

“What I cannot create, I do not understand.” – Richard Feynman
I’m building a clone of sqlite from scratch in C in order to understand, and I’m going to document my process as I go.
译注:cstsck在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的,实现教程原文是英文,共有13篇,这里翻译过来以飨读者。原文标题:Let’s Build a Simple Database,本文是第一篇
Part 1 介绍&设置REPL
作为一名开发人员,在工作中我每天都使用关系型数据库。但是对我来说,它们是一个黑盒。我有一些问题:
- 数据存储使用什么格式? (在内存与磁盘中)
- 数据什么时候从内存转移到磁盘?
- 为什么每张表只能有一个主键?
- 事务回滚是怎么工作的?
- 索引是什么格式的?
- 全表扫描时什么时候发生,如何发生的?
- 预处理语句(prepared statement)是使用什么格式存储的?
换句话说,数据库是怎么工作的?
为了弄清楚这些,我从头写了一个数据库。它是模仿sqlite实现的,因为sqlite设计小巧,并且相比于MySQL和PostgreSQL,它的功能相对要少很多,所以我希望能更容易的理解它。在实现上,整个数据库都存储在一个数据文件中。
Sqlite
在sqlite的网站上,有很多sqlite的内部文档(https://www.sqlite.org/arch.html)。另外我还拷贝了文档(SQLite Database System: Design and Implementation.)的一个副本(https://play.google.com/store/books/details?id=9Z6IQQnX1JEC)。

sqlite architecture
(https://www.sqlite.org/zipvfs/doc/trunk/www/howitworks.wiki)
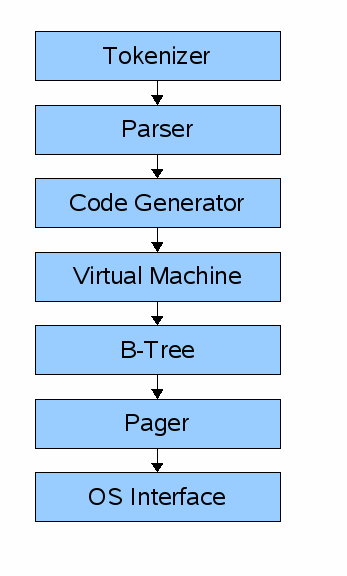
一个查询通过组件链来获取数据或者修改数据。前端如下组件:
- 分词器(tokenizer)
- 解析器(parser)
- 代码生成器(code generator)
前端的输入是SQL语句。输出则是sqlite的虚拟机字节码(sqlite virtual machine bytecode),本质上是一个可以在数据库运行的编译程序。
译注:数据库实现查询优化模型分为传统的火山模型(Volcano model)与Code gen模型,本文作者实现的是code gen模型。
后端包括如下组件:
- 虚拟机(virtual machine)
- B-tree
- 页管理(pager)
- 系统接口(os interface)
virtual machine
虚拟机将前端生成的字节码作为指令。它接下来可以在一个或更多的表、索引上执行操作,表以及索引都是存储在叫B-tree的数据结构中。VM 本质上是字节码指令类型的一个大开关语句(a big switch statement on the type of bytecode instruction)。
B-tree
每个B-tree许多节点。每个节点是一个page的长度。B-tree可以通过执行命令到pager,从磁盘获取一个page或者保存回page到磁盘。
pager
pager接收命令来读取或者写入数据的pages。它是负责来读、写数据库文件的适当偏移位置。也负责保持当前访问的pages在内存中,并且决定何时这些pages需要写回磁盘。
os interface
系统接口与sqlite根据不同操作系统平台来编译不同,在这个系列教程中,我不准备去支持多平台适配。
千里之行始于足下,所以我们从一些简单的事开始:REPL
实现简单的REPL
译注:REPL,Read – Execute – Print – Loop,即读取 – 执行 – 打印输出 – 循环,这个过程。有时候翻译成交互式解释器
当你执行命令行命令时,sqlite开始读取-执行-打印循环:
~ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
~
为了实现这样的效果,我们的主程序需要有一个无限循环来打印这个提示,获取一行输入,然后处理这行输入:
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
我们定义一个InputBuffer来作为一个封装,封装围绕在我们需要存储的、与getline()函数交互的状态(稍后将对此进行详细介绍)
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
接下来, print_prompt()函数为用户打印出提示。在做这个之前需要读取每一行输入。
void print_prompt() { printf("db > "); }
读取命令行输入,需要使用getline()函数:
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
(以下为getline的函数释义)
lineptr:
一个指针指向我们在buffer中包含的,从命令行读取的命令的变量。如果设置为NULL,它由getline()函数分配内存。并且后续由用户来释放,即使命令行的命令执行失败也能保证会被释放已分配的内存。
n:
一个指针变量,指向已经分配内存的buffer的大小(size)。
stream:
读取的输入流,这里是从标准输入读取的。
return value(返回值,ssize_t类型):
读取的字节数量,可能会比buffer的size小。
我们告诉getline()函数保存读取的命令行到 input_buffer->buffer,存储buffer的size到 input_buffer->buffer_length,保存返回值到 input_buffer->input_length。
buffer 在初始时是null,所以getline()函数分配足够的内存来存输入的命令行数据然后让buffer来指向这些数据。
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) { printf("error reading input\n"); exit(exit_failure); } ignore trailing newline input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
</=>
现在就可以定义一个函数来释放已分配给InputBuffer*实例和buffer中元素各自的数据结构的内存了(在read_input()函数中,调用getline()函数为 input_buffer->buffer 分配内存)。
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
在最后,我们解析并执行命令。现在这只是一个认可的命令:.exit,一个终止程序的命令。除此之外的命令,我们打印一个报错信息然后继续程序的循环。
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
让我们来试试吧!
~ ./db
db > .tables
Unrecognized command '.tables'.
db > .exit
~
好了,我们得到了一个可以工作的REPL。在下一部分,我们将开始开发我们的命令语言。同时,下面是是这部分的全部程序代码:
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("db > "); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) { printf("error reading input\n"); exit(exit_failure); } ignore trailing newline input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
</=></string.h></stdlib.h></stdio.h></stdbool.h>
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
欢迎来GreatSQL社区发帖提问
https://greatsql.cn/

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。

Original: https://www.cnblogs.com/greatsql/p/16706642.html
Author: GreatSQL
Title: 实现一个简单的Database1(译文)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/598636/
转载文章受原作者版权保护。转载请注明原作者出处!