

一、kdeplot
核密度估计用来估计未知的密度函数,是非参数检验之一。直观上来看是平滑后的直方图。核密度估计方法不利用有关数据分布的先验知识,对数据分布不附加任何假定,是一种从数据样本本身出发研究数据分布特征的方法,因而,在统计学理论和应用领域均受到高度的重视。
函数:seaborn.kdeplot
常用参数:
dataarray,用于绘制核密度图的数据data2array,如果传入数据,将估计双变量核密度。vertical
bool,指定y轴还是x轴为密度。
kernal”gau””cos””biw””epa””ri””triw”,选择核函数。双变量只能使用”gau”高斯核密度shadebool,是否在kde曲线下着色。gridsizeint,网格中离散点个数,默认为100.cumulativebool,是否绘制累积分布,默认为Falsecbarbool,是否添加颜色棒,默认为False。
iris=sns.load_dataset('iris')
iris.head()
>
sepal_lengthsepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
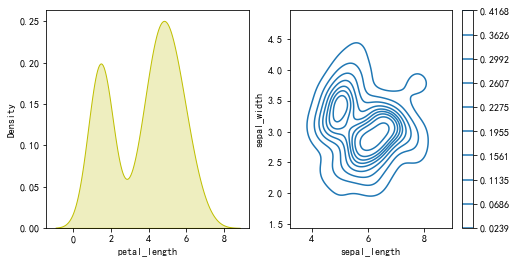
fig,axes=plt.subplots(1,2,figsize=(8,4))
#绘制单变量核密度图
sns.kdeplot(iris['petal_length'],ax=axes[0],shade=True,color='y')
#绘制双变量核密度图
sns.kdeplot(iris['sepal_length'],iris['sepal_width'],ax=axes[1],shade=False,cbar=True)

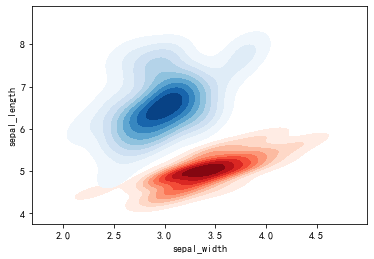
绘制两个阴影的双变量密度图:
setosa=iris.loc[iris.species=='setosa']
virginica=iris.loc[iris.species=='virginica']
sns.kdeplot(setosa.sepal_width,setosa.sepal_length,cmap='Reds',shade=True)
sns.kdeplot(virginica.sepal_width,virginica.sepal_length,cmap="Blues",shade=True)
二、rugplot
rugplot函数用来绘制地毯图,地毯图可以认为是数据刻度,用来辅助显示数据的分布特点。
函数:seaborn.rugplot
常用参数:
aarray,表示添加刻度的数据。heightfloat,刻度的高度,默认为0.05.axis接收x或y,指定添加刻度的轴。ax接收绘图对象,选择在哪个图中绘制刻度。
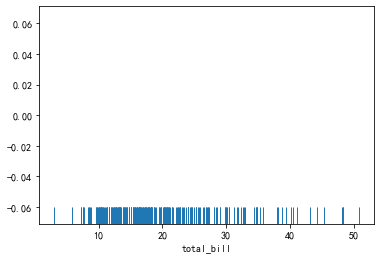
tips=sns.load_dataset('tips')
sns.rugplot(tips.total_bill,height=0.08)
在核密度图上添加地毯图:
sns.kdeplot(tips.total_bill)
sns.rugplot(tips.total_bill,height=0.08)

三、distplot
是hist函数的升级版,它集合了hist函数和kdeplot函数的功能,添加了rugplot分布观测条显示与利用scipy库拟合参数分布的新用途。
函数:seaborn.distplot
常用参数:
a接收series,list,array,表示观察数据,如果是具有name属性的series对象,则该名称将用于标记数据轴。binint,表示长方形数目,默认为”auto”histbool,是否绘制直方图。默认为Truekdebool,是否绘制高斯核密度估计,默认为Falserugbool,是否添加地毯刻度,默认为Falsefit接收随机变量对象,用来拟合分布。color表示除了拟合曲线外的所有内容的颜色。{hist,kde,rug,fit}_kws接受字典,表示底层绘图函数的关键字参数。
import pandas as pd
from scipy.stats import norm
import numpy as np
np.random.seed(1)
x=np.random.normal(size=100)
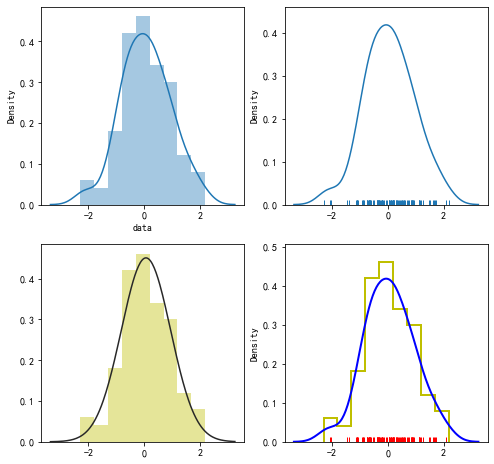
pic=plt.figure(figsize=(8,8))
data=pd.Series(x,name='data')#添加name属性
#使用默认参数绘图
pic.add_subplot(2,2,1)
sns.distplot(data)
#去除直方图,添加地毯图
pic.add_subplot(2,2,2)
sns.distplot(x,hist=False,rug=True)
#正态拟合参数分布,改变整体颜色
pic.add_subplot(2,2,3)
sns.distplot(x,fit=norm,kde=False,color='y')
#修改底层绘图函数参数
pic.add_subplot(2,2,4)
sns.distplot(x,rug=True,rug_kws={'color':"r"},kde_kws={'color':'k','lw':2,'label':'kde',"color":'b'},hist_kws={'histtype':'step','linewidth':2,'alpha':1,'color':'y'})
Original: https://blog.csdn.net/weixin_44020827/article/details/121710680
Author: Caspian�
Title: Python数据分析-绘图-2-Seaborn进阶绘图-3-分布图
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600113/
转载文章受原作者版权保护。转载请注明原作者出处!