,分别是 1、2、4、5,如果按照上面的方法,那么取到 id=4 的这一行的概率是取得其他行概率的两倍。如果这四行的 id 分别是 1、2、40000、40001 ,这个算法 bug 了。
方法二:
为了得到严格随机的结果,可以用下面这个流程:
- 取得整个表的 行数,并记为 C。
- 取得 Y = floor(C * rand())。 floor 函数在这里的作用,就是取整数部分。
- 再用 limit Y,1 取得一行。
select count(*) into @C from t;
set @Y = floor(@C * rand());
set @sql = concat("select * from t limit ", @Y, ",1");
prepare stmt from @sql;
execute stmt;
DEALLOCATE prepare stmt;
MySQL 处理 limit Y,1 的做法就是按顺序一个一个地读出来,丢掉前 Y 个,然后把下一个记录作为返回结果,因此这一步需要扫描 Y+1 行。再加上,第一步扫描的 C 行,总共需要扫描 C+Y+1 行,执行代价比随机算法 1 的代价要高。
按照随机算法 2 的思路,要随机取 3 个 word 值
- 取得整个表的行数,记为 C;
- 根据相同的随机方法得到 Y1、Y2、Y3;
- 再执行三个 limit Y, 1 语句得到三行数据。
select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; // 在应用代码里面取 Y1、Y2、Y3 值,拼出 SQL 后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1;
总扫描行数是 C+(Y1+1)+(Y2+1)+(Y3+1)
Q:怎么做来减少扫描行数呢?说说你的方案,并说明你的方案需要的扫描行数。
A:
让表里面保存一个无空洞的自增值,这样就可以用算法 1 来实现
Original: https://www.cnblogs.com/ydssx7/p/16518838.html
Author: ydssx
Title: MySQL实战45讲 17
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/611939/
转载文章受原作者版权保护。转载请注明原作者出处!