

正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个 “规则字符串”,这个 “规则字符串” 用来表达对字符串的一种过滤逻辑。
1. 正则表达式的语法规则
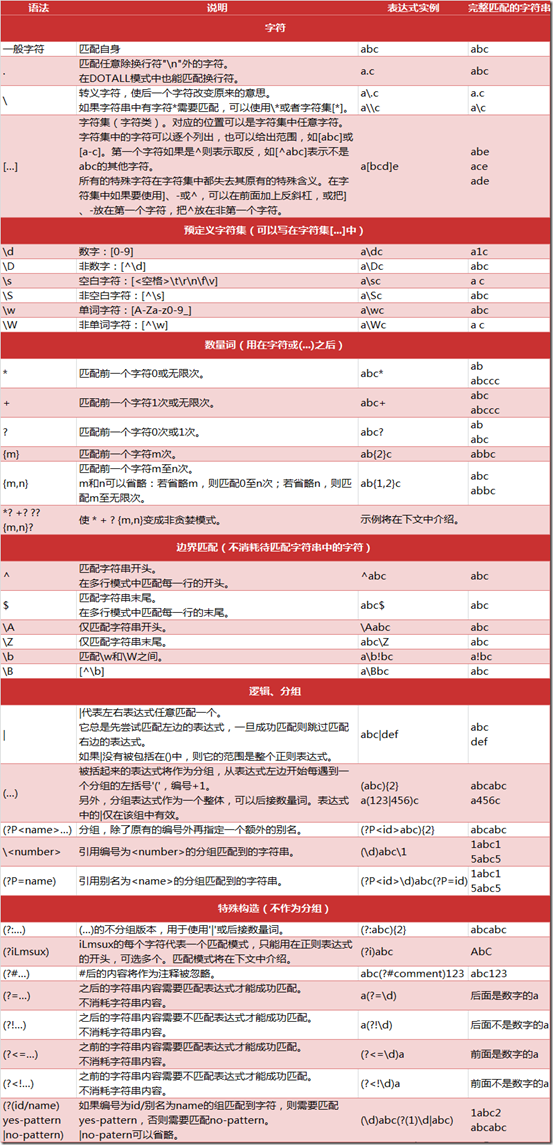

2.正则表达式相关注解
(1) 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python 里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab “如果用于查找” abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab?”,将找到”a”。 注:我们一般使用非贪婪模式来提取。
(2) 反斜杠问题
与大多数编程语言相同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要 4 个反斜杠”\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。 Python 里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用 r”\”表示。同样,匹配一个数字的”\d” 可以写成 r”\d”。有了原生字符串,妈妈也不用担心是不是漏写了反斜杠,写出来的表达式也更直观勒。
3.Python Re 模块
返回pattern对象
re.compile(string[,flag])
以下为匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.split(pattern, string[, maxsplit])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count])
我们先来介绍一下 pattern 的概念,pattern 可以理解为一个匹配模式,那么我们怎么获得这个匹配模式呢?很简单,我们需要利用 re.compile 方法就可以。例如
pattern = re.compile(r’hello’)
在参数中我们传入了原生字符串对象,通过 compile 方法编译生成一个 pattern 对象,然后我们利用这个对象来进行进一步的匹配。 另外大家可能注意到了另一个参数 flags,
在这里解释一下这个参数的含义: 参数 flag 是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如 re.I | re.M。 可选值有:
• re.I ( 全拼: IGNORECASE): 忽略大小写 (括号内是完整写法,下同)
• re.M ( 全拼: MULTILINE): 多行模式 ,改变 ‘^’ 和 ‘$’ 的行为 (参见上图)
• re.S ( 全拼: DOTALL): 点任意匹配模式 ,改变 ‘.’ 的行为
• re.L ( 全拼: LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
• re.U ( 全拼: UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于 unicode 定义的字符属性
• re.X ( 全拼: VERBOSE): 详细模式 。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
(1) re.match(pattern, string[, flags])
这个方法将会从 string(我们要匹配的字符串)的开头开始,尝试匹配 pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回 None,如果匹配未结束已经到达 string 的末尾,也会返回 None。两个结果均表示匹配失败,否则匹配 pattern 成功,同时匹配终止,不再对 string 向后匹配。下面我们通过一个例子理解一下
author = ‘YC’
# –– coding: utf-8 ––
# 导入 re 模块
import re
# 将正则表达式编译成 Pattern 对象,注意 hello 前面的 r 的意思是”原生字符串”
pattern = re.compile(r’hello’)
# 使用 re.match 匹配文本,获得匹配结果,无法匹配时将返回 None
result1 = re.match(pattern,’hello’)
result2 = re.match(pattern,’helloo YC!’)
result3 = re.match(pattern,’helo YC!’)
result4 = re.match(pattern,’hello YC!’)
# 如果 1 匹配成功
if result1:
# 使用 Match 获得分组信息
print result1.group()
else:
print ‘1 匹配失败! ‘
# 如果 2 匹配成功
if result2:
# 使用 Match 获得分组信息
print result2.group()
else:
print ‘2 匹配失败! ‘
# 如果 3 匹配成功
if result3:
# 使用 Match 获得分组信息
print result3.group()
else:
print ‘3 匹配失败! ‘
# 如果 4 匹配成功
if result4:
# 使用 Match 获得分组信息
print result4.group()
else:
print ‘4 匹配失败! ‘
(2) re.search(pattern, string[, flags])
search 方法与 match 方法极其类似,区别在于 match () 函数只检测 re 是不是在 string 的开始位置匹配,search () 会扫描整个 string 查找匹配,match()只有在 0 位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match () 就返回 None。同样,search 方法的返回对象同样 match () 返回对象的方法和属性。我们用一个例子感受一下
# 导入re 模块
import re
# 将正则表达式编译成Pattern 对象
pattern = re.compile(r’world’)
# 使用search() 查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match() 无法成功匹配
match = re.search(pattern,’hello world!’)
if match:
# 使用Match 获得分组信息
print match.group()
### 输出 ###
# world
(3) re.split(pattern, string[, maxsplit])
按照能够匹配的子串将 string 分割后返回列表。maxsplit 用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。
import re
pattern = re.compile(r’\d+’)
print re.split(pattern,’one1two2three3four4′)
### 输出 ###
# [‘one’, ‘two’, ‘three’, ‘four’, ”]
(4) re.findall(pattern, string[, flags])
搜索 string,以列表形式返回全部能匹配的子串。我们通过这个例子来感受一下
import re
pattern = re.compile(r’\d+’)
print re.findall(pattern,’one1two2three3four4′)
### 输出 ###
# [‘1’, ‘2’, ‘3’, ‘4’]
(5) re.finditer(pattern, string[, flags])
搜索 string,返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。我们通过下面的例子来感受一下
import re
pattern = re.compile(r’\d+’)
for m in re.finditer(pattern,’one1two2three3four4′):
print m.group(),
### 输出 ###
# 1 2 3 4
(6) re.sub(pattern, repl, string[, count])
使用 repl 替换 string 中每一个匹配的子串后返回替换后的字符串。 当 repl 是一个字符串时,可以使用 \id 或 \g、\g 引用分组,但不能使用编号 0。 当 repl 是一个方法时,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count 用于指定最多替换次数,不指定时全部替换。
import re
pattern = re.compile(r'(\w+) (\w+)’)
s = ‘i say, hello world!’
print re.sub(pattern,r’\2 \1′, s)
def func(m):
return m.group(1).title() + ‘ ‘ + m.group(2).title()
print re.sub(pattern,func, s)
### output ###
# say i, world hello!
# I Say, Hello World!
(7) re.subn(pattern, repl, string[, count])
返回 (sub (repl, string [, count]), 替换次数)。
import re
pattern = re.compile(r'(\w+) (\w+)’)
s = ‘i say, hello world!’
print re.subn(pattern,r’\2 \1′, s)
def func(m):
return m.group(1).title() + ‘ ‘ + m.group(2).title()
print re.subn(pattern,func, s)
### output ###
# (‘say i, world hello!’, 2)
# (‘I Say, Hello World!’, 2)
爬取网页案例:
from urllib import request
import re
定义url
page = 100
url = "https://tieba.baidu.com/f?kw=%B6%CE%D7%D3&fr=ala0&tpl=5&dyTabStr=MCw2LDIsNCw1LDMsMSw4LDcsOQ%3D%3D&ie=utf-8"+str(page)
try:
#定义请求头
headers={"User-Agent":" Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36"}
#传入请求头
req = request.Request(url=url,headers=headers)
#打开网页
resp = request.urlopen(req)
#阅读下载的页面
content = resp.read().decode("utf-8")
print(content)
#定义正则表达式
# ps.根据页面源代码进行一个规则定义 越详细匹配到的数据越精确
# (.*?)小括号分组的就是我们要保存的数据
# .*? 是匹配掉无用数据 不保存
# \s 匹配空格 ps.为了更加精确的进行匹配
pattern =re.compile(r'(.*?)')
#进行匹配制定的网页
items=re.findall(pattern,content)
# 打印解析的内容
for i in items:
print(i[0]+"\t"+i[1])
except request.URLError as e:
# d打印响应码
if hasattr(e,'code'):
print(e.code)
# 打印异常原因
if hasattr(e,"reason"):
print(e.reason)
Original: https://www.cnblogs.com/zzc1102/p/16004241.html
Author: and脱发周大侠
Title: 爬虫基础_正则表达式_补
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/599509/
转载文章受原作者版权保护。转载请注明原作者出处!