

在面向对象的程序设计中,模块之间交互采用接口编程,通常情况下调用方不需要知道被调用方的内部实现细节,因为一旦涉及到了具体实现,如果需要换一种实现就需要修改代码,这违反了程序设计的”开闭原则”。所以我们一般有两种选择:一种是使用API(Application Programming Interface),另一种是SPI(Service Provider Interface),API通常被应用程序开发人员使用,而SPI通常被框架扩展人员使用。
在进入下面学习之前,我们先来再加深一下API和SPI这两个的印象:
API:由实现方制定接口标准并完成对接口的不同实现,这种模式服务接口从概念上更接近于实现方;
SPI:由调用方制定接口标准,实现方来针对接口提供不同的实现;从前半句话我们来看,SPI其实就是” 为接口查找实现“的一种服务发现机制;这种模式,服务接口组织上位于调用方所在的包中,实现位于独立的包中。
API和SPI简略图示:
看完上面的简单图示,相信大家对API和SPI的区别有了一个大致的了解,现在我们使用SPI机制来实现我们一个简单的日志框架:
第一步,创建一个maven项目命名为spi-interface,定义一个SPI对外服务接口,用来后续提供给调用者使用;
将上面这个这个项目打成spi-interface.jar包。
第二步,新建一个maven项目并导入第一步中打出来的spi-interface.jar包,这个项目用来提供服务的实现,定义一个类,实现第一步中定义的cn.com.wwh.Logger接口,示例代码如下:
同时在当前项目的classpath路径下建立META-INF/services/文件夹(至于为什么这么建立目录,我们一会儿再解释),并且新建一个名称为cn.com.wwh.Logger内容为cn.com.wwh.Logback的文件,这一步是关键(具体作用后面再详细说明),然后将上面第二步这个这个项目打成spi-provider.jar包,供给之后使用,我目前使用的开发工具是Eclipse,目录结构如下图所示:
第三步,编写测试类,新建一个maven项目,命名为spi-test,导入前面两个步骤打的spi-interface.jar和spi-provider.jar这两个jar包,并编写测试代码,示例如下:
有了SPI我们可以将服务和服务提供者轻松地解耦,假如将来的某一天我们需要将日志保存到数据库,或者通过网络发送,我们直接只需要替换针对服务接口的实现类即可,别的地方都不用修改,这更符合程序设计中的”开闭原则”。
SPI的大致原理是:应用启动的时候,扫描classpath下面的所有jar包,将jar包下的/META-INF/services/目录下的文件加载到内存中,进行一系列的解析(文件的名称是spi接口的全路径名称,文件内容应该是spi接口实现类的全路径名,可以用多个实现类,在文件中换行保存),之后判断当前类和当前接口是否是同一类型?结果为true,则通过反射生成指定类的实例对象,保存到一个map集合中,可以通过遍历或者迭代的方式拿出来使用。
SPI实质就是一个加载服务实现的工具,核心类是ServiceLoader,其实了解了SPI的原理,我们再接着探究JDK中的源码就没有那么费力了,下面我们开始源码分析吧。
ServiceLoader类是定义在java.util包下的,使用final定义禁止子类继承和修改,实现了Iterable接口,使得可以通过迭代或者遍历的方式获取SPI接口的不同实现。
从上面的我们所举的例子中,我们知道SPI的入口是ServiceLoader.load(Class ~~service)方法,我们来看看它都干了什么?
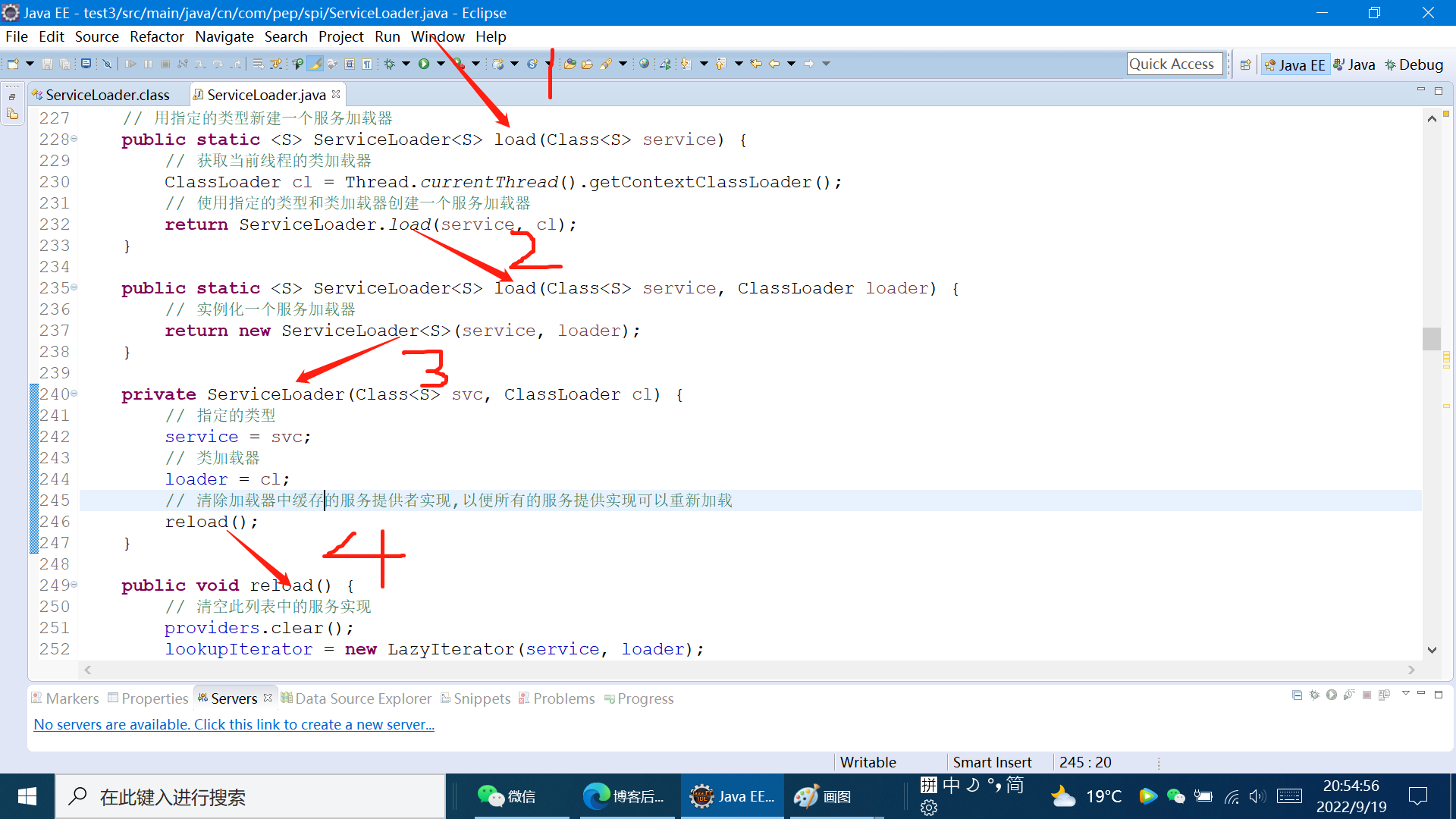
 ~~
~~
上面的这4步总的来说,就是使用指定的类型和当前线程绑定的classLoader实例化了一个LazyIterator对象赋值给lookupIterator这个引用,并且清除了原来providers列表中缓存的服务的实现。接下来我们调用了ServiceLoader实例的iterator()方法获取了一个迭代器,代码如下:
我们接着调用上步获取的迭代器it的hasNext()方法,因为我们在ServiceLoader.load()过程中其实是清除了providers列表中的缓存服务实现的,所以其实调用的是lookupIterator.hasNext()方法,如下:
假如上部判断为true,紧接着我们又调用了迭代器it的next()方式,同理也调用的是lookupIterator.next()方法,源码如下:
其实spi实现的主要流程是:扫描classpath路径下的所有jar包下的/META-INF/services/目录( 即我们需要将服务接口的具体实现类暴露在这个目录下,之前我们提到需要在实现类的classpath下面建立一个/META-INF/services/文件夹就是这个原因。),找到对应的文件,读取这个文件名找到对应的SPI接口,然后通过InputStream流将文件内容读出来,获取到实现类的全路径名,并得到这个全路径名所表示的Class对象,判断其与服务接口是否是同一类型,然后通过反射生成服务接口的实现,并保存在providers列表中,供给后续的使用。
SPI这种设计方式为我们的应用扩展提供了极大的便利,但是它的短板也是显而易见的,Java SPI 在查找扩展实现类的时候遍历 SPI 的配置文件并且将实现类全部实例化,假设一个实现类初始化过程比较消耗资源且耗时,但是你的代码里面又用不上它,这就产生了资源的浪费。所以说 Java SPI 无法按需加载实现类。
另外,SPI 机制在很多框架中都有应用:slf4j日志框架、Spring 框架的基本原理也是类似的反射。还有 Dubbo 框架提供同样的 SPI 扩展机制,只不过 Dubbo 和 spring 框架中的 SPI 机制具体实现方式跟咱们今天学得这个有些细微的区别( Dubbo可以实现按需加载实现类),不过整体的原理都是一致的,我们今天先对SPI有个简单的了解,相信有了今天的基础理解剩下的那几个也不是什么难事。
好了,今天就到这儿了,文章中有说的不对的地方还请各位大佬批评指正,一起学习,共同进步,谢谢。
Original: https://www.cnblogs.com/wha6239/p/16692713.html
Author: 一只烤鸭朝北走
Title: Java中的SPI原理浅谈
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/611573/
转载文章受原作者版权保护。转载请注明原作者出处!