

一、SE 模块的结构


SE 模块主要包含 Squeeze 和 Excitation 两部分。W,H 表示特征图宽,高。C 表示通道数,输入特征图大小为 W×H×C。
; 1、压缩(Squeeze)
第一步是压缩(Squeeze)操作,如下图所示:

这个操作就是一个
全局平均池化(global average pooling)。经过压缩操作后特征图被压缩为1×1×C向量。
2、激励(Excitation)
接下来就是激励(Excitation)操作,如下图所示:

由两个全连接层组成,其中SERatio是一个缩放参数,这个参数的目的是为了
减少通道个数从而降低计算量。
第一个全连接层有C*SERatio个神经元,输入为1×1×C,输出1×1×C×SERadio。
第二个全连接层有C个神经元,输入为1×1×C×SERadio,输出为1×1×C。
; 3、scale 操作
最后是 scale 操作,在得到 1×1×C 向量之后,就可以对原来的特征图进行 scale 操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C, 将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
这里我们可以得出SE模块的属性:
参数量 = 2×C×C×SERatio
计算量 = 2×C×C×SERatio
总体来讲SE模块会增加网络的总参数量,总计算量,因为使用的是全连接层计算量相比卷积层并不大,但是参数量会有明显上升
二、SE 模块的结构
SE 模块根据注意的方面不同分为通道注意力 CAM 和空间注意了 SAM,一个关注”what”,一个关注”where”, 两者可以并行或者串行使用。
1、通道注意力 CAM
通道注意力通过混合通道维度的信息来进行特征提取。
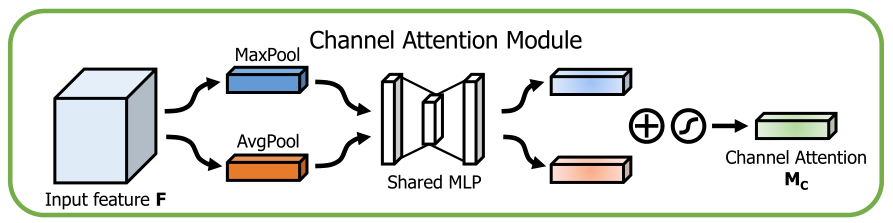
对于输入的 feature map F,首先在每个空间位置上应用 MaxPooling、AvgPooling,得到两个 C _1_1 的向量,然后分别送入一个共享的包含两层 FC 的 MLP,最后将两者相加融合,经过一个激活函数,得到通道注意力 CAM,其公式表达为:

Pytorch 实现:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
atten = self.sigmoid(avg_out + max_out)
return x * atten
2、空间注意力 SAM

首先在每个通道上应用 MaxPooling、AvgPooling,得到两个 1 _H_W 的 feature map,然后按通道 concat 起来,送入一个标准卷积层,经过激活函数之后就得到了空间注意力 SAM,其公式表达为:

Pytorch 实现:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
atten = torch.cat([avg_out, max_out], dim=1)
atten = self.conv1(atten)
atten = self.sigmoid(atten)
return x * atten
3、CBAM模块(Convolutional Block Attention Module)
该注意力模块( CBAM ),可以在通道和空间维度上进行 Attention 。其包含两个子模块 Channel Attention Module(CAM) 和 Spartial Attention Module(SAM)。

Original: https://blog.csdn.net/IT__learning/article/details/119326173
Author: IT__learning
Title: SE注意力模块
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/711814/
转载文章受原作者版权保护。转载请注明原作者出处!