

Redis key-value结构组织
首先,Redis使用了一个全局哈希表来保存所有的键值对。这个全局哈希表,也就是一个存放哈希桶(entry)的数组。Redis可以用哈希算法算出某个key的哈希值,直接取到这个数组这个位置的元素,也就是O(1)的读写。每个entry包含了两到三个部分,一个是 *key也就是指向键key的指针,一个 *value指向值value的指针,一级有可能会有 *next,当发生hash冲突时,使用链表存储值的下一个entry的位置指针。
冲突解决
上面提到了如果发生哈希冲突,会用一个链表的结构保存entry,一旦冲突变多势必影响读写性能,所以Redis会进行Rehash。Redis进行rehash的方式,是一开始就准备好两个数组h1, h2, h2为h1大小的两倍,使用h1的过程中,一旦h1元素多了,就将h1的内容拷贝到h2,然后释放h1。
为了保证rehash对读写业务影响尽可能小,Redis采用了 渐进式rehash:开始rehash的时候,redis仍然正常处理客户端请求,但每处理一个请求就 顺便从h1的第一个元素开始,把h1上的entries都拷贝到h2(这个思想倒是挺多地方有见到)。而且对于读的请求会先读h1没有就去读h2,而对于更新,删除操作也会对两个表进行,新增只会新增到h2,保证h1的数量会只减少不增。
Redis 数据结构
Redis有很多数据类型,这些数据类型都有一些元数据需要记录。Redis会封装这些数据在一个RedisObject里面,我们看看这个RedisObject长啥样:
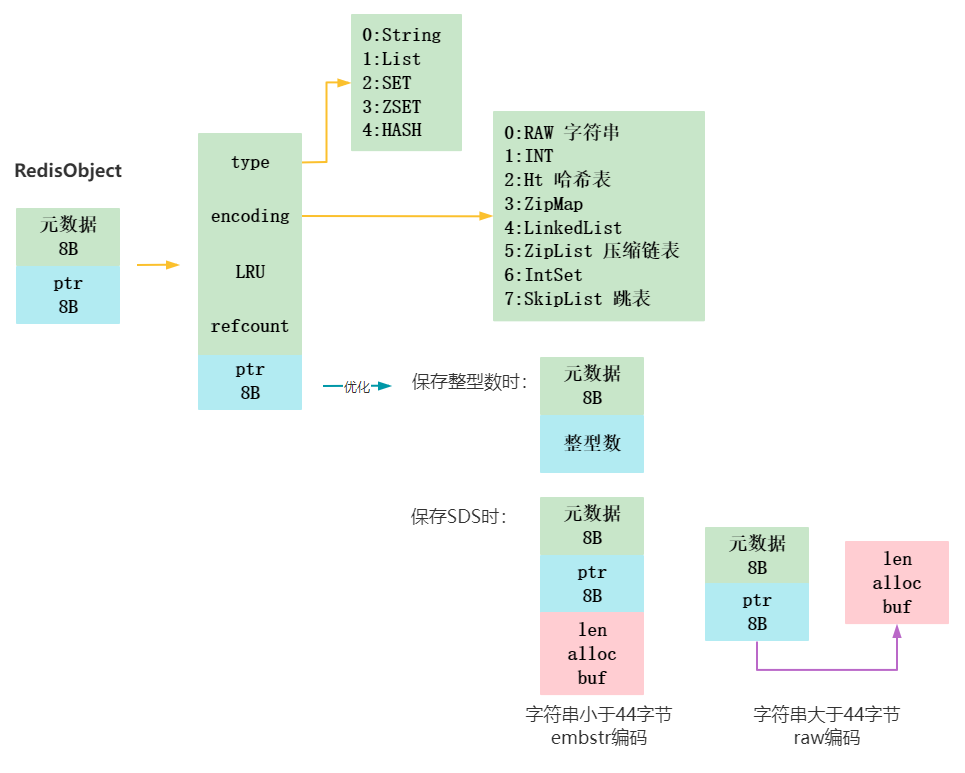

RedisObject主要包括了8字节的元数据和8字节的指针。元数据里有保存的数据类型,编码方式(底层实现),LRU即最后一次访问的时间,refcount引用计数。
RedisObject对整型数和简单字符串也做了优化,如果是整型数,*ptr就直接存整型数;如果是字符串,那么根据字符串大小(是否超过44字节)分为embstr编码方式,即ptr后紧凑地再分配一块内存存字符串,和raw方式,指针指向字符串。
应用数据结构
我们知道key就是一个字符串,而value,Redis提供了多种数据结构可以选择,包括常见的: String, List, Hash, Set, Sorted Set,和特殊的一些例如 Bitmap, HyperLogLog和 GEO。
底层实现的数据结构
Redis底层实现主要依靠了 SDS(Simple Dynamic String), 双向链表, 压缩列表, 哈希表, 跳表, 整数数组,其和应用数据结构的关系如下表:
类型 编码方式 string raw/embstr/int hash hashtable/ziplist list linkedlist/ziplist/quicklist set hashtable/intset zset ziplist/skiplist
压缩列表
压缩列表其实就是一个数组,只是比数组在表头多了三个字段 zlbytes列表长度, zltail列表尾部偏移量, zllenentry的个数,表尾多了一个字段 zlend表示结束,如下图:

在压缩列表中,查找第一个和最后一个元素的时间复杂度是O(1),而其他的则是O(N)
跳表
之前讲过这个,这里就不多说了//todo
Original: https://www.cnblogs.com/rachel-aoao/p/redis_data_structure.html
Author: rachel_aoao
Title: Redis-数据结构
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/601478/
转载文章受原作者版权保护。转载请注明原作者出处!