

· 什么是TF-IDF?
TF-IDF(term frequency–inverse document frequency)是一种加权技术,用于文本数据的挖掘与清洗。
· 使用情境
现有大段文本数据,希望从中获得高频、有效的词汇。
e.g. 文本数据:”今天天气很好,适合出去玩。”→n.天气;a.好;v.出去/玩
(Task:从中找出类似的词汇并统计词频)
· 算法步骤
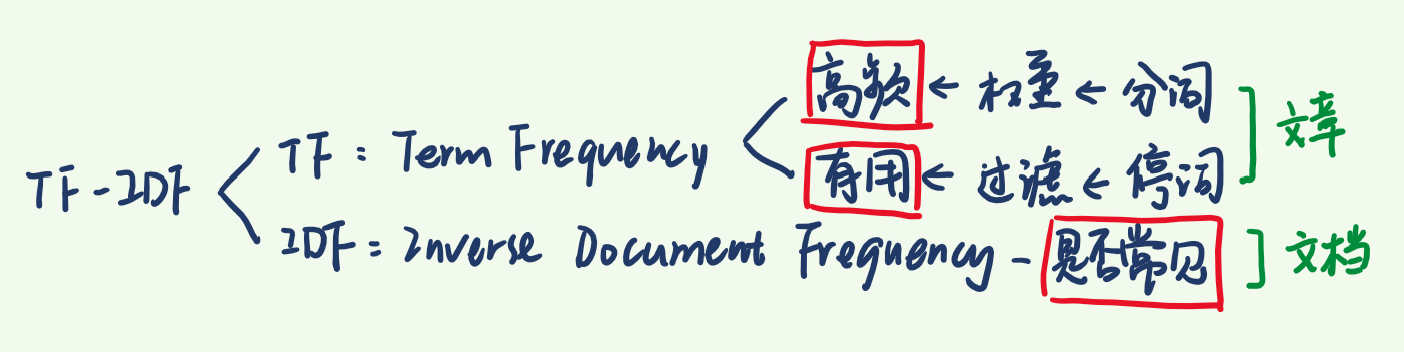

1.单篇文章中,计算TF:
Denote Xi=词汇i出现次数,X=文章总词汇数
#为什么要计算TF?
A:为了看 一篇文章/一段文字中词汇i出现的频率。
2.语料库中,计算IDF:
Denote Y=语料库中文章总数,Yi=包含词汇i的文章数
#为什么要计算IDF?
A:对比 不同文章中词汇出现的相对频率,可以得出 词汇i在特定文章中的重要性。
3.结合文章与词汇,计算TF-IDF:
· 代码实现
使用python中jieba库实现:分词→停词→计算词频。
首先进行 分词:
import pandas as pd
import jieba
import jieba.analys
import xlwt #读取excel文件
df_data = pd.read_excel('xx.xlsx',names=['x1', 'x2'],header =0)
contentslist = df_data.content.values.astype(str).tolist()
def jiebacut(content):
content_S = []
for line in content:
current_segment = jieba.lcut(line) #使用精确模式,且每行进行分词
if len(current_segment) > 1 and current_segment != '\r\n':
content_S.append(current_segment)
return content_S
jieba_contentslist=jiebacut(contentslist)
接下来,进行 停词以过滤无效词汇:
def drop_stopwords(contents, stopwords):
contents_clean = [] #清洗后的文本内容
all_words = [] #所需关键词
for line in contents:
line_clean = []
for word in line:
if word in stopwords: #去除停词表里的字词
continue
if word == ' ' or bool(re.search(r'\d', word)): #去除空格、数字
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean, all_words #得到清洗后的有效词汇
最后, 计算词频:
join_content_str=''
for index_num in range(0,len(clean_content)):
join_content_str += ''.join(clean_content[index_num])
keywords = jieba.analyse.extract_tags(join_content_str, topK=20, withWeight=True, allowPOS=()) #allowPOS限制提取的关键词词性
for item in keywords:
print(item[0],item[1]) #输出关键词与对应权重
· 使用后评价
优势:TF-IDF作为一种逻辑直接、简单的数据处理算法,可以 直观地反映出词汇在文章中的重要性,且使用 添加了IDF作为噪音抑制因子,其结果应该是相对可信的。
不足:正是由于添加了IDF, 其本身的简单性使得词汇提取中的偏差没有得到有效消除。比如说,现在进行同一类型语段的词汇提取,因为语段间类型相同——词汇类似,故IDF的加入反而使得一些重要词汇没有得到应有的重视, 即被低估了。
2022/4/6
Original: https://blog.csdn.net/etSha/article/details/123994316
Author: etSha
Title: 使用TF-IDF算法进行数据处理(附代码)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600785/
转载文章受原作者版权保护。转载请注明原作者出处!